










论文地址
论文地址:https://arxiv.org/abs/1710.10903
github:PetarV-/GAT: Graph Attention Networks (https://arxiv.org/abs/1710.10903) (github.com)
论文首页

笔记框架
图注意力网络
📅出版年份:2018
📖出版期刊:
📈影响因子:
🧑文章作者:Veličković Petar,Cucurull Guillem,Casanova Arantxa,Romero Adriana,Liò Pietro,Bengio Yoshua
🔎摘要:
我们提出了图注意力网络(GATs),这是一种可在图结构数据上运行的新型神经网络架构,它利用掩码自注意力层来解决之前基于图卷积或其近似值的方法的不足之处。通过堆叠节点能够关注其邻域特征的层,我们能够(隐式地)为邻域中的不同节点指定不同的权重,而不需要任何形式的代价高昂的矩阵运算(如反转),也不依赖于对图结构的预先了解。通过这种方式,我们同时解决了基于谱的图神经网络所面临的几个关键挑战,并使我们的模型可随时应用于归纳和转换问题。我们的 GAT 模型在四个已确立的转导和归纳图基准中取得了最先进的结果或与之相当:Cora、Citeseer 和 Pubmed 引用网络数据集,以及蛋白质-蛋白质相互作用数据集(其中测试图在训练期间保持未见)。
🔩GATs模型架构:
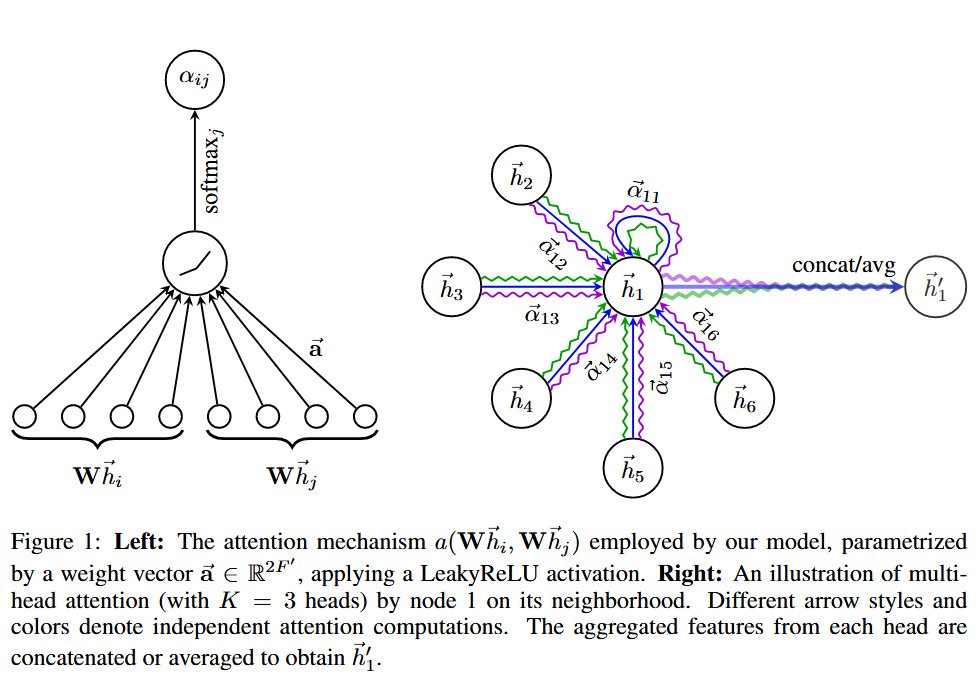
我们将首先描述单个图形注意力层,作为我们实验中使用的所有 GAT 架构中使用的唯一层。我们使用的特殊注意力设置密切遵循 Bahdanau 等人的工作。
输入层
我们层的输入是一组节点特征,该层生成一组新的节点特征作为其输出。
权重初始化
作为初始步骤,将由权重矩阵参数化的共享线性变换应用于每个节点。
共享注意力机制
然后,我们对节点执行自注意力——共享注意力机制。我们通过执行屏蔽注意力将图结构注入到机制中。
在我们的实验中,注意力机制 a 是一个单层前馈神经网络,由权重向量参数化,并应用 LeakyReLU 非线性(负输入斜率 α = 0.2)。
多头注意力
K个独立的注意力机制执行方程4的变换,然后将它们的特征连接起来。
softmax
一旦获得,归一化注意力系数用于计算与其对应的特征的线性组合,作为每个节点的最终输出特征(在可能的之后)应用非线性 。
如果我们在网络的最后(预测)层上执行多头注意力,串联就不再明智了——相反,我们采用平均,并延迟应用最终的非线性(通常是 softmax 或逻辑 sigmoid分类问题)。
🧪实验:
📇数据集:
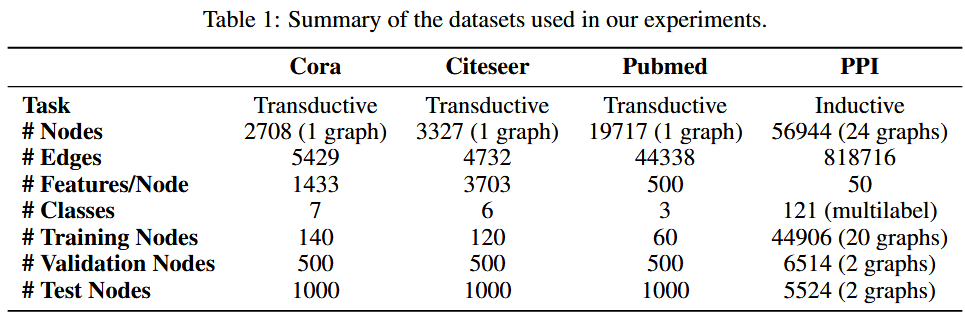
我们利用三个标准引文网络基准数据集——Cora、Citeseer 和 Pubmed(Sen 等人,2008)——并严格遵循 Yang 等人的转导实验设置。
我们利用蛋白质-蛋白质相互作用(PPI)数据集,该数据集由对应于不同人体组织的图表组成(Zitnik & Leskovec,2017)。
📉优化器&超参数:
转导学习任务
我们应用两层 GAT 模型。
其架构超参数已在 Cora 数据集上进行了优化,然后重新用于 Citeseer。第一层由 K = 8 个注意力头组成,每个注意力头计算 F ′ = 8 个特征(总共 64 个特征),后面是一个指数线性单元 (ELU) 非线性。
第二层用于分类:计算 C 个特征(其中 C 是类数)的单个注意力头,然后是 softmax 激活。
为了应对较小的训练集大小,在模型中广泛应用了正则化。在训练期间,我们应用 λ = 0.0005 的 L2 正则化。此外,p = 0.6 的 dropout(Srivastava 等人,2014)应用于两个层的输入以及归一化注意力系数。
与 Monti 等人观察到的类似。 (2016),我们发现 Pubmed 的训练集大小(60 个示例)需要对 GAT 架构进行轻微更改:我们应用了 K = 8 个输出注意头(而不是 1 个),并将 L2 正则化增强到 λ = 0.001。除此之外,该架构与 Cora 和 Citeseer 使用的架构相匹配。
归纳学习
我们应用了三层 GAT 模型。
前两层均由 K = 4 个注意力头组成,计算 F ′ = 256 个特征(总共 1024 个特征),后面是 ELU 非线性。
最后一层用于(多标签)分类:K = 6 个注意力头,每个注意力头计算 121 个特征,对这些特征进行平均,然后进行逻辑 sigmoid 激活。
该任务的训练集足够大,我们发现不需要应用 L2 正则化或 dropout——但是,我们已经成功地在中间注意力层中使用了跳跃连接(He et al., 2016)。
我们在训练期间使用 2 个图的批量大小。为了严格评估在这种情况下应用注意力机制的好处(即与接近 GCN 等效的模型进行比较),我们还提供了使用恒定注意力机制 a(x, y) = 1 时的结果,其中相同的架构——这将为每个邻居分配相同的权重。
优化器
两个模型均使用 Glorot 初始化(Glorot & Bengio,2010)进行初始化,并使用 Adam SGD 优化器(Kingma & Ba,2014)进行训练,以最小化训练节点上的交叉熵,Pubmed 的初始学习率为 0.01,对于所有其他数据集的初始学习率为 0.005。
📋实验结果:
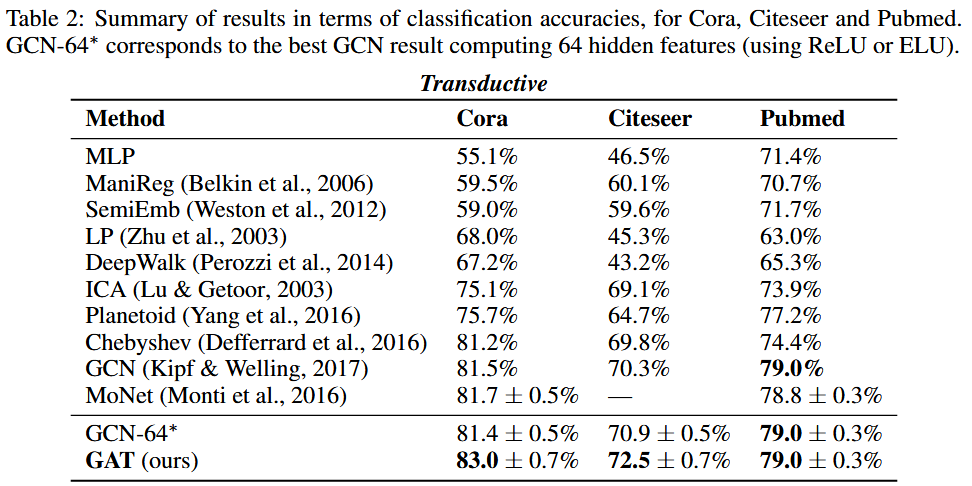
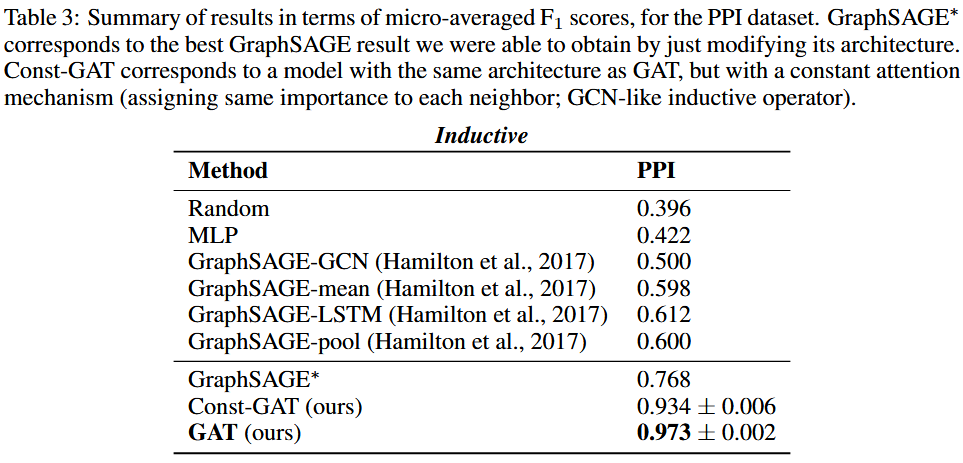
我们的结果成功地证明了在所有四个数据集上实现或匹配的最先进的性能 - 符合我们的预期。
我们能够在 Cora 和 Citeseer 上分别比 GCN 提高 1.5% 和 1.6%,这表明为同一邻域的节点分配不同的权重可能是有益的。
值得注意的是 PPI 数据集上取得的改进:我们的 GAT 模型相对比提高了 20.5%。这是我们能够获得的最佳 GraphSAGE 结果,证明我们的模型有潜力应用于归纳设置,并且可以通过观察整个邻域来利用更大的预测能力。
此外,它还提高了 3.9% w.r.t. Const-GAT(具有恒定注意力机制的相同架构),再次直接证明了能够为不同邻居分配不同权重的重要性。
🚩研究结论:
我们提出了图注意力网络(GAT),这是一种新颖的卷积式神经网络,它利用屏蔽的自注意力层对图结构数据进行操作。
我们利用注意力的模型已经成功地在四个成熟的节点分类基准中实现或匹配最先进的性能,包括传导性和归纳性(特别是用于测试的完全不可见的图)。
📝总结
💡创新点:
我们引入了一种基于注意力的架构来执行图结构数据的节点分类。这个想法是通过关注其邻域并遵循自注意力策略来计算图中每个节点的隐藏表示。
-
引入masked self-attentional layers 来改进前面图卷积graph convolution的缺点
-
对不同的相邻节点分配相应的权重,既不需要矩阵运算,也不需要事先知道图结构。
⚠ 局限性:
我们使用的张量操作框架仅支持 2 阶张量的稀疏矩阵乘法,这限制了当前实现的层的批处理能力(特别是对于具有多个图的数据集)。
根据现有图形结构的规律性,在这些稀疏场景中,与 CPU 相比,GPU 可能无法提供主要的性能优势。
我们模型的“感受野”的大小受到网络深度的上限(与 GCN 和类似模型类似)。
最后,跨所有图边的并行化,尤其是以分布式方式,可能涉及大量冗余计算,因为邻域通常在感兴趣的图中高度重叠。
🖍️知识补充:
许多有趣的任务涉及无法以网格状结构表示的数据,而是位于不规则域中的数据。 3D 网格、社交网络、电信网络、生物网络或大脑连接组就是这种情况。
GNN 由一个迭代过程组成,该过程会传播节点状态,直至达到平衡;然后是一个神经网络,该网络根据每个节点的状态为其生成输出。
将卷积推广到图域这个方向的进展通常分为谱方法和非谱方法。
谱方法使用图的谱表示,并已成功应用于节点分类的背景下。
另一方面,我们有非谱方法(Duvenaud et al., 2015;Atwood & Towsley, 2016;Hamilton et al., 2017),它们直接在图上定义卷积,对空间上邻近的组进行操作。
注意力机制的好处之一是它们允许处理可变大小的输入,专注于输入中最相关的部分以做出决策。当注意力机制用于计算单个序列的表示时,通常称为自注意力或内部注意力。


















 1554
1554

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











