







💦 打开文件
在python中无论是从文件读取内容还是把内容写到文件中,都需要先打开文件。打开文件用的是内置函数open。
open函数有许多参数,在官方文档中open函数的定义如下:
open(file,mode = 'r',buffering = 1,encoding = None,errors = None.newline = None,closefd = True,opener = None)
可以从函数的定义中看到,open函数只有file参数是必须传递的,其它参数都有默认值。举一个最简单的打开文件的例子👇:
filename = "test1.py"
f = open(filename)
若一切正常,open函数就会返回一个文件对象,于是我们用f来接收它的返回值;如果文件不能被打开,open函数就会抛出一个异常。
☁️ 文件模式
文件模式指的是open函数的参数mode,它指明了要以何种方式打开文件。默认的模式是“r”,即以只读的方式打开文件,只能读不能写。
可用的模式如下👇:
| 模式 | 描述 |
|---|---|
| r | 只读,文件的指针将会放在文件的开头 |
| rb | 以二进制格式打开,只读,文件的指针将会放在文件的开头 |
| r+ | 读写,文件的指针将会放在文件的开头 |
| rb+ | 以二进制格式打开,读写,文件的指针将会放在文件的开头 |
| w | 写,如果该文件已存在,则打开文件,并从头开始编辑,即原有内容会被删除。如果不存在,则创建新文件。 |
| wb | 以二进制格式打开,其它同上 |
| w+ | 读写,同上 |
| wb+ | 以二进制格式打开,读写,同上 |
| a | 追加内容,如果该文件已存在,文件指针将会放在文件的结尾,也就是说,新的内容会被写入到已有内容之后。不存在则创建新文件 |
| ab | 以二进制格式打开,追加,同上 |
| a+ | 读写,同上 |
| ab+ | 以二进制格式打开,读写,同上 |
💦 文件基本操作
- 读文件
首先在源文件的目录下另建一文本文档。

并在文本文档中输入。

f = open("aaa.txt") //这里不带文件模式是因为默认为read
b = f.read()
print(b)
#hello
#how are you
如果我们操作的文件不在源文件的目录下,则需要加上路径名。
f = open("d:\\pycharm\\ab.txt")
b = f.read()
print(b)
read函数也可以传递参数,用于指定读取多少个字符。
- 写文件
f = open("aaa.txt","w")
b = "你好"
print(f.write(b)) #while函数返回写入字符的个数
#2
这时,我们创建的文本文件中的内容就变了

由上图可以看到,我们用“w”模式打开文件都会从头开始覆盖原有的内容。如果我们想在已有的文件内容后面追加内容,就要用“a”模式。
f = open("aaa.txt","a")
b = "你过得好吗"
print(f.write(b))
#5

- 按行读文件
python提供了readline函数来逐行读取文件内容,我们重新在这个文本文档中写入内容。
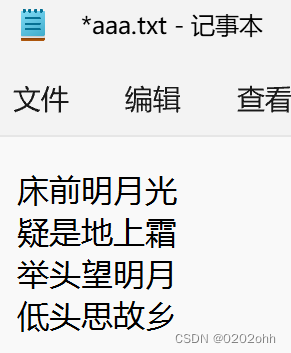
p = open("aaa.txt")
print(p.readline()) #读取第一行
print(p.readline()) #读取第二行
#床前明月光
#疑是地上霜
readlines函数把文件内容按行切割后会返回一个list列表对象。
p = open("aaa.txt")
print(p.readlines())
#['床前明月光\n', '疑是地上霜\n', '举头望明月\n', '低头思故乡']
p = open("aaa.txt")
for i in p.readlines():
print(i)
#床前明月光
#疑是地上霜
#举头望明月
#低头思故乡
还可以直接迭代文件对象本身:
p = open("aaa.txt")
for i in p:
print(i)
#床前明月光
#疑是地上霜
#举头望明月
#低头思故乡
它和readlines的区别在于readlines会读取整个文件并返回一个list,但是迭代的方法是只有迭代到需要读取的一行,才会真的执行读取操作。这样做的好处是如果文件十分大,并且只需要一行一行地处理文件,就不同把整个文件都导入到内存中了。
- 按行写文件
python提供了writelines方法,把列表作为参数写入文件,因为python并不会帮我们添加换行符。
writelines方法接收一个参数,这个参数必须是列表,列表的每个元素就是想写入的每行文本内容,但是需自行添加换行符:
p = open("aaa.txt","r+")
b = ["最是人间留不住\n","朱颜辞镜花辞树"]
p.writelines(b)

- 关闭文件
在读取和写入文件的过程中出现异常,我们就需要使用try语句捕获可能出现的相关异常,然后进行退出文件或者其它的相关操作。但需要注意的是,无论是否有异常都需要关闭文件。
一般情况下,文件对象在程序退出后都会自动关闭,但为了安全起见,最好还是显示地调用close方法来关闭文件比较好:
f = None
try:
p = open("aaa.txt")
print(p.read())
except IOError:
print("Error")
finally:
if p:
p.close()
但如果每次打开文件之后都需要我们显示地关闭文件,难免有时候会忘记关闭文件。对此,python引入了with语句来帮助我们自动调用close方法:
with open("aaa.txt") as p:
a = p.read()
print(a)
💦 StringIO和BytesIO
有时候数据并不需要真正地写入到文件中,只需要在内存中做读取写入即可。python中的IO模块提供了对str操作的StringIO函数。
要把str写入StringIO,我们需要先创建一个StringIO对象,然后像文件一样写入即可:
from io import StringIO
p = StringIO()
p.write('你好吗?\n')
p.write('我很好')
print(p.getvalue())
#你好吗?
#我很好
getvalue方法用于获得写入后的str。
要读取StringIO,可以先用一个str初始化StringIO,然后像文件一样读取即可:
from io import StringIO
p = StringIO("你最近过得还好吗?\n我过得并不好 ")
for i in p.readlines():
print(i)
#你最近过得还好吗?
#我过得并不好
StringIO的操作对象只能是str,如果要操作二进制数据,就需要使用BytesIO。
写入bytes:
from io import BytesIO
p = BytesIO()
p.write("你好".encode("utf-8"))
print(p.getvalue())
print(p.getvalue().decode("utf-8"))
#b'\xe4\xbd\xa0\xe5\xa5\xbd'
#你好
❗️:写入的不是str,而是经过UTF-8编码的bytes。
读取bytes:
from io import BytesIO
p = BytesIO(b'\xe4\xb8\xad\xe6\x96\x87')
print(p.read().decode("utf-8"))
#中文
💦 序列化与反序列化
程序在运行的时候,所有变量都是保存在计算机内存中的,我们可以把变量从内存中转存到磁盘或者别的存储介质上,这个把变量从内存中变成可存储或传输的过程被称为序列化。反过来,我们把变量内容从序列化的对象重新读取到内存的过程称为反序列化。
再简单点说,序列化就是将数据结构或对象转换成二进制串,反序列化就是将二进制串转回成数据结构或对象。
☁️ pickle模块
pickle模块实现了一些基本数据的序列化和反序列化。
通过pickle模块的序列化操作,我们可以将程序中运行的对象信息保存到文件中;通过它的反序列化操作,我们可以从文件中恢复或者创建上次程序保存下来的对象。
pickle模块中的dumps方法可以把对象序列化成bytes:
import pickle
class Student:
def __init__(self,name,age,gender):
self.name = name
self.age = age
self.gender = gender
student = Student("小明",15,"男")
print(pickle.dumps(student))
#b'\x80\x04\x95G\x00\x00\x00\x00\x00\x00\x00\x8c\x08__main__\x94\x8c\x07Student\x94\x93\x94)\x81\x94}\x94(\x8c\x04name\x94\x8c\x06\xe5\xb0\x8f\xe6\x98\x8e\x94\x8c\x03age\x94K\x0f\x8c\x06gender\x94\x8c\x03\xe7\x94\xb7\x94ub.'
pickle.dumps方法可以帮助我们把任意对象序列化成bytes,然后直接写入到文件对象中,不需要我们再一步一步地写入文件:
import pickle
class Student:
def __init__(self,name,age,gender):
self.name = name
self.age = age
self.gender = gender
student = Student("小明",15,"男")
with open("d:\\pycharm\\pythonProject1\\data.txt","wb") as p:
pickle.dumps(student,p)
执行这个例子会生成文件data.txt,这个文件包含了代码中student对象的信息,打开这个文件就可以看到一堆看不懂的内容:
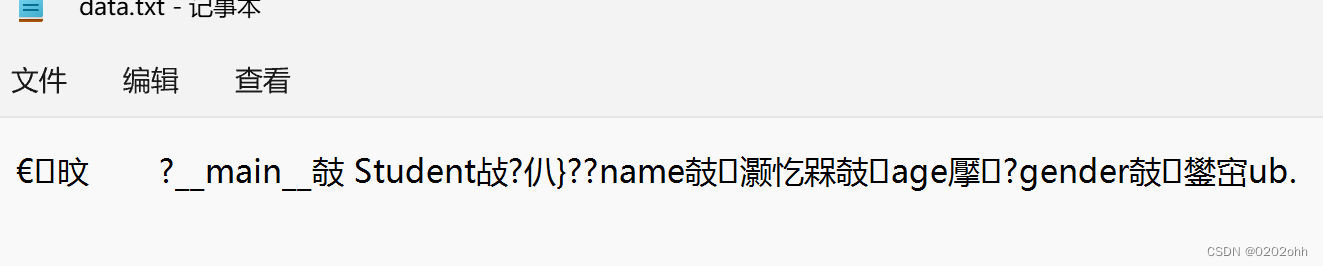
既然已经将序列化的内容保存到文件中了,在使用文件时自然也可以把对象从磁盘读取到内存中。我们可以先把内容读取到一个bytes对象中,然后使用pickle.loads方法获取反序列化后的对象,例如👇:
import pickle
class Student:
def __init__(self,name,age,gender):
self.name = name
self.age = age
self.gender = gender
p = open("data.txt","rb")
data = p.read()
student = pickle.loads(data)
p.close()
print(student.name)
print(student.age)
print(student.gender)
#小明
#15
#男
可以看出,student对象被正确地读取出来并加载到变量中(注意:类定义不能省略)。
❗️:pickle的序列化和反序列化只能用于python而不能被其它语言读取,并且不同版本的python中间也可能存在兼容性问题。
为了解决这个问题,python中内置了JSON模块,也可以用于序列化和反序列化。
☁️ JSON模块
JSON(JavaScript Object Notation)是一种轻量级的数据交换格式,易于阅读和编写,也易于及其解析和生成。它是基于JavaScript编程语言的。
JSON建构于两种结构:
- “名称/值对”的集合。在python中对应的就是字典。
- 值的有序列表。在python中对应的就是列表。
JSON类型和python类型转换对照表如下:
| JSON类型 | python类型 |
|---|---|
| object | dict |
| array | list |
| string | str |
| number(int) | int |
| number(real) | float |
| true | True |
| false | False |
| null | None |
json模块的序列化使用方法和pickle模块一摸一样,但是pickle可以序列化任意python对象,而json模块只能序列化某些特定的类型。
使用json模块序列化字典:
import json
student = {
"name" : "小明",
"age" : 15,
"gender" : "男"
}
print(json.dumps(student))
#{"name": "\u5c0f\u660e", "age": 15, "gender": "\u7537"}
和pickle模块一样,json模块也可以直接写入文件对象,例如:
import json
student = {
"name" : "小明",
"age" : 15,
"gender" : "男"
}
with open("ccc.txt","w") as p:
json.dump(student,p)
这时,我们打开该源文件所在目录,就会发现已经创建好的文本“ccc.txt”:

再打开这个文本文档:
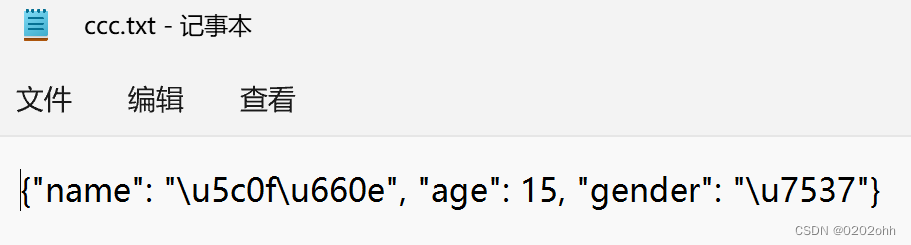
使用json模块反序列化的使用方法和pickle模块也是一样的,但是要需要注意的是❗️:json反序列化只能应用在使用json序列化的数据上,不能反序列化pickle模块序列化后的bytes数据。例如:
import json
p = open("ccc.txt","r")
a = json.loads(p.read())
print(a)
#{'name': '小明', 'age': 15, 'gender': '男'}
最后,再注意一下json和pickle的区别:json模块的特点是各种语言都支持json格式的数据,没有兼容性问题,但是json模块只能序列化部分类型的数据;而pickle模块可以序列化大部分的python对象,但是只有python支持对pickle模块序列化后的数据进行反序列化。















 261
261











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









