






WeClone 是一个开放源码项目,能通过个人微信聊天记录微调大语言模型(LLM),并结合声音克隆技术,让你的“数字分身”不仅“说你的话”,还能“听你的声”。自 2024 年上线以来,项目迅速积累了 4.6k⭐、350🍴,并入选 HelloGitHub 月度榜单,当前最新版本 v0.2.2(2025-05-08 发布)已为更大规模训练和多卡并行做好准备。

一、项目背景与意义
随着 ChatGPT 等通用大模型的普及,如何让 AI 理解并还原个人风格成为新的挑战。通用模型输出往往缺乏个性化色彩,而 WeClone 则通过对微信聊天记录和语音进行微调,使模型在问答、对话中高度贴合用户原有语气与用词习惯。同时,声音克隆模块可在无需额外录音设备的情况下,实现高保真的声纹复现,为数字分身增添更多真实感。
二、核心功能一览
-
全链路数字分身
-
聊天记录导出(SQLite/CSV)→ 数据预处理 → LoRA 微调 → 多平台部署
-
支持隐私过滤、文本清洗、对话分段等,确保数据安全与格式规范
-
-
个性化模型微调
-
集成 LoRA 轻量化适配器,兼容 0.5B–7B 各规模模型
-
单卡/多卡训练可选,显存需求最低 16 GB,超参可定制
-
项目默认使用Qwen2.5-7B-Instruct模型,LoRA方法对sft阶段微调,大约需要16GB显存。也可以使用LLaMA Factory支持的其他模型和方法。
需要显存的估算值:
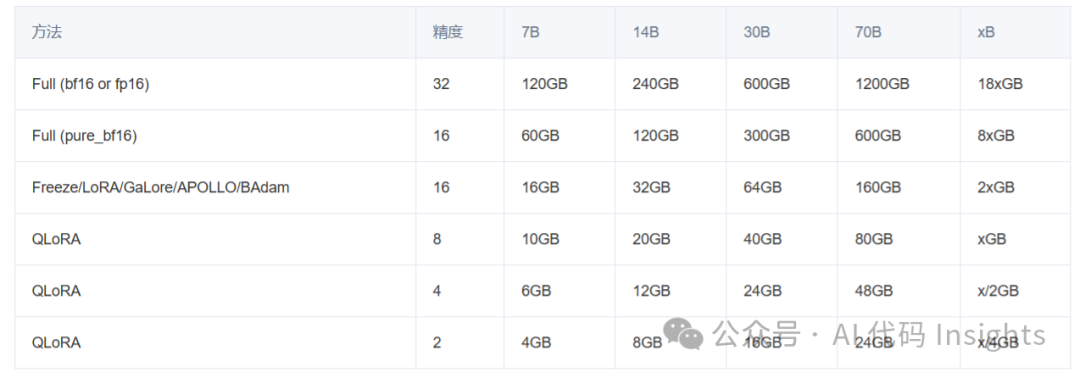
-
模型微调:集成 LoRA 轻量化微调框架,兼容主流 0.5B–7B 规模模型,显存需求可控,训练效率高;可自定义学习率、批大小与训练轮数,满足小样本低资源场景
-
声音克隆
-
基于微信语音消息训练 0.5B 参数 TTS 模型
-
端到端复制声纹、语速与语调,无需额外麦克风或录音设备
-
-
多平台无缝对接
-
一套 API + Bot 脚本支持微信、QQ、Telegram、企业微信、飞书
-
快速一行命令启动机器人,即可与数字分身实时对话
-
三、技术架构剖析
1. 数据层
-
导出与转换
-
csv_to_json.py:将微信导出的 CSV/SQLite 文件转为标准 JSON
-
-
预处理管道
-
文本清洗:去除噪声、敏感信息过滤
-
对话切分:保留时间戳、分段标注
-
2. 训练层
-
LoRA 微调框架
-
低秩适配器显著减少可训练参数
-
单机/分布式训练兼容,多卡 OOM 问题正在社区协作中优化
-
-
超参管理
-
ds_config.json提供示例配置 -
可结合 Hydra、Kubernetes 实现大规模训练编排
-
3. 部署层
-
API 服务化
-
基于 FastAPI/Flask 封装微调模型
-
支持 GPU/CPU 混合部署,兼容 OpenAI 标准接口
-
-
Bot 接入模块
-
weclone_bot.py:封装多平台登录、消息收发逻辑 -
一行命令即可启动,支持自定义参数
-
四、快速上手指南(四步走)
-
导出与转换聊天记录
python csv_to_json.py \ --input chat.csv \ --output chat.json -
预处理与配置
# 修改 settings.template.jsonc,定义隐私词典与截断规则 python preprocess.py \ --config settings.jsonc \ --data chat.json -
模型微调
# 编辑 ds_config.json,指定模型、学习率、训练轮次 accelerate launch train.py --config ds_config.json -
部署与对接机器人
# 启动 API 服务 uvicorn app:app --host 0.0.0.0 --port 8000 # 启动微信机器人 python weclone_bot.py \ --platform wechat \ --api-url http://localhost:8000
五、典型应用场景
-
智能个人助理:自动回复微信消息、生成邮件草稿、撰写会议纪要
-
高颜值客服机器人:模拟品牌语气,提升用户满意度
-
纪念与传承:为亲友或已故长辈构建对话模型,保存珍贵回忆
-
内容创作利器:快速产出个性化文章、脚本、视频解说
六、社区生态与未来路线
-
社区活力:4.6k⭐、350🍴、活跃 Issue 区与 PR 流,持续迭代文档与功能
-
发展规划:
-
多模态融合——结合视觉、表情与情感识别
-
方言与多语言支持——扩展更多语种与地方话
-
轻量化前端——推出手机端/Web 小程序,一键体验
-
隐私合规——引入联邦学习与差分隐私,强化数据安全
-


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









