









Hadoop两大核心:HDFS和MapReduce
Hadoop的特性:
1.高可靠性:多台机器构成集群,部分机器故障,剩余机器可以继续对外提供服务
2.高效率:成百上千台机器一起计算
3.高扩展性:可以不断地向集群中加入机器
4.低成本:可以常用普通PC机来构成一个集群
Hadoop应用现状:

Hadoop项目结构:

Tez:运行在YARN之上的下一代Hadoop查询处理框架,将很多MapReduce文件分析优化后构成有向无环图
Spark:基于存储处理的类似于Hadoop,MaprReduce的通用并行框架
Hive:Hadoop上的数据仓库,把SQL语句转换成MapReduce作业
Pig:数据流处理,一个基于Hadoop的大规模数据分析平台,提供类似SQL的查询语言Pig Latin
Oozie:Hadoop上的工作流管理系统
Zookeeper:提供分布式协调一致性服务
HBase:Hadoop上的非关系类型的分布式数据库
Flume:一个高可用,高可靠的分布式的海量日志采集,聚合和传输的系统
Sqoop:数据导入导出,用于Hadoop与传统数据库之间进行数据传递
Ambari:Hadoop快速部署工具,支持Apache Hadoop集群的供应,管理和监控
Hadoop集群的部署和使用:
Hadoop的两大核心是HDFS和MapReduce,所以对Hadoop进行配置的时候无非就是照顾到这两方面的性能。
一.主要的集群硬件配置:
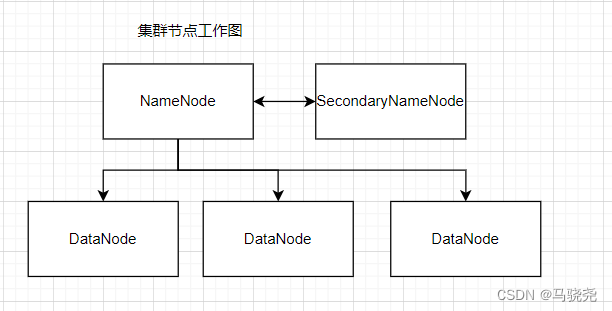
1.NameNode:名称节点(HFDS),用来存储数据的存储地址
2.DataNode:数据节点(HFDS),用来存储数据
二.MapReduce核心:

JobTracker:对整个用户的作业进行管理,把一个大的作业发放到不同的集群上进行
TaskTracy:负责跟踪和分配各自的作业
三.冷备份SecondayNameNode:
















 619
619











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











