






1. 大数据启蒙
学习视频
大数据多,复杂度很重要,
- 内存不够,分治处理
- IO仍成为瓶颈,多机器并行
- 多机器间通信也可以并行,但仍是个问题
- 分发上传,累计计算的话,多台同时跑+通信也比一台快
总结(大数据的重点)
- 分而治之
- 并行计算
- 计算向数据移动:数据移动化成本高
- 数据本地化读取
1.1 意义
1.1.1 查找元素
1w个元素中查找X?
线性查找:O(N)
想要O(4)呢?hash
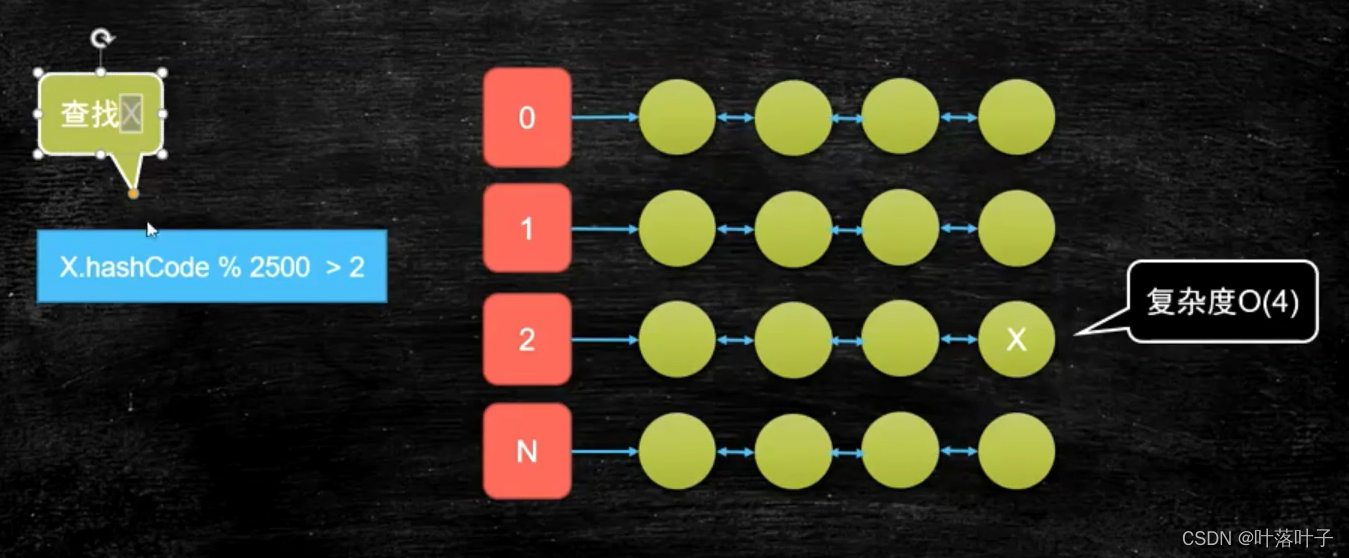
1.1.2 单机处理大数据问题
大文本,仅两行一样,想要找出。
单机,内存小(几十兆)

2. 如果文件中全是数字,做排序呢?
桶排序:外部有序,内部无序
先分到不同桶里,再给桶内排序
归并:一次读50M排序,第二次在读50M对这个50M排序–外部无序,内部无序
单机IO瓶颈,所以多机器并行
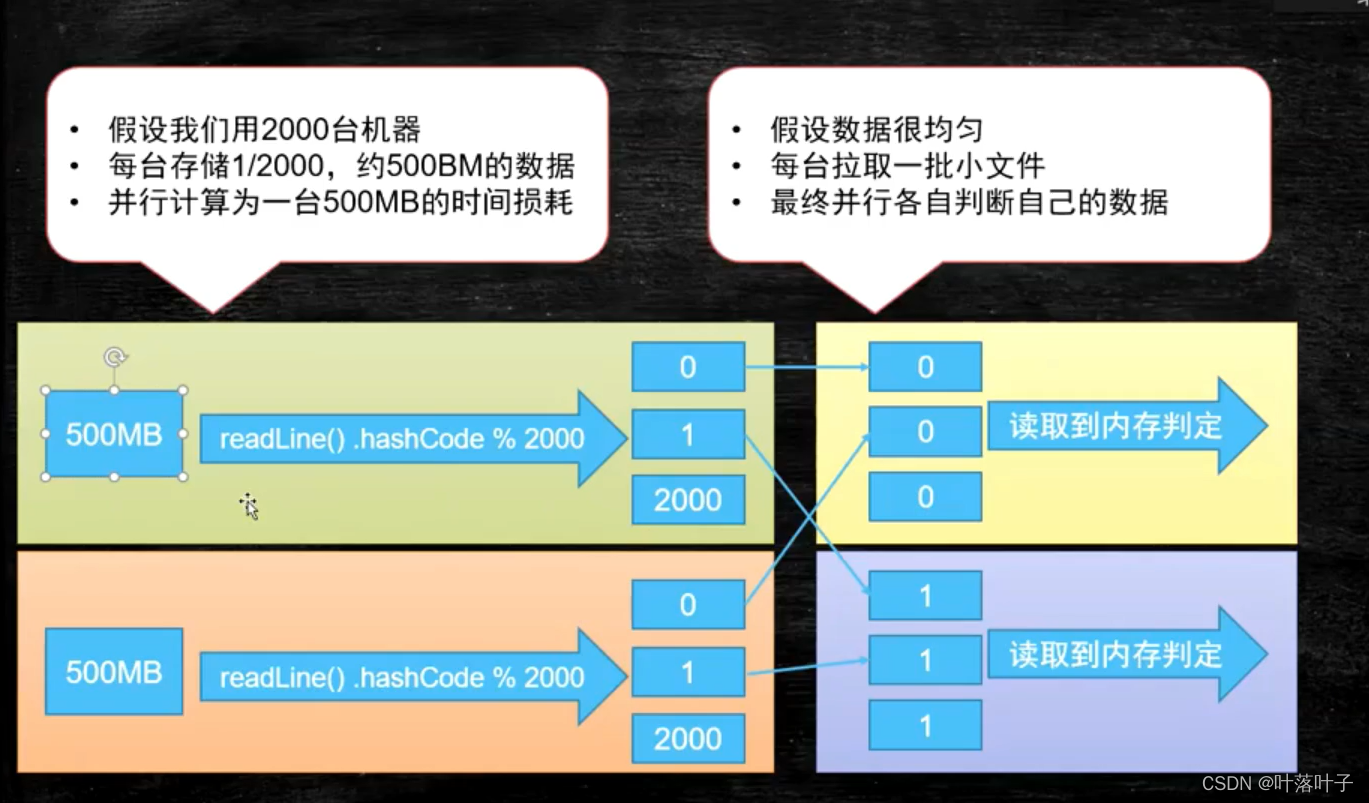
多台机器并行操作,处理速度快,但不同机器间网络通信?
1.2 历史
Hadoop
NDFS(一开始的文件系统)
hadoop.apache.org:顶级项目
1.3 hadoop
hadoop项目包含:
1.x:
hadoop common
hdfs(hadoop distributed file system
hadoop mapreduce
2.x:
新增yarn:job管理、资源分配
其他相关项目(生态圈):
Hbase:
Hive:sql、数仓
Spark:用内存,更快,是hadoop的十倍
Zookeeper:协调服务
…

网站:www.cloudera.com
ducumentation:选择版本
目前企业版本:5.16.X–可靠,hadoop2.6
原来:batch批量计算
flink/spark:全栈的
- flink:阿里用的多:流式计算,来一个搞一个/5min跑一次
- 可以实时
- spark:伪实时














 1733
1733











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









