






首先去GitHub上下载好YOLOv5这个项目,内容如下:
其中,detect.py是用来检测的,也就是运行yolo实现目标检测,其中有许多的参数可以进行设置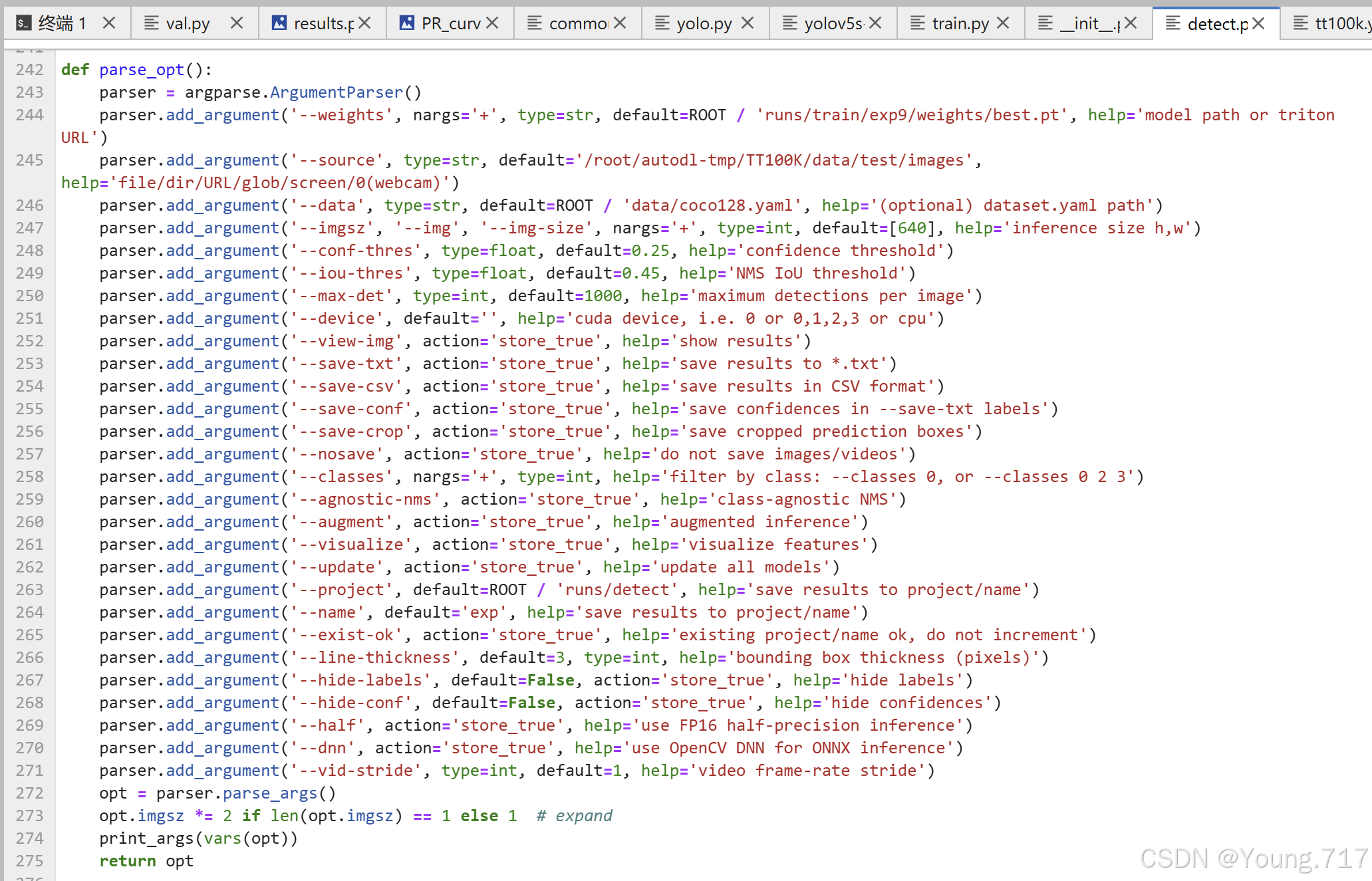 其中较为重要的参数,我来简单说明一下:
其中较为重要的参数,我来简单说明一下:
--weight 这里指定的模型的参数选择,在github上下好的里面有多个模型参数,点开model下面,可以看到有很多yaml配置文件,里面就记录着不同参数量的yolo模型,其中用的最多的就是yolov5s.yaml,因为v5s是最轻量的,同样也是大家用得比较多的。(这里已经是我训练好的参数了,所以和大家自己直接下载后的源代码有些差别)
--source 这里就是要进行yolo处理的数据了,看后面的help可知,yolo支持的格式有jpg,png,文件夹,视频,还有自己本地电脑的摄像头(这里default=0就可以了)
之后,就是train.py文件,这个文件就是自己选择数据集,之后进行训练的py文件。
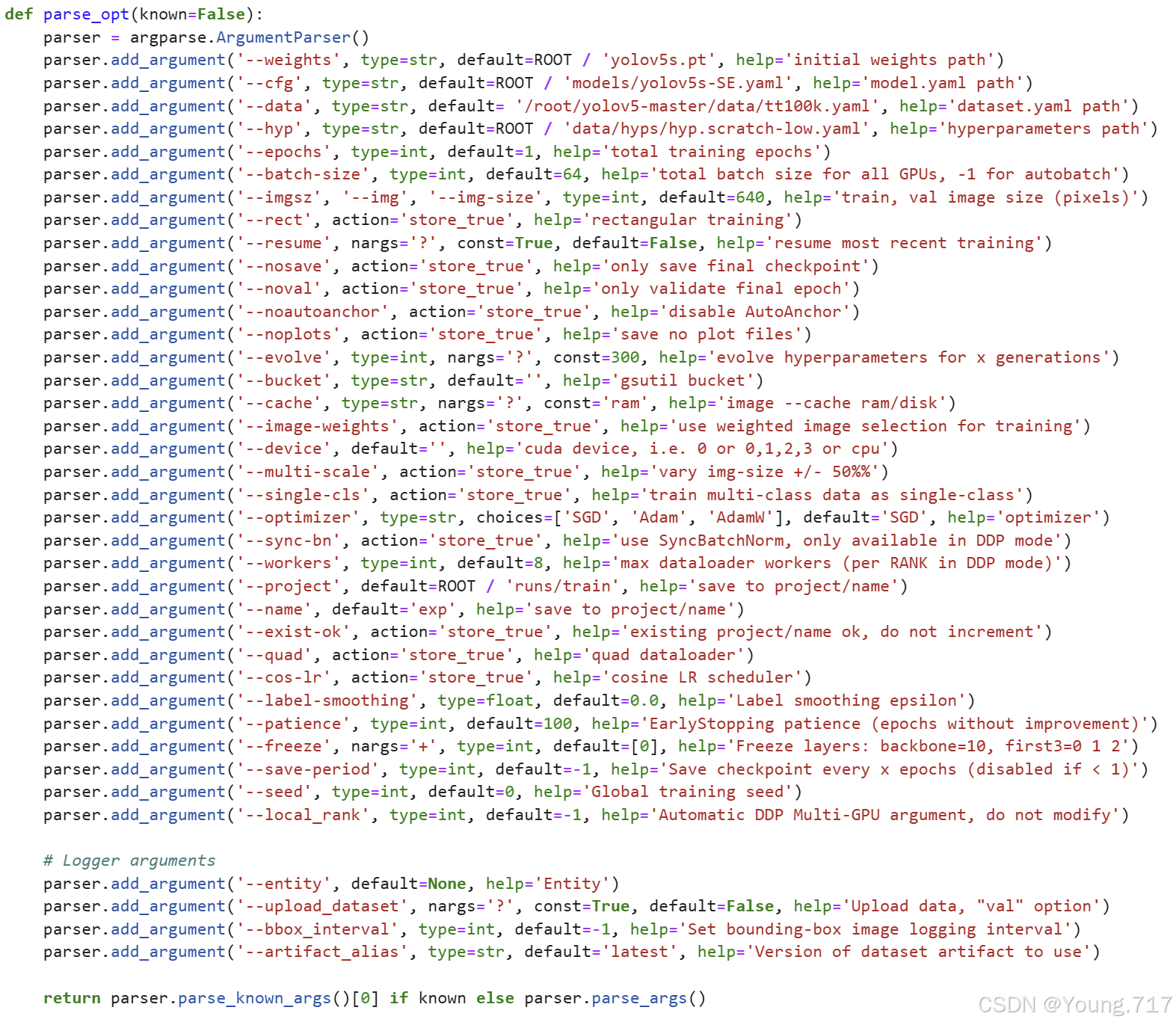
也是说一些关键一点的参数:
--weight 这里是初始化模型参数,在这个参数基础上进行训练,也就是加载预训练参数(这里其实我有点迷糊,因为我训练完之后发现,yolo并不认得以前的图片了,只认得这些新训练的图片)。这里我的感觉是,仅仅是加速了模型的训练速度,因为前面提取特种用的卷积层们,他们的特征提取能力以及可以了,所以有利于在此基础上训练。之后就是我的一点猜想,会不会也会因此获得一组较好的初始化参数,从而容易找到那个最优解。
--cfg 就是配置文件,这里是去model下面的记录了网络结构的yaml文件中去选择,和你上面选择的那个参数配套就好。
--data 这里是选择那个记录了数据的yaml文件,里面有训练数据存放的位置,以及yolo格式的类别。
--hpy 就是超参数配置文件,我觉得不用调整,里面是原作者炼丹时候感觉最好的组合了吧。
--epochs 训练轮次,建议根据你自己的数据集来做调整,像我这个超大tt100k,我训了300轮还是没收敛,打算再加大剂量。
--batch_size 批量大小,根据自己gpu显存来。这里只是影响一下训练时间长短。
--imgsz 是指输入图片的大小,yolo在加载图片的那个transform里,调整大小
--patience 这个一般结合着epoch来用,意思是说,多少轮参数不变了,就停止训练。所以可以设置很大的epoch,再用patience来找啥时候算是收敛。
接下来介绍下,tt100k数据集,https://cg.cs.tsinghua.edu.cn/traffic-sign/
这个是清华那个官方的连接,里面可以自己选择版本(版本选择要清楚,因为要搞清楚有几类,label很重要)。或者点击那个“教程”,里面有直接可以用的Linux命令。

下载之后应该是这样的:
里面是清一色的jpg格式,而yolo格式是要jpg和txt格式来对应的,所以就要转化一下。(至于代码,我代码能力比较弱,所以我就自己csdn去copy了一个,稍微改下路径就能用了,我就不明摆出来了)
之后那个代码是转成了jpg+txt格式,需要分开的,也就是images和label要分开的(这里必须叫images和labels,因为yolo内部代码实现路径就是这样的,改了会报错的),成这样才是yolo格式
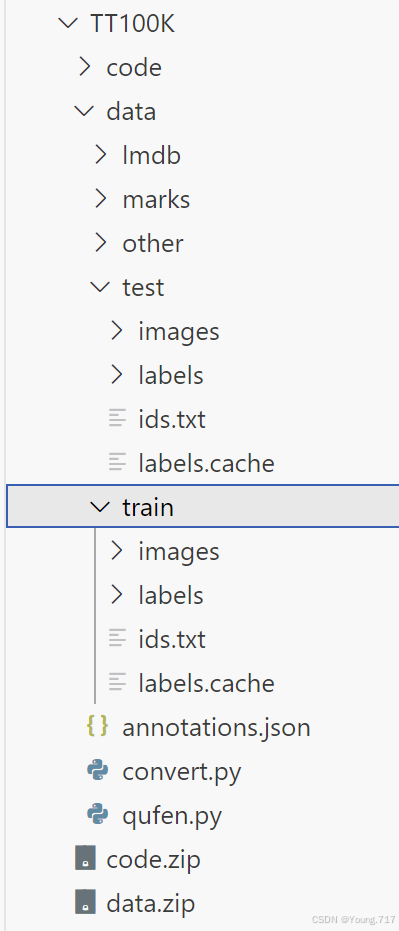
这个分类代码,找AI一写就出来了,很简单的。(下面是我用ai写的)
import os
import shutil
# 指定的目录
source_dir = './test'
# 目标文件夹
images_dir = './test/images'
labels_dir = './test/labels'
# 如果文件夹不存在,创建它们
if not os.path.exists(images_dir):
os.makedirs(images_dir)
if not os.path.exists(labels_dir):
os.makedirs(labels_dir)
# 遍历源目录下的文件
for filename in os.listdir(source_dir):
file_path = os.path.join(source_dir, filename)
# 如果是文件,进行分类移动
if os.path.isfile(file_path):
if filename.endswith('.jpg'):
shutil.move(file_path, os.path.join(images_dir, filename))
elif filename.endswith('.txt'):
shutil.move(file_path, os.path.join(labels_dir, filename))
print("文件移动完成!")
之后还差最后一步,就是写一个data的yaml文件就行了。

之后路径都在train.py的参数部分相应填好,就可以开始运行了。
我是用3090跑了整整一晚上,我看是晚上6点开始,早上7点才跑完。
之后可以去runs/train里看想要的结果就可以了。
至此,这个tt100k的数据集训练就算是跑通了。

















 7534
7534

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









