








一、什么是Q—learning?
概述:Q-Learning通过模拟儿童在面对不同选择时的学习过程,如完成作业与看电视,来说明算法如何通过不断试错和学习,建立一个Q表以预测特定状态下执行各种行为的潜在奖励。这个算法的核心在于不断更新Q表,以优化决策,目标是在给定情境下选择最优行为。讨论还涵盖了Q-Learning中的两个关键参数:学习效率(阿尔法)和未来奖励的衰减值(伽马),强调了它们对算法决策质量的影响。
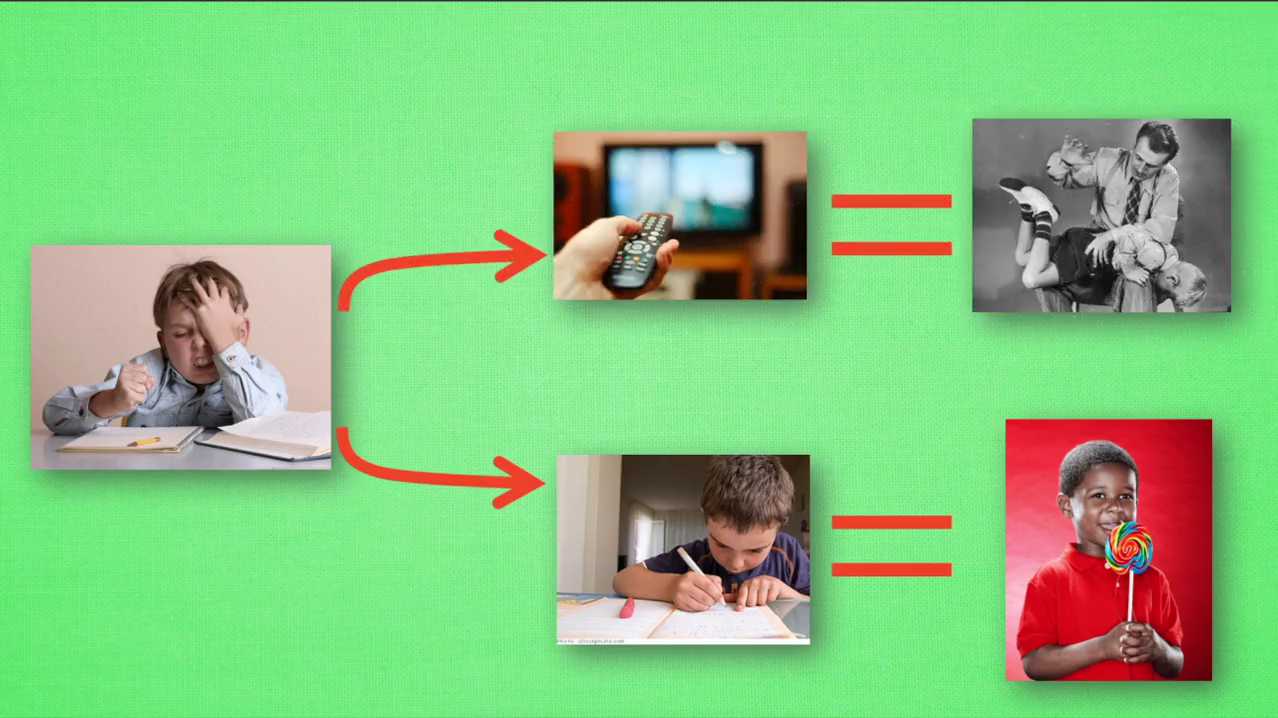
Q—learning也是一个决策过程,和小时候的这种情况差不多。我们举例说明,假设现在我们处于写作业的状态,而且我们以前并没有尝试过写作业的时候看电视。所以现在我们有两种选择,一继续写作业,二跑去看电视。因为之前没有被处罚过,所以我选择了看电视。然后现在的状态变成了看电视,我又选择了继续看电视,接着还是看电视。最后爸妈回家发现我没有写完作业就去看电视,狠狠的处罚了我一次,我也深刻的记下了这一次经历,并在我的脑海中将没有写完作业看电视这种行为更改为负面行为。
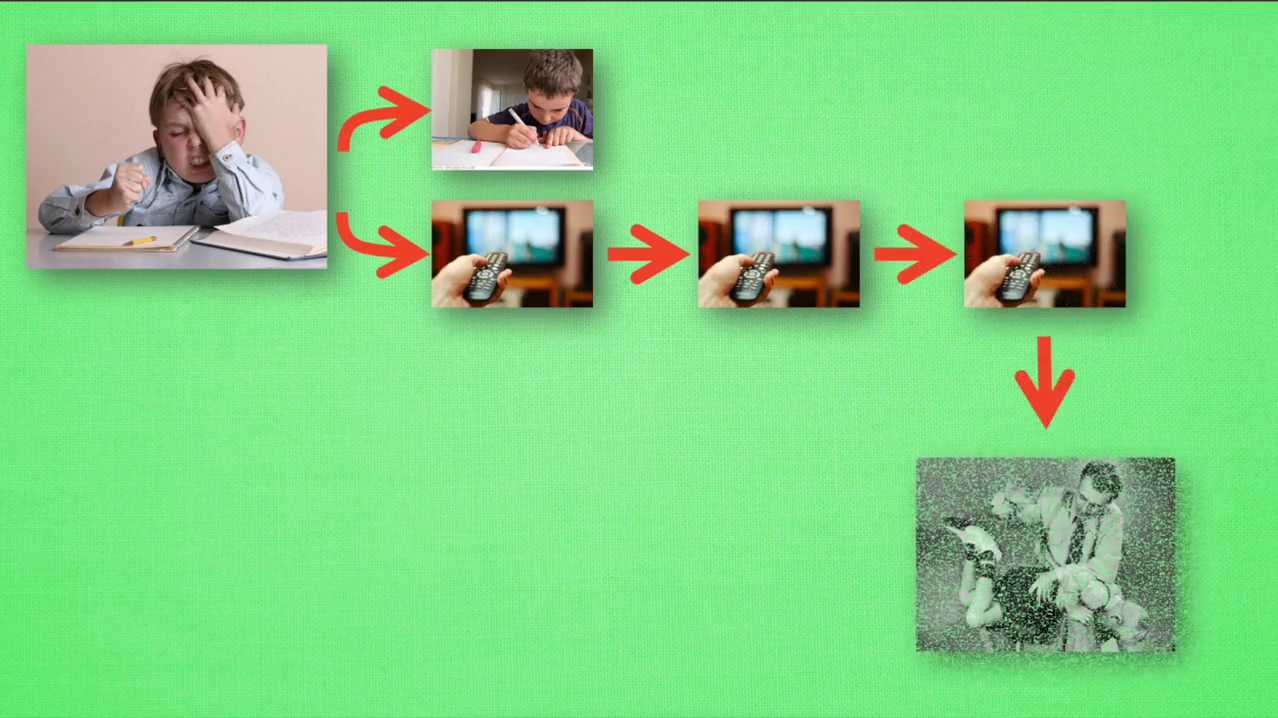
我们再看看q learning根据很多这样的经历是如何决策的吧。假设我们的行为准则已经学习好了,现在我们处于状态。S一我在写作业,我有两个行为,A一和A二分别是看电视和写作业。根据我的经验,在这种S一的状态下,A2写作业带来的潜在奖励要比A一看电视要高。这里的潜在奖励我们可以用一个有关于S和A的Q表来代替。在我的记忆Q表格中,QS1A1等于负二要小于QSEA2等于1,所以我们判断要选择A二作为下一个行为。
现在我们的状态更新为S2,我们还是有两个同样的选择,重复上面的过程。在行为准则Q表中选择QS2A1、QS2A2的值,并选择较大的一个。接着根据较大的A2我们到达了S3,并再次重复上面的决策过程。Q learning的方法也就这样决策的看完决策,我们的研究一下这张行为准则Q表是通过什么样的方式更新提升的。所以我们回到之前的流程,根据Q表的估计,现在在S一中A2的值比较大,通过之前的决策方法,我们会在S一采取A2的行动并且到达S2。这时我们开始更新用于决策的Q表。接着我们并没有在实际中采取任何行动,而只是在想象自己在S2上采取的每种行动,分别看看两种行为哪一个的Q值比大。比如说QSRAR的比QS2A1的值要大,所以我们会把大的QS2A2乘上一个衰减值伽马,比如说0.9并加上到达S2时所获得的奖励。

这里还没有获取到我们的棒棒糖,所以奖励为零,因为会获取实实在在的奖励R我们将这一次作为我们现实中的QSEAR的值,但是我们之前是根据Q表估计了QSEAR的值,所以有了现实和估计值,我们就能更新QSEAR,根据估计与现实的差距,将这个差距乘以一个学习效率,阿尔法累加上老的QSEAR的值变成新的值。但时刻记住,我们虽然用了max QSR来估计下一个SR的状态,但还没有在状态SR做出任何的行为。SR的决策部分要等到更新完了以后再重新另外做,这就是off policy的那你是如何决策和学习优化决策的过程?
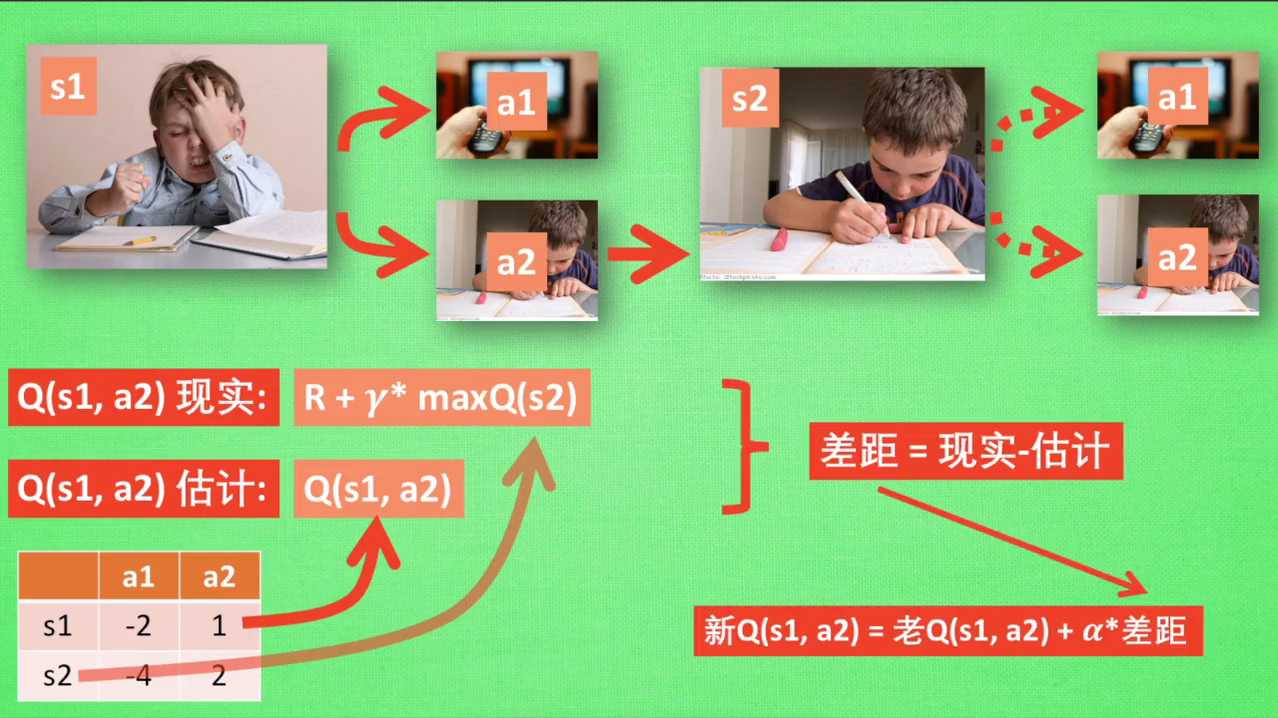 R的现实中也包含了一个QS2的最大估计,将对下一步衰减的最大估计和当前所获得的奖励当成这一步的现实,很奇妙。
R的现实中也包含了一个QS2的最大估计,将对下一步衰减的最大估计和当前所获得的奖励当成这一步的现实,很奇妙。

如果伽马从零变到1,眼睛的度数由浅变深,对远处的价值看得越清楚,所以机器人渐渐变得有远见,不仅仅只看到眼前的利益,也为自己的未来着想。

二、简单的学习例子
概述:介绍了强化学习中的Q学习算法,通过一个虚拟探索者寻找宝藏的例子进行说明。演示了探索者如何从随机行动逐渐学习到最优策略,最终用更少的步骤找到宝藏的过程。首先构建Q表并设定环境,然后通过选择动作、更新Q表等步骤,实现了算法的训练。特别强调了10%的随机探索对学习路径的影响。
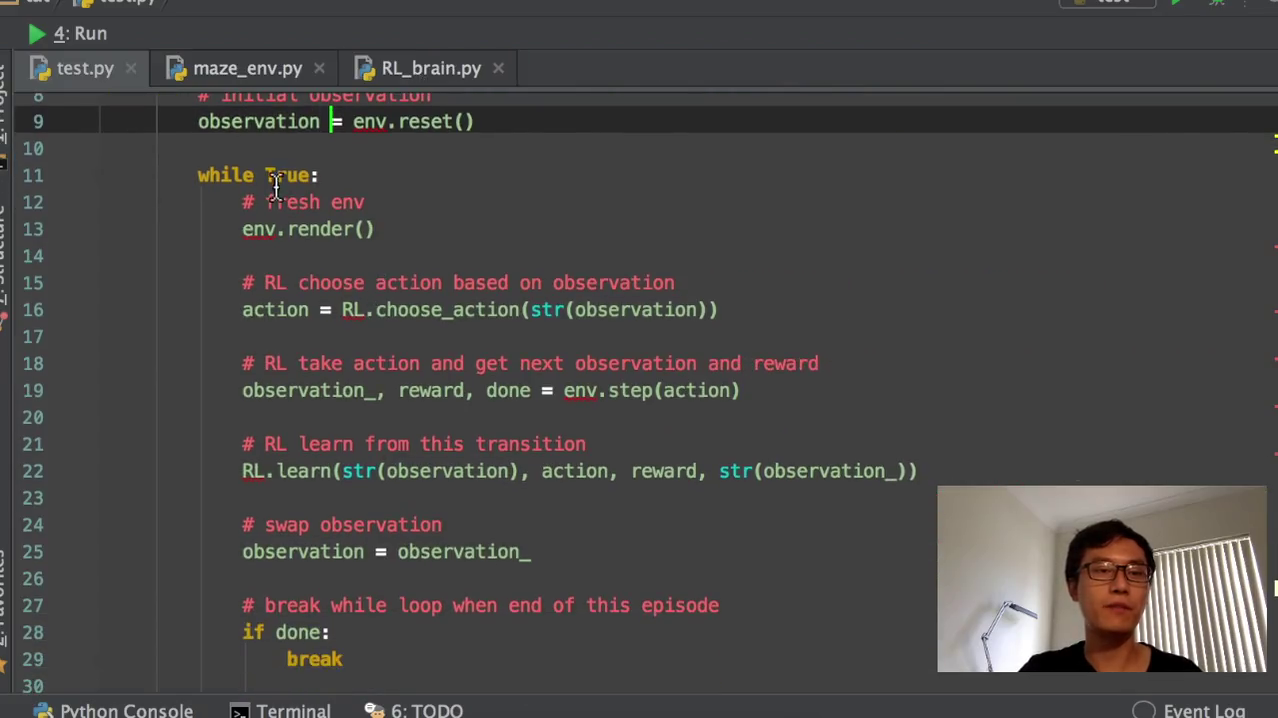
这次我们会用一个超级简单的例子来介绍一下这个reinforcement等等强化学习中间的一个非常好用的一个算法,叫做Q2O。这一次我先给大家看一下这一次的效果,这一次的效果就是这样的一个东西。你看它这个T就是我们的宝藏所在的位置,这个O是我们一个探索者,探索者在一步一步的尝试怎么样去得到保障。你看第一次我们花了三十多步来找到这个宝藏,因为他什么都不知道,他也不知道这个宝藏是对他好的还是对他不好的,所以他在一次一次尝试。第二次我们画了28步,第三次我们只画了六步,就说明他不断的在学习,怎么样很快速的去拿到这个保障。通过不断的这样的尝试,它就越来越快。这个就是使用q learning这个算法实现的这个功能。

首先我们会要有一个q table,也就是Q的表格,就把所有的state就是我们的状态对应上我们的action,对应上我们的动作。然后每个状态每个动作都会有一个Q值,那我们就通过这个Q值来判断在哪一个固定的state选取哪个动作。那我们就要建立一个Q表,我们也要创建一个选择动作的一个功能,选择工动作的功能完了以后,我们我们还要创建一个environment,也就是创建一个环境。这个环境也就是我们刚刚看到的探索者怎么去拿到保障的这个环境,也就是一条直线的环境。这个环境不是我们这一系列课程的主要的主要要讲的东西。因为环境编写起来特别的复杂,所以我们不会讲环境是如何编写的。大家如果有兴趣可以去看一下代码中间的环境是怎么样编写的。
(1)代码阐述
1)首先我们要import三个模块,是numpy和pandas,都是用于数据处理。这个time的模块就是用来控制我们这个探索者他移动速度有多快。现在如果你想达到跟我视频中是一样的效果,你可能就要用到这个random seed。Random seed就是说计算机产生一组伪随机数列,它虽然是随机的,但是每次你运行的时候,它的随机过程都是一样的。所以你就能能看到跟我视频当中一样的这种效果。
2)再就要开始创建几个global variables。Global variable就是说我这些参数都是固定的。比如说我有多少个state,有多少种状态,也就是我想最开始的距离离这个宝藏的距离有多少步,那我这里就是有六步的距离。然后探索者他有两个可以选的动作,一个是走左边,一个是走右边。因为它是一条一维的线,那它要不就走左边,要不就走右边。然后这个APP就是我们之前讲到的这个actually on gradation,是我们这边actual grade。也就是在我们选择动作的时候,有一个90%的时候我们选择最优的动作,10%的时候我们选择这个随机的动作,这就是actual。
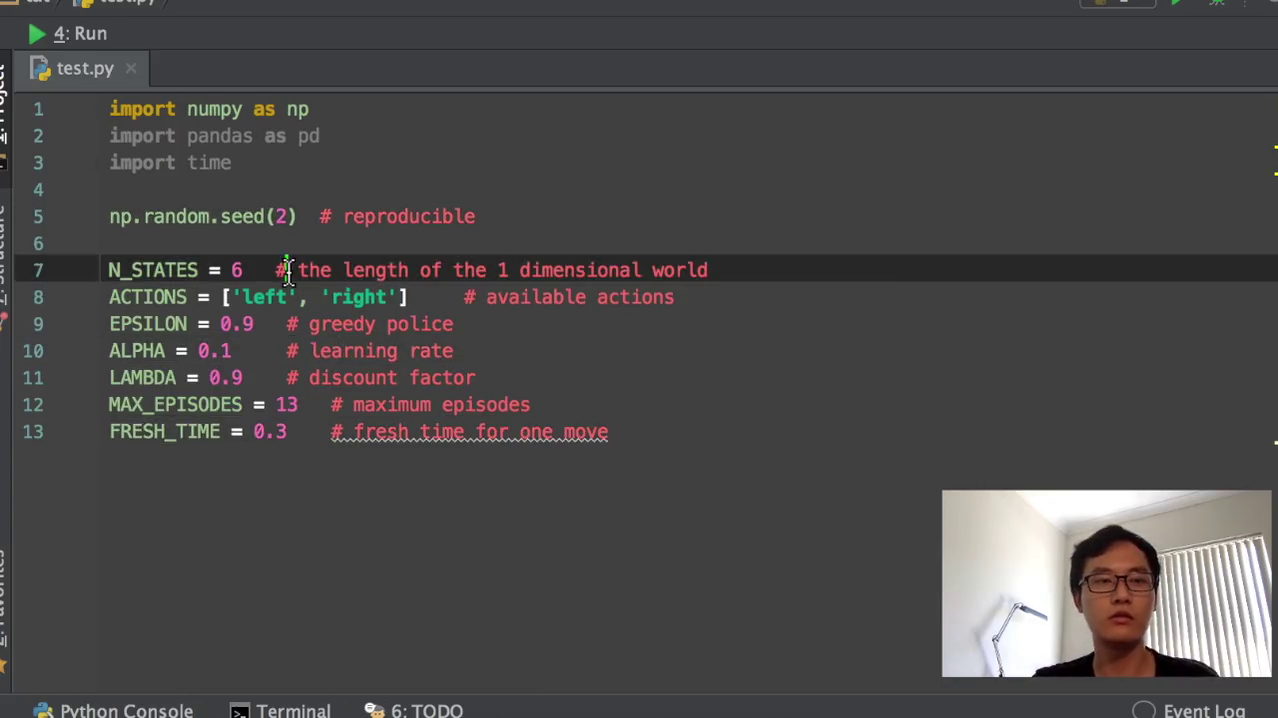
然后阿尔法就是我们的learning rate,0.1的learning rate学习效率。Nmda就是我们的这个递减就是衰减度,也就是对于未来的这个reward,就是就叫奖励了未来的奖励的一个衰减值。然后这个maximum episodes就是说我只玩13回合,因为13回合他已经能训练的非常好。然后这个fresh time就是我规定的用这个time模块规定我的花走一步花的时间有多长。0.3秒走一步,那就是为了更清楚的看到我走步的这个效果。如果你想让它走慢一点,你就把它变成一秒间隔一秒走一步,间隔两秒走一步都可以。
3)然后我们就开始建立我们的q table。首先初始化的时候,我们以全零初始化。然后它的color就是我们用到这个pandas来创建一个表格。为了看一下效果,我们就开我们就直接纵轴就是我的state,就是S1、S2、S3、S4。然后我的横轴就是我的action,就是左边右边这两个action。那我们打印出来看的话,就是会变成这样。
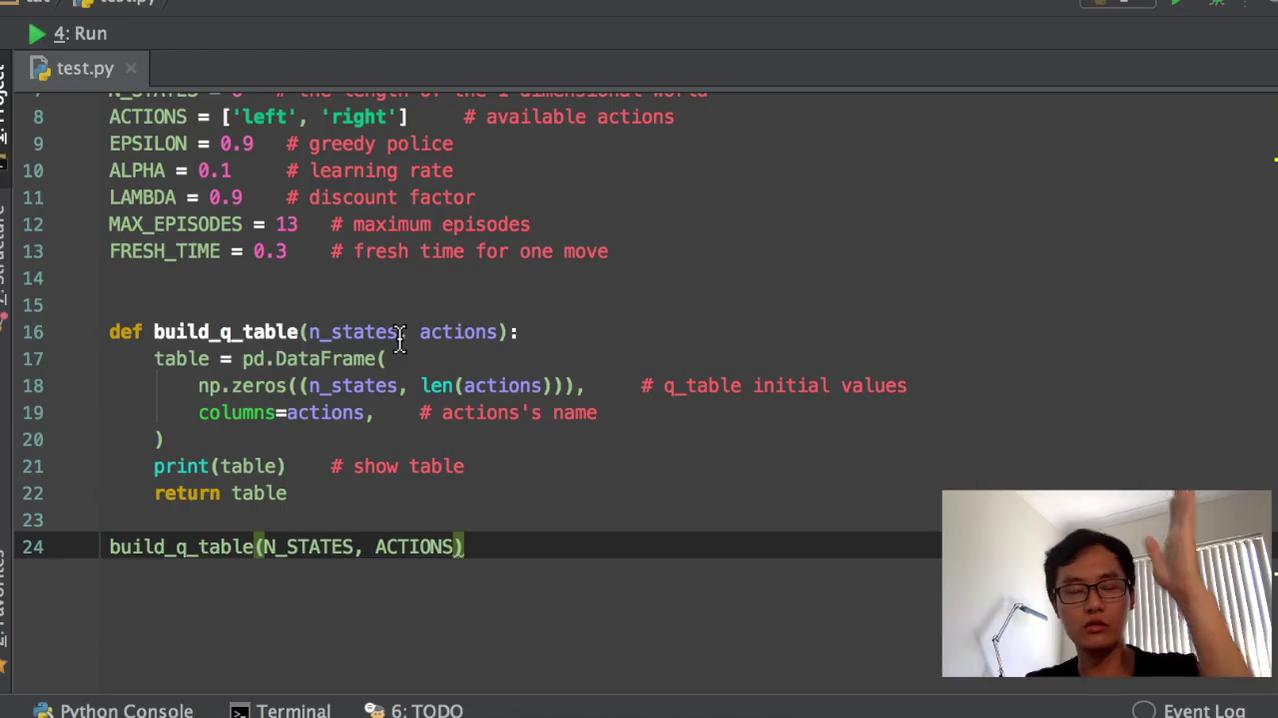 q table有两个动作,一个是向左走,一个是向右走。然后在每一个state上面,state 0 state 12345,state上面向左走向右走。目前的状况是都是相等的,它们没有任何的价值高低。他们都是初始化到零之后,我们会慢慢学习,把这些零变成其他的数,建好了一个初始化的一个q table,我们就开始初始化。我们的这个我们就创建这个趋势action的功能。我们选动作,选动作也是一个功能,这是我们最简单的一种代码形式。
q table有两个动作,一个是向左走,一个是向右走。然后在每一个state上面,state 0 state 12345,state上面向左走向右走。目前的状况是都是相等的,它们没有任何的价值高低。他们都是初始化到零之后,我们会慢慢学习,把这些零变成其他的数,建好了一个初始化的一个q table,我们就开始初始化。我们的这个我们就创建这个趋势action的功能。我们选动作,选动作也是一个功能,这是我们最简单的一种代码形式。
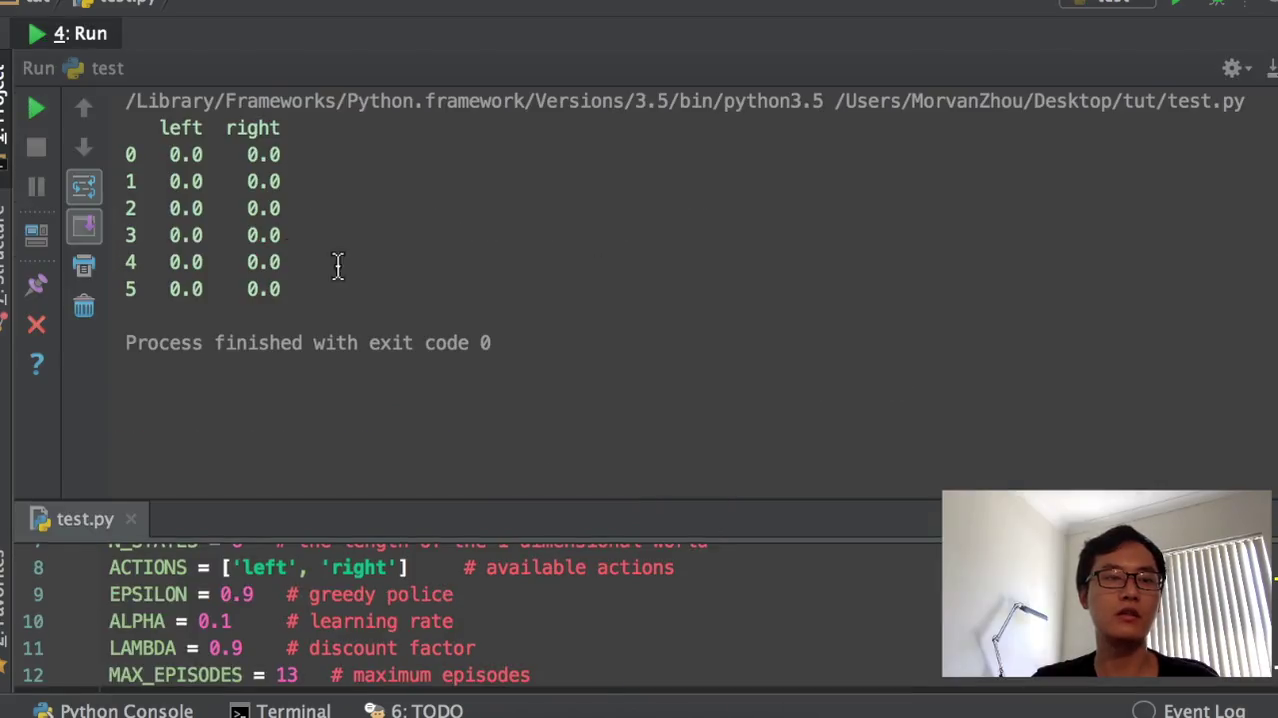 选动作选动作的时候,我们要根据所在的状态state和这个q table里面的值来选择我们现在要选的动作。百分大于0.9就是10%的情况,和就我们就随机的选择action里面的动作,actions里面的动作在这里随机的选择左或者右。那我们就是当随机这个随机数小于F1,就是小于0.9的时候,就是90%的情况,我们就选择在我们这个state action里面,也就是q table的这个state里面,选择这一个比较大的数。比如说这句话的意思就是说我比如说这个state我到了state 3到了state 3,然后把state三这一行把它赋值到state action这个地方,然后state action就再选90%的情况,state action就是三这一行,再选哪一个比较大,然后把把比较大的这个的index,就是把比较大的这个只能附到我的action name里面,然后再return action name。
选动作选动作的时候,我们要根据所在的状态state和这个q table里面的值来选择我们现在要选的动作。百分大于0.9就是10%的情况,和就我们就随机的选择action里面的动作,actions里面的动作在这里随机的选择左或者右。那我们就是当随机这个随机数小于F1,就是小于0.9的时候,就是90%的情况,我们就选择在我们这个state action里面,也就是q table的这个state里面,选择这一个比较大的数。比如说这句话的意思就是说我比如说这个state我到了state 3到了state 3,然后把state三这一行把它赋值到state action这个地方,然后state action就再选90%的情况,state action就是三这一行,再选哪一个比较大,然后把把比较大的这个的index,就是把比较大的这个只能附到我的action name里面,然后再return action name。
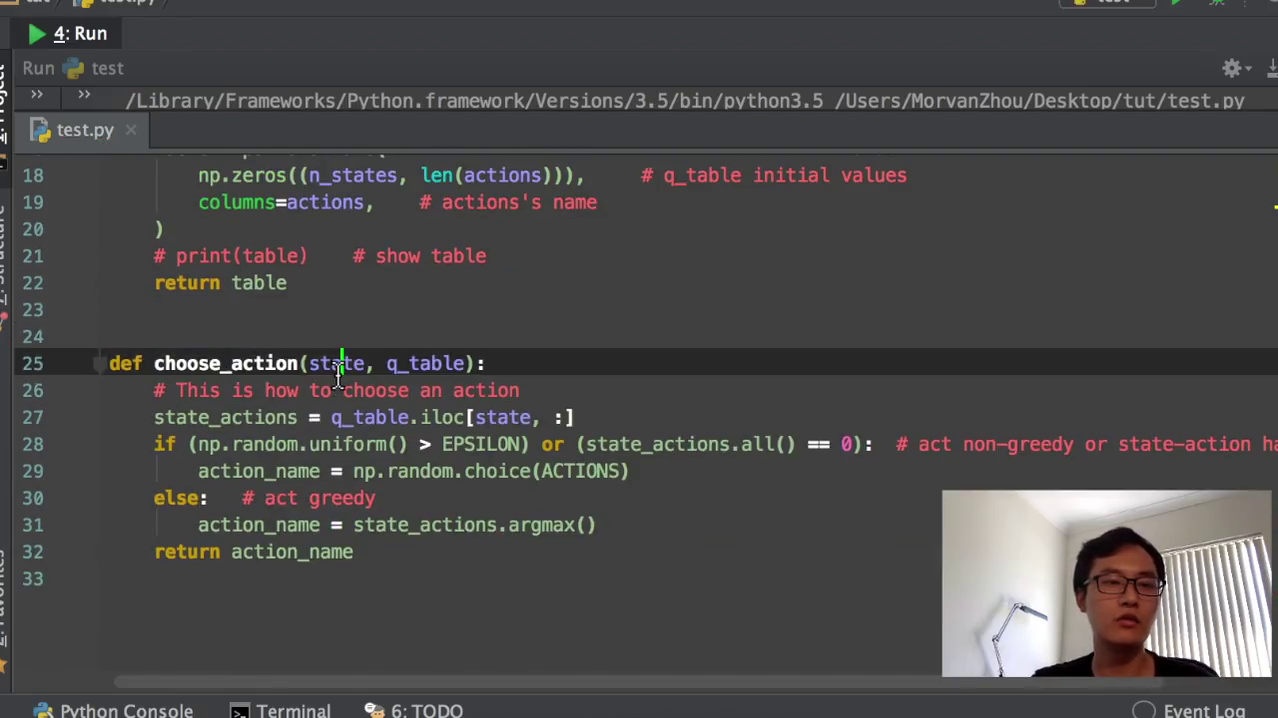 然后上面这种情况这边我就要特别讲一下,就是说我在因为初始化全部为零,那么我全部为零的这种情况,也把它变成我的这个随机的情况比较合适。这样子我就是有两个判断结构,除了这个choice action,我们还要有什么呢?我们之前不是讲过了吗?我们要创建我们的这一个环境和环境的feedback,也就是环境对我们的行为会做出什么样的反应。我现在在这个states我采取了一个行为,我会到达下一个就是S下斜杠下横杠。然后我在采取这个行动的时候,到达那个state的时候,下一个state时候,我会获得环境给我我的哪一个reward,那就是它会返回下一个state和reward。也就是这个算法当中,你看一句,如果我在这个环境这个state当中选了一个action a然后我会获得这个行为所得到的奖励,和我下一个state,就是这个功能。
然后上面这种情况这边我就要特别讲一下,就是说我在因为初始化全部为零,那么我全部为零的这种情况,也把它变成我的这个随机的情况比较合适。这样子我就是有两个判断结构,除了这个choice action,我们还要有什么呢?我们之前不是讲过了吗?我们要创建我们的这一个环境和环境的feedback,也就是环境对我们的行为会做出什么样的反应。我现在在这个states我采取了一个行为,我会到达下一个就是S下斜杠下横杠。然后我在采取这个行动的时候,到达那个state的时候,下一个state时候,我会获得环境给我我的哪一个reward,那就是它会返回下一个state和reward。也就是这个算法当中,你看一句,如果我在这个环境这个state当中选了一个action a然后我会获得这个行为所得到的奖励,和我下一个state,就是这个功能。
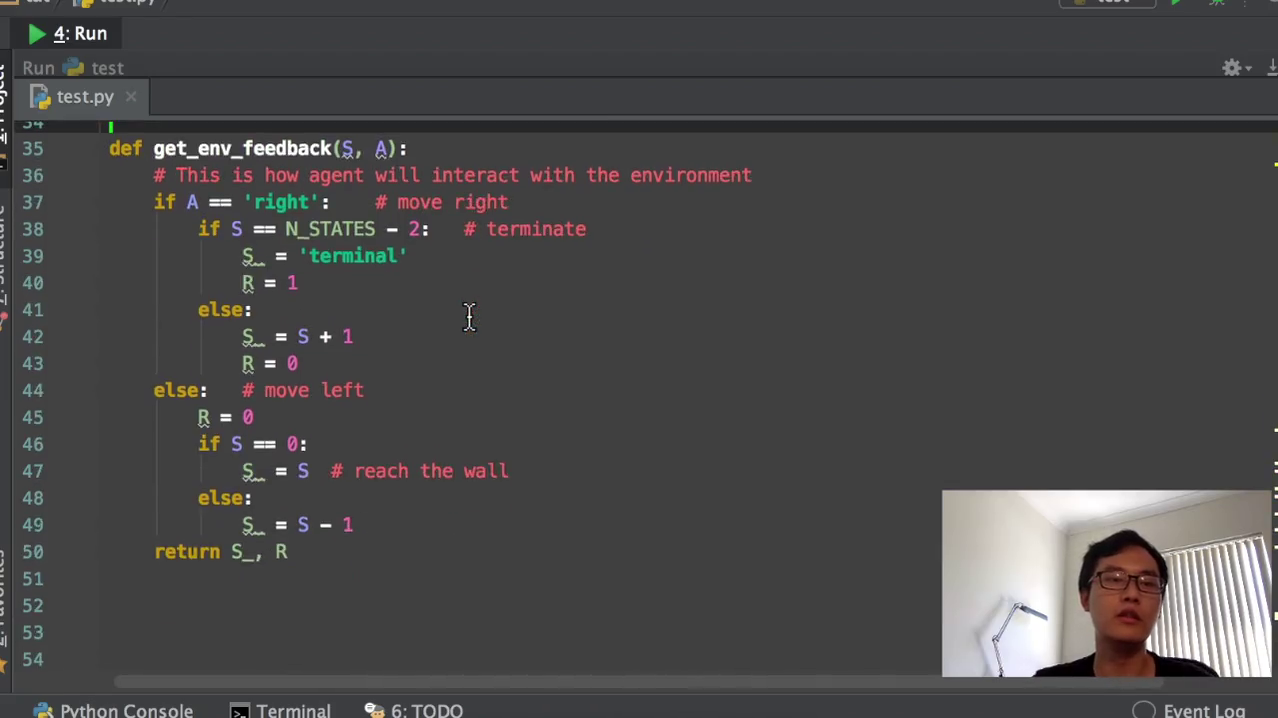 4)开始建立我们的环境。环境大家没有必要仔细看里面的代码。整个这一套环境就是在说我怎么样让这个探索者在这样的一维的环境中移动。
4)开始建立我们的环境。环境大家没有必要仔细看里面的代码。整个这一套环境就是在说我怎么样让这个探索者在这样的一维的环境中移动。
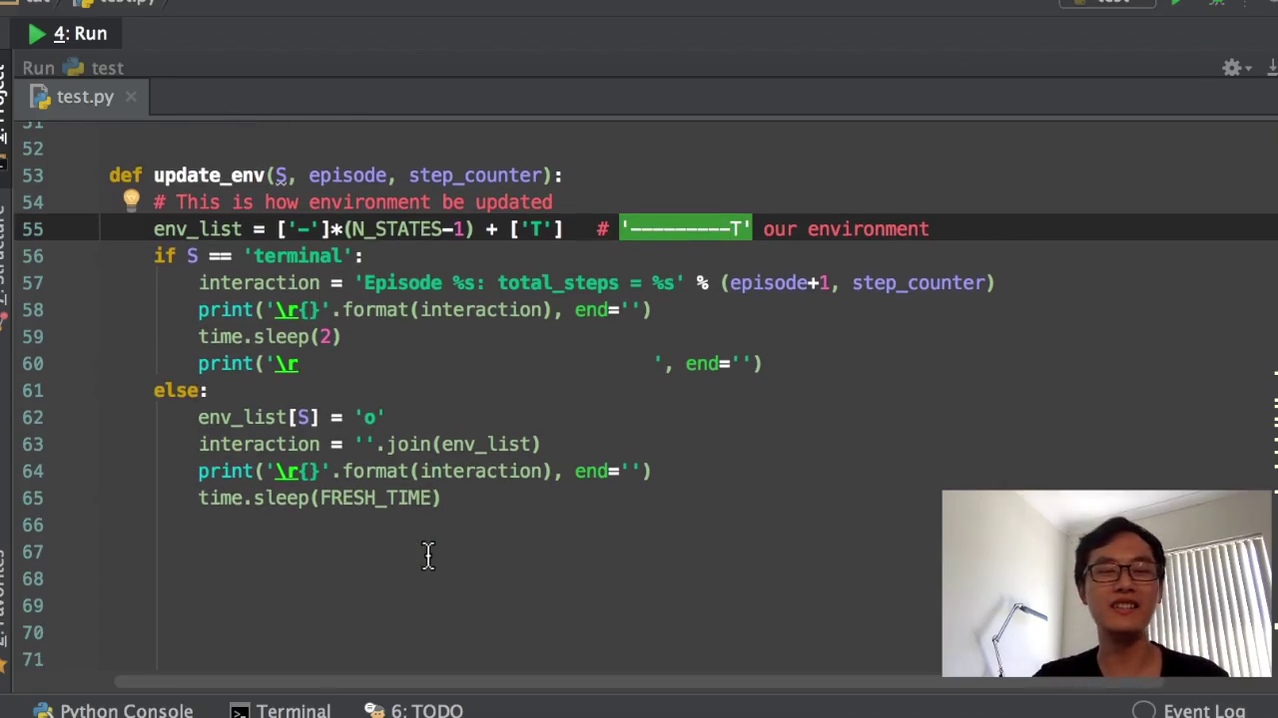
5)然后我们就要开始创建我们的主循环了,主循环在这里,RRL就是reinforcement learning。首先根据它的这个,我们要创建我们的这个q table,q table已经创建好了。从第一个egisto就是从第一个回合玩到最后一个回合。我们先看这边,让这个初始的state初始的情况我们就是把探索者放在最左边,初始情况因为不是terminate,就是不是中场而不是终止符号。那么它是不是终止符号,我们就用false来代替,它不是终终止符。如果它是终止符,我们就结束这一个回合,然后我们就开始repeat。就是对每一个回合我们就开始在回合里面玩了。
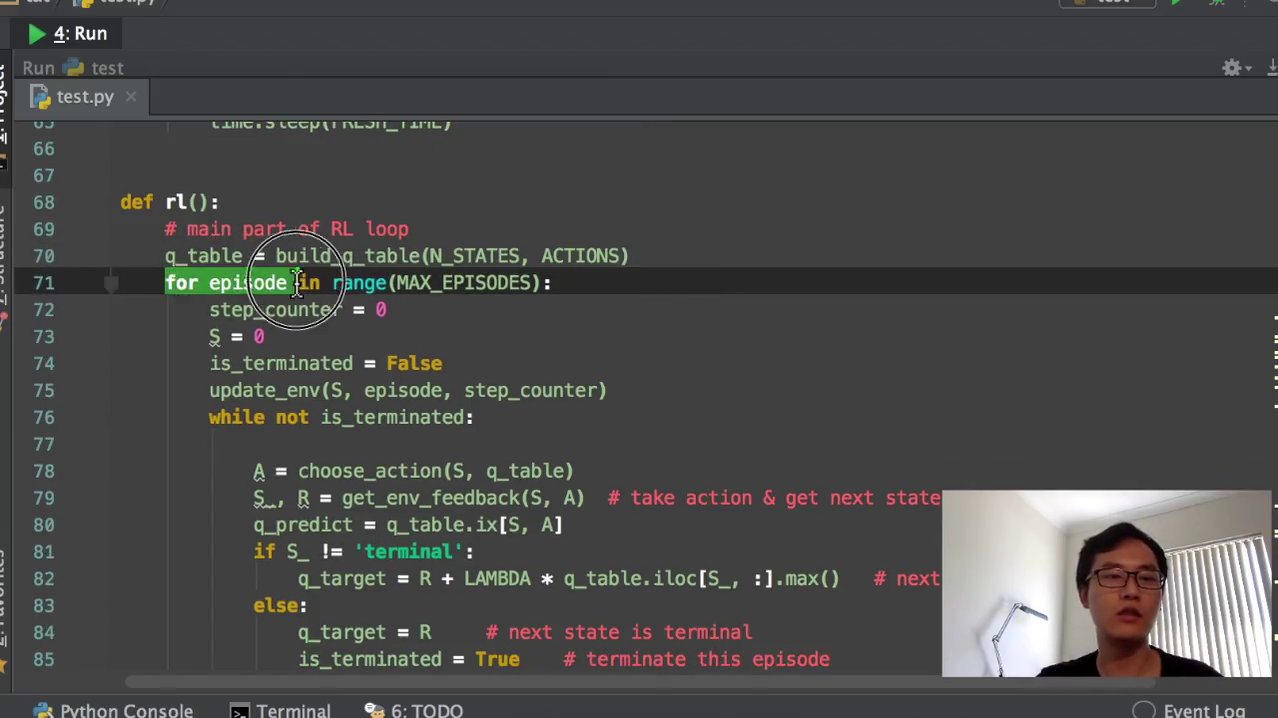
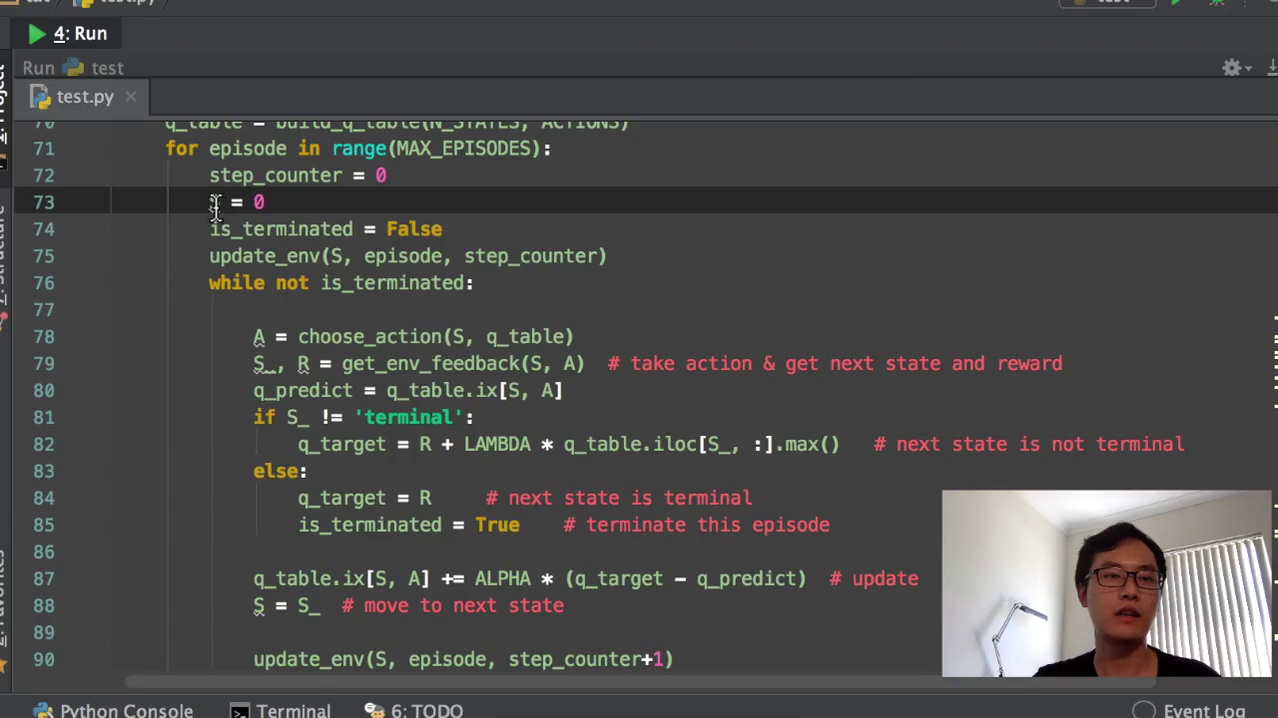
6)算法更新。就是我们这个老的q table当中的这个state和action。加上我们这一个,我们之前在Q20的教程简介当中也讲过,这个就是估计值。这个就是它的真实值,就是真实值减掉它的估计值乘以学习效率,那我们的这个就是它的估计值了,然后这个就是它的真实值了。在回合没有结束的时候,它的真实值就是R那个reward加上nda就是第这个衰减度乘以我的这个q max,这就是q max。然后如果说他达到了这个terminate terminal的时候,就是我达到了回合终止的时候,我就因为回合已经终止了,我就没有下一个这个q max了,我就直接是2。然后我就我就我就说他exterminate,就是它已经终止了。这样子的话我就可以断开这个while循环,直接又回到了这个for循环,就可以变到我的下一个episode,下一个回合了。
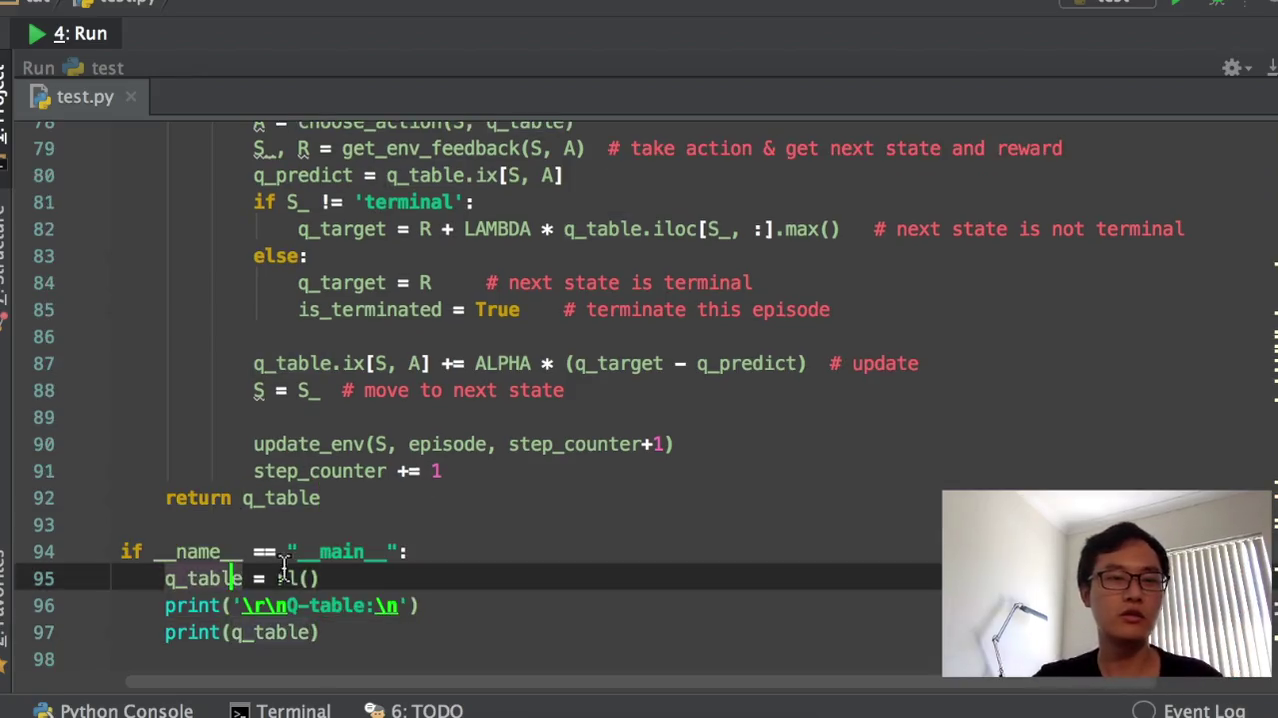
然后更新的时候就是q table,就是新的这个Q的值等于老的Q的值,等于这个老的Q的值就是加等于加等于在python当中加等于很强大,然后就阿尔法乘以它的这个误差值,我们就正式的把我们的下一个这个state,换到我们的下一回下一下一步的state。然后这个state,再循环下来以后,就是我们下一步的state了,然后再更新,然后再有一个step counter,就是我们在更新环境的时候,要用到这个东西。然后最后,我特意返回了一下q table,为的是什么呢?为的就是我们在训练完以后看一下这个q table,它里面的所有的值的样子。运行我们东西的时候,就是if name等于men的时候,我们就开始q table就等于RL。最终的q table就是我们学习好了以后的q table。然后我们再打印出来q table所有的值,看一下q table所有的值都长得什么样。我们为了加快速度,我们把这个fresh time改一下,我估计还是要把它改快一点比较好。
三、q-learning算法更新

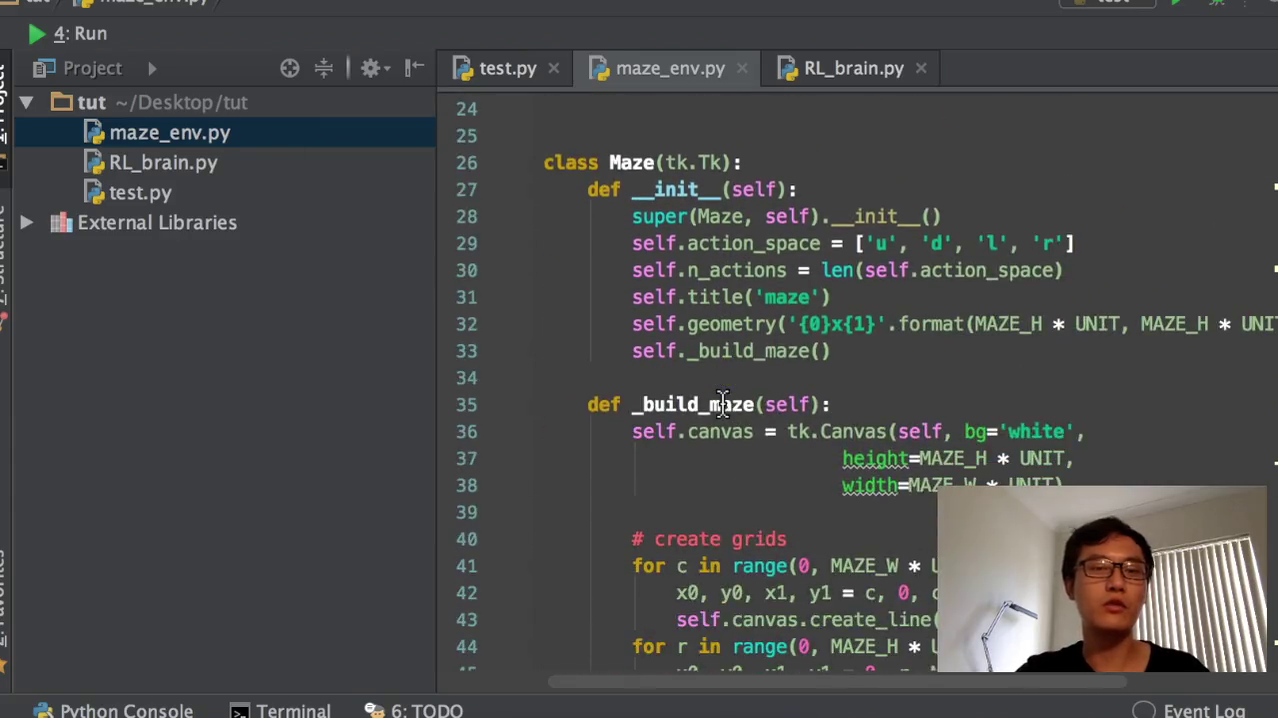
摘要:通过实现一个二维走迷宫游戏,让红色探索者找到黄色圆圈位置的宝藏。游戏将根据成功与否以及是否遇到障碍物给予奖励。教学内容涵盖三个文件:迷宫环境构建与Q-learning表算法实现。迷宫环境使用Tkinter编写,代码将附在视频描述中。下节课将详细讲解Q-learning表的实现与循环更新模式,并介绍OpenAI gym作为可能的应用方向。
用红色的探索者,扩展成一个二维的走迷宫游戏。那么红色探索者要达到这一个黄色的圆圈,这个就是我们宝藏的位置,它会得到一个reward,等于正的一。如果他跨到了这个黑色的地方,就是一个无底洞,那无底洞它的reward就等于0。负一就是说我要惩罚你,你跨到了这个黑洞里面,这个就夸了黑洞等于惩罚,那么捡到宝物等于一。我们今天来看用q learning table的这种形式的q learning,它是如何去实现这个功能呢?我们会扩展一下上一节课我们讲到的这个算法。

这节课我们把它分成了三个文件。大家可以看到就是我们整个的environment,就是我们环境。这个RL brand就是我们所要编写的整个的这一套的q learning q table。
一节课我们会讲如何编写这一套循环更新的模式,另外一节课我们会讲如何编写这个q brand里面的q learning table这一种class。你可以把它想象成一个这边这个的environment环境,另外一个是我的强化学习的大脑如何去思考,如何去决策。然后再来一个就是run this或者是test,它这个版本这个脚本,它就是说我如何去用我思考的东西去提升我的但这个reinforcement learning的循环。
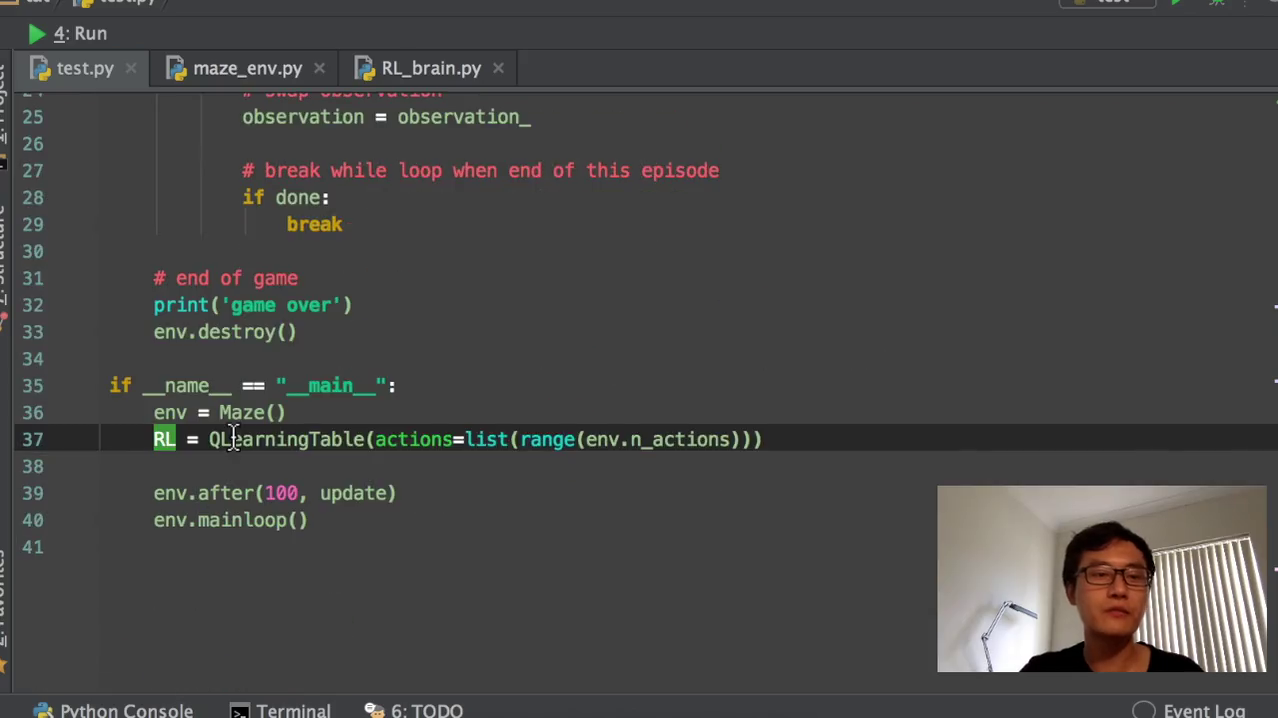
1)首先我们会import两个模块,这两个模块都是我们自己写的模块。第一个就是从我们的这个环境当中,这个是环境当中imports maze这个环境就是迷宫的这个环境,也就是这个class mates妹子是用TK into写的。这两个完了以后,一个是大脑,一个是环境。那我们就开始写一个update的功能。这个update的功能很简单,就是跟我们之前的以前那个代码的update功能非常的类似。他也就是说我首先我要运行,这是一个function update function。首先我们要运行有100个XO100个回合。
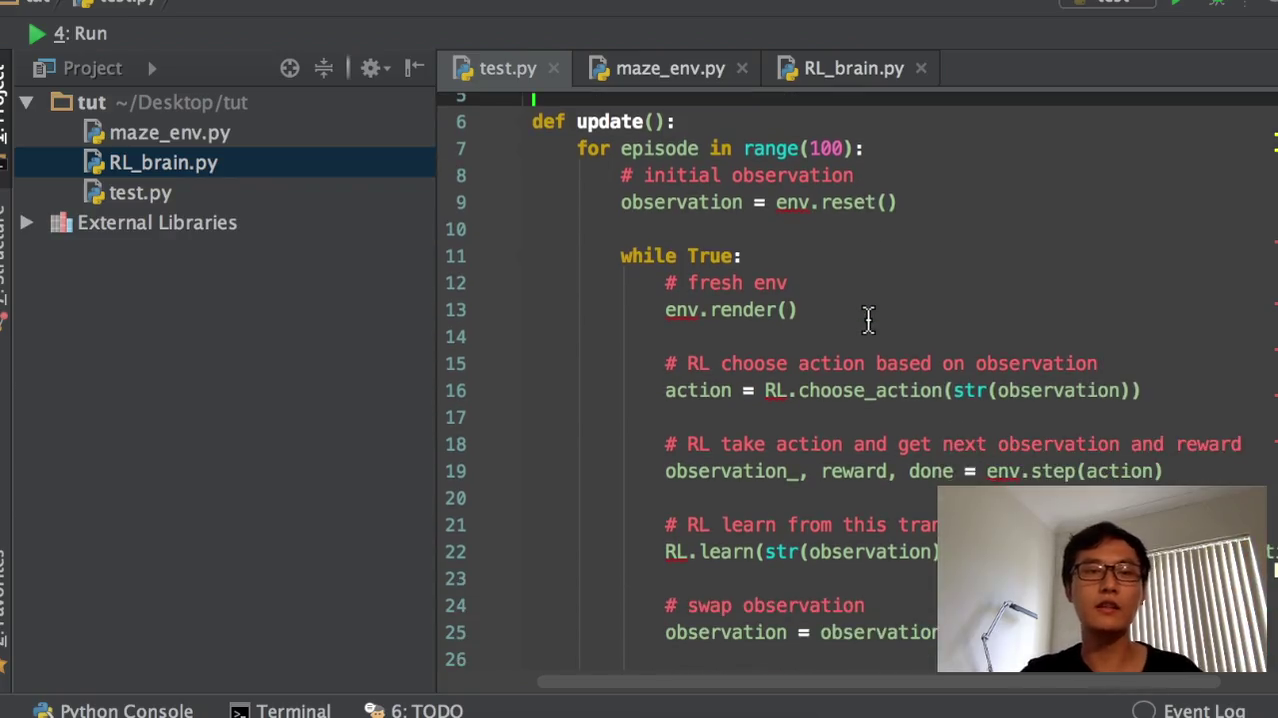
2)然后每一个回合开始的时候,我会得到开始的时候的一个observation,就是环境给出的一个观测值。这个观测值就是说我所在的红色的这个点,你这个点的一个位置。比如说它的位置是横的一和纵的一,那这个是一二这样子的一个位置的信息observation就是这个信息,然后这个是环境给出的,它初始值的信息都是一一的这个坐标。然后每个episode我们把这个放宽一点,每个epo每一个回合我要做的事情就是在回合里面玩。当回合还没有结束的时候,我的这个环境就重新刷新一下。刷新一下以后,我这个不是在没有在这个算法的里面,但是你要跟环境互动的话,你就要把环境刷新。
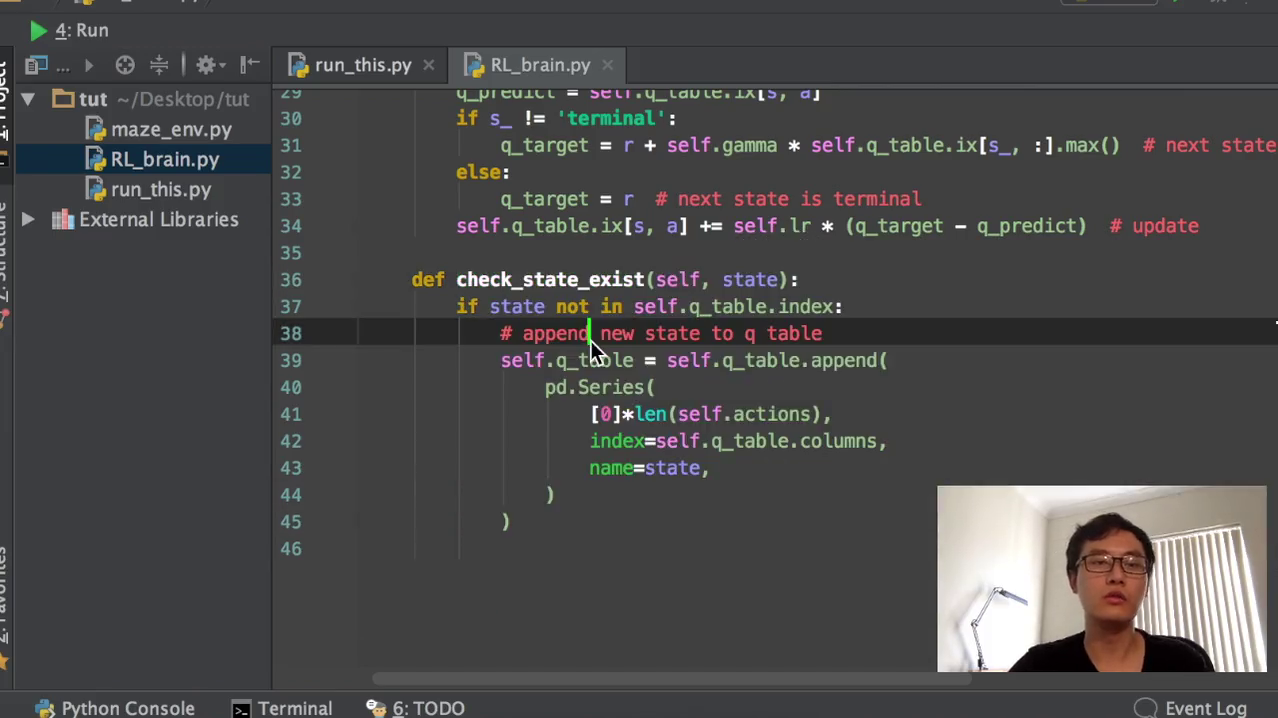
3)然后这个就是我们之前所讲到的RL,就是我们选择的选择的这个RL方式,选它去挑选一个action,挑选一个动作,它基于的是什么?它基于的是我们的observation,也就是它基于我们的观测值来挑选动作。上一节课我们讲到的这个观测值,实际上就是它的一个state,它的一个状态。我们就是说关键词,我们在这边用一个string模式来定义它的这个观测值,这个放在table当中,你这个string可以当做它的索引。然后我挑选了一个动作,我在这个environment里面去施加这个动作。施加这个动作environment又会返回下一个observation,就是我施加动作以后,我跳到下一个。下一个状态又会有下一个状态的observation,又会有下又会有跳到下一个动状态的所获得的这个reward,那我们就是它就会返回下一个状态,我用这边我在这边用这个下斜杠,后面加一个下斜杠代表下一个状态,然后他又会返回一个reward。这个down就是说我有没有跳进地狱,跳进那个坑,或者是有没有拿到这个保障。如果跳到了坑里面,那就是完了,这个回合完了,或者是我又我我拿到了保障,也是等于这个回合完了。等回合完了以后,我们就跳出这个while循环进入下一个回合,下一个回合又重新开始哈那回合没完的时候,我们的RL就是我们强化学习的这种方法,就要学习从什么地方学习。从我们的第一个observation和我们在第一个observation的时候施加的动作和我们的施加动作以后得到的reward,和施加动作以后我们跳到了下一个哪个状态。这个是整个一个transition,也就是整个一个对对对transition。我翻译全智贤整个一大步,就把它理解成它的一个重要步骤。
4)Q learning table就是我们刚刚import进来的q learning table。它所要这个我们之后下节课会讲它具体的功能,反正你就知道了。我们选择了一种学习方式,然后我们选择了一种environment,然后把这个学习方式放到environment里面去,不断的提升,不断的去玩。
四、Q-learning思维决策
摘要:在探讨Reinforcement Learning领域中Q-Learning算法的实现时,重点在于Q-table的构建与行动选择策略的优化。已经完成了Q-Learning的基本框架和循环更新机制,接下来深入讨论了如何在Q-table中定义一个高效的选择函数,该函数依据当前的观察结果来决定下一步行动。特别强调了学习过程中的一个关键环节:处理新状态的能力,即如果遇到未曾经历的状态,需要将其加入Q-table并给予合理初始化,以适应环境的不确定性。此外,为了在探索与利用之间找到平衡,引入了ε-greedy策略,根据该策略,学习者有时会随机选择行动以探索新状态,有时则选择Q-table中预估值最高的行动以利用已知信息。状态-动作对的更新方法被详细解释,确保了Q-table的持续优化。通过一个实例展示了学习者如何通过不断尝试和学习,最终找到避开陷阱并成功获取宝藏的有效行动策略。
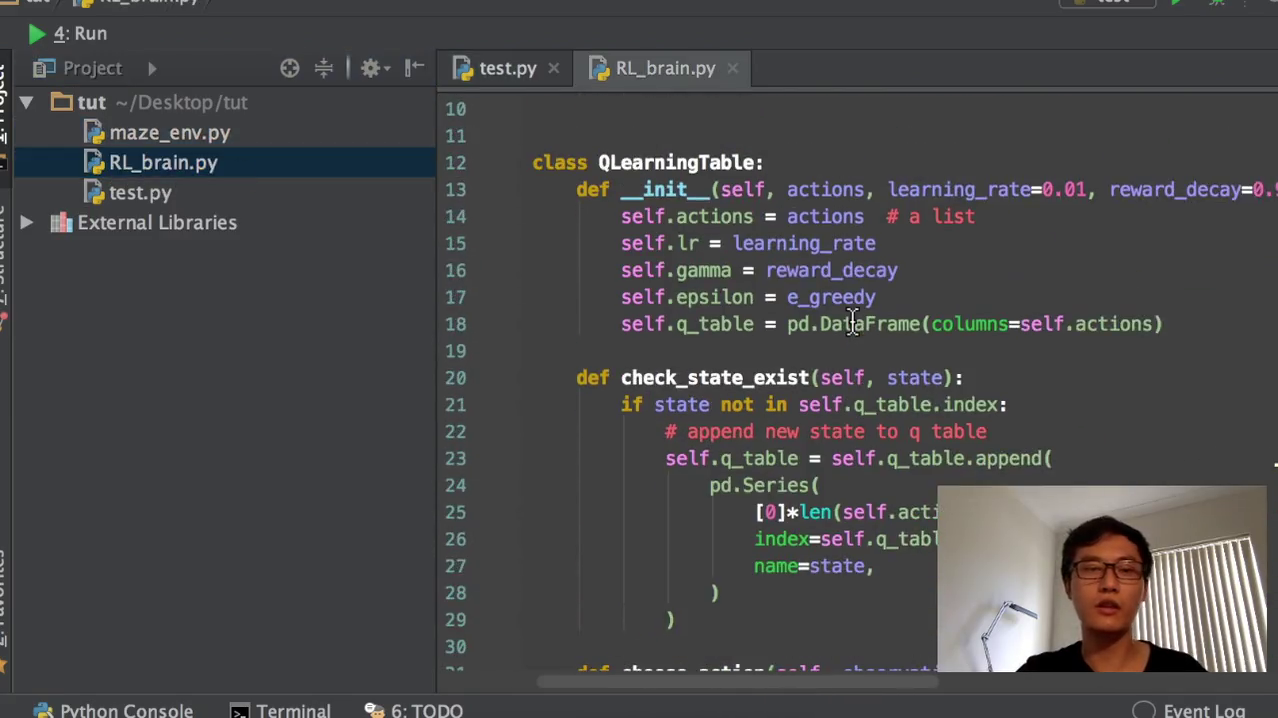
Q learning我们之前已经编写好了我们的这个,然后也已经编写好了run_this就是它的循环更新的这一部分。那今天我们就会来如何编写这一个air brand,也就是我们的q learning table的方法,table look up的方法。
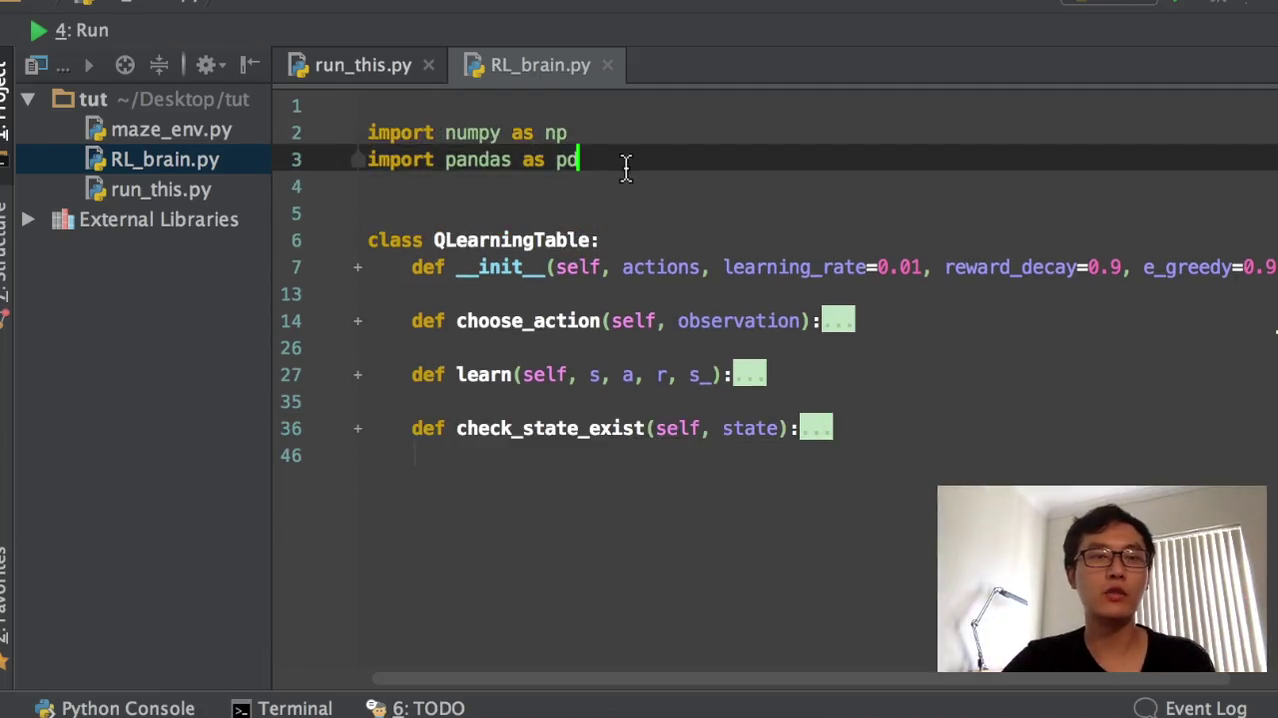
我们首先要确定我们有imports number of pandas作为我们q lin的数据处理。我们会要写在Q单元当中,我们首先我们在run this不是有加一个RL choose action的方那个功能吗?那我们在这个q table q learning table的方式里面就要定义choose action。然后我们也是根据observation来定义它的怎么样去选择行为。然后我们选择行为以后,我们RL我们的这个常规学习还需要学习根据我们过往的经验去学习这个observation和reward。这个就是这个learn的功能,也就是我们要学从现在的state加上我们选择的action,加上我们获得的reward,加上我们获取的下一个来学从中学习,来提升我们的这个q table。然后这个功能是我们以前没有的,我们之前讲那个一维的探索者和保障的问题里面没有这个东西。因为因为那个里面我们已经固定好了q table的长度大小。
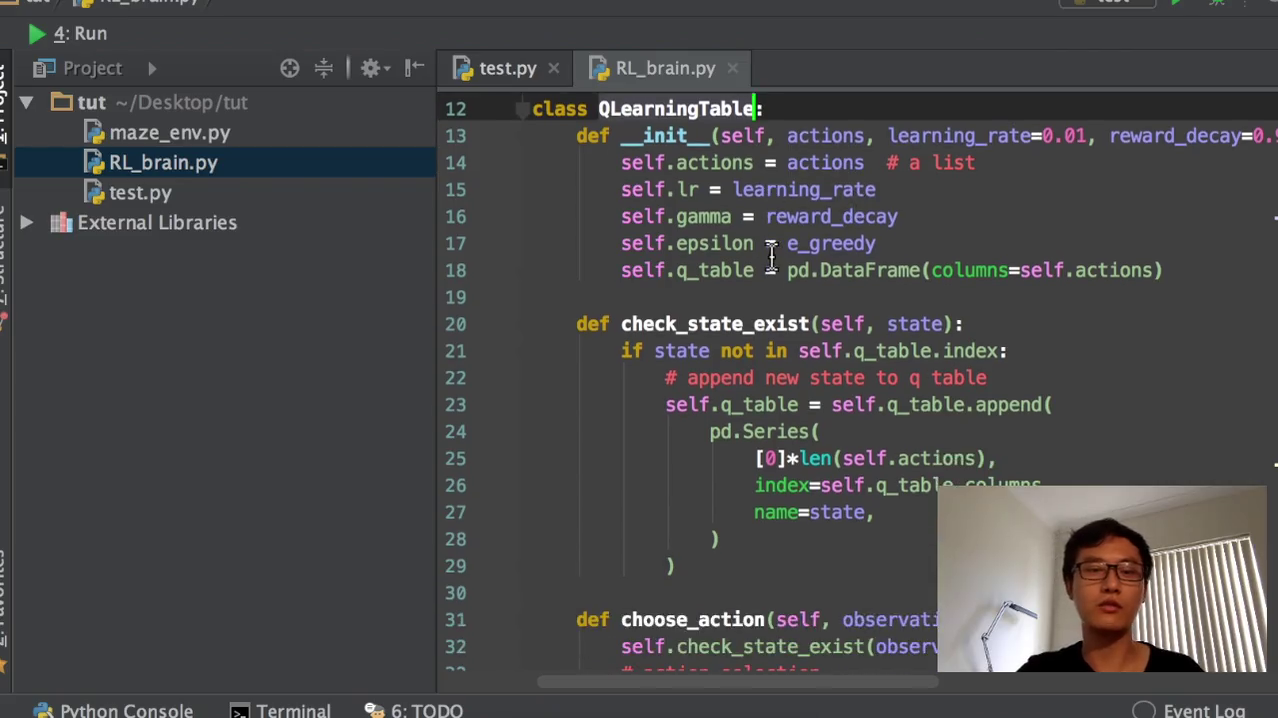
但是在这一个例子当中我们不知道假设我们不知道到会有多少个state,那我们就要需要检验我们下一个经历的这个state,它是不是我们之前已经经历过的,或者是我们从来没有经历过。如果从来没有经历过这个state,我们再把这个state的信息放到我们的q table当中去。那q table的初始化的时候,我们就要初始化。Q table是什么都没有的,它是一个空的panda s的data rame,这就是我们的q table。我们在initial的时候,我们就会需要这几个值。一个是能量rate,也就是阿尔法,一个是这个reward decade,也就是我们的伽马0.9,默认是0.9。然后这个EFAE grade就是我们的这个action credit参数,也就是我们的action的参数。然后把这些值都附上。
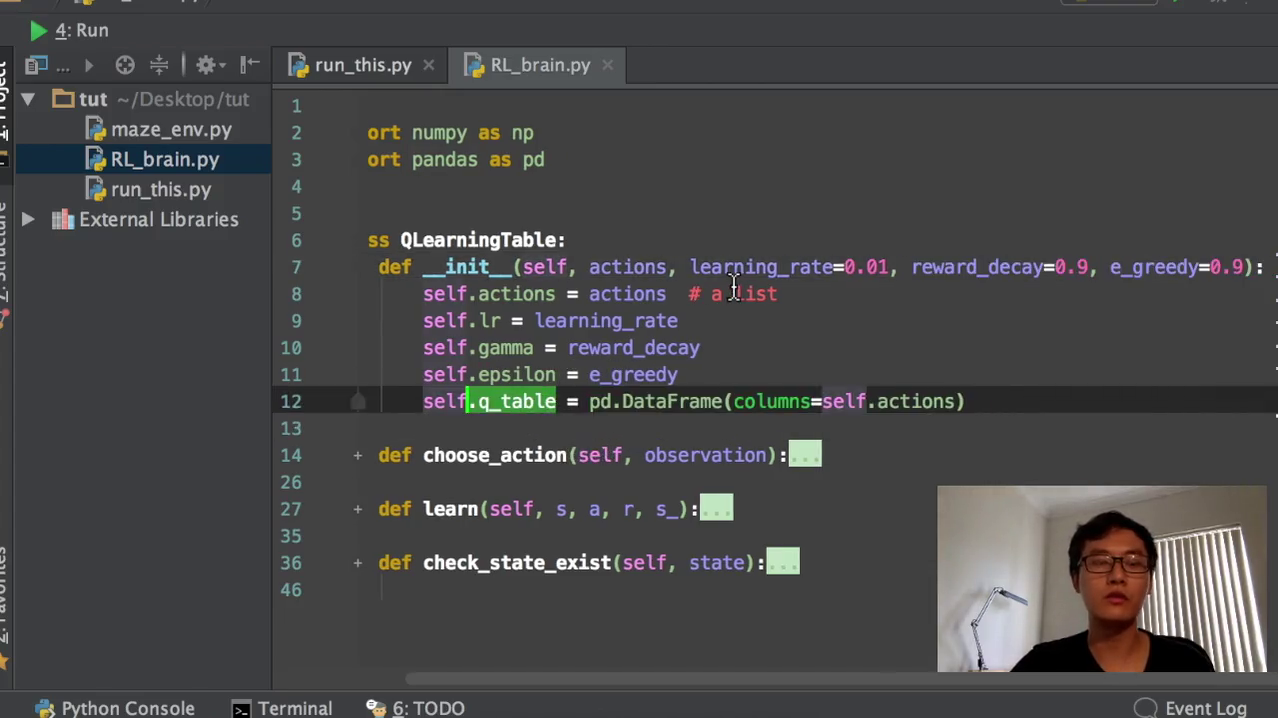
我们的这个action就是我我们在建立q table的时候,纵轴就是这个012345678的纵轴是我们的state的,有多少个state。然后我们的横轴横轴的标签,这个横轴的标签是我们的action,可用的action,所以我们要传入我们有多少个可用的action。然后在定义q table的时候,把Collins的名字定义成action的名字,这就是我们空的一个空的q table。然后我们如果要经历某一个没有经历过的state,我们再把这个state添加到我们的空的q table当中去。这就是我们的一个添加过程,也就是之前没有的这个过程。
好,我们我们这边首先我们按照这一个循环的套路来一步一步来。这个environment出去以后,environment渲染以后,因为这就到了我们的RL趋势action的部分,它传入的是一个street,也就是可以作为我们的索引。那cuse action,首先我们就要检验我们传入进来的这个observation,有没有在我们的这一个q table当中。如果没有在我们的q table当中,我们就把这个observation的这个state加到我们的observation当中去,加到我们的这个q table当中去,当做一个新的索引值。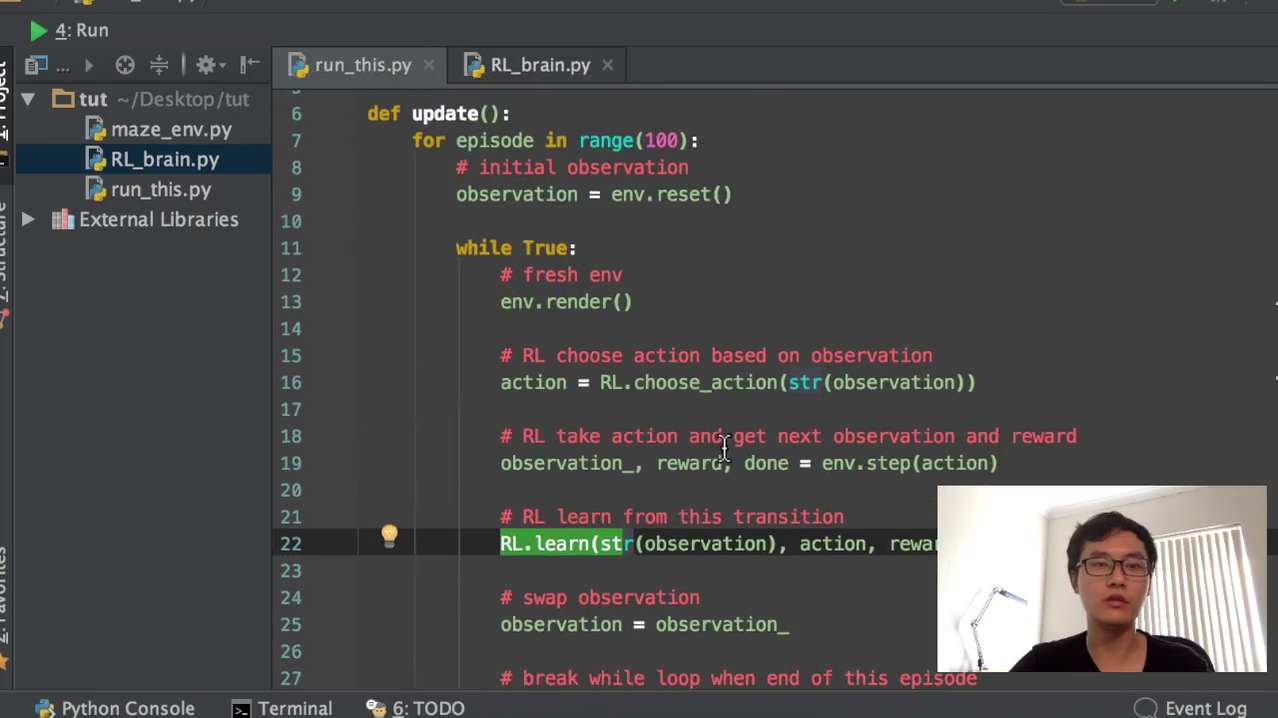
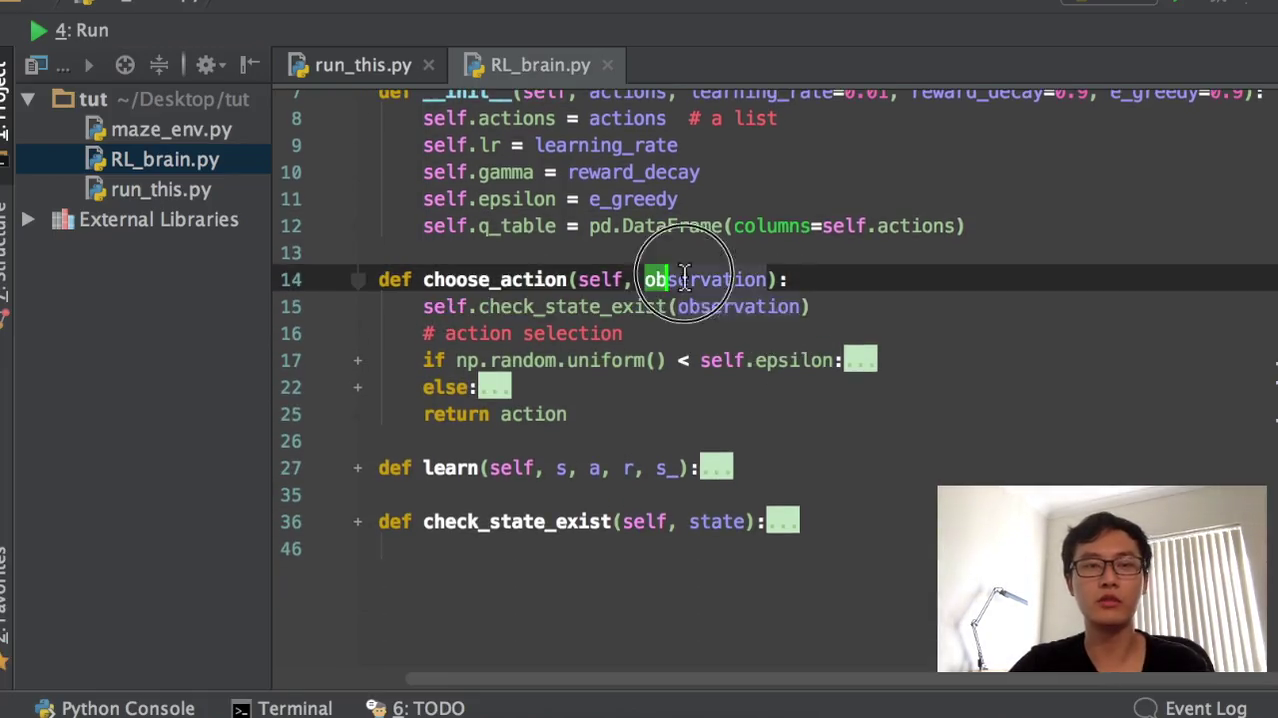
这一步就是因为如果我的假设我有两个action,然后这两个action它的这个value在这个q tape当中的值它恰好又是相等的那如果直接用这个state action,用这个ugly max,它就会选择相等中间的第一个的索引,那它就永远不会选到第二个索引。那我为什么要做这一步呢?就是我打乱所有action的位置,然后随便他。即使你选了第一个,你也不知道这是学习到哪一个的第一个。所以我先打断所有的action的位置,然后我再假设它们的值是相同的那我还是选择第一个的话。那第一个的这个action不一定也是我永远会选择的那个action。
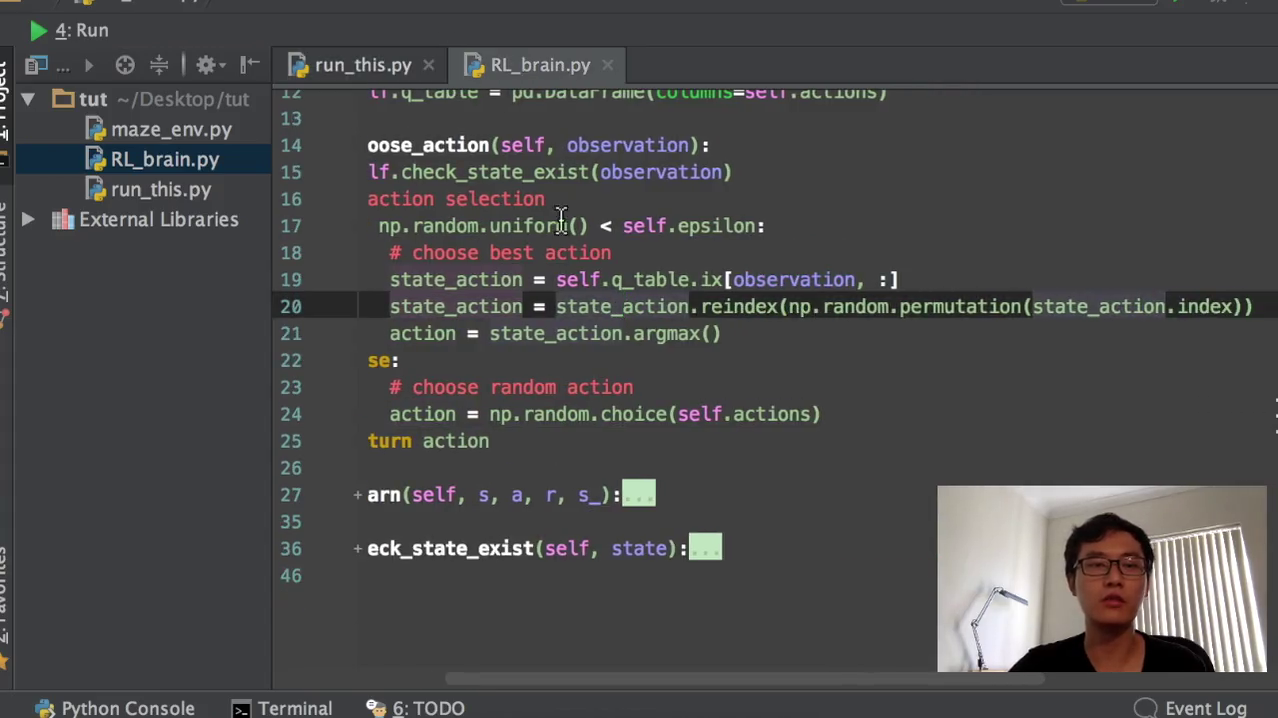
Action完以后我们这边就会有一个observation,下一个的observation和reward,还有这个有没有terminate。然后我们就是把所有的信息放到RL当中去学习。学习的步骤就在这里,我们会囊括这个state action,reward next state.
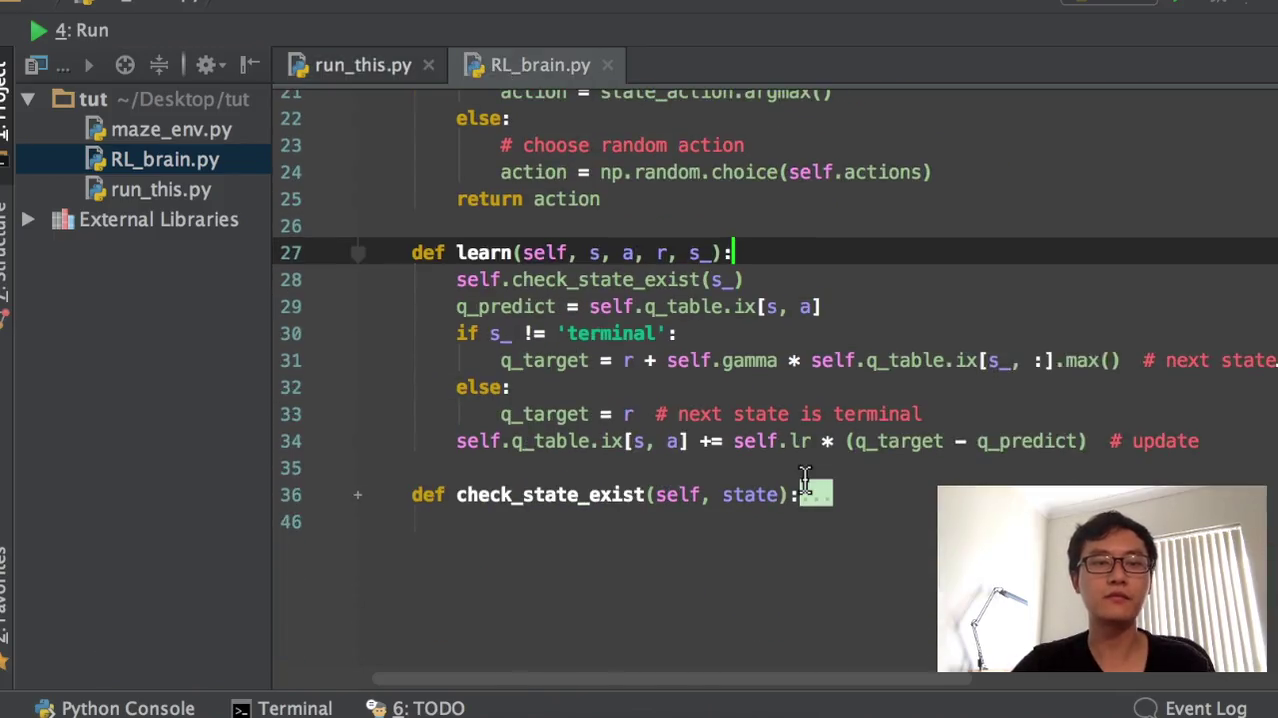
然后我们因为我们包括了一个新的next state,也就是我们还是需要检验它有没有在我们的q table当中。如果这个没有,在我们QQ当中,我们再加上这一个,然后我们就跟之前是一模一样的。我们需要找到Q的这个估计值,然后用这个真实值减掉Q的估计值乘以学习效率,就在我们的要修改的这个值。好,最后就是我们所说的这个check state exist,就是看它有没有存在的这个功能了如这很简单,就是说它如果有存在的话,我们就是没有做任何东西。它如果不存在的话,它没有在这个q table当中的index里面的话,那我们就把它attend到我们的这个原始的q table里面去。这全零的这个state在任何的action里面都是全零的。然后把这个全零的数字append到我们的q table的明确ipad完以后,这就是我们所有的代码了。然后我们很庆幸的直接运行一下它,你就可以看到这样的一个小窗口,这就是我们q learning的一个窗口。
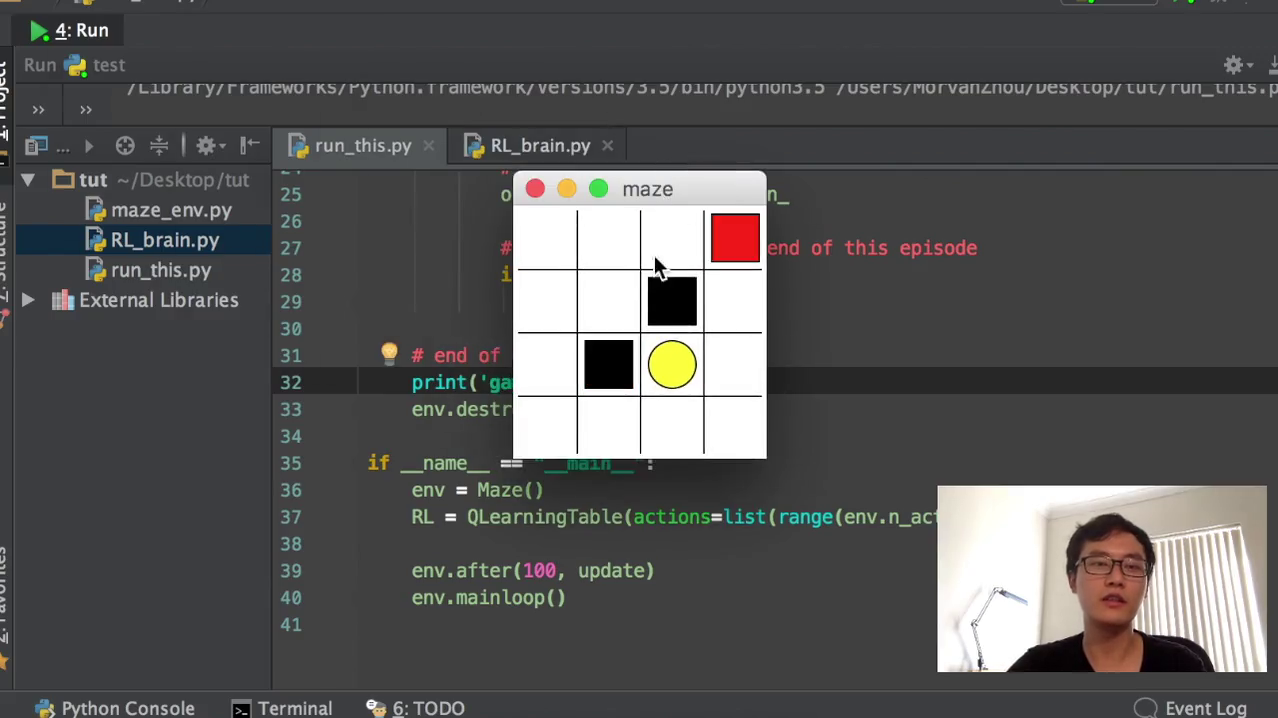
你看首先红色的这个探索者,他会不断的尝试,我掉进坑里了,那下一次我就要要摄取一下之前的经验,我就要尽量的避免这个坑。你看他现在他在这个坑的周围还在不停的转,因为他已经知道进坑是一个非常危险的动作,然后他就会通过不同的尝试。那为什么他还会进坑呢?就是因为这个确实action的时候,不是还有一个10%的概率吗?10%我会采取随机的概率,他所以他就10%的时候可能就进坑了。那你看现在Q60他就已经找到了一个合适的去往保障的路线。这个就是我们成功的让我们的探索者学会了如何去探宝。然后这个就是我们这一节课所要讲的


















 1172
1172

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











