







前言
这学期开了门课是python数据分析和可视化,今天第一次实验课主要是复习了一下python基础和常用的一些操作
【1】读取txt,csv文件和文件的写入
#读取txt,csv文件
file=open("C:\\Users\86178\Downloads\泰戈尔的诗.txt",mode='r') #以只读方式打开文件
content=file.read() #一次性读取整个文件内容
print(content)
file.close()
#读取csv文件
import csv
with open("C:\\Users\86178\Downloads\student.csv","r") as f:
reader=csv.reader(f)
rows=[row for row in reader]
for item in rows:
print(item)
#csv文件的写入
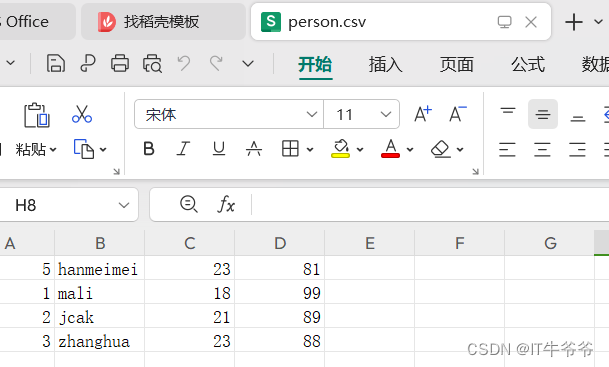
content=[
["5","hanmeimei","23","81"],
["1","mali","18","99"],
["2","jcak","21","89"],
["3","zhanghua","23","88"], ]
f=open("C:\\Users\86178\Downloads\person.csv", "w",encoding="utf-8", newline="") #不加newline="",就会出现空行
content_out=csv.writer(f) #1.创建writer对象
for con in content: #遍历列表,将每一行的数据写入csv
content_out.writerow(con)
f.close()
写入后的文件:
【2】白葡萄酒的数据分析
1.查看白葡萄酒中共分为几种品质等级
① 查看当前葡萄酒文件的格式,选择合适的方法进行数据载入
② 明确描述“品质等级”的具体位置,即quality属性
③ 遍历数据,将每行数据的quality值放于列表
④ 对此列表进行去重
2.按白葡萄酒等级将数据集划分为7个子集,并统计每种品质等级的数量
① 考虑保存数据的数据结构,要求既有等级又有对应的等级的数量,可用字典
② 遍历文件,相同等级的数据可放于一个列表,每一个等级创建一个列表
③ 计算列表的长度
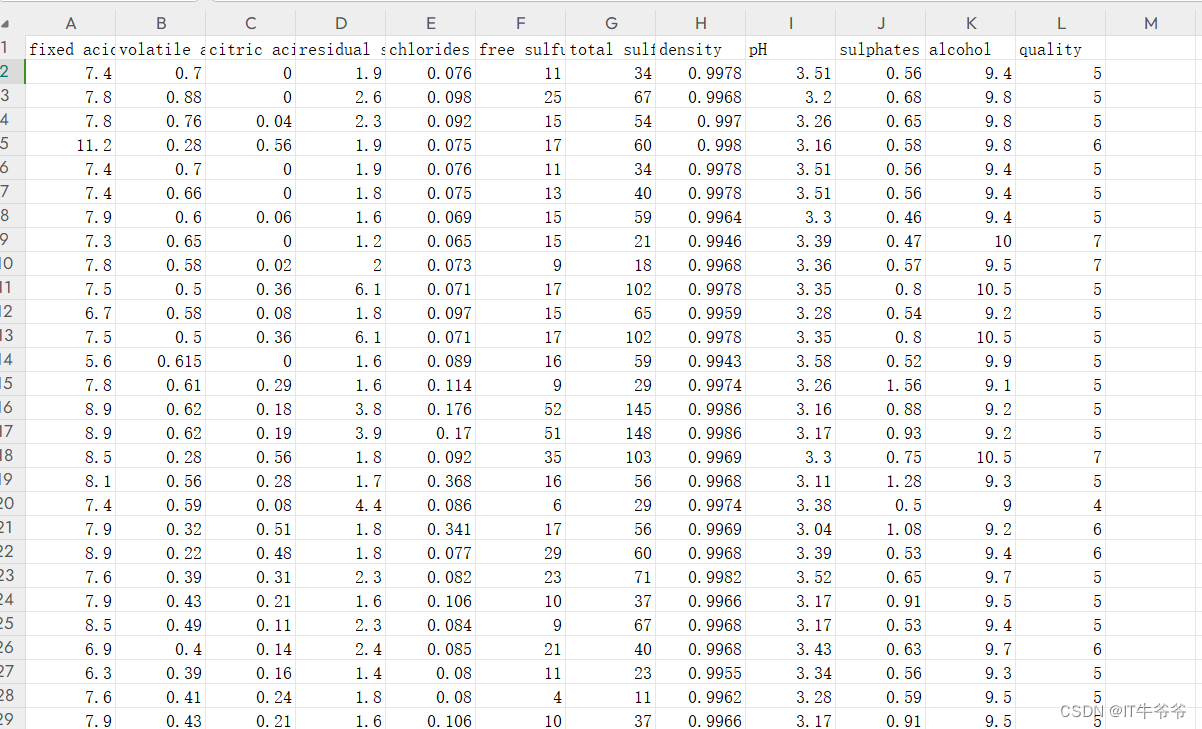
白葡萄酒的数据集:
代码:
import csv
f=open("C:\\Users\86178\Desktop\winequality-red.csv","r",encoding="utf-8")
reader=csv.reader(f)
content=[]
for i in reader:
content.append(i) #把每一行数据放到列表中,列表中每一个元素是每一行数据
f.close()
quality_list=[] #存放每列quality的值
for row in content[1:]:
quality_list.append(int(row[-1])) #把每列的quality的值放到列表中
quality_count=set(quality_list)#去重
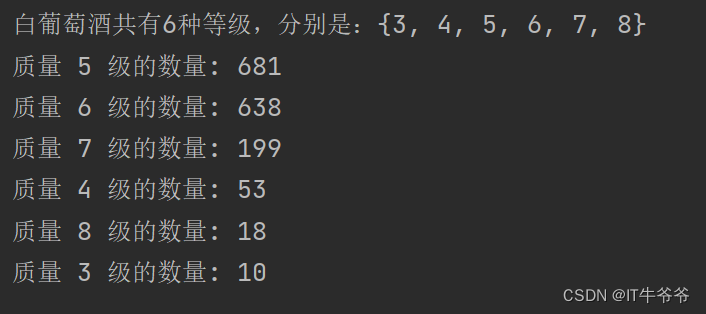
print("白葡萄酒共有%d种等级,分别是:%r"%(len(quality_count),quality_count))
content_dict={}
for row in content[1:]:
quality = int(row[-1])
if quality not in content_dict.keys():
content_dict[quality] = [row] # 创建values:[ [] ]
else:
content_dict[quality].append(row) #向字典中添加values值,例如[ [],[],[] ]
for key in content_dict:
print("质量",key,"级的数量:",len(content_dict[key]))
运行结果:
















 8378
8378











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











