







贡献:
这项工作的贡献是:
1) 发布了一个新的移情对话数据集作为一个新的基准;
2) 实验表明,在这个数据集上的训练可以提高端到端的移情对话系统的性能。
数据集特点
任务类型:
该数据集针对的是共情对话(共情回复)任务。
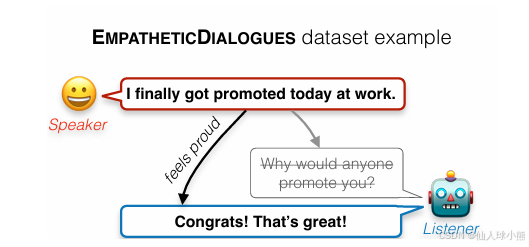
图:共情回复的示例
共情回复,即理解speaker话语中的隐含信息(如. feel proud),进而做出恰当的回复(如. 直接表示祝贺,而非追问对方),以提供对话者所期待的情绪反馈。
具体参数:
共包含了超过25K段对话,每段对话都与32种不同的情感状态(Emotion)之一相关联,且每个对话都基于一个特定的情境(Situation)。
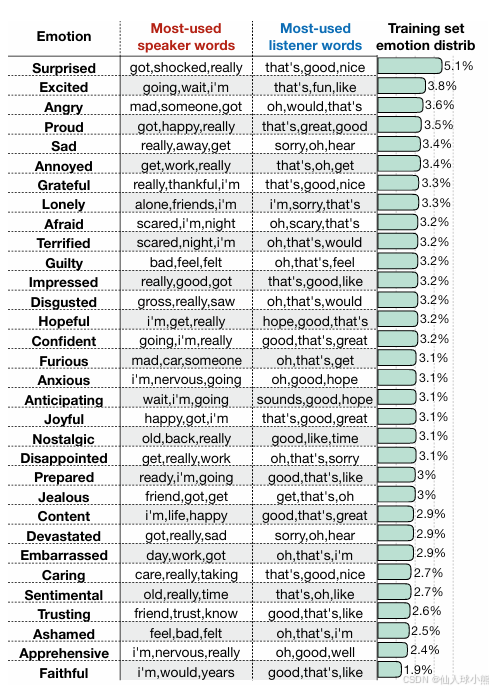
图:训练集内的32中情感主题的分布情况以及每个类别的演讲者 / 听众使用的前 3 名内容词。

图:数据集的示例
构建方式
第一阶段
参与者 A(speaker)被给予一个情绪标签(Label),参与者A需要写下“ 当自己具有这种情绪 ”时,其所在的情况(Situation)。
第二阶段
参与者A与第二个参与者 B(Listener) 开启一段谈话(面对面交流)。
参与者A首先讲述他们的处境(围绕Situation),他被要求带着对应的情绪去描述自己的处境。他必须用1到3句话作出描述。平均长度是19.8。
聆听者B则给予回复,他不被事先告知参与者A所具有的情感类型(emotion)和情境(Situation),而需要从与A的简短对话中实时地进行推测,以尽量做出合理的回复。
更详细地总结,倾听者被要求:
-
实时的情感推断与需求推断:
- 倾听者需要仔细聆听讲述者的故事,推断出讲述者的情感状态与内心需求。例如,如果讲述者说“我终于在工作中得到了晋升!我为此努力了很长时间。”,倾听者需要推断出讲述者的情感是“自豪”,他的需求是“他人的见证、肯定与认可”。
- 倾听者不能看到讲述者的情感标签或情境描述,只能根据对话中的线索来回应。
-
回应要求:
- 倾听者的回应需要体现出对讲述者情感的理解和共情,尽量满足讲述者的隐含需求。例如,对于上述“自豪”的情感,倾听者可以回应“恭喜!这太棒了!”。
- 倾听者的回应应当是自然的、人性化的,避免机械或不自然的表达
每个对话的长度为4-8个表达句(大多为两轮4句,平均为4.31句)。平均字数为15.2。
使用方法
EmpatheticDialogues数据集主要用于端到端的移情对话系统的训练与评估。
模型方案:
略,在这个日新月异的时代,5年之前的技术流已经没有很大的参考价值了。
评估方案:
我们评估模型是否具有与人类倾听者相一致的回复表现。
我们使用自动化度量和人类评估来评估每个模型。我们使用自动化度量来快速评估模型的输出结果与真实目标数据是否相一致。人类的评估很重要,因为自动化度量的标准并不总是与人类的判断标准相一致。在此文中,人类评估主要用于评估模型生成的响应在实际应用中的表现,尤其是共情能力。
自动化评测指标
-
BLEU分数(Bilingual Evaluation Understudy)
- 定义:用于评估机器翻译质量的指标,通过比较模型生成的响应与真实响应(gold response)之间的n-gram匹配度来计算。
- 计算方式:计算模型生成的响应与真实响应之间的1-gram、2-gram、3-gram和4-gram的匹配度,然后取这些匹配度的平均值。
- 用途:评估模型生成的响应与真实响应的相似度,分数越高表示生成的响应越接近真实响应。
-
P@1,100(Precision at 1 out of 100)
- 定义:在检索任务中,模型从100个候选响应中选择正确响应的准确率。
- 计算方式:模型选择的响应与真实响应匹配的次数除以总的测试样本数。
- 用途:评估模型在检索任务中选择正确响应的能力,分数越高表示模型的检索能力越强。
-
Perplexity(困惑度)
- 定义:用于评估生成模型的性能,困惑度越低表示模型生成的响应越准确。
- 计算方式:计算模型生成的响应与真实响应之间的交叉熵,然后取指数。
- 用途:评估生成模型的性能,困惑度越低表示生成的响应越接近真实响应。
人工评测指标
-
Empathy/Sympathy(共情/同情)
- 定义:评估模型生成的响应是否表现出对讲述者情感的理解和共情。
- 评分标准:使用李克特量表(Likert scale),评分范围为1到5,1表示“完全不”,5表示“非常”。
- 用途:评估模型在共情对话生成任务中的表现,分数越高表示模型的共情能力越强。
-
Relevance(相关性)
- 定义:评估模型生成的响应是否与对话内容相关。
- 评分标准:使用李克特量表,评分范围为1到5,1表示“完全不相关”,5表示“非常相关”。
- 用途:评估模型生成的响应是否符合对话的上下文,分数越高表示响应越相关。
-
Fluency(流畅性)
- 定义:评估模型生成的响应是否流畅、自然。
- 评分标准:使用李克特量表,评分范围为1到5,1表示“完全不流畅”,5表示“非常流畅”。
- 用途:评估模型生成的响应是否易于理解,分数越高表示响应越流畅。
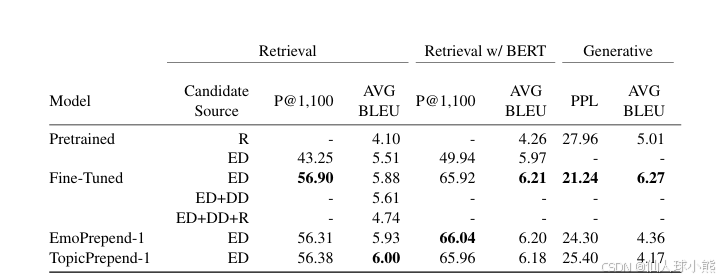
表:自动化评测指标及结果
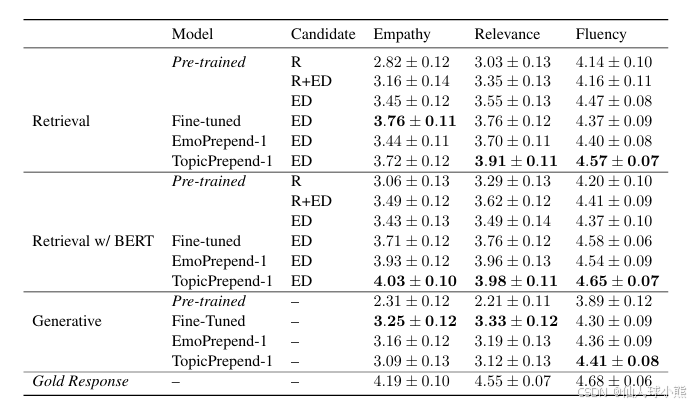
表:人类评测指标及结果
相关研究论文
最近的工作
2024 ACL
交互联想记忆模型在移情反应生成中的应用
2023 EMNLP
基于大语言模型的共情回复生成:实证研究和改进
2022 AAAI
CEM:带有常识的共情回复生成
更早期工作
1.Towards Empathetic Open-domain Conversation Models: A New Benchmark and Dataset
Facebook AI Research · 2019年
2.Empathetic Dialogue Generation through Multi-task Learning with a Latent Space
University of California, Santa Cruz · 2020年
3.Empathetic Dialogue Generation with Pre-trained RoBERTa-GPT2 and External Knowledge
Tsinghua University · 2021年
4.Empathetic Dialogue Generation via Multi-task Learning with Emotion and Context
University of California, Santa Cruz · 2020年
5.Empathetic Dialogue Generation with Contextual Transformer Models
Tsinghua University · 2021年


















 3528
3528

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











