






在数据分析和编程中,apply、merge、groupby 和 agg 是处理数据集时常用的操作。下面举一个简单的例子来说明这些操作是如何使用的:
假设我们有两个数据集,一个是关于书籍的销售数据,另一个是关于书籍的详细信息。
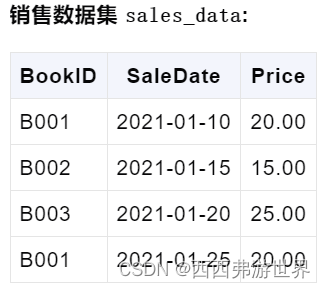
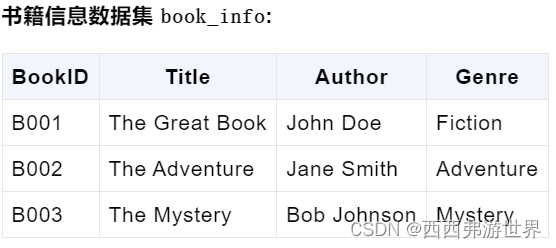
首先创建我们需要的数据集:
import numpy as np
import pandas as pd
df1 = pd.DataFrame({
'BookID': ['B001', 'B002', 'B003', 'B001'],
'SaleDate': ['2021-01-10', '2021-01-15', '2021-01-20', '2021-01-25'],
'Price': [20.00, 15.00, 25.00, 20.00]
})
df2 = pd.DataFrame({
'BookID': ['B001', 'B002', 'B003'],
'Title': ['The Great Book', 'The Adventure', 'The Mystery'],
'Author': ['John Doe', 'Jane Smith', 'Bob Johnson'],
'Genre': ['Fiction', 'Adventure', 'Mystery']
})Apply
apply 函数可以对数据集中的每个元素应用一个函数。例如,如果我们想要将价格转换为美
元,可以使用 apply,这里我使用了匿名函数:
df1['PriceUSD'] = df1['Price'].apply(lambda x: '$' + str(x))
print(df1)
运行结果如下:
BookID SaleDate Price PriceUSD
0 B001 2021-01-10 20.0 $20.0
1 B002 2021-01-15 15.0 $15.0
2 B003 2021-01-20 25.0 $25.0
3 B001 2021-01-25 20.0 $20.0Merge
merge 用于合并两个数据集,通常是基于一个或多个键。例如,我们可以将销售数据和书籍信息合并,这个例子中的键就是BookID:
merged_data = df1.merge(df2, on='BookID')
#on='BookID'指的是pandas 按照 BookID 列的值将两个 DataFrame 对应的行连接起来。
#也就是说,BookID 列在两个 DataFrame 中都存在,
# 并且它的值将用来确定如何将行配对。
print(merged_data)运行结果如下,可以看到两个表格被合并了起来:
BookID SaleDate Price PriceUSD Title Author Genre
0 B001 2021-01-10 20.0 $20.0 The Great Book John Doe Fiction
1 B002 2021-01-15 15.0 $15.0 The Adventure Jane Smith Adventure
2 B003 2021-01-20 25.0 $25.0 The Mystery Bob Johnson Mystery
3 B001 2021-01-25 20.0 $20.0 The Great Book John Doe Fiction
Groupby
groupby 用于根据某个或某些键对数据集进行分组。例如,我们可以按书籍的 Genre 分组,然后计算每种类型书籍的平均价格:
genre_avg_price = merged_data.groupby('Genre')['Price'].mean()
# mean()取相同题材的书籍的平均price
print(genre_avg_price)结果如下:
Genre
Adventure 15.0
Fiction 20.0
Mystery 25.0
Name: Price, dtype: float64Agg
agg 是 aggregate 的缩写,用于对分组后的数据集应用聚合函数。例如,我们可以计算每个 Genre 的总销售额:
genre_total_sales = merged_data.groupby('Genre')['Price'].agg('sum')
print(genre_total_sales)结果如下:
Genre
Adventure 15.0
Fiction 40.0
Mystery 25.0
Name: Price, dtype: float64可以看出,这和下面这行代码的效果是一样的。
genre_total_sales = merged_data.groupby('Genre')['Price'].sum()
print(genre_total_sales)














 1566
1566

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









