







seq2seq简介
-
输入:划分为序列的词向量
-
输出:针对每一个词向量对应的译文
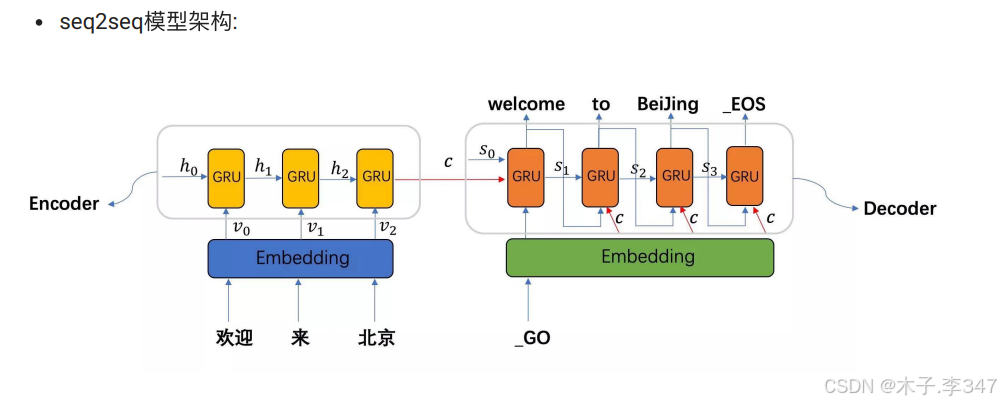
从上图中可知, seq2seq模型架构, 包括两部分分别是encoder(编码器)和decoder(解码器),
编码器和解码器的内部实现都使⽤了GRU模型, 这⾥它要完成的是⼀个中⽂到英⽂的翻译: 欢迎 来 北京 --> welcome to BeiJing. 编码器⾸先处理中⽂输⼊"欢迎 来 北京", 通过GRU模型获得每个时间步的输出张量,最后将它们拼接成⼀个中间语义张量c, 接着解码器将使⽤这个中间语义张量c以及每⼀个时间步的隐层张量, 逐个⽣成对应的翻译语⾔。
- 注意:此处编码器的输入和输出与GRU相同;解码器的输入包括隐藏层和每一次都作用的中间语义张量,还有被译文的词张量表(这点在之后构建解码器时可以体现)
1.编码器
1.1 基于GRU的编码器结构
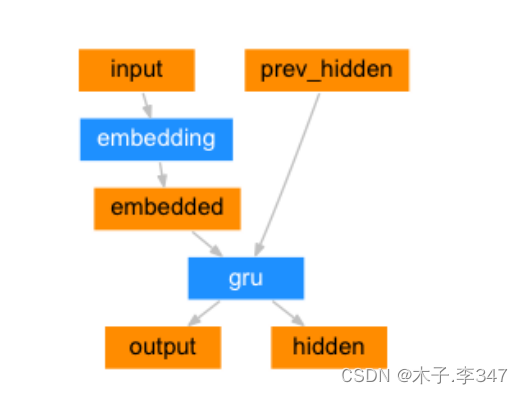
class EncoderRNN(nn.Module):
def __init__(self, input_size, hidden_size):
"""它的初始化参数有两个, input_size代表编码器的输入尺寸即源语言的词表大小(单词个数),
hidden_size代表GRU的隐层节点数, 也代表词嵌入维度(想要将每个词embedding的维度), 同时又是GRU的输入尺寸"""
super(EncoderRNN, self).__init__()
# 将参数hidden_size传入类中
self.hidden_size = hidden_size
# 实例化nn中预定义的Embedding层, 它的参数分别是input_size, hidden_size
# 这里的词嵌入维度即hidden_size
self.embedding = nn.Embedding(input_size, hidden_size)
# 然后实例化nn中预定义的GRU层, 它的参数是hidden_size
#(输入张量和隐藏层维度都为hidden_size;隐藏层数默认为1)
self.gru = nn.GRU(hidden_size, hidden_size)
def forward(self, input, hidden):
"""编码器前向逻辑函数中参数有两个, input代表源语言的Embedding层输入张量
hidden代表编码器层gru的初始隐层张量"""
# 将输入张量进行embedding操作, 并使其形状变为(1,1,-1),-1代表自动计算维度
# 理论上,我们的编码器每次只以一个词作为输入, 因此词汇映射后的尺寸应该是[1, embedding]
# 而这里转换成三维的原因是因为torch中预定义gru必须使用三维张量作为输入, 因此我们拓展了一个维度
output = self.embedding(input).view(1, 1, -1)
# 然后将embedding层的输出和传入的初始hidden作为gru的输入传入其中,
# 获得最终gru的输出output和对应的隐层张量hidden, 并返回结果
output, hidden = self.gru(output, hidden)
return output, hidden
def initHidden(self):
"""初始化隐层张量函数"""
# 将隐层张量初始化成为1x1xself.hidden_size大小的0张量
return torch.zeros(1, 1, self.hidden_size, device=device)
2.解码器
2.1 构建基于GRU的解码器
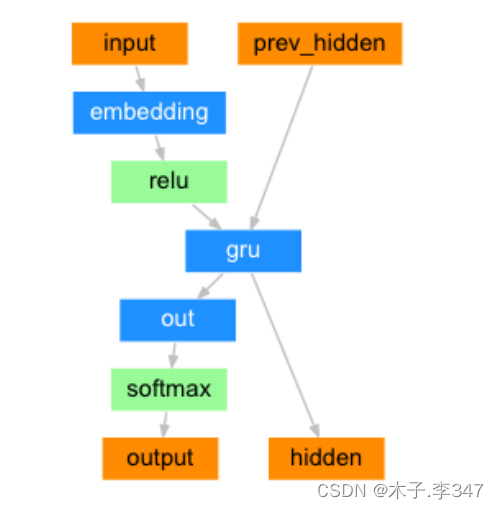
class DecoderRNN(nn.Module):
def __init__(self, hidden_size, output_size):
"""初始化函数有两个参数,hidden_size代表解码器中GRU的输入尺寸,也是它的隐层节点数
output_size代表整个解码器的输出尺寸, 也是我们希望得到的指定尺寸即目标语言的词表大小"""
super(DecoderRNN, self).__init__()
# 将hidden_size传入到类中
self.hidden_size = hidden_size
# 实例化一个nn中的Embedding层对象, 它的参数output这里表示目标语言的词表大小
# hidden_size表示目标语言的词嵌入维度
self.embedding = nn.Embedding(output_size, hidden_size)
# 实例化GRU对象,输入参数都是hidden_size,代表它的输入尺寸和隐层节点数相同
self.gru = nn.GRU(hidden_size, hidden_size)
# 实例化线性层, 对GRU的输出做线性变化, 获我们希望的输出尺寸output_size
# 因此它的两个参数分别是hidden_size, output_size
self.out = nn.Linear(hidden_size, output_size)
# 最后使用softmax进行处理,以便于分类
self.softmax = nn.LogSoftmax(dim=1)#列上进行
def forward(self, input, hidden):
"""解码器的前向逻辑函数中, 参数有两个, input代表目标语言的Embedding层输入张量
hidden代表解码器GRU的初始隐层张量"""
# 将输入张量进行embedding操作, 并使其形状变为(1,1,-1),-1代表自动计算维度
# 原因和解码器相同,因为torch预定义的GRU层只接受三维张量作为输入
output = self.embedding(input).view(1, 1, -1)
# 然后使用relu函数对输出进行处理,根据relu函数的特性, 将使Embedding矩阵更稀疏,以防止过拟合
output = F.relu(output)
# 接下来, 将把embedding的输出以及初始化的hidden张量传入到解码器gru中
output, hidden = self.gru(output, hidden)
# 因为GRU输出的output也是三维张量,第一维没有意义(尺寸为1*1*hidden_size),因此可以通过output[0]来降维
# 再传给线性层做变换, 最后用softmax处理以便于分类(output[0]表示output的第0层)
output = self.softmax(self.out(output[0]))#self.out(output[0])尺寸为1*hidden_size
return output, hidden
def initHidden(self):
"""初始化隐层张量函数"""
# 将隐层张量初始化成为1x1xself.hidden_size大小的0张量
return torch.zeros(1, 1, self.hidden_size, device=device)
2.2 构建基于GRU和Attention的解码器
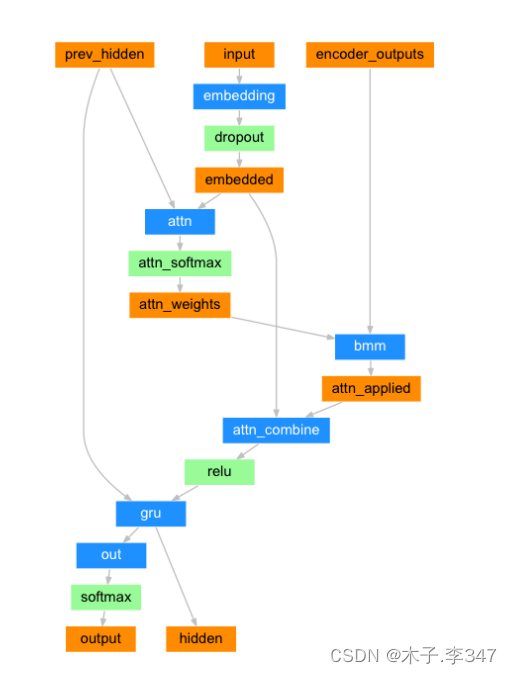
- 这里可以找到注意力机制中的Q、K、V;
- Q:embedded
- K:prev _hidden
- V:encoder_outputs
class AttnDecoderRNN(nn.Module):
def __init__(self, hidden_size, output_size, dropout_p=0.1, max_length=MAX_LENGTH):#MAX_LENGTH=10
"""初始化函数中的参数有4个, hidden_size代表解码器中GRU的输入尺寸,也是它的隐层节点数
output_size代表整个解码器的输出尺寸, 也是我们希望得到的指定尺寸即目标语言的词表大小
dropout_p代表我们使用dropout层时的置零比率,默认0.1, max_length代表句子的最大长度"""
super(AttnDecoderRNN, self).__init__()
# 将以下参数传入类中
self.hidden_size = hidden_size
self.output_size = output_size
self.dropout_p = dropout_p
self.max_length = max_length
# 实例化一个Embedding层, 输入参数是self.output_size和self.hidden_size
self.embedding = nn.Embedding(self.output_size, self.hidden_size)
# 根据attention的QKV理论,attention的输入参数为三个Q,K,V,
# 我们这里使用的是第一步中的第一种计算方式, 因此需要一个线性变换的矩阵, 实例化nn.Linear
# 因为它的输入是Q,K的拼接, 所以输入的第一个参数是self.hidden_size * 2,第二个参数是self.max_length
# 这里的Q是解码器的Embedding层的输出, K是解码器GRU的隐层输出,因为首次隐层还没有任何输出,会使用编码器的隐层输出
# 而这里的V是编码器层的输出
self.attn = nn.Linear(self.hidden_size * 2, self.max_length)
# 接着我们实例化另外一个线性层, 它是attention理论中的第四步的线性层,用于规范输出尺寸
# 这里它的输入来自第三步的结果, 因为第三步的结果是将Q与第二步的结果进行拼接, 因此输入维度是self.hidden_size * 2
self.attn_combine = nn.Linear(self.hidden_size * 2, self.hidden_size)
# 接着实例化一个nn.Dropout层,并传入self.dropout_p
self.dropout = nn.Dropout(self.dropout_p)
# 之后实例化nn.GRU, 它的输入和隐层尺寸都是self.hidden_size
self.gru = nn.GRU(self.hidden_size, self.hidden_size)
# 最后实例化gru后面的线性层,也就是我们的解码器输出层.
self.out = nn.Linear(self.hidden_size, self.output_size)
def forward(self, input, hidden, encoder_outputs):
"""forward函数的输入参数有三个, 分别是源数据输入张量, 初始的隐层张量, 以及解码器的输出张量"""
# 根据结构计算图, 输入张量进行Embedding层并扩展维度
embedded = self.embedding(input).view(1, 1, -1) # 输出1*1*hidden_size
# 使用dropout进行随机丢弃,防止过拟合
embedded = self.dropout(embedded)
# 进行attention的权重计算, 哦我们呢使用第一种计算方式:
# 将Q,K进行纵轴拼接, 做一次线性变化, 最后使用softmax处理获得结果
# embedded[0], hidden[0]尺寸均为1*hidden_size;attn_weights输出为1*10
attn_weights = F.softmax(
self.attn(torch.cat((embedded[0], hidden[0]), 1)), dim=1)
# 然后进行第一步的后半部分, 将得到的权重矩阵与V做矩阵乘法计算, 当二者都是三维张量且第一维代表为batch条数时, 则做bmm运算
# 即,(1*1*MAX_LENGTH)1*1*10 (1*MAX_LENGTH*hidden_size)1*10*25
attn_applied = torch.bmm(attn_weights.unsqueeze(0),
encoder_outputs.unsqueeze(0))
# 之后进行第二步, 通过取[0]是用来降维, 根据第一步采用的计算方法, 需要将Q与第一步的计算结果再进行拼接
output = torch.cat((embedded[0], attn_applied[0]), 1)
# 最后是第三步, 使用线性层作用在第三步的结果上做一个线性变换并扩展维度,得到输出
output = self.attn_combine(output).unsqueeze(0)
# attention结构的结果使用relu激活
output = F.relu(output)
# 将激活后的结果作为gru的输入和hidden一起传入其中
output, hidden = self.gru(output, hidden)
# 最后将结果降维并使用softmax处理得到最终的结果 这里的1和 -1都可以
output = F.log_softmax(self.out(output[0]), dim=1)
# 返回解码器结果,最后的隐层张量以及注意力权重张量
return output, hidden, attn_weights
def initHidden(self):
"""初始化隐层张量函数"""
# 将隐层张量初始化成为1x1xself.hidden_size大小的0张量
return torch.zeros(1, 1, self.hidden_size, device=device)















 8477
8477











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









