






神经网络

1.神经网络基础
1.1线性函数
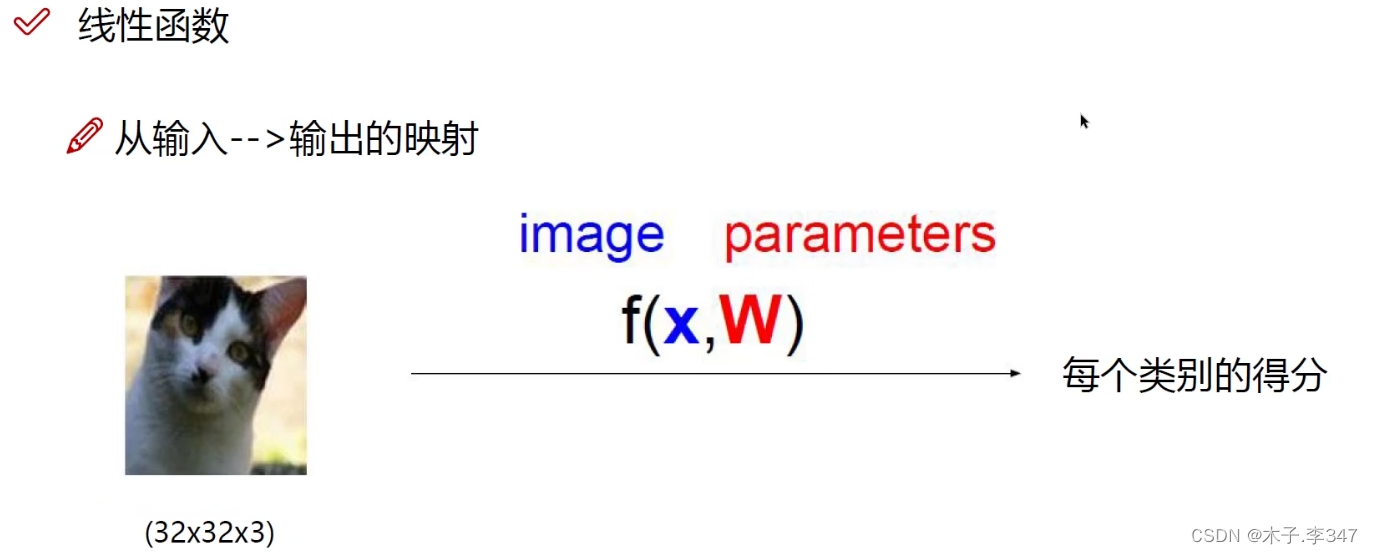
x为图像,W为权重值,f输出对于该图像的得分值
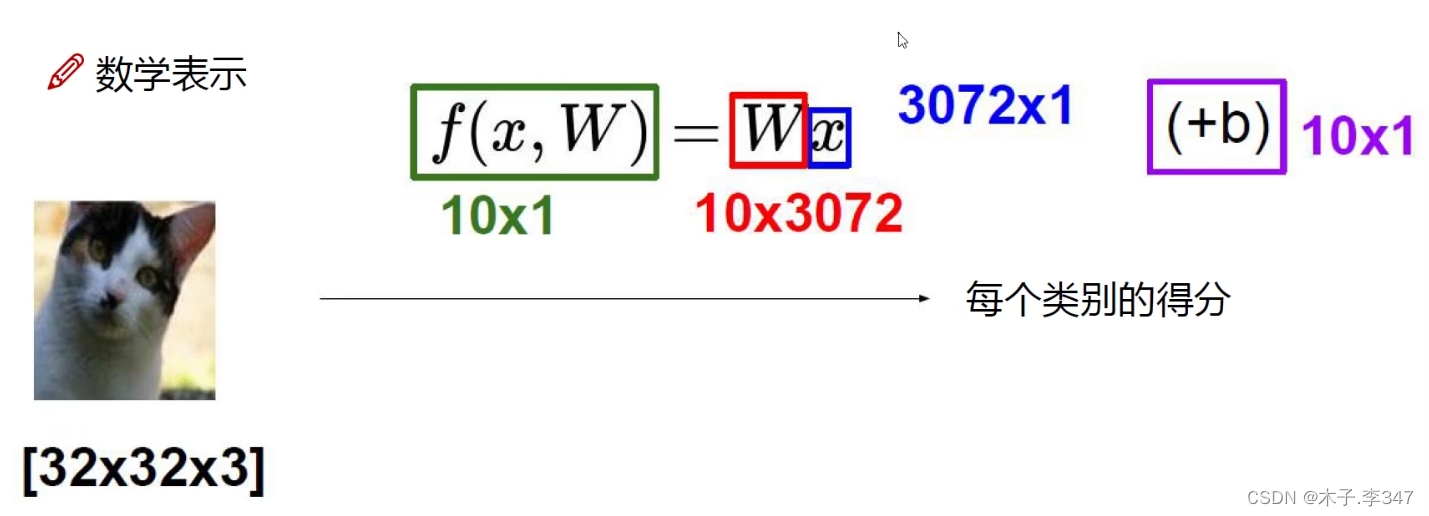
以图片(图像以32* 32*3=3072为例)分类(10类)为例:
f值(10 * 1)就是对一张图像的类别打分值;
W(10 * 3072)包含对3072个像素点每一点的权重值;
x(3072 * 1)图像的列向量;
b(10 * 1)每一个类别的偏移量(感觉像消除误差的)
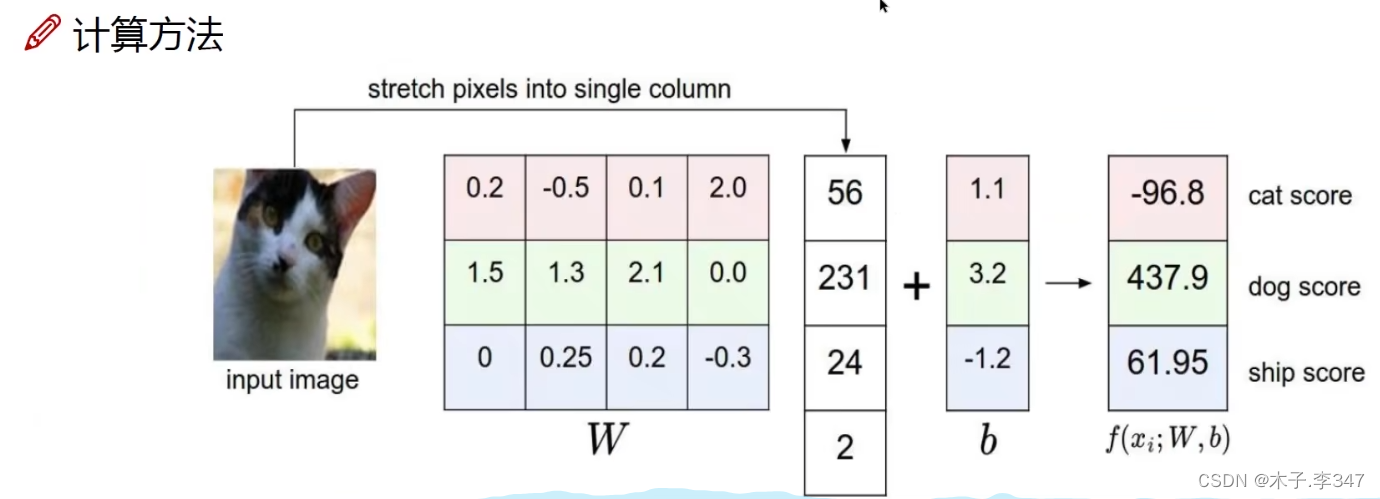
以3类图像,图像为2*2的为例
1.2损失函数
结果的得分值可以指出模型的当前效果,有多好或是多差!

损失函数Li (越小越好,越大表示分类效果越差)中sj 为该图像在其他类别中的得分值,syi 为该图像在自己类别中的打分;其中+1是为了防止得分比较近的时候,使得误判损失为0(如:第一幅图打分为3.2,3.15,-1.7,则计算cat和car之间的损失时,不加1,输出为0,表示两者无误差,但实际是不对的),也就是让正确类别比错误类别高于1以上才无损失。


R(W)为所有权重阵的平方和,λ惩罚系数,越大表示不希望过拟合,削减奇异值,越小表示削减程度小点。
过拟合是指模型在训练数据上表现良好,但在未见过的测试数据上表现较差的情况。这种情况通常发生在模型过于复杂、参数过多的情况下,导致模型过度记忆了训练数据的噪声和细节,而忽略了数据的整体趋势和泛化能力。过拟合的模型对训练数据过于敏感,可能会出现过度拟合噪声的情况,导致泛化能力下降。
正则化是一种通过修改学习算法以减少泛化误差的策略,它通过对模型添加额外的约束和惩罚来改善模型在测试集上的表现
1.3激活函数
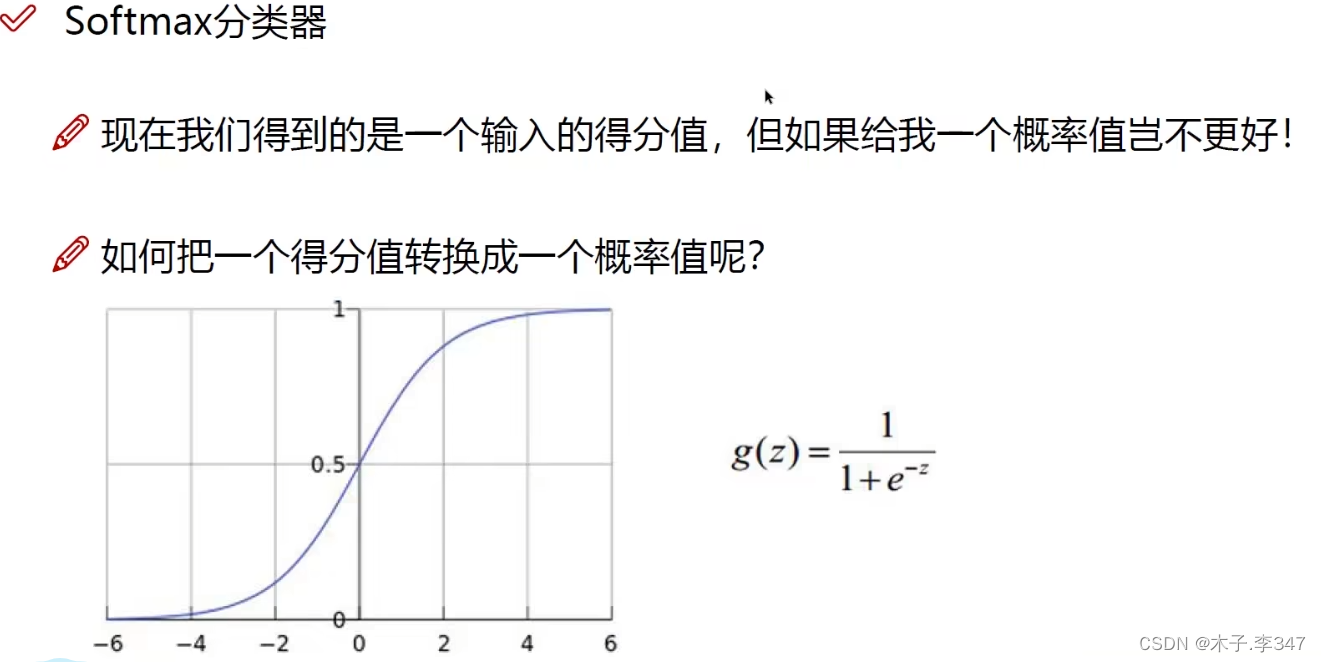
使得得分值的范围归到0-1之间

第一列为类别的得分值;第二列为exp(得分);第三列为归一化(第二列每个值都除以所有的求和值),最后求-log(越接近0表示损失越小,分类越好)
1.4前向传播
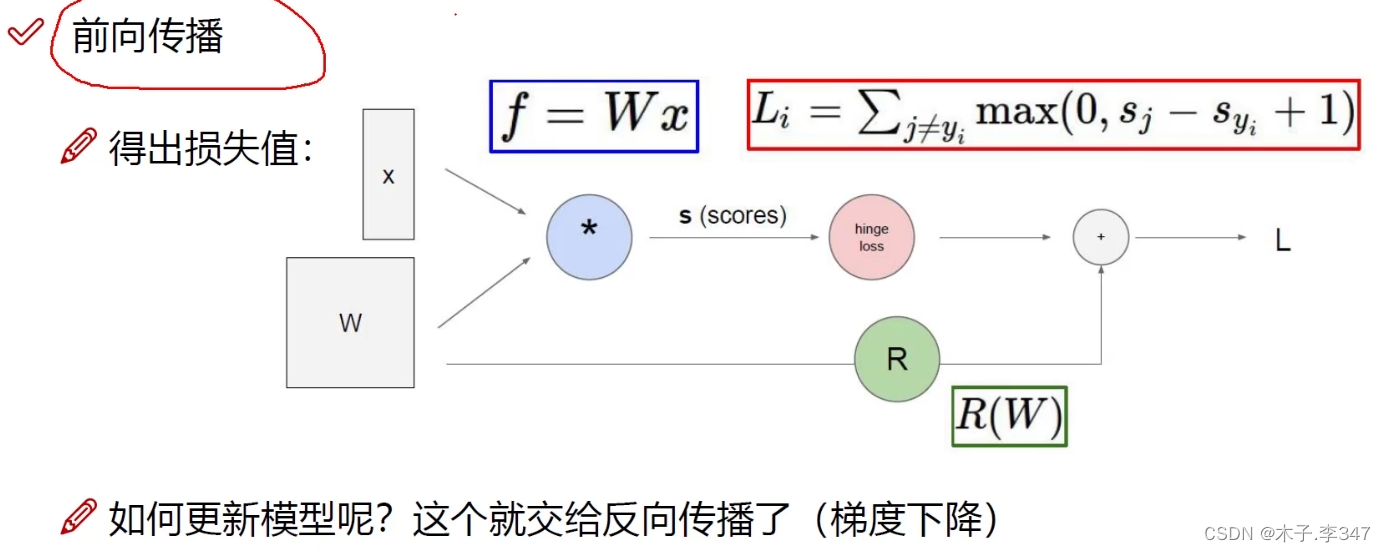



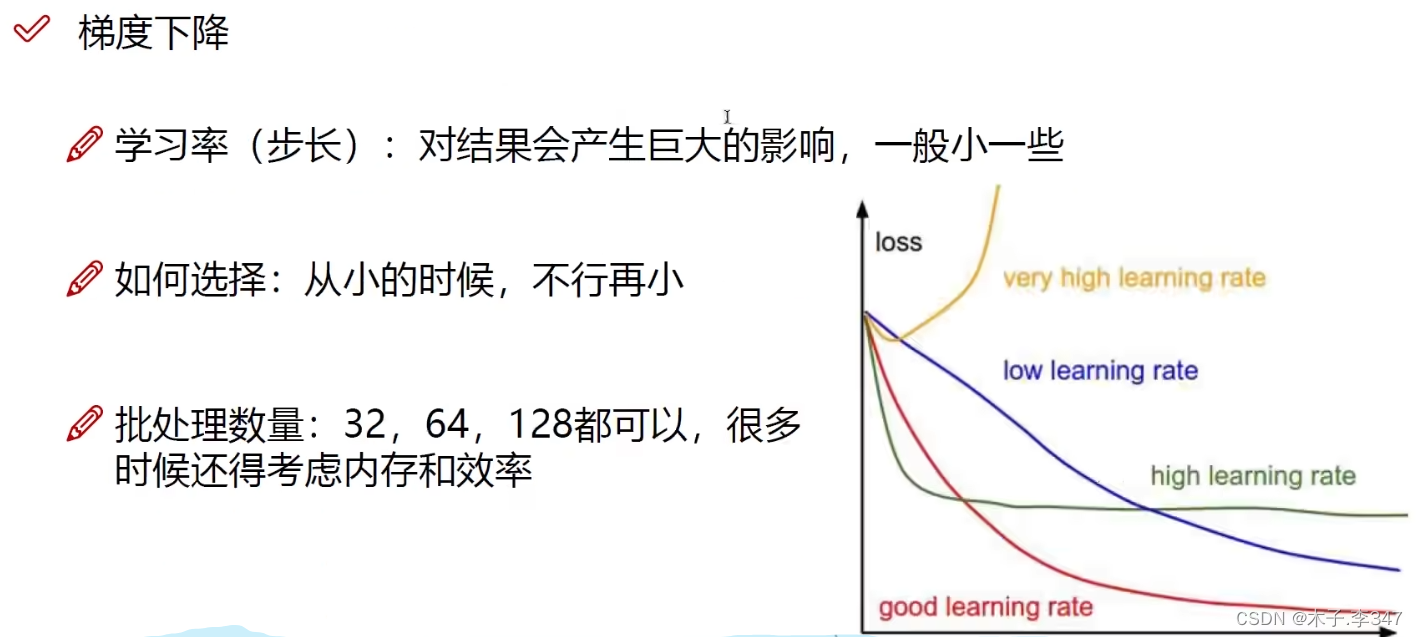
1.5反向传播
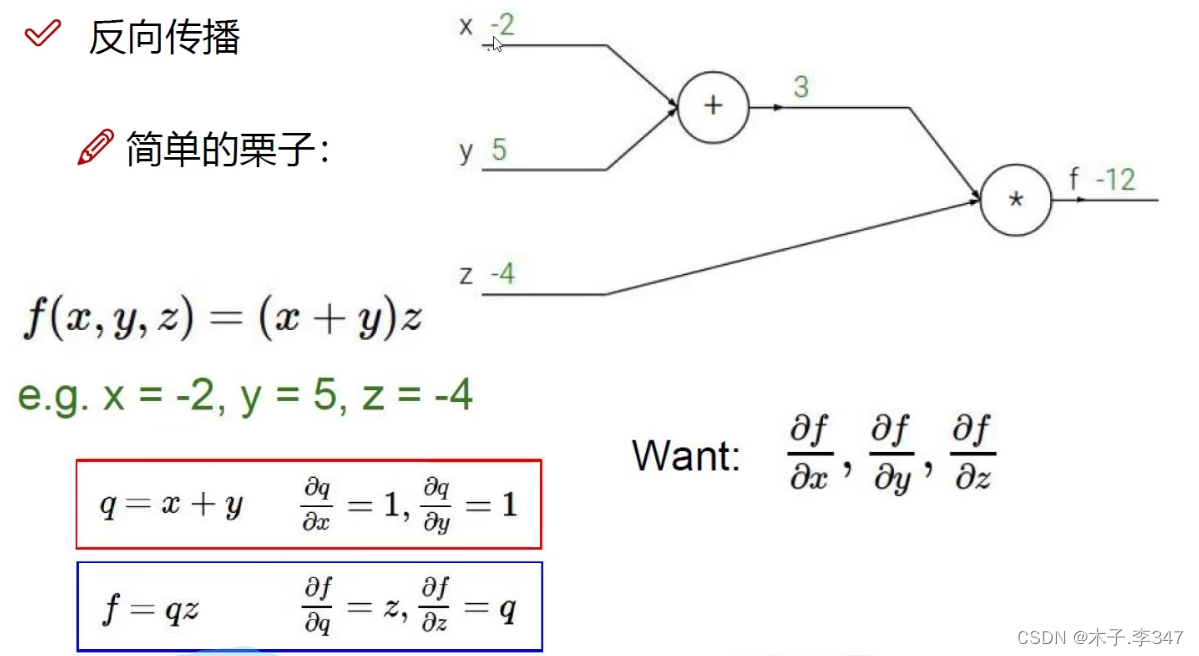
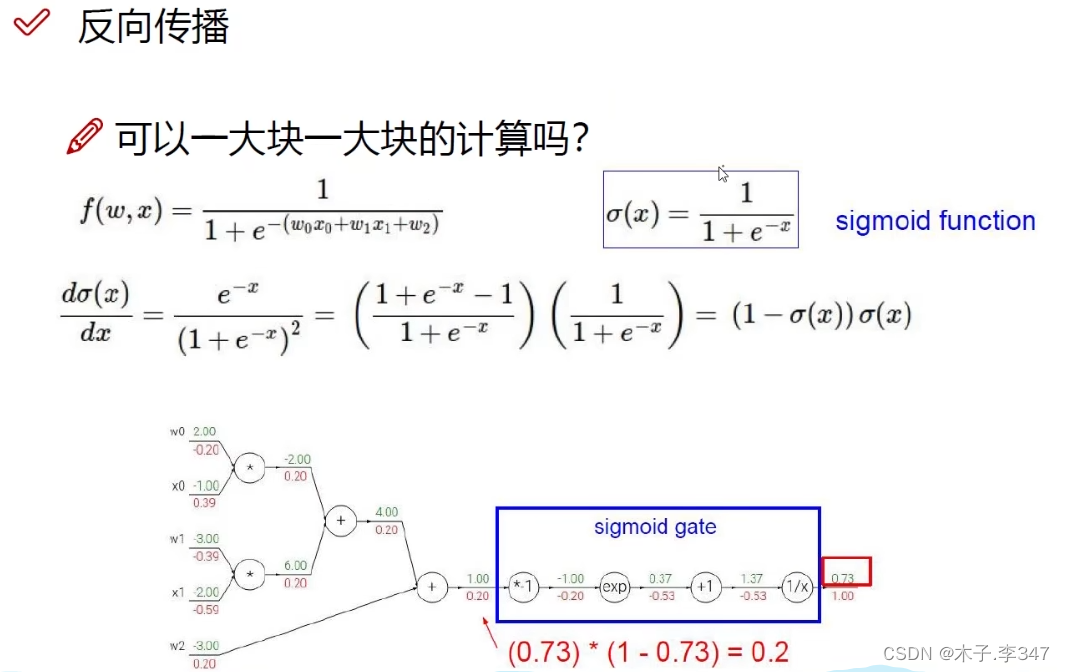
链式求导法则
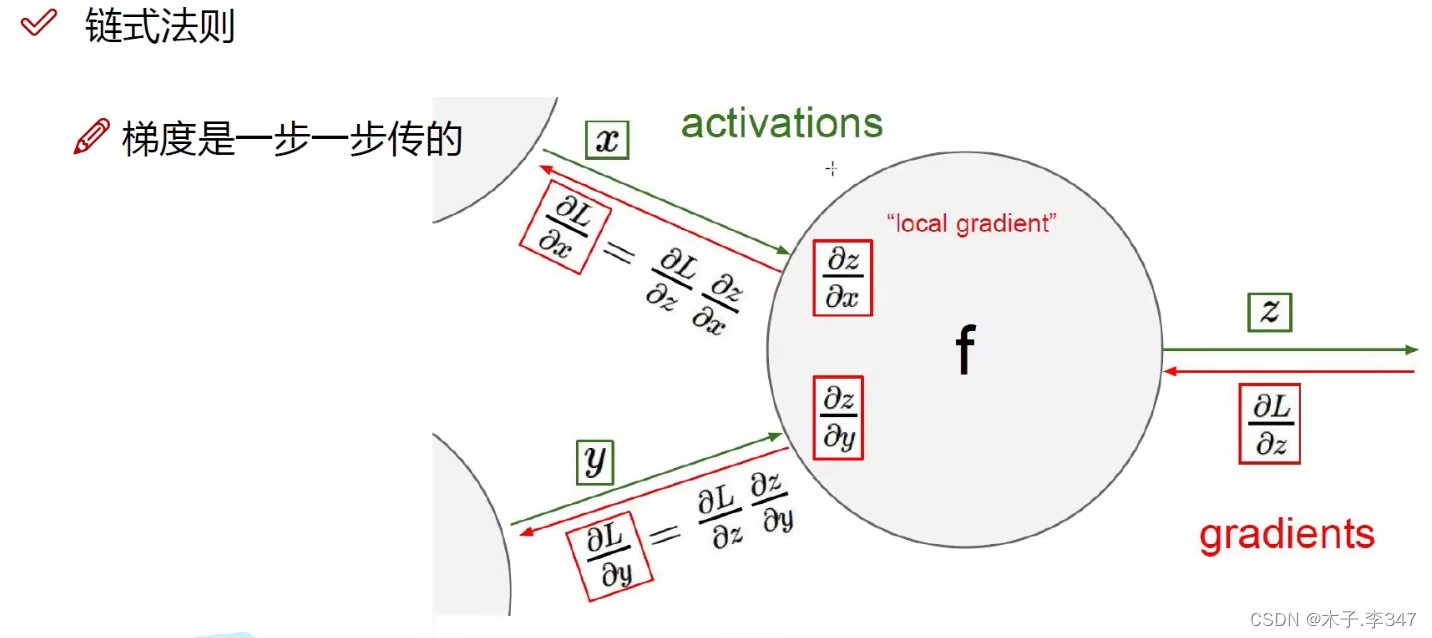
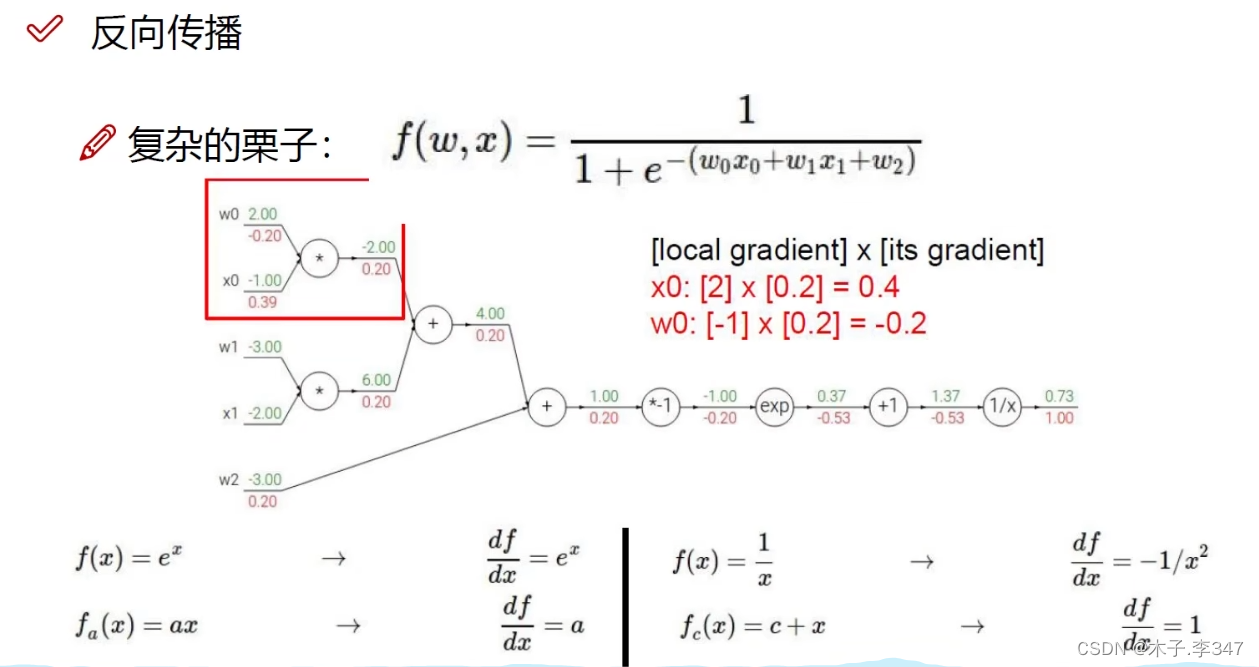
图中,绿色表示相应的输入量,红色表示链式求导的逆向输出值(如:1/x的导数为-1/x2 ,x=1.37,输出为下面的-0.53)
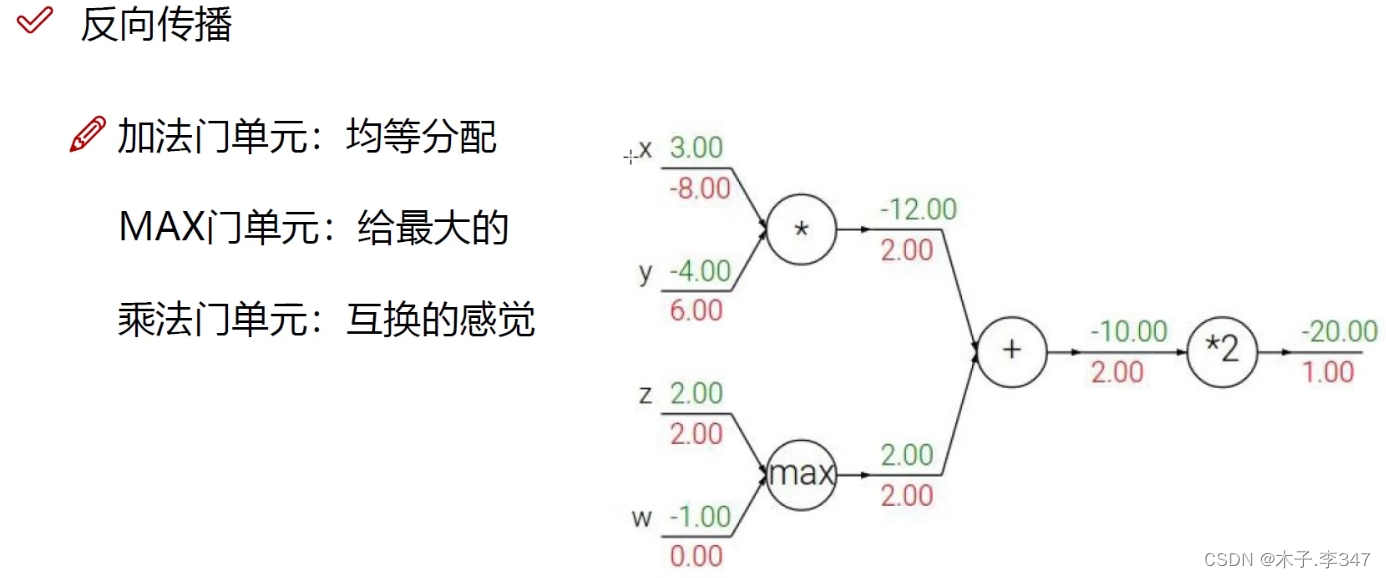
该图表示:加法的导数都为1,MAX的导数是输入最大的变量导数为整个输出;
乘法导数互换。
1.6整体框架
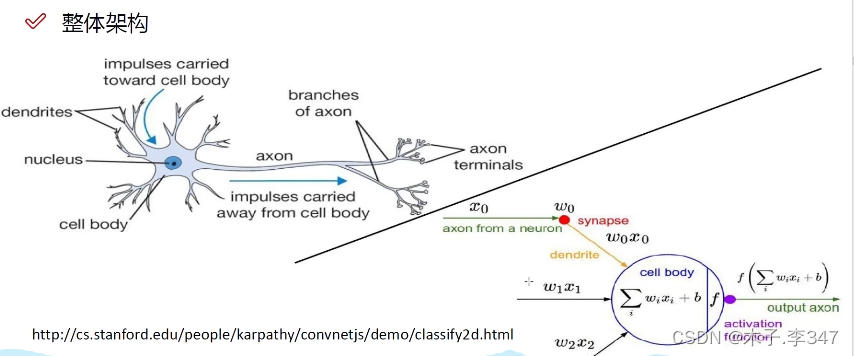
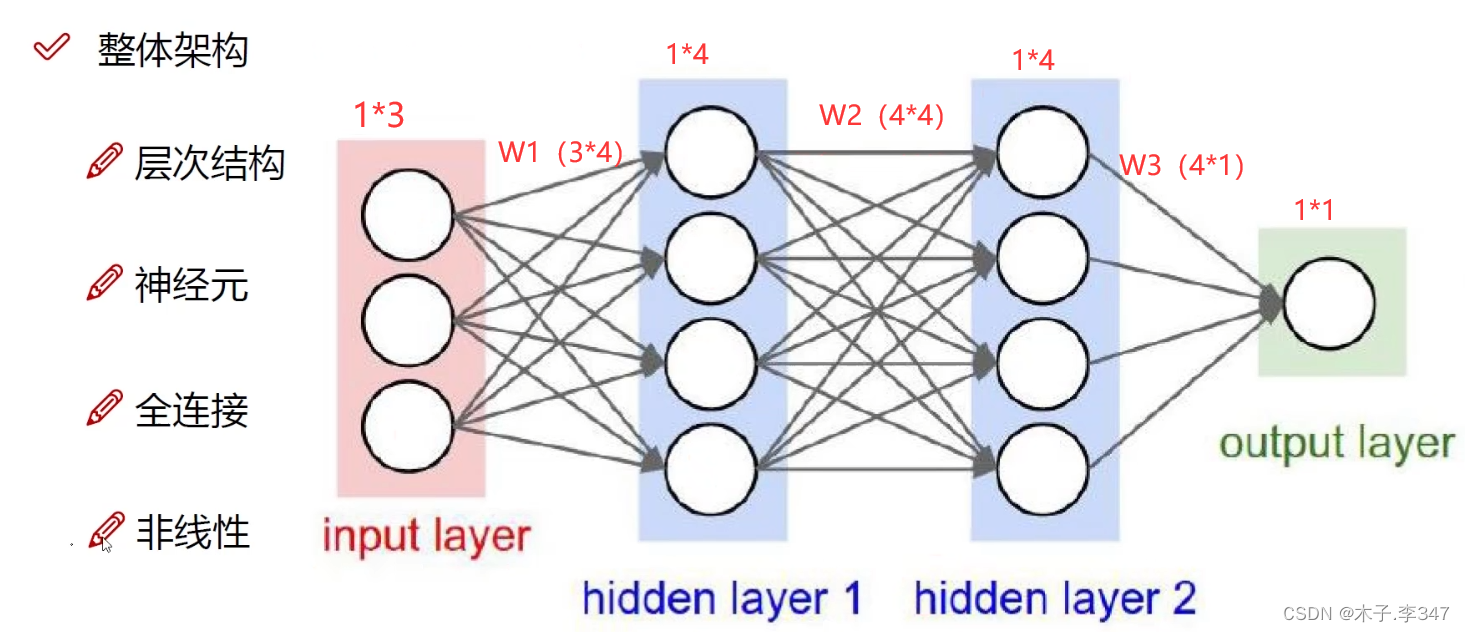
隐藏层:对输入的每个数据都附上权重值(几个圆(神经元)代表有多少种权重)。
每一隐藏层后都进行非线性变化(激活函数,如sigmoid,max)。
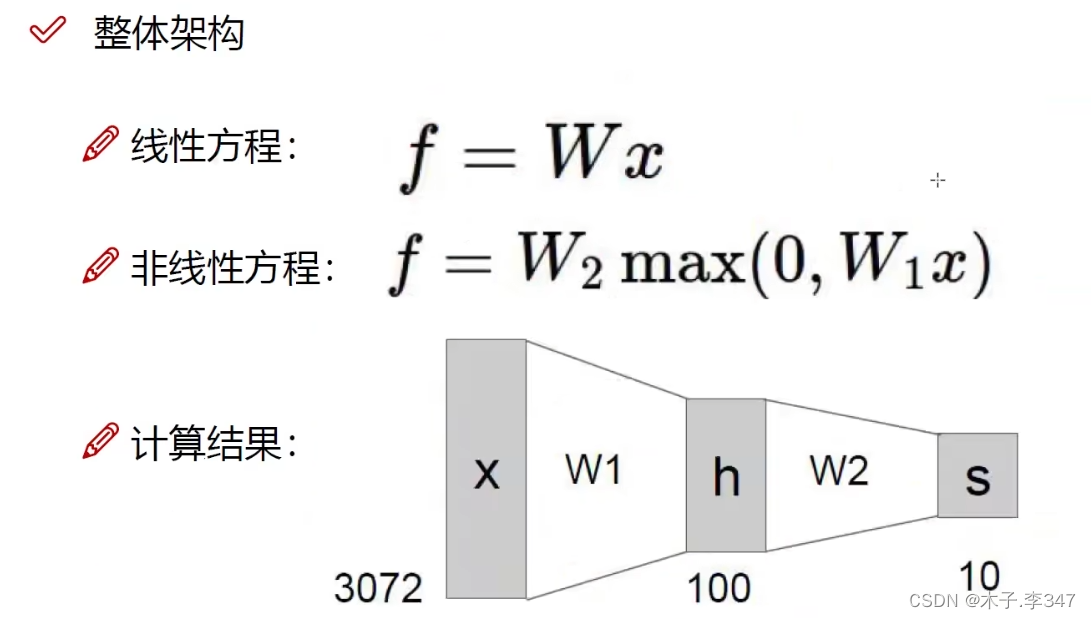
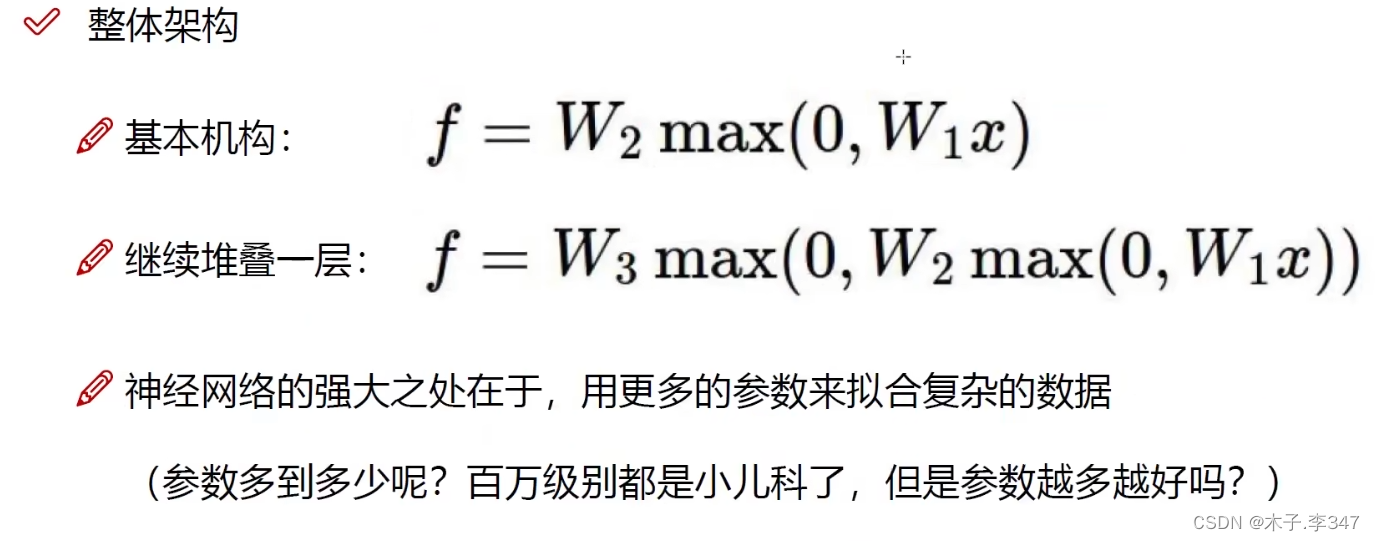
神经元越多过拟合程度也越大,效果可能越好,但速度越慢
斯坦福大学可视化神经网络训练
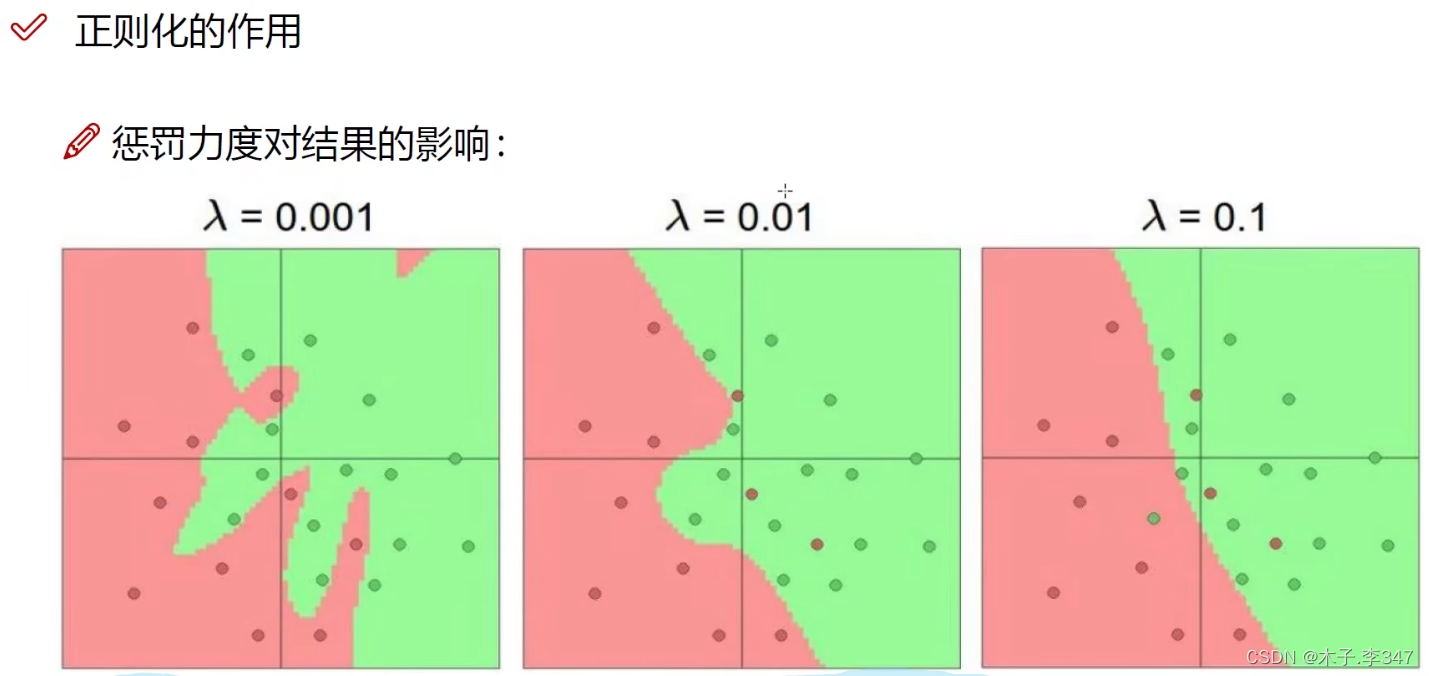
惩罚力度越大过拟合效果越弱。
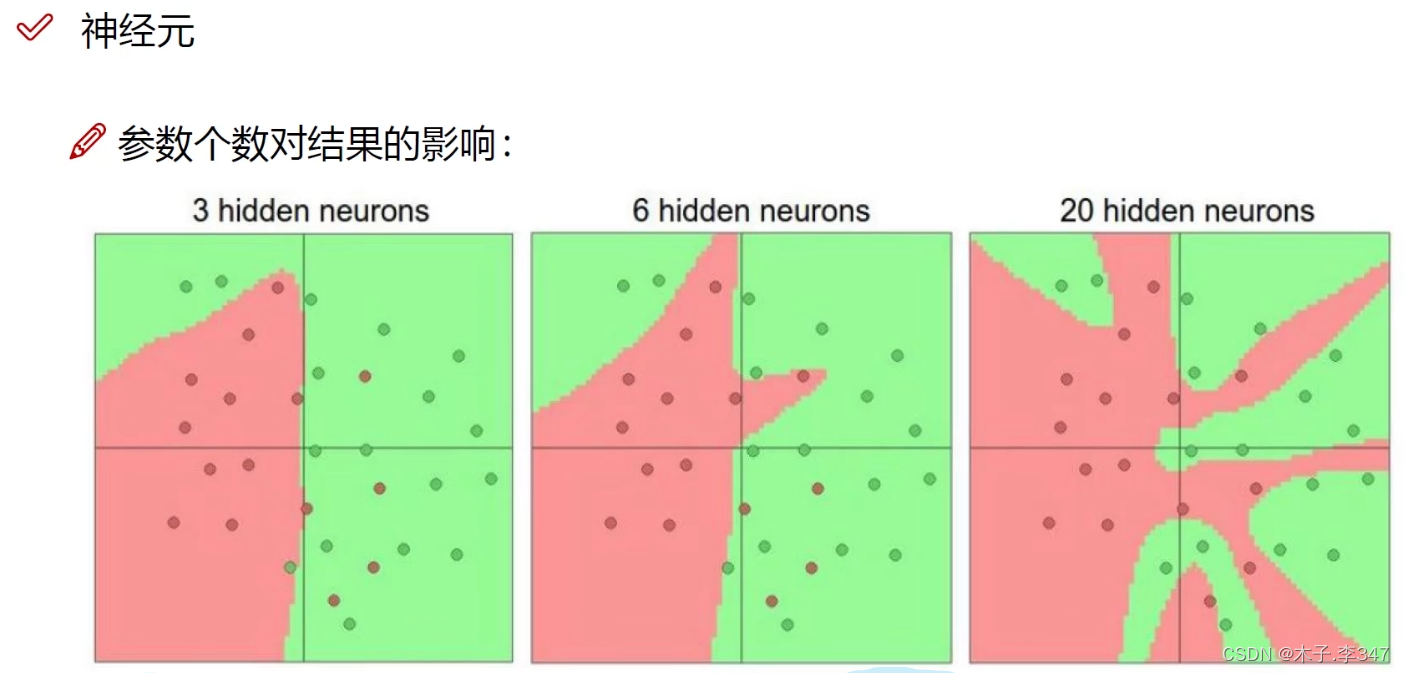
隐藏层神经元一般为64,128,256,512。可见神经元数目越多过拟合越大

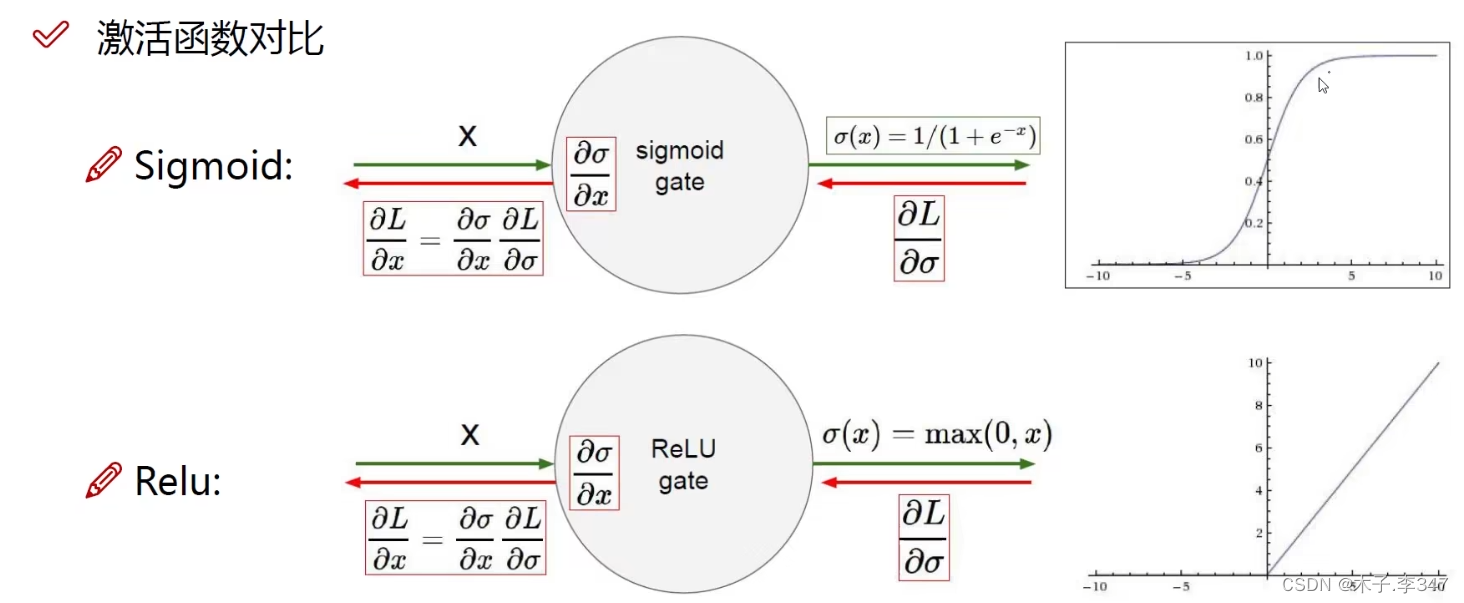
sigmoid函数当自变量过大会出现梯度消失,变为0.
1.7数据预处理
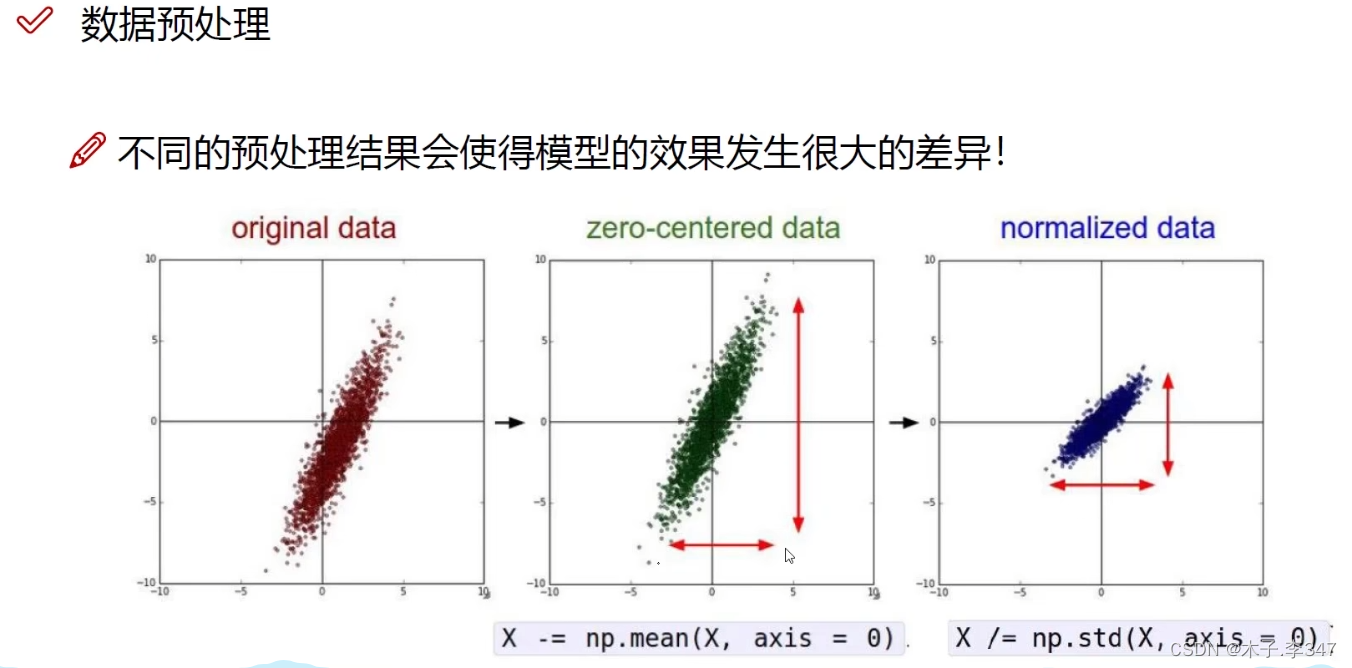

形成权重矩阵(D*H的矩阵)
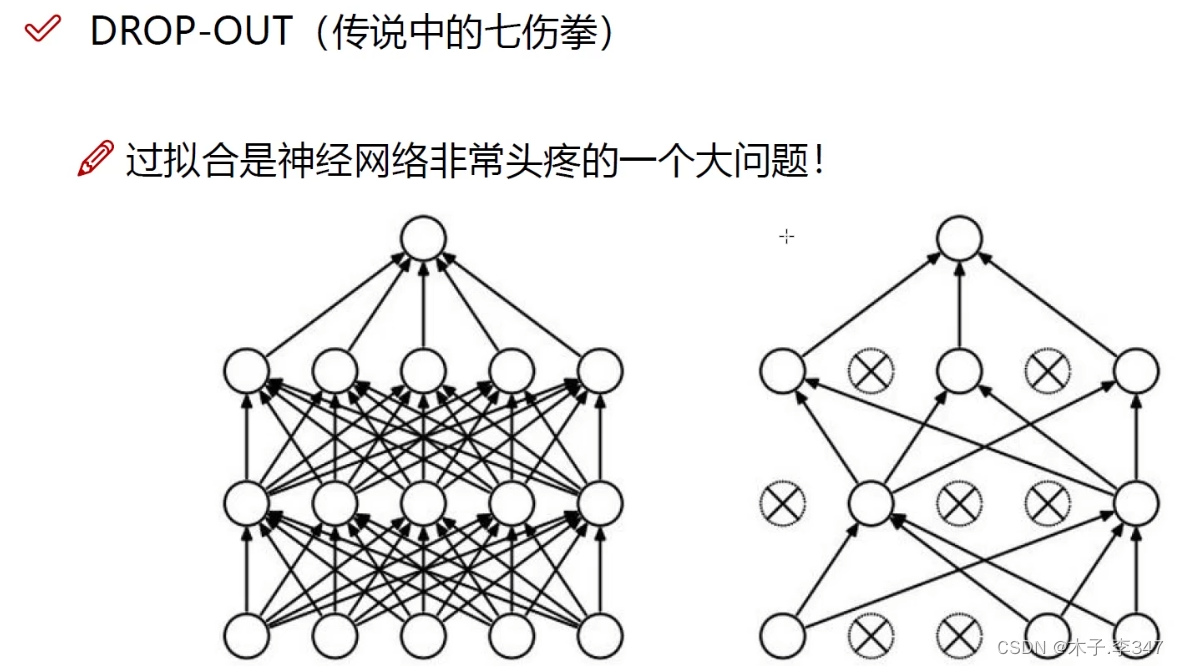
在每一层中随机选取少量神经元参与计算,以此避免过拟合。
总结:
输入数据经过预处理,*W1——>激活函数…*Wn——>激活函数,输出。
之后计算损失函数,通过反向传播对每一个参数进行求导,以修正参数值。
2.卷积神经网络(CNN)
输入不再是列向量,而直接是一张图像
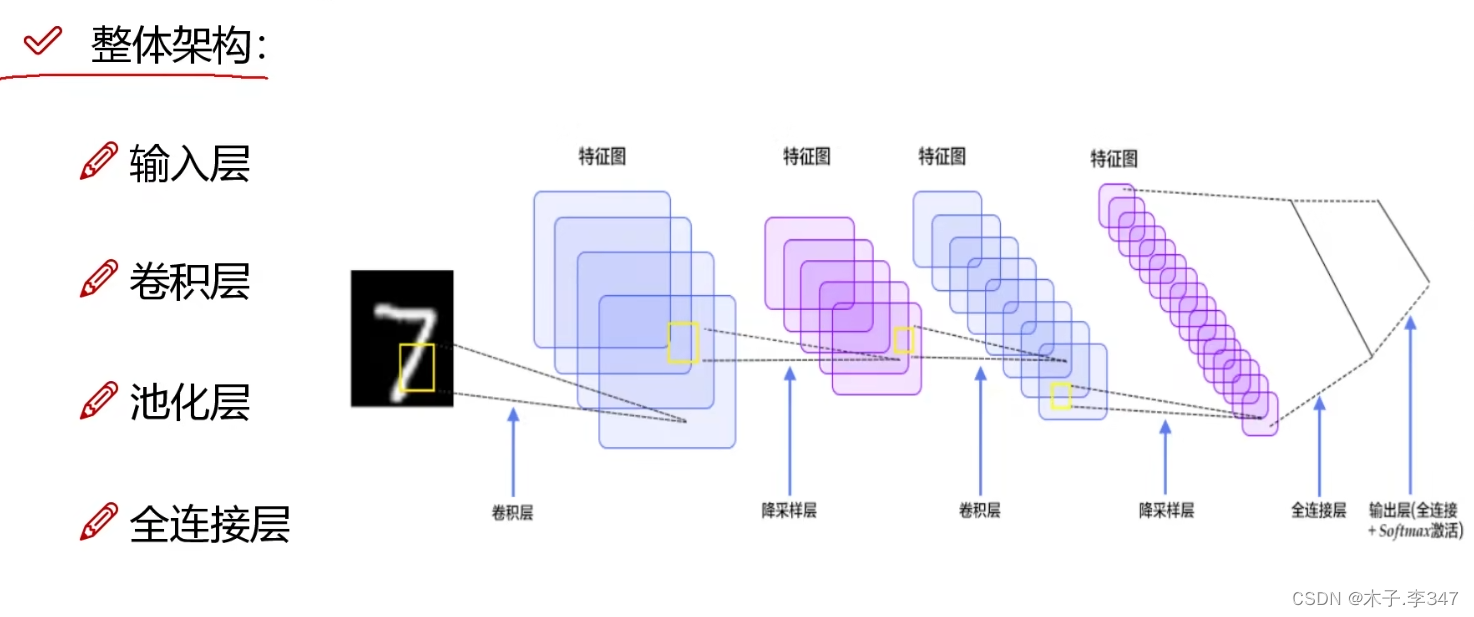
2.1卷积
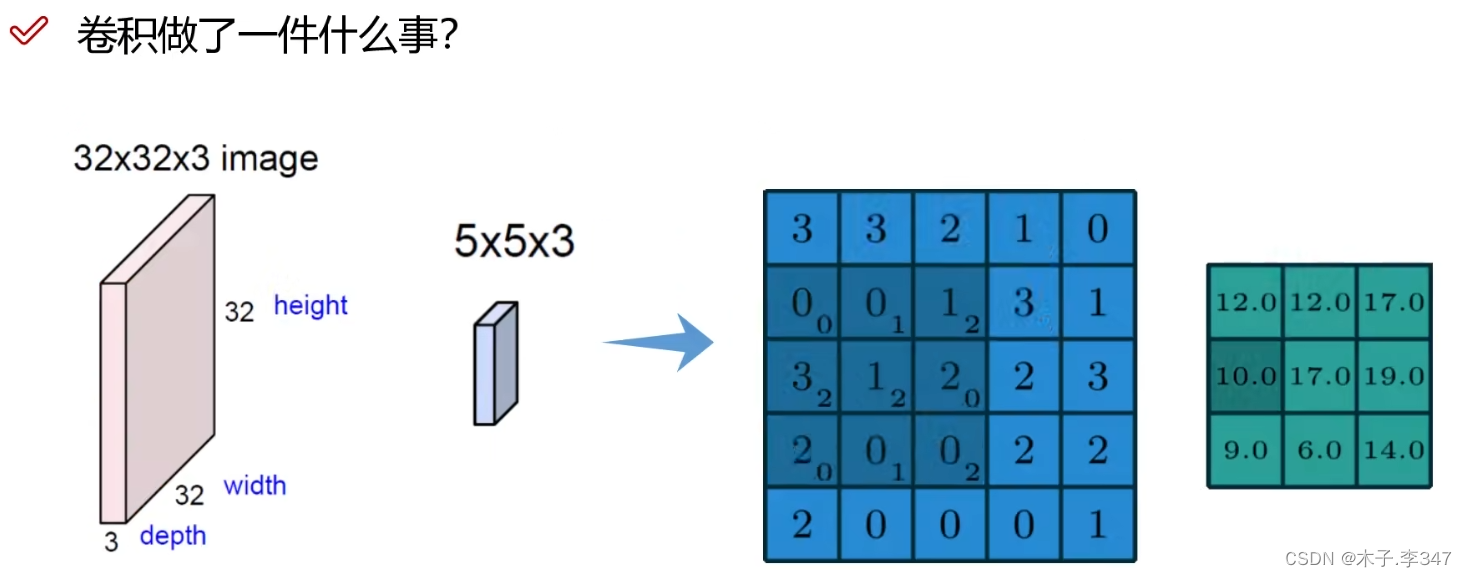
三通道图像:每一通道都进行卷积,之后相加。

有多个卷积核就会输出几层特征图。(图中bias表示w*x+b中的b偏移量)
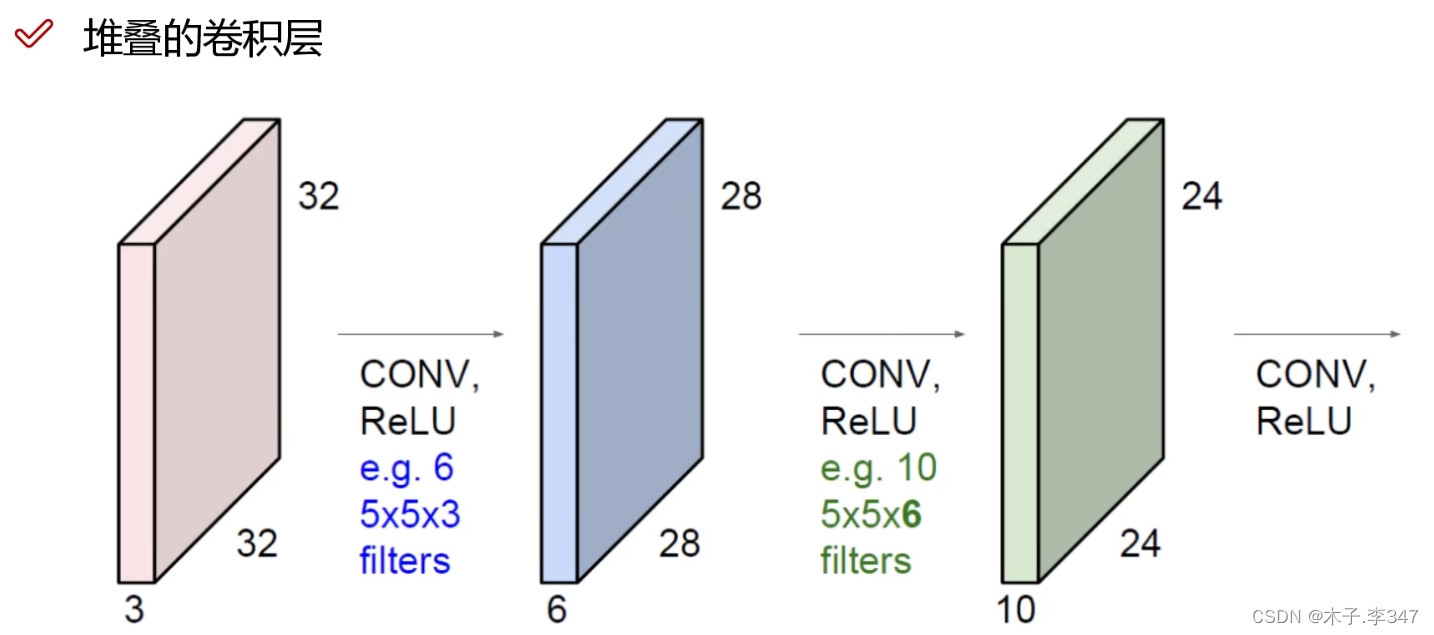
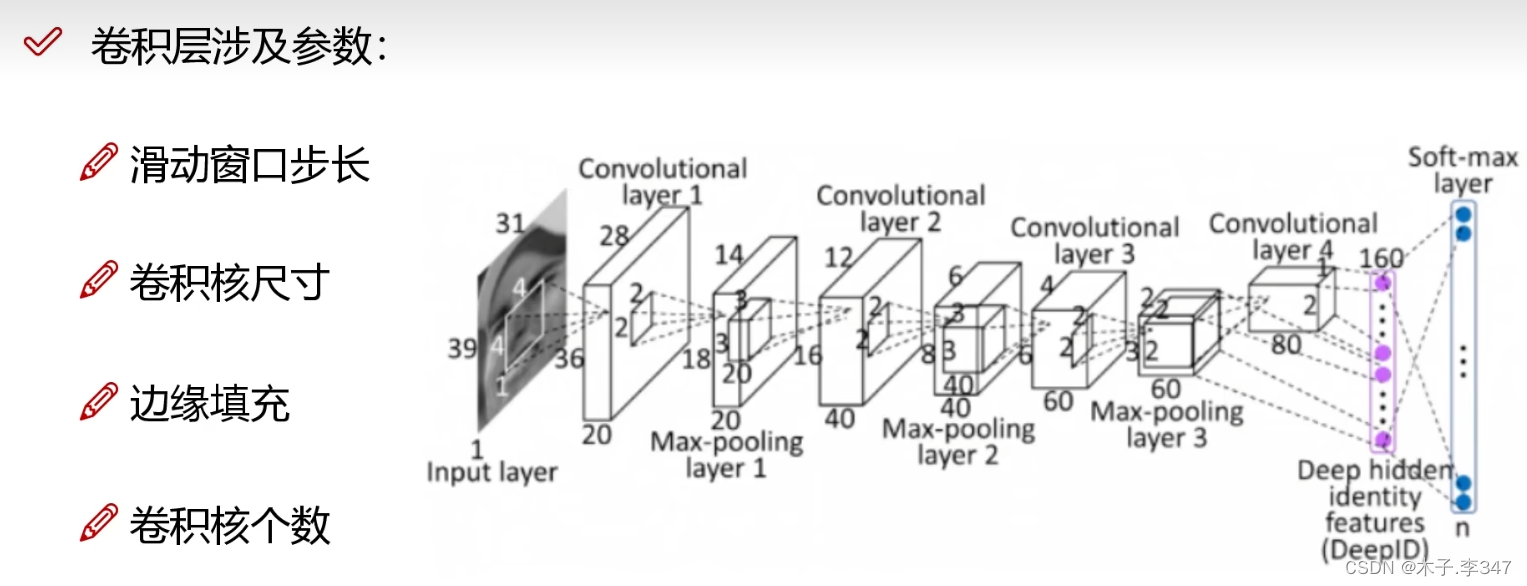
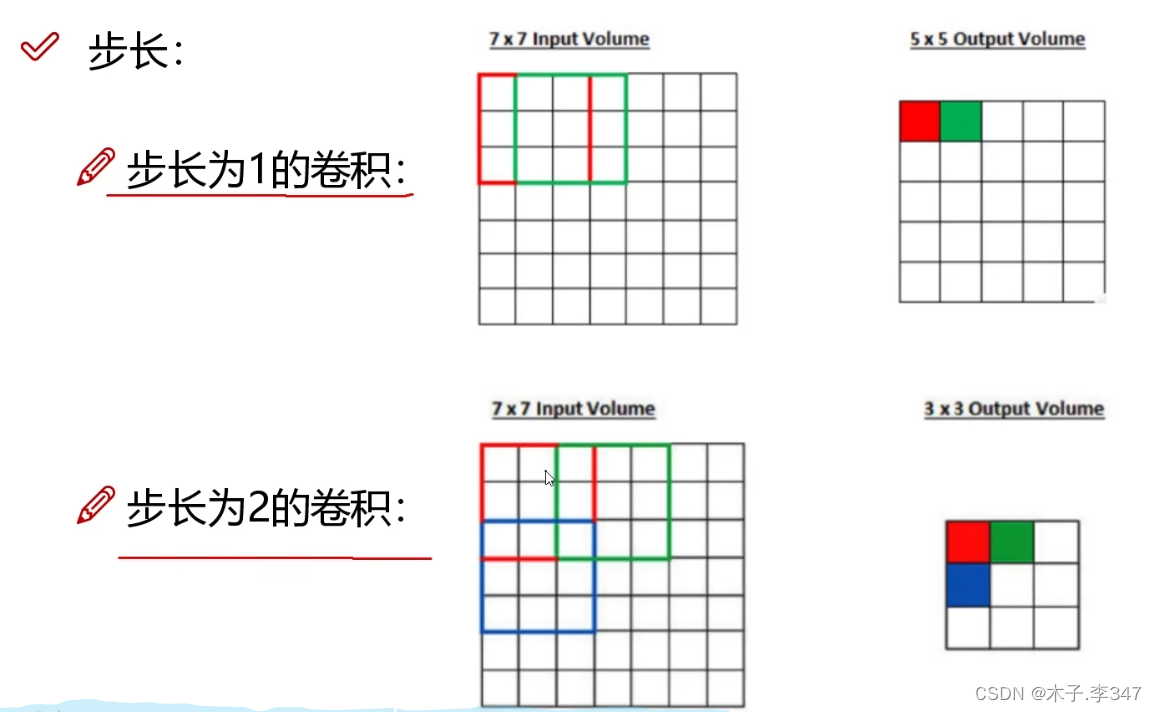
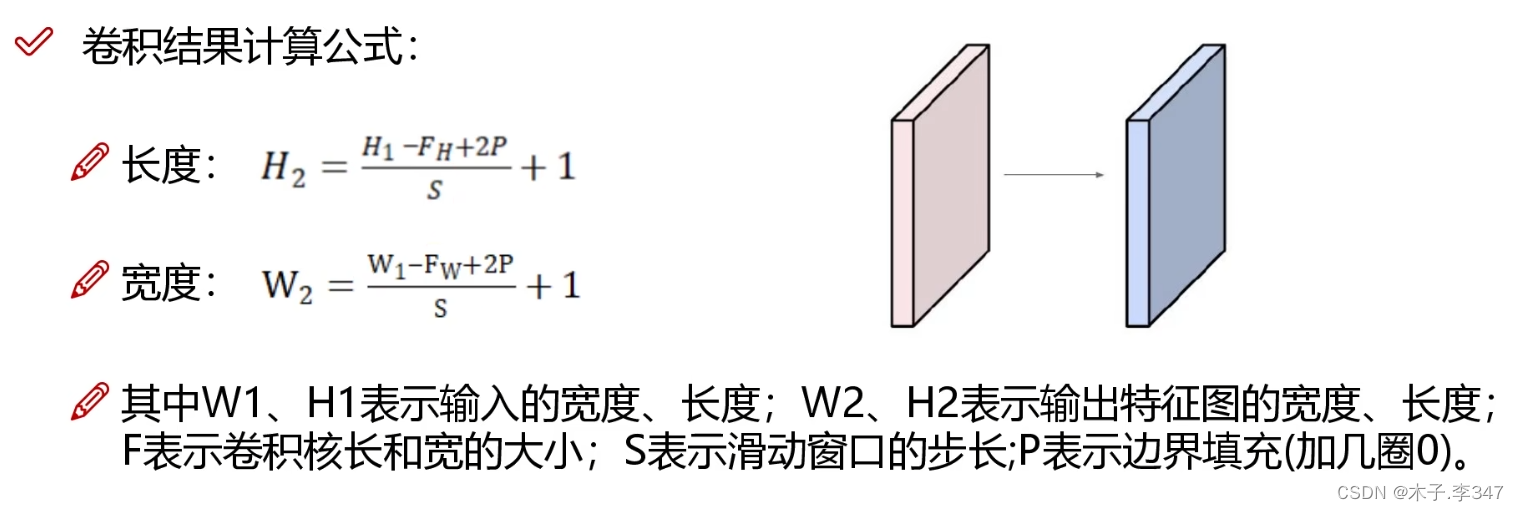

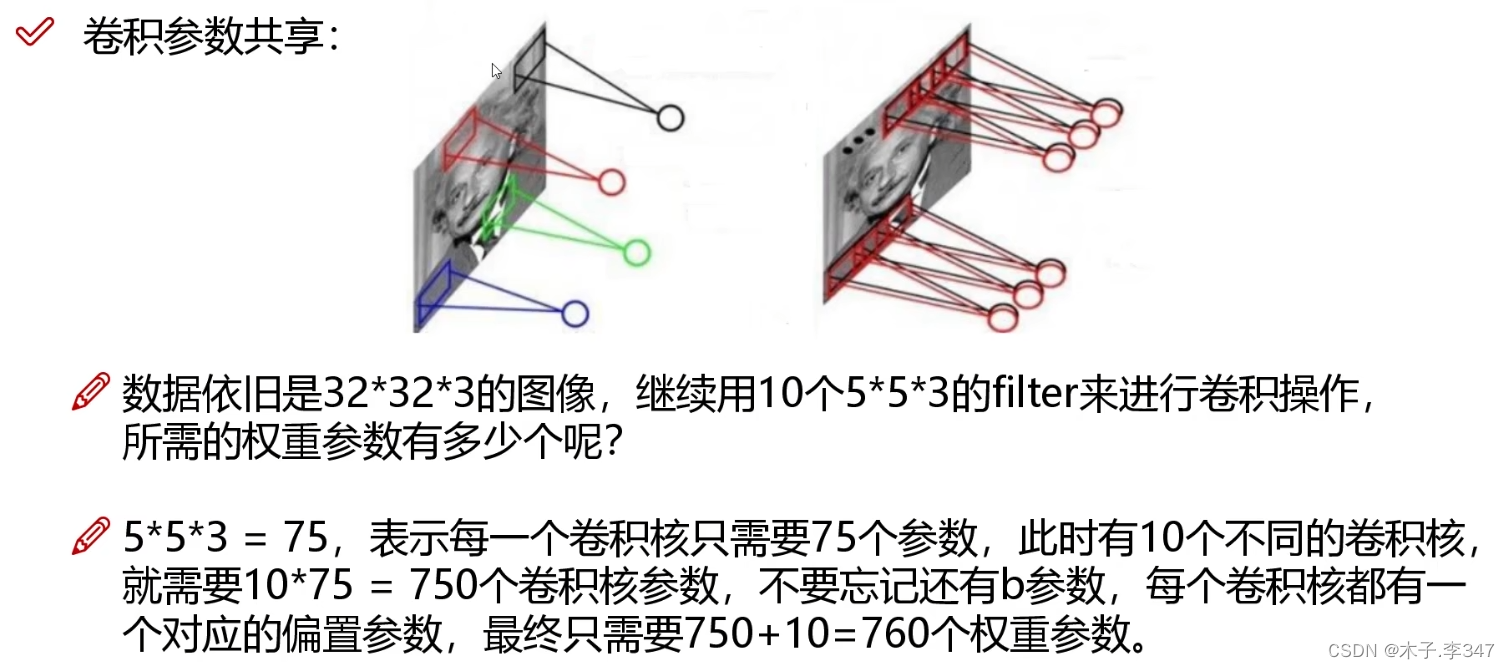
2.2池化层
降低特征图的大小,也称压缩或下采样
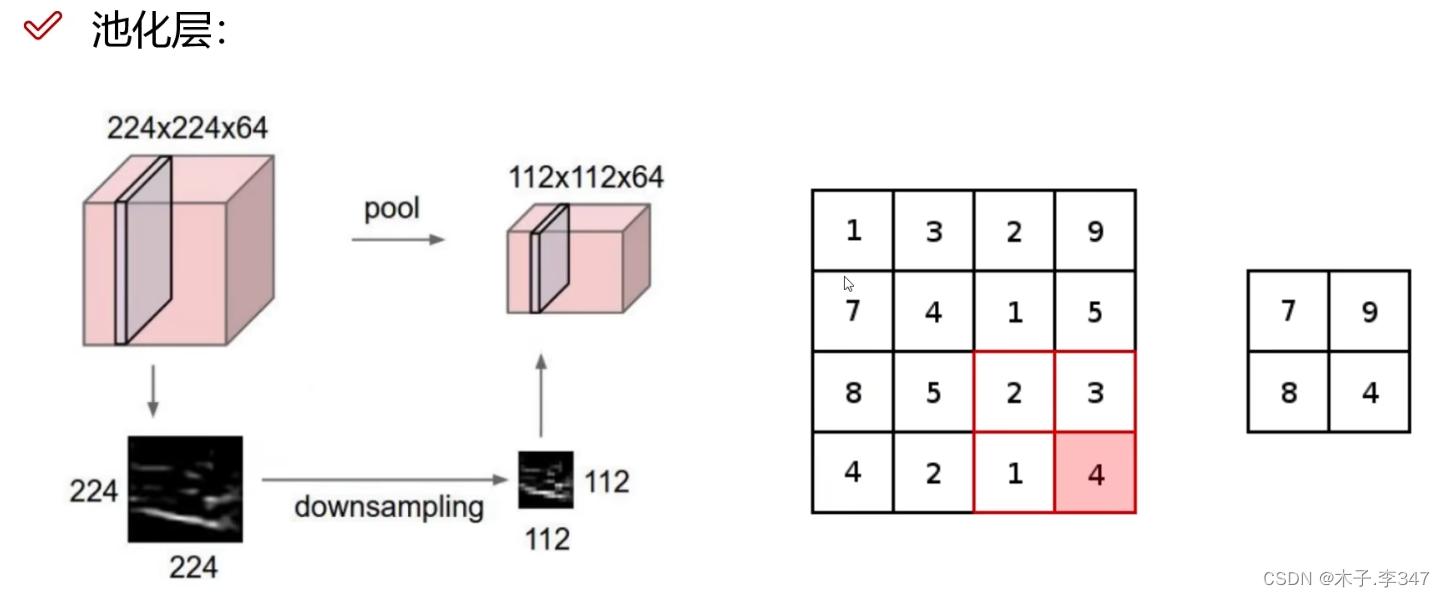
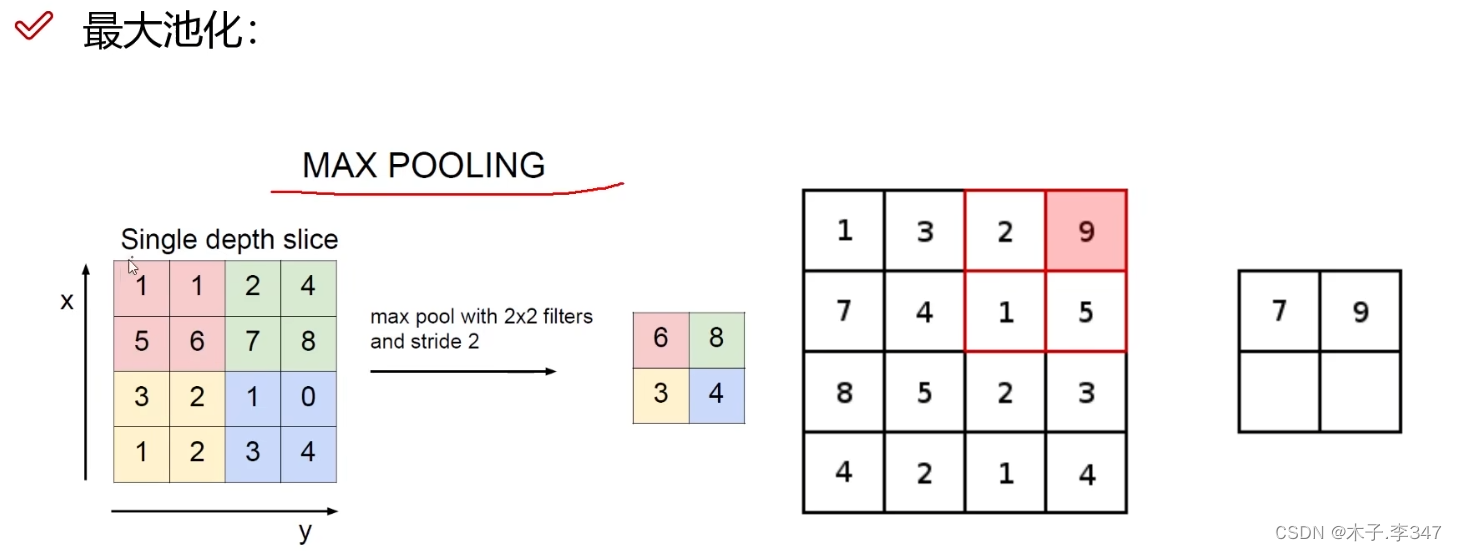
在每个区域选择最大的值,只将特征图中重要的特征提取出来。
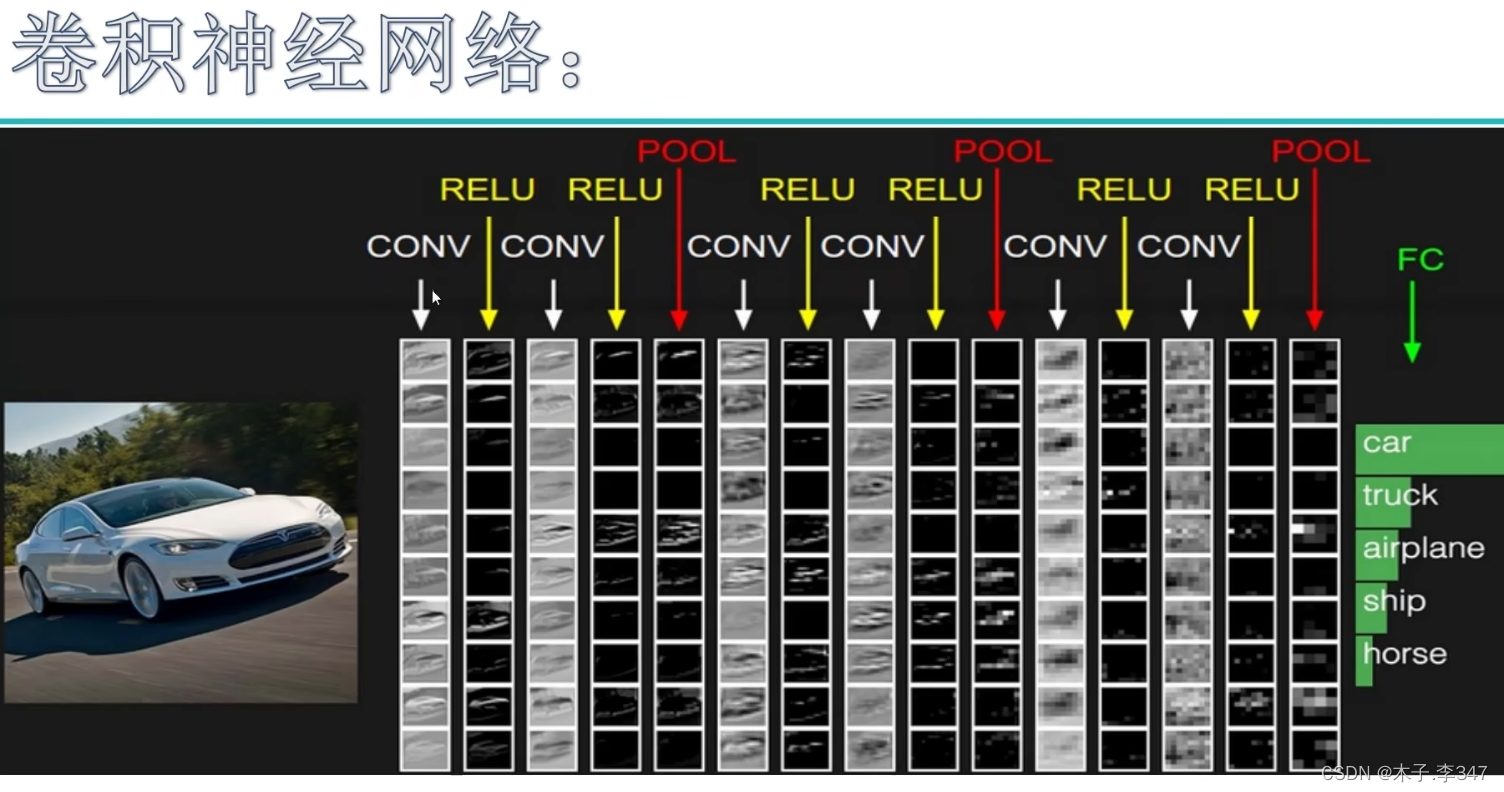
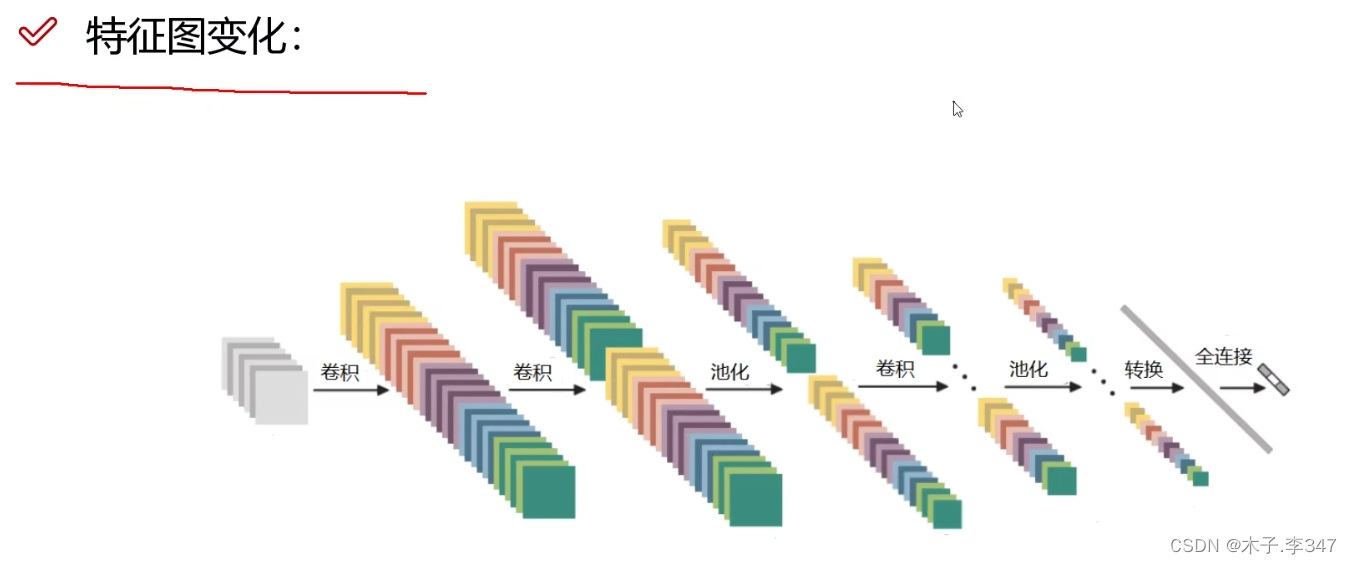
上图为一个七层的卷积神经网络(只有带参数计算的才算一层:6个卷积+1个全连接层FC),在最后的池化和FC之间还有一步将三维的特征块,转化成列/行向量(即下图中转换)。
2.3感受野
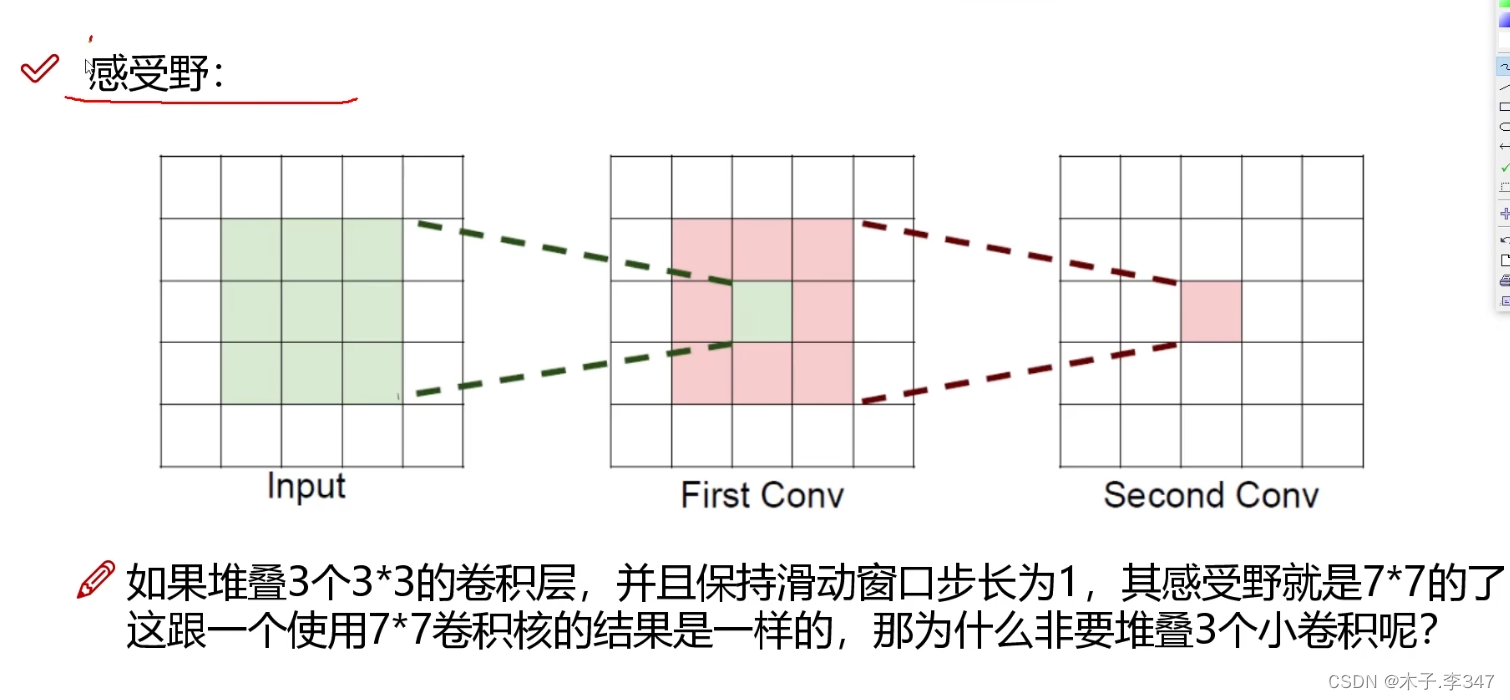
图中表示:input经过一次卷积,输出为粉色区域,第二次卷积输出为一个粉色格。
对于一个77的图像,经过三次33的卷积后输出一个值,与直接进行77的卷积一样。

所需参数个数:77C中C表示输入为C层,C(77C)左侧C表示需要C个卷积核。右同。
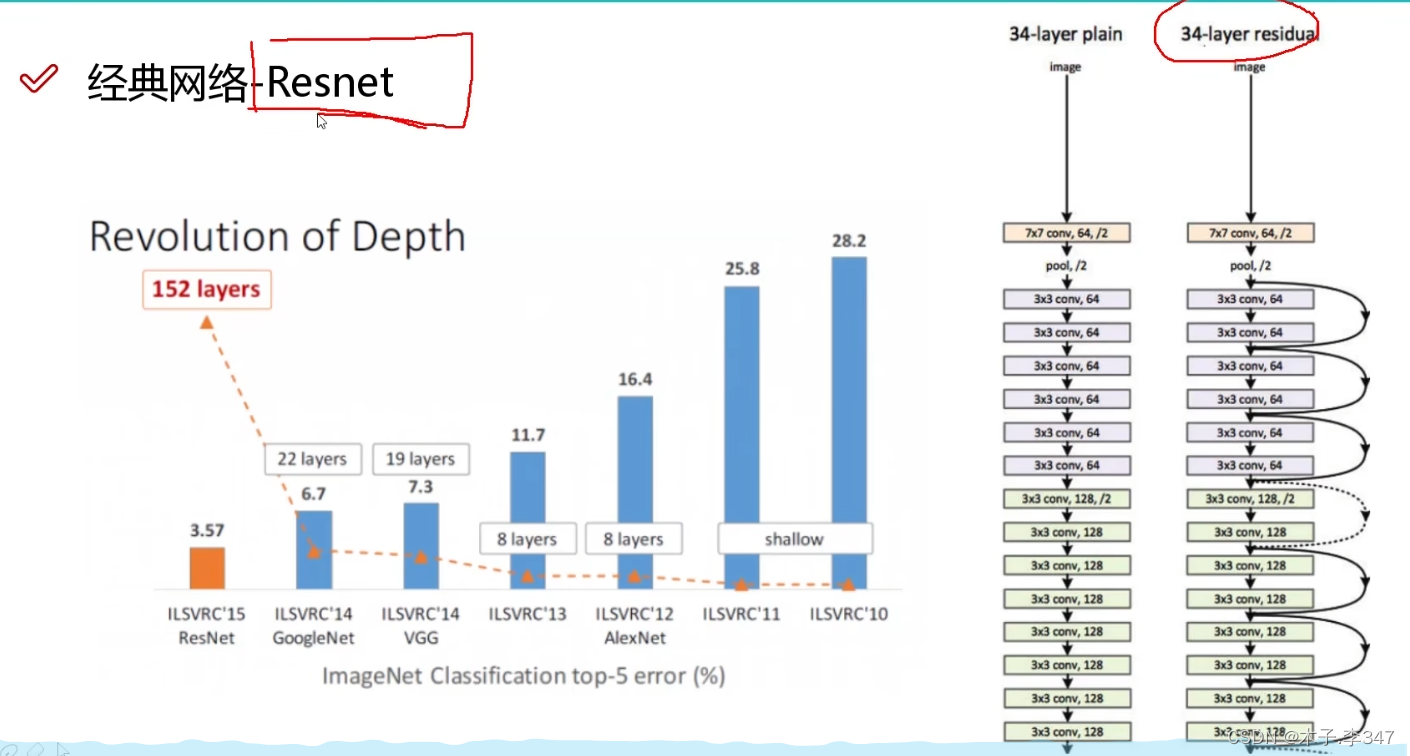
2.4Resnet
对于层数越多效果反而不好的,采取Resnet残差网络。
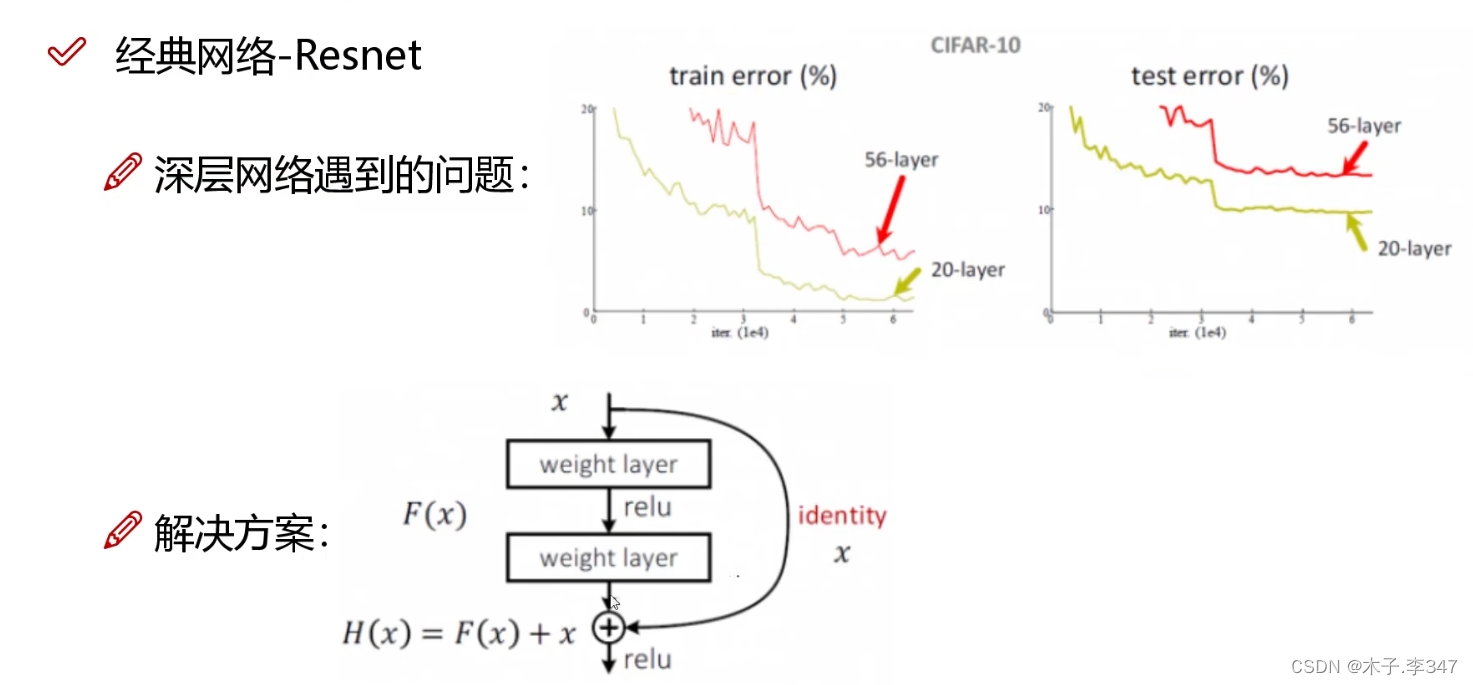
即,在本来流程中的每一层(经卷积)中都加入一个直接连接到下一层的线路,保证当网络经过训练后,本层中权重参数不适合时,去掉后不影响之后的网络(保证不会比层数少的时候效果差)。
2.5 CNN简单示例
input_size=4
#生成数据集
def generate_mock_data(num_samples):
# Generate random inputs and labels
inputs = np.random.rand(num_samples, input_size) # Random inputs: num_samples*input_size的二维数组
group_intents = np.random.randint(0, 4, num_samples) # Random group intents (0 to 3)
individual_intents = np.random.randint(0, 3, num_samples) # Random individual intents (0 to 2)
labels = group_intents * (group_intents != 3) + 4 + individual_intents * (
group_intents == 3) # Combine into labels (0-7)
#转化成张量
inputs_tensor = torch.tensor(inputs, dtype=torch.float32)
labels_tensor = torch.tensor(labels, dtype=torch.int64)
return inputs_tensor,labels_tensor
inputs_tensor, labels_tensor=generate_mock_data(100)
# 将数据转换为Dataset
dataset = TensorDataset(inputs_tensor, labels_tensor)
# 创建数据加载器
batch_size = 32
#data_loader是将所有数据分成每32一组的形式,每一组包括输入32*4的数据,标签1*32,还有键值0,1,2,3重复
data_loader = DataLoader(dataset, batch_size=batch_size, shuffle=True)
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
self.conv1 = nn.Conv2d(1, 16, kernel_size=3, stride=1, padding=1)#batch_size*1*
self.relu = nn.ReLU()
# self.maxpool = nn.MaxPool2d(kernel_size=2, stride=1)#池化核为2*2,步长为2
self.fc1 = nn.Linear(16 * 1 * 4, 8) # Adjust input size based on your data
def forward(self, x):
x = x.unsqueeze(1) # Add a channel dimension (for grayscale images) 由batch_size*4-> batch_size*1*4
x = self.conv1(x)
x = self.relu(x)
# x = self.maxpool(x)
x = x.view(x.size(0), -1) # Flatten the tensor;第0维不变,其余相乘(即32*1*1*4->32*(1*1*4))
x = self.fc1(x)
return x
model = CNN()
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
epochs = 100#循环迭代次数
for epoch in range(epochs):
running_loss = 0.0
for i, (inputs, labels) in enumerate(data_loader, 0):
#i的值0,1,2,3重复
optimizer.zero_grad()
# print(inputs)
# print(inputs.shape)
outputs = model(inputs.unsqueeze(1))
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
# print(i, (inputs, labels))
running_loss += loss.item()
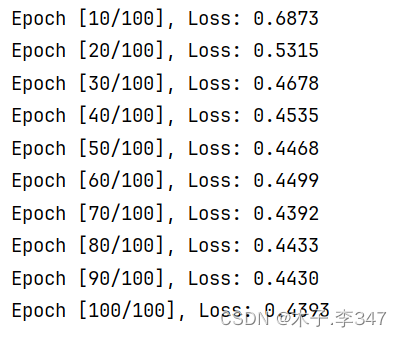
if (epoch+1) % 10 == 0: # 每10次打印一次
print(f'Epoch [{epoch + 1}/{epochs}], Loss: {running_loss / 10:.4f}')
CNN架构一些参数:
- nn.Conv2d(1, 16, kernel_size=3, stride=1, padding=1):参数依次:通道数(1或3,即灰色图还是彩色图)、输出长度16、卷积核3*3,步长1,填充值1;其需要输入的是一个四维张量(张量格式为 (batch_size, channels, height, width))
注意: TensorFlow使用"NHWC"(批次、高度、宽度、通道)格式,而PyTorch使用"NCHW"(批次、通道、高度、宽度)格式,因此
outputs = model(inputs.unsqueeze(1))和x = x.unsqueeze(1),即由32*4->32*1*4->32*1*1*4
Relu函数不改变维度;(此处应该有池化,但池化总是报错,就先没加)
最后线性层:输入长度、输出长度
Conv2d详解
3.循环(递归)神经网络
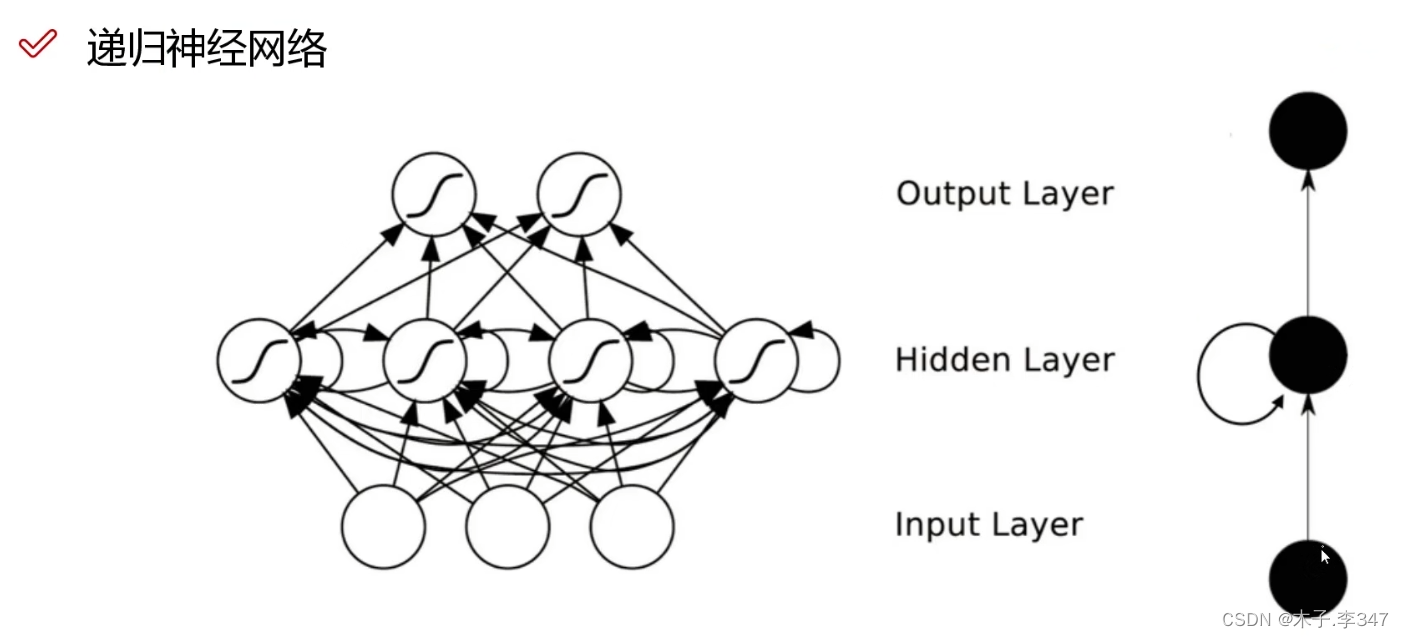
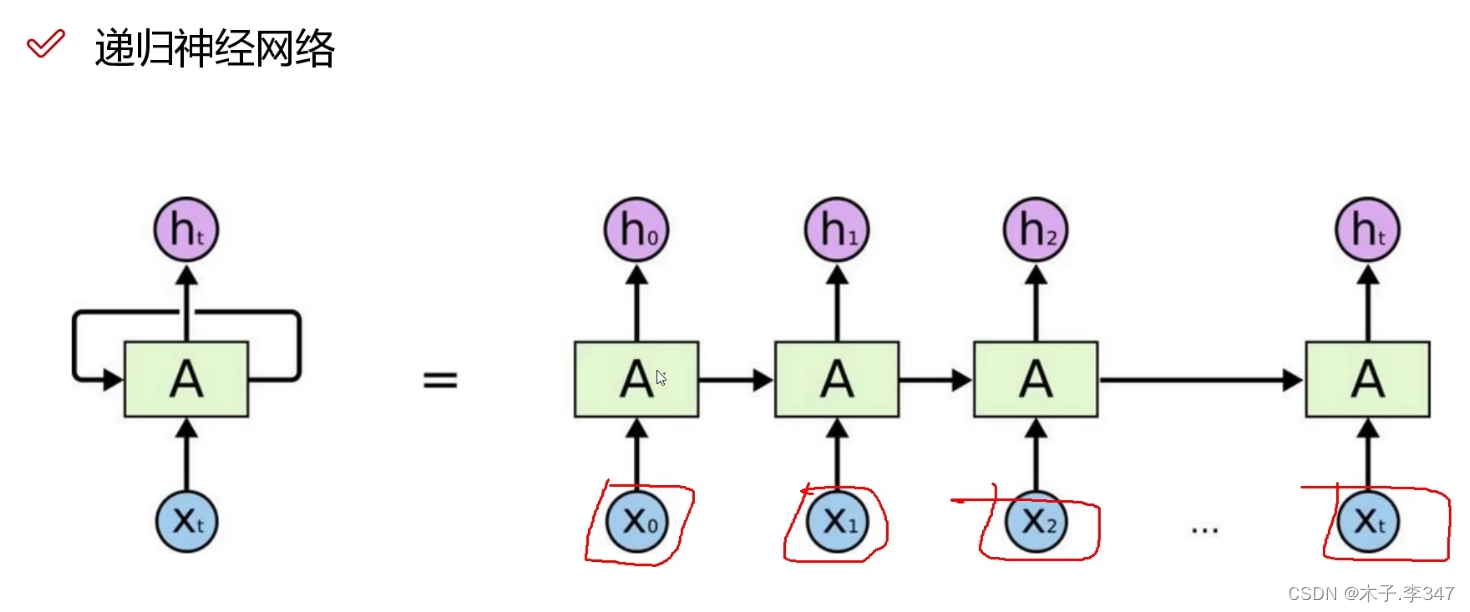
h表示每个时刻的结果,即当前隐藏状态,作为下一时刻的输入。
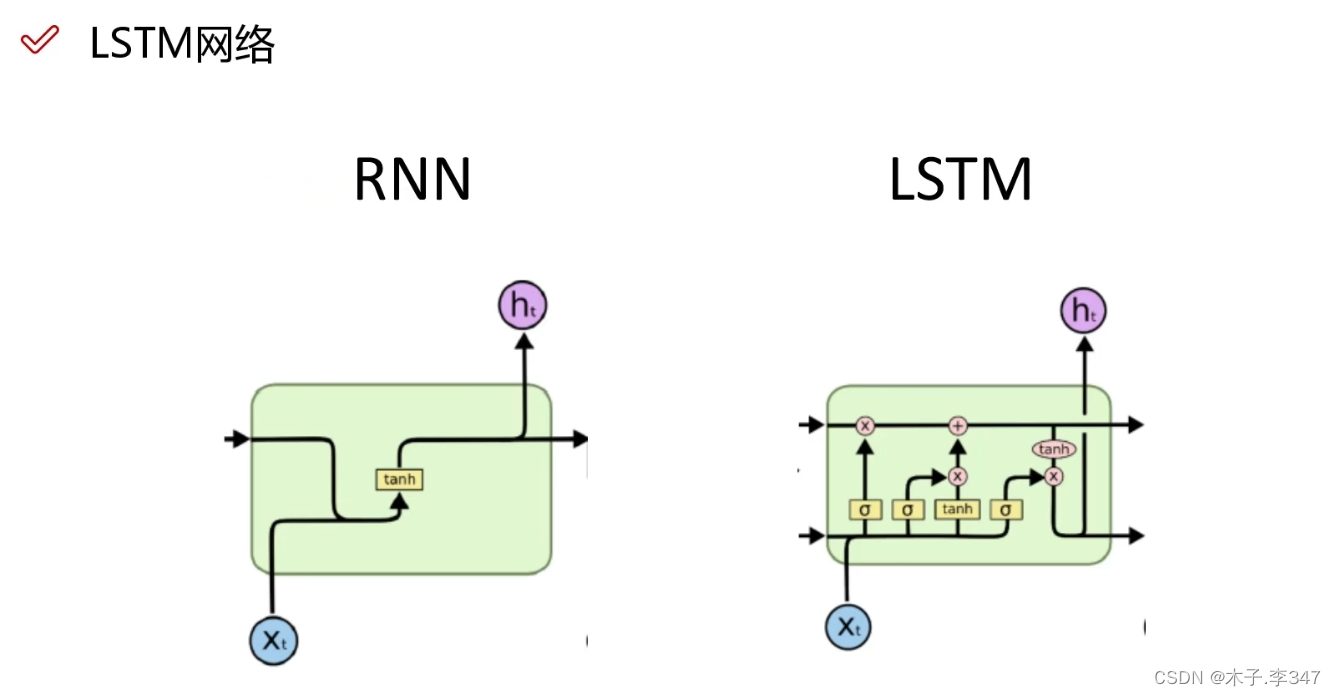
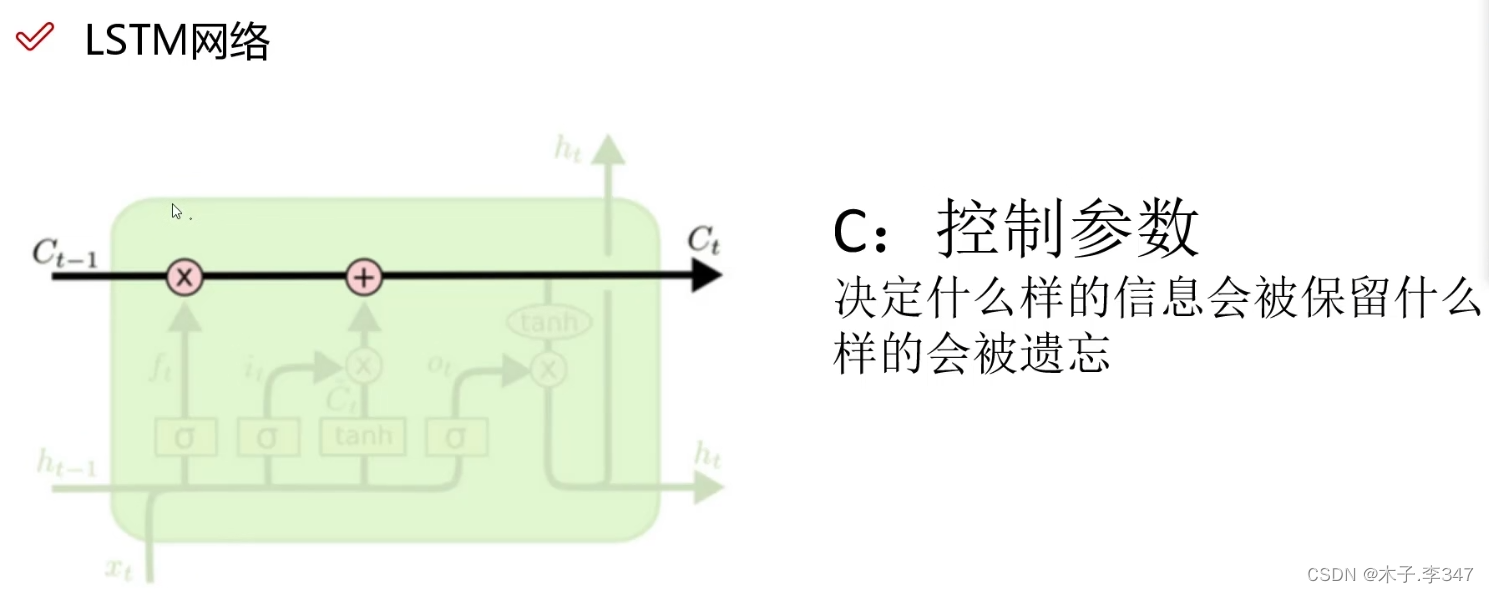
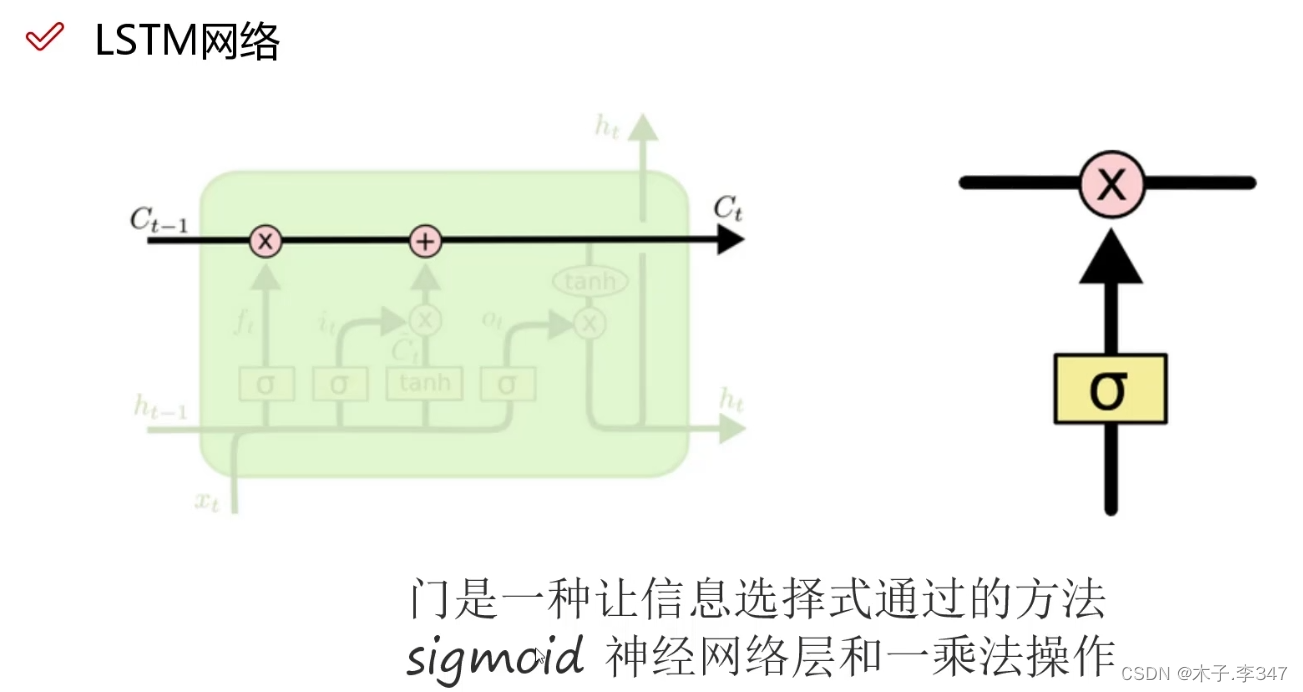
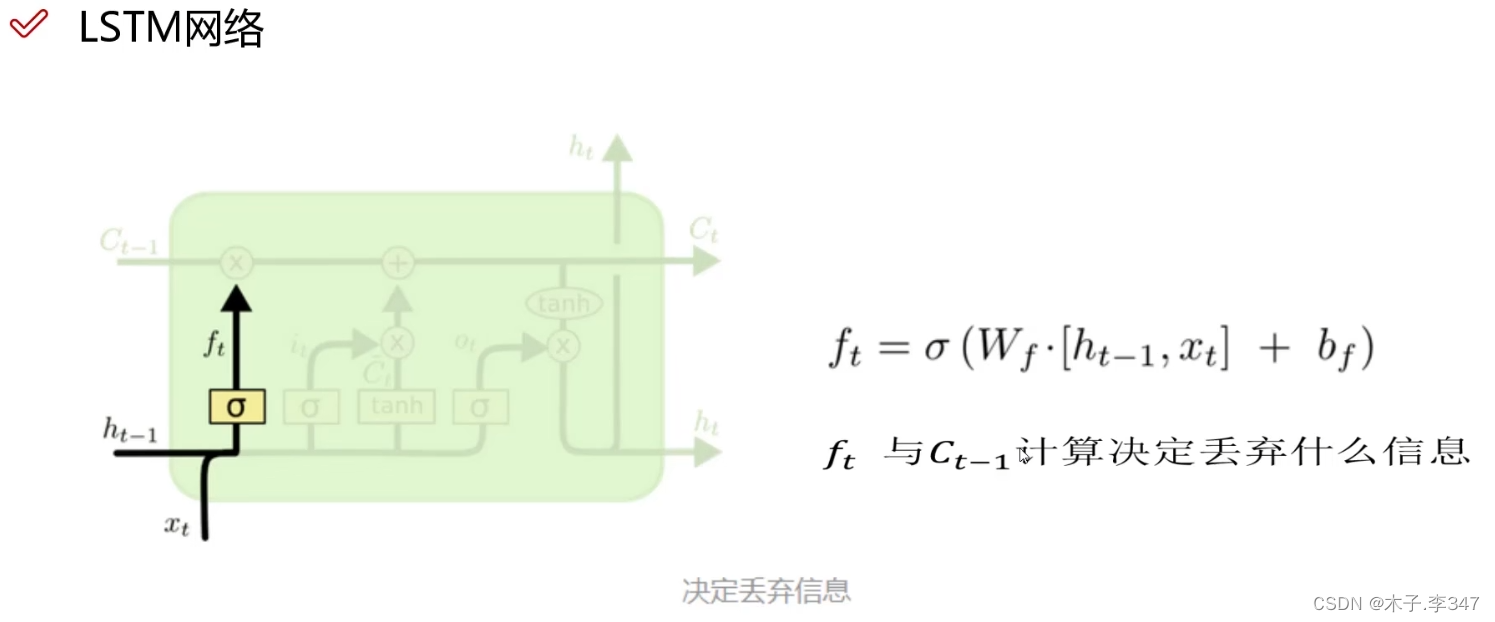
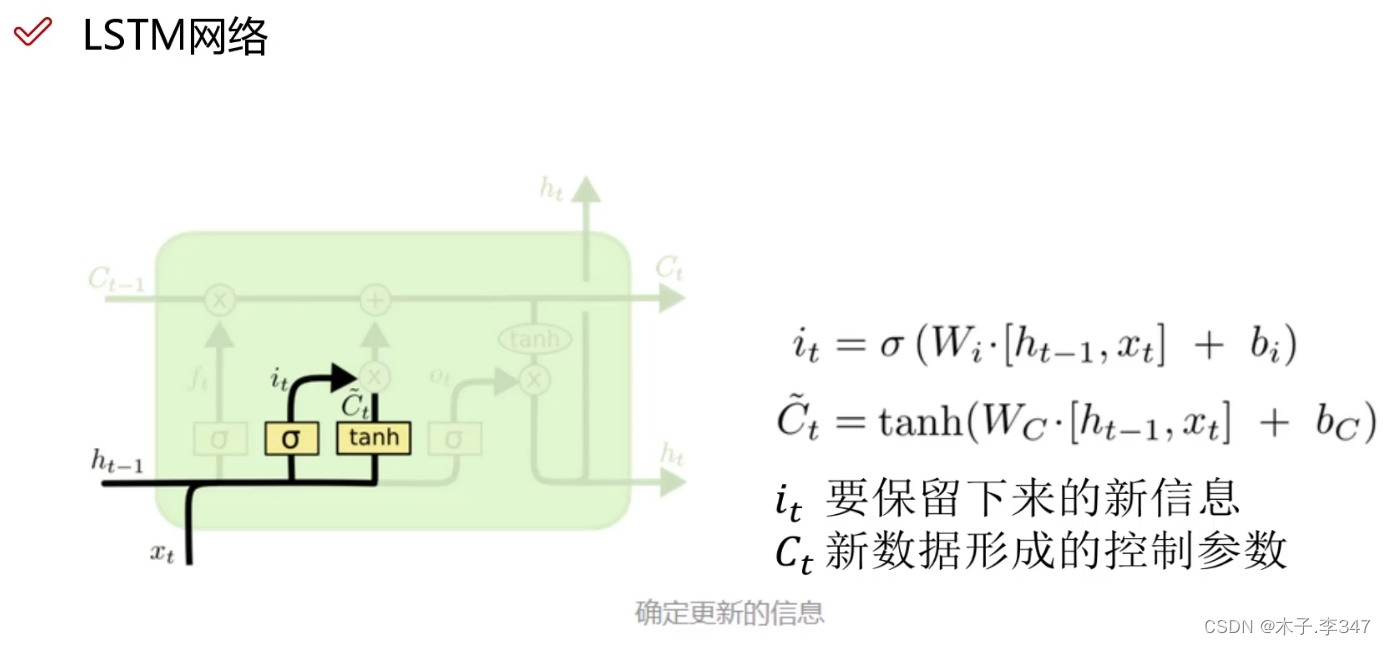
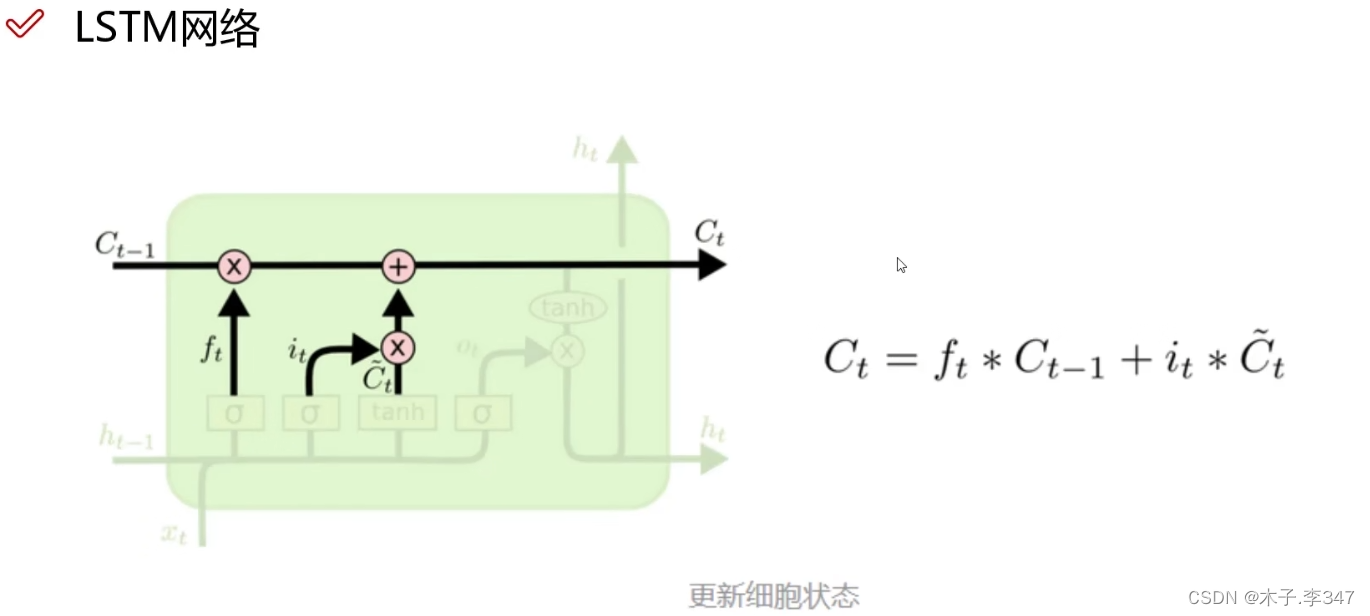
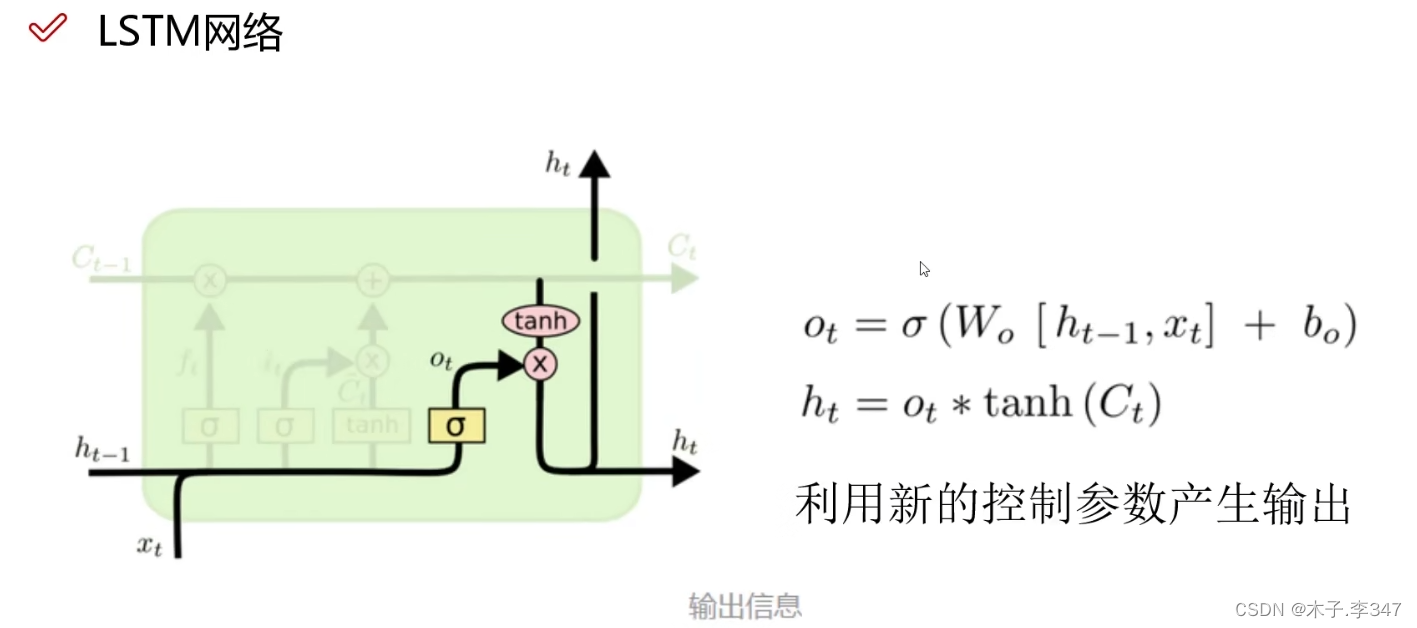
3.1 LSTM
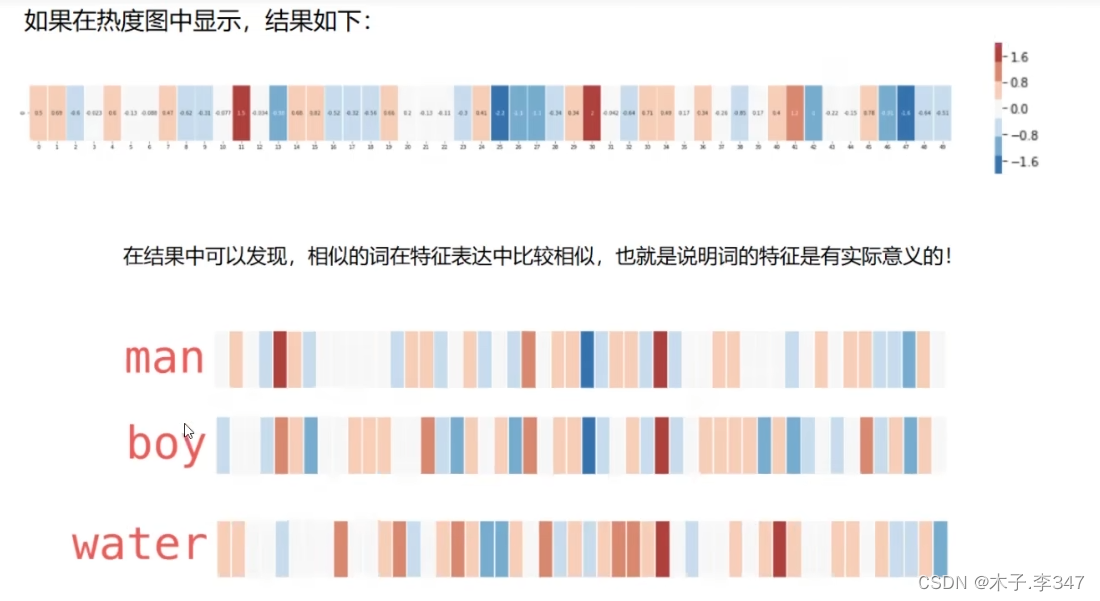
3.2自然语言处理(NLP)-词向量模型(Word2Vec)

即对每一个特征进行打分[-1,1],最后形成向量形式。



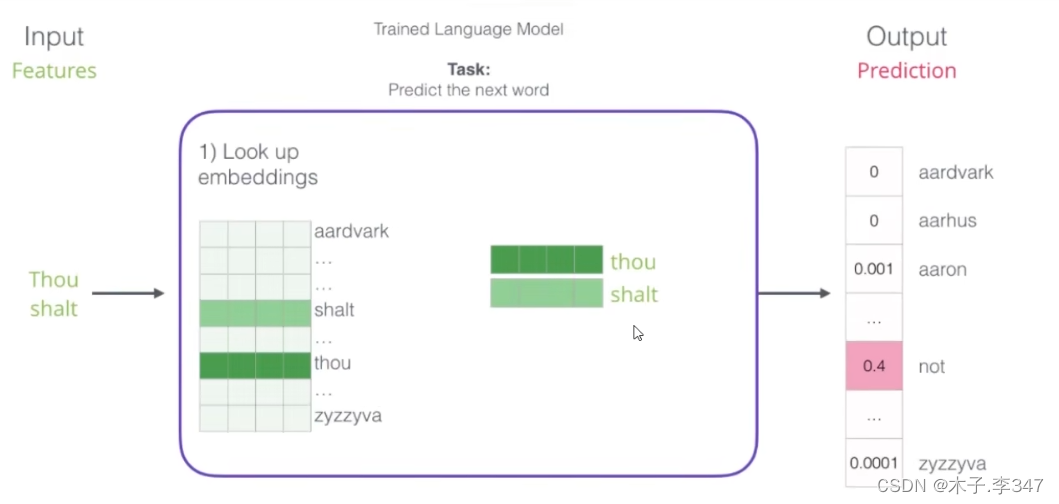
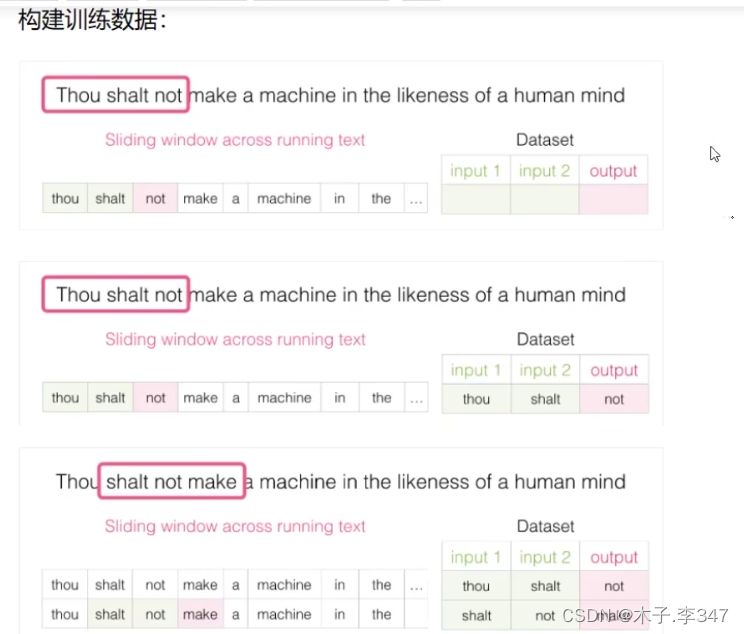
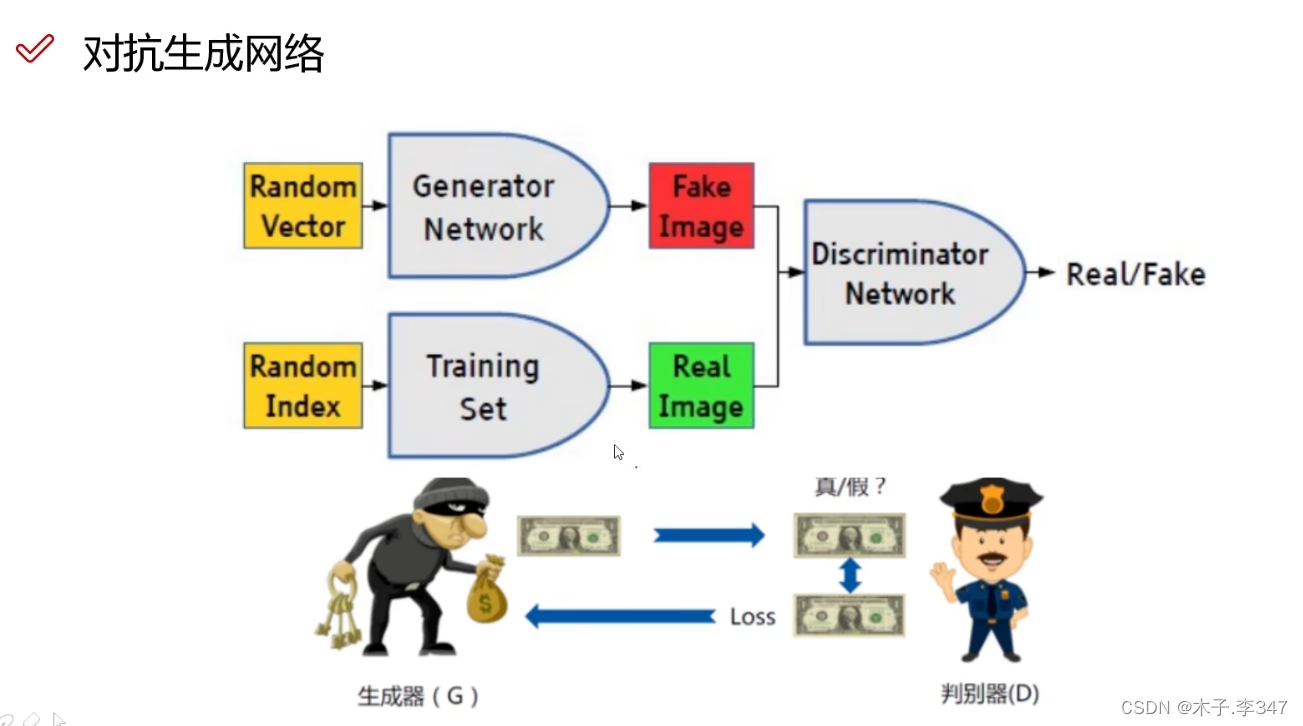
4.对抗生成网络(GAN)


参考资料:神经网络入门到实战















 116
116











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









