







3.Python网络爬虫—常用工具Fiddler的使用教程
前言

网络爬虫是一种自动获取网页内容的程序,在Python中,常用的网络爬虫工具主要包括Python编程语言、PyCharm集成开发环境(IDE)、浏览器和Fiddler。
Python是一种通用的编程语言,广泛用于网络爬虫的开发。它提供了丰富的库和模块,如Requests、BeautifulSoup和Scrapy,这些库可以帮助我们发送HTTP请求、解析HTML页面以及提取所需的数据。
PyCharm是一款流行的Python集成开发环境(IDE),它提供了代码编辑、调试和运行的功能,可以帮助开发者更高效地编写和管理Python代码,包括网络爬虫项目。
浏览器是访问网页的工具,常见的浏览器包括Chrome和火狐(Firefox)。在网络爬虫的开发过程中,我们可以使用浏览器手动检查网页的结构,调试和分析网络请求,这对于理解网页的数据结构和设计爬虫策略非常有帮助。
Fiddler是一款免费的网络调试工具,它可以捕获和分析HTTP请求和响应。通过Fiddler,我们可以模拟不同的请求头和参数,这有助于我们调试网络爬虫程序,查看和修改请求内容。
Fiddler的使用
操作界面
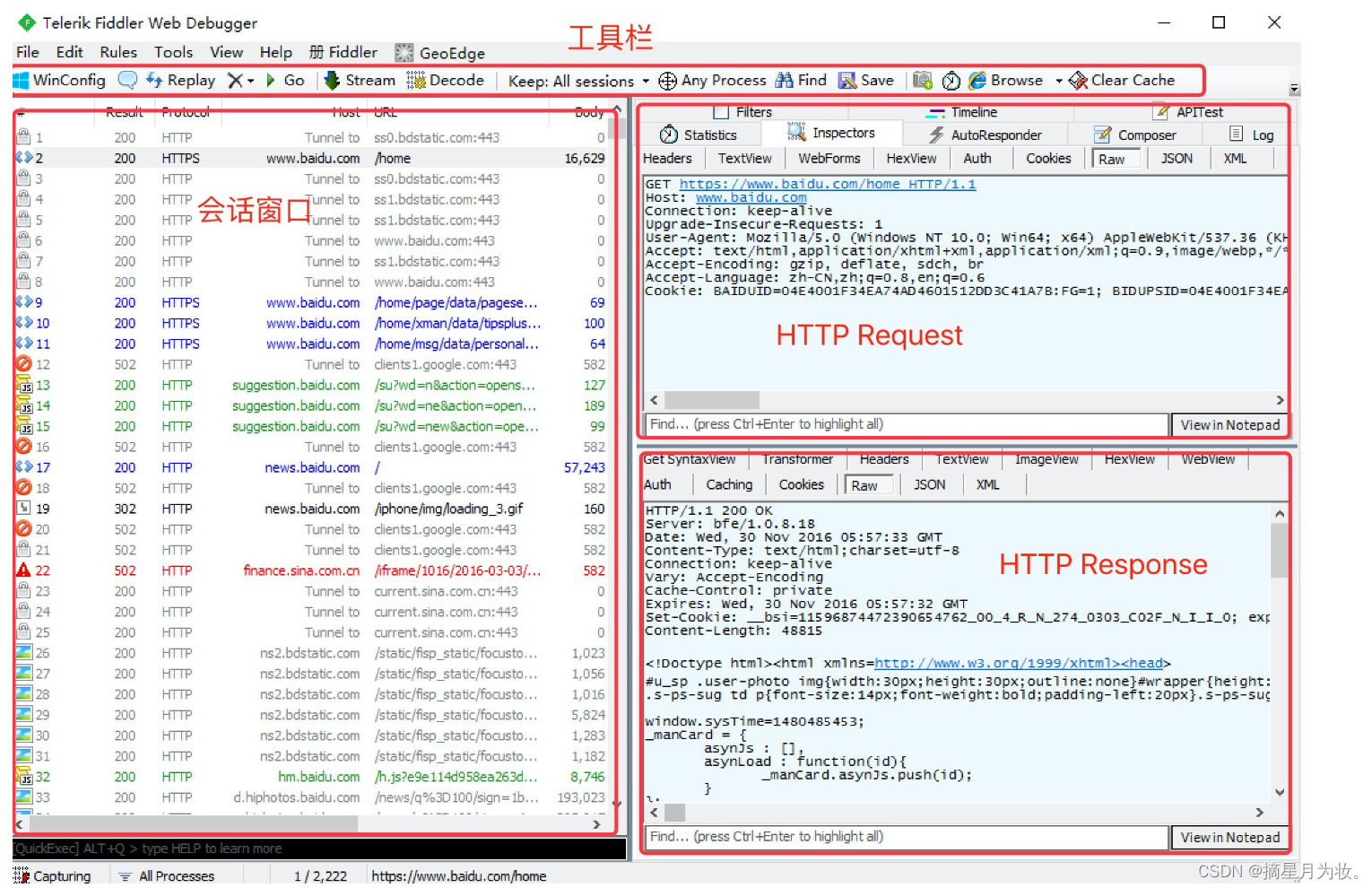
2.2 界面含义
请求 (Request) 部分详解
| 名称 | 含义 |
|---|---|
| Headers | 显示客户端发送到服务器的 HTTP 请求的,header 显示为一个分级视图,包含了 Web 客户端信息、Cookie、传输状态等 |
| Textview | 显示 POST 请求的 body 部分为文本 |
| WebForms | 显示请求的 GET 参数 和 POST body 内容 |
| HexView | 用十六进制数据显示请求 |
| Auth | 显示响应 header 中的 Proxy-Authorization(代理身份验证) 和 Authorization(授权) 信息 |
| Raw | 将整个请求显示为纯文本 |
| JSON | 显示JSON格式文件 |
| XML | 如果请求的 body 是 XML格式,就是用分级的 XML 树来显示它 |
响应 (Response) 部分详解
| 名称 | 含义 |
|---|---|
| Transformer | 显示响应的编码信息 |
| Headers | 用分级视图显示响应的 header |
| TextView | 使用文本显示相应的 body |
| ImageVies | 如果请求是图片资源,显示响应的图片 |
| HexView | 用十六进制数据显示响应 |
| WebView | 响应在 Web 浏览器中的预览效果 |
| Auth | 显示响应 header 中的 Proxy-Authorization(代理身份验证) 和 Authorization(授权) 信息 |
| Caching | 显示此请求的缓存信息 |
| Privacy | 显示此请求的私密 (P3P) 信息 |
| Raw | 将整个响应显示为纯文本 |
| JSON | 显示JSON格式文件 |
| XML | 如果响应的 body 是 XML 格式,就是用分级的 XML 树来显示它 |
2.3 设置
2.3.1 如何打开
启动Fiddler,打开菜单栏中的 Tools >Options,打开“Fiddler Options”对话框
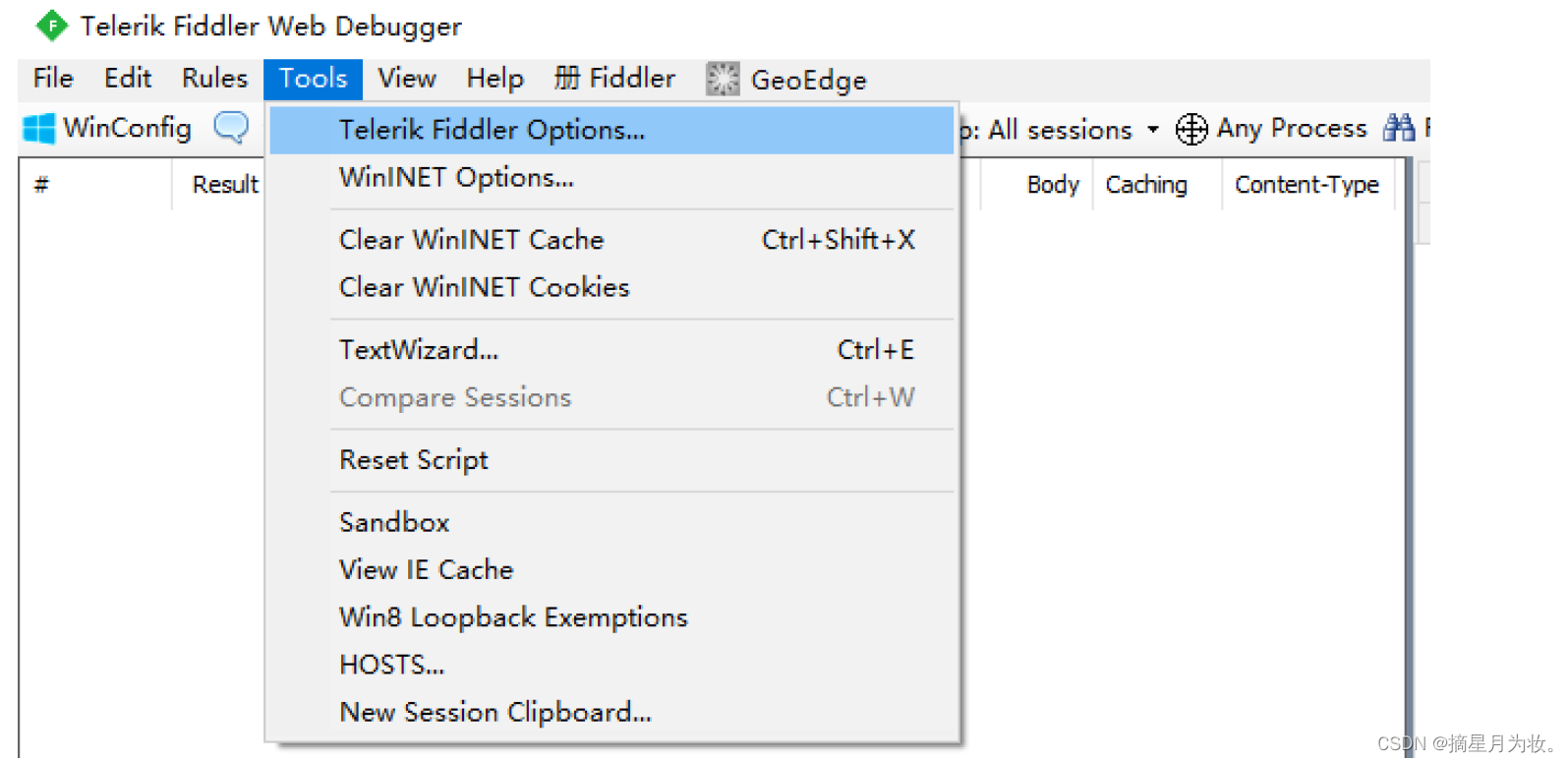
2.3.2 设置
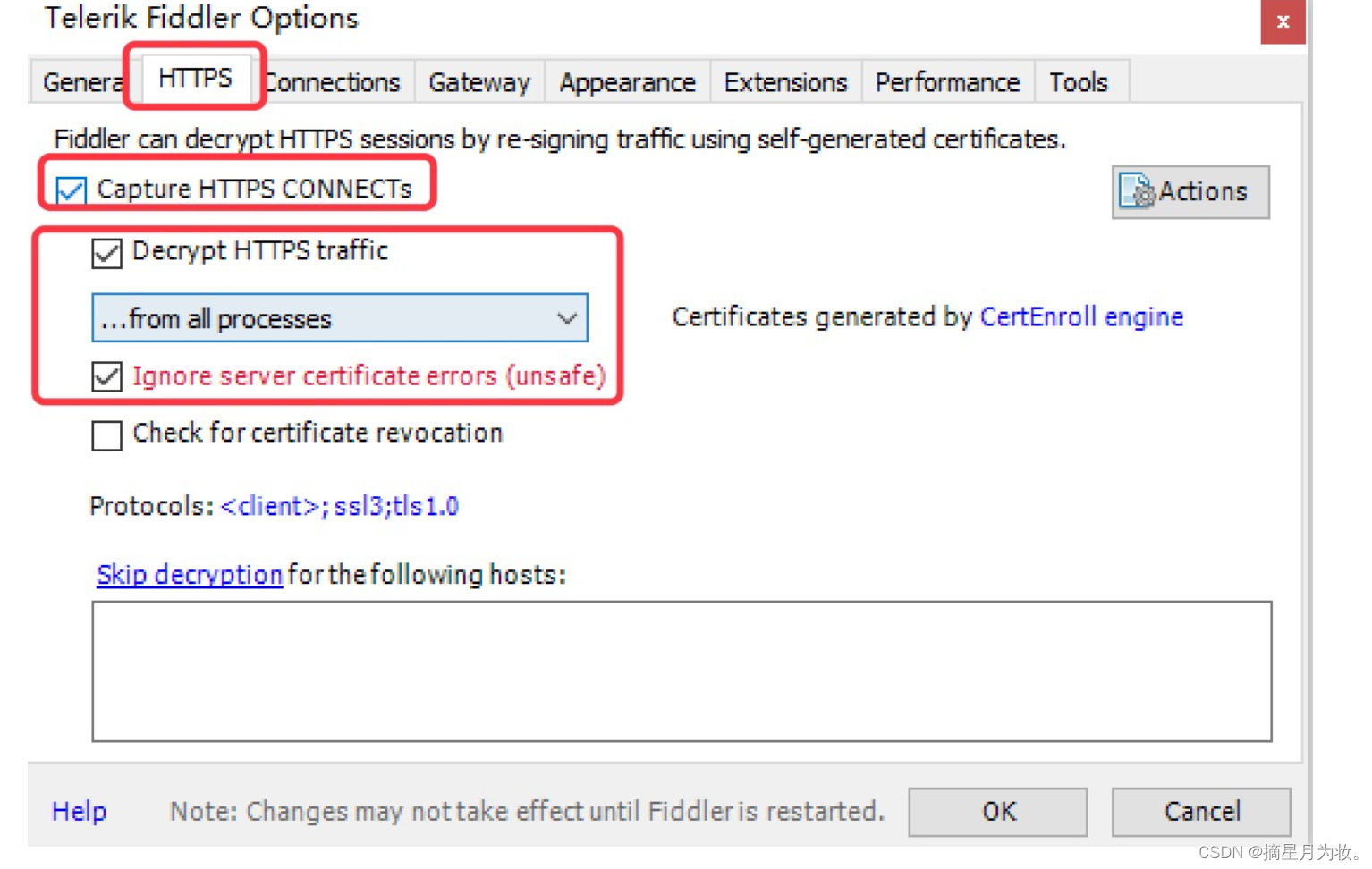
- Capture HTTPS CONNECTs 捕捉HTTPS连接
- Decrypt HTTPS traffic 解密HTTPS通信
- Ignore server certificate errors 忽略服务器证书错误
- all processes 所有进程
- browsers onlye 仅浏览器
- nono- browsers only 仅非浏览器
- remote clients only 仅远程链接
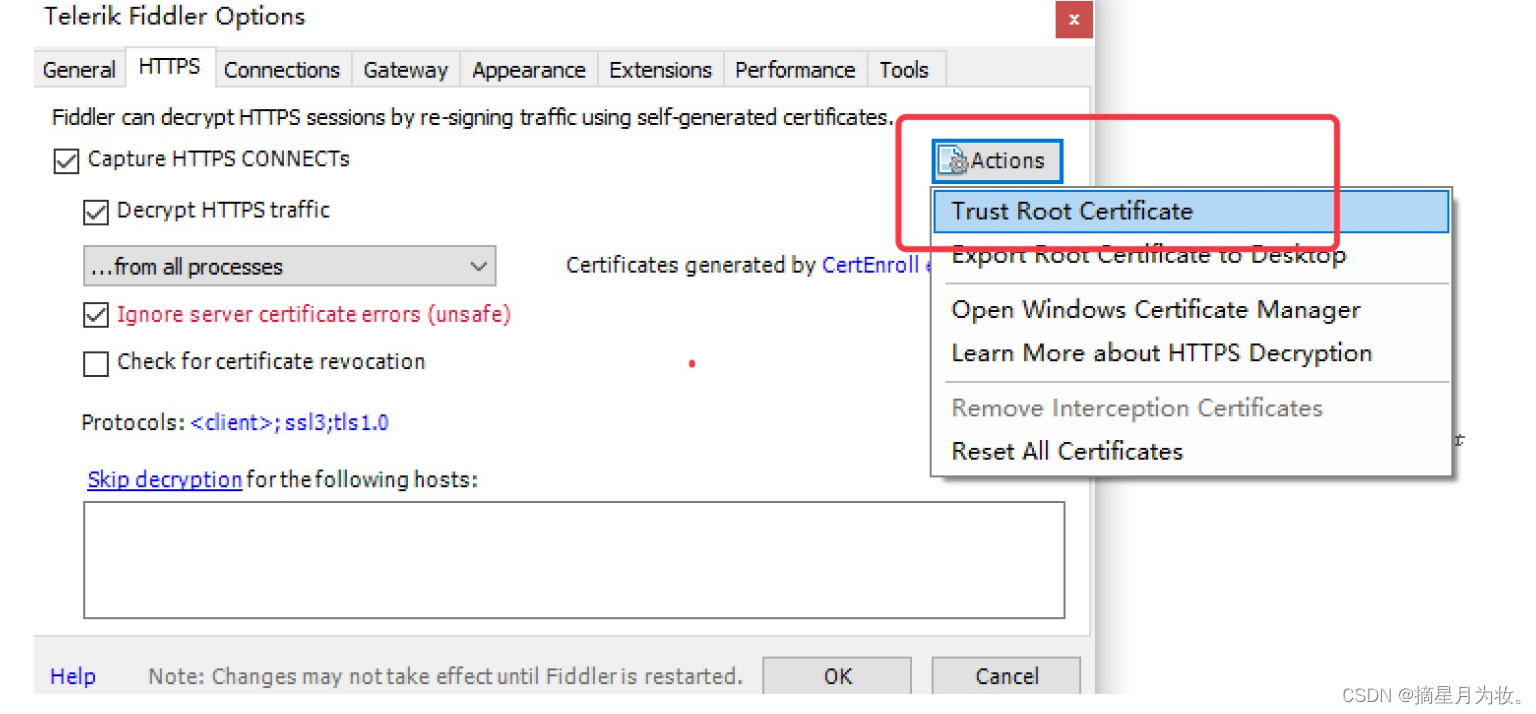
Trust Root Certificate(受信任的根证书) 配置Windows信任这个根证书解决安全警告
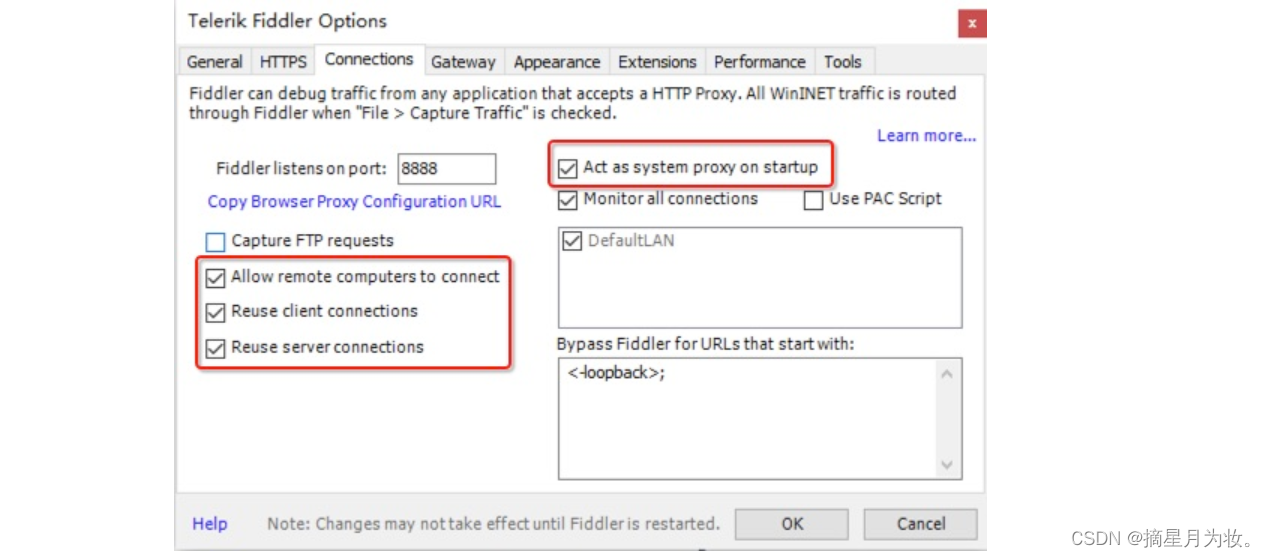
- Allow remote computers to connect 允许远程连接
- Act as system proxy on startup 作为系统启动代理
- resuse client connections 重用客户端链接















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









