







 本文详细介绍了如何使用Python的Urllib库进行网络爬虫,包括基本的HTTP请求、Request对象的使用、实战项目中爬取今日头条搜索结果中的图片和视频链接,以及如何结合selenium处理更复杂的网页内容。
本文详细介绍了如何使用Python的Urllib库进行网络爬虫,包括基本的HTTP请求、Request对象的使用、实战项目中爬取今日头条搜索结果中的图片和视频链接,以及如何结合selenium处理更复杂的网页内容。
一·前言

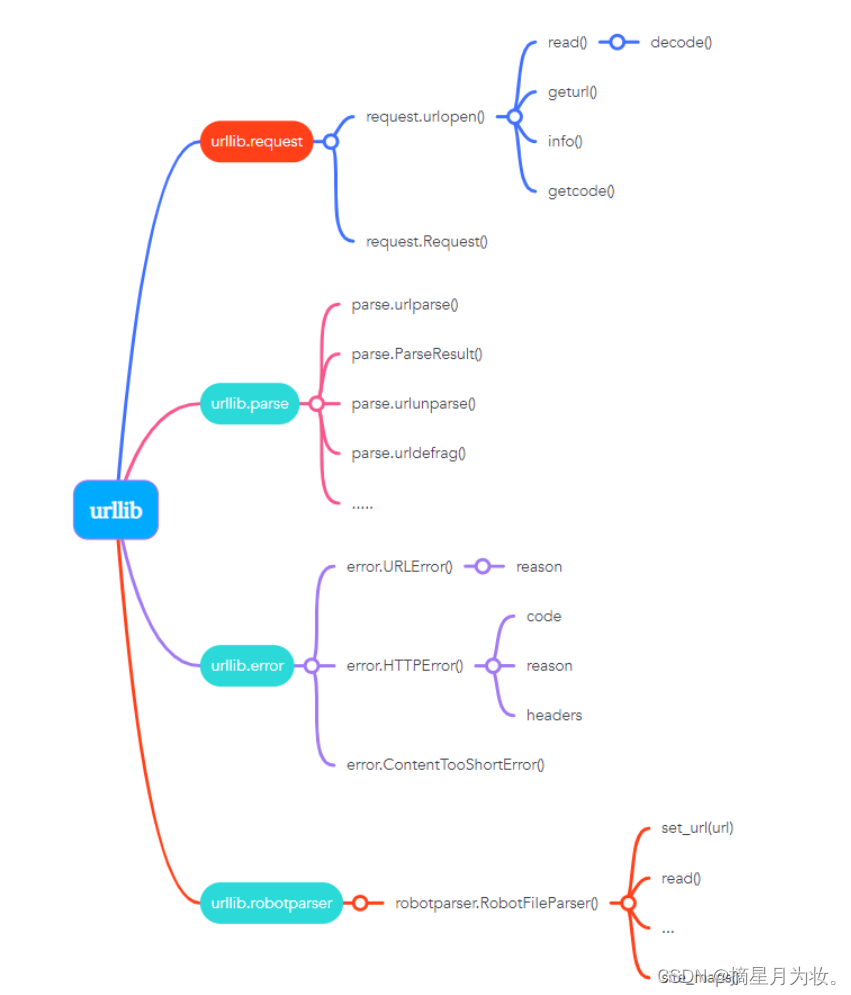
Urllib是Python的一个内置库,专门用于处理HTTP请求。这个库包含四个主要模块:
request:这是Urllib库中最基本的HTTP请求模块。使用该模块,你可以模拟发送各种HTTP请求,如GET、POST等。它允许你通过编程方式与Web服务器进行交互,获取或上传数据。
error:此模块负责处理在HTTP请求过程中可能出现的错误。如果在请求过程中遇到问题,比如网络连接失败、服务器返回错误代码等,error模块可以帮助你捕获这些异常,并据此采取相应的措施,例如重新发送请求或者输出错误信息。
parse:这个模块提供了一些函数和方法来解析URLs。你可以利用它提取URL的不同组成部分,如协议、主机名、路径和查询参数等。此外,还可以解析HTML页面中的链接、表单等元素。
robotparser:尽管这个模块不如其他三个常用,但它用于解析网站的robots.txt文件。这些文件指导网络爬虫哪些页面可以抓取,哪些不可以。如果你正在开发一个网络爬虫,robotparser可以帮助你避免违反网站的爬取规则。
二·入门案例
网页爬取,也被称为网页抓取或网络爬虫,是一种从互联网上自动获取信息的技术。它通过模拟浏览器的行为,向服务器发送请求并接收响应,然后解析响应内容以提取所需的数据。
在Python中,我们可以使用Urllib库来实现网页爬取。Urllib是Python的一个内置库,专门用于处理HTTP请求。这个库包含四个主要模块:request、error、parse和robotparser。其中,request模块是最基本的HTTP请求模块,可以用来模拟发送各种HTTP请求,如GET、POST等。
下面是一个使用Urllib库爬取网页的简单示例:
from urllib.request import urlopen
response = urlopen("http://www.baidu.com")
print(response.read().decode())
这段代码首先导入了urlopen函数,然后使用这个函数向"http://www.baidu.com"发送了一个GET请求,并将返回的响应对象存储在response变量中。最后,我们调用response的read方法读取响应的内容,并使用decode方法将其从字节串解码为字符串,然后打印出来。
执行这段代码,将看到百度首页的HTML源代码被打印出来。这就是网页爬取的基本过程。
三·常用方法
Urllib库是Python的一个内置库,专门用于处理HTTP请求。这个库包含四个主要模块:request、error、parse和robotparser。其中,request模块是最基本的HTTP请求模块,可以用来模拟发送各种HTTP请求,如GET、POST等。
request.urlopen()方法是用来打开URL的,它有三个参数:url、data和timeout。url参数是必须的,表示要访问的网址;data参数是可选的,表示要传送的数据,默认为None;timeout参数也是可选的,表示设置超时时间,默认为socket._GLOBAL_DEFAULT_TIMEOUT。这个方法会返回一个response对象,包含了服务器的响应信息。
response.read()方法是用来读取服务器响应的全部内容,返回的是bytes类型。
response.getcode()方法是用来获取HTTP的响应码,成功返回200,4表示服务器页面出错,5表示服务器问题。
response.geturl()方法是用来获取实际数据的实际URL,防止重定向问题。
response.info()方法是用来获取服务器响应的HTTP报头。
四·Request对象
Urllib库是Python的一个内置库,专门用于处理HTTP请求。这个库包含四个主要模块:request、error、parse和robotparser。其中,request模块是最基本的HTTP请求模块,可以用来模拟发送各种HTTP请求,如GET、POST等。
request.urlopen()方法是用来打开URL的,它可以接受一个Request类的实例作为参数。Request类在构造时需要传入Url、Data等信息。例如,我们可以这样改写上面的代码:
from urllib.request import urlopen
from urllib.request import Request
request = Request("http://www.baidu.com")
response = urlopen(request)
print(response.read().decode())
这段代码首先导入了urlopen函数和Request类,然后创建了一个Request对象,并将其传递给urlopen函数。最后,我们调用response的read方法读取响应的内容,并使用decode方法将其从字节串解码为字符串,然后打印出来。
这种方式在构建请求时可以加入更多的内容,使得逻辑更加清晰明确。
五·实战项目
import requests
import time
from selenium import webdriver
base_url = 'https://www.toutiao.com/api/search/content/'
timestamp = int(time.time()*1000)
article_url_list = []
browser = webdriver.Chrome()
# 获取到一个页面内所有的article url
def get_article_urls():
for offset in range(0, 120, 20): # 搜索结果有六个页面,所以只120,有时页面没这么多
params = {
'aid': 24,
'app_name': 'web_search',
'offset': offset,
'format': 'json',
'keyword': '街拍',
'autoload': 'true',
'count': 20,
'en_qc': 1,
'cur_tab': 1,
'from': 'search_tab',
'pd': 'synthesis',
'timestamp': timestamp
}
headers = {
'cookie': 'tt_webid=6726420735470077454; WEATHER_CITY=%E5%8C%97%E4%BA%AC; tt_webid=6726420735470077454; csrftoken=e826e0c3c32a74555da7ec10112dc449; UM_distinctid=16ca3d7c13388-08bc3bd0b608e-c343162-144000-16ca3d7c1353a0; CNZZDATA1259612802=568057237-1566113713-https%253A%252F%252Fwww.toutiao.com%252F%7C1566113713; _ga=GA1.2.343540482.1566116922; __tasessionId=tiuwzvodh1566809947037; s_v_web_id=3c58c92ef3181a0e355d8348267b5efa',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.157 Safari/537.36',
'x-requested-with': 'XMLHttpRequest',
'referer': 'https://www.toutiao.com/search/?keyword=%E8%A1%97%E6%8B%8D',
}
html = requests.get(url=base_url, params=params, headers=headers)
result = list(html.json().get('data'))
for item in result:
article_url = item.get('article_url') # 提取每篇文章的url
if article_url and len(article_url) < 100:
article_url_list.append(article_url)
def request_AND_storage():
get_article_urls()
print(article_url_list)
print(len(article_url_list))
for url in article_url_list:
print('我是文章url****************************************************', url)
with open('result_url_txt', 'a', encoding='utf-8') as f:
f.write('***********************************************************************'+url+'\n')
try:
browser.get(url)
try:
# 图片在一个url的情况
div = browser.find_element_by_xpath('/html/body/div/div[2]/div[2]/div[1]/div[2]/div')
if div:
image_divs = div.find_elements_by_css_selector('.pgc-img')
for image_div in image_divs:
image_url = image_div.find_element_by_xpath('./img').get_attribute('src')
print('图片在一个url:', image_url)
with open('result_url_txt', 'a', encoding='utf-8') as f:
f.write(image_url+'\n')
continue # 结束本次循环
except:
try:
# 图片不在一个url的情况
li_list = browser.find_element_by_xpath('/html/body/div/div[2]/div[1]/div/div/div[1]/div/div/ul').find_elements_by_xpath('./li')
if li_list:
for li in li_list:
photo_url = li.find_element_by_xpath('./div/img').get_attribute('src') or li.find_element_by_xpath('./div/img').get_attribute('data-src')
print('图片不在在一个url:', photo_url)
with open('result_url_txt', 'a', encoding='utf-8') as f:
f.write(photo_url+'\n')
continue # 结束本次循环
except:
# 视频的情况
time.sleep(2)
# try:
video_url = browser.find_element_by_xpath('//*[@id="vs"]/video').get_attribute('src')
print('视频:' ,video_url)
with open('result_url_txt', 'a', encoding='utf-8') as f:
f.write(video_url+'\n')
except:
print('此文章url无妨访问' ,browser.current_url)
browser.close()
if __name__ == '__main__':
request_AND_storage()
六·代码讲解
这段代码的主要功能是爬取今日头条(www.toutiao.com)上关于"街拍"关键词的搜索结果,并将搜索结果中的图片、视频等资源链接保存到本地文件中。
代码主要分为以下几个部分:
- 导入所需的库:requests、time和selenium的webdriver模块。
- 定义基础URL和时间戳变量。
- 定义一个空列表article_url_list,用于存储文章的URL。
- 使用webdriver创建一个Chrome浏览器实例。
- 定义一个函数get_article_urls(),用于获取搜索结果中的所有文章URL。这个函数通过循环遍历不同的offset值(每页20个结果),构造请求参数和请求头,然后发送GET请求获取数据。将返回的数据中的article_url提取出来,并添加到article_url_list列表中。
- 定义一个函数request_AND_storage(),用于处理文章URL列表。首先调用get_article_urls()函数获取文章URL列表,然后遍历这些URL,对每个URL进行以下操作:
- 打开浏览器,访问该URL。
- 尝试查找页面中的图片或视频元素,并提取它们的URL。
- 如果找到图片或视频元素,将它们的URL保存到本地文件中。
- 如果遇到异常(如无法访问某个URL),则打印错误信息。
- 在主程序入口中调用request_AND_storage()函数。















 940
940











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









