






1.什么是TRPO?
它是一个用来优化策略(policy)的算法,是通过对理论证明过程的近似得来的算法。该算法类似于自然策略梯度方法,对神经网络等大型非线性策略是有效的。TRPO倾向于给出单调的改进,很少调整超参数。
2.怎样实现
信赖区间优化策略目的在有限样本下有效地选择动作和更新价值函数。该方法通过随时间变化调整动作价值函数的置信区间大小,以平衡勘探和利用,从而提高策略的效率和稳定性。
其主要思想是,在每个时间步骤上,算法计算当前状态下每个动作的置信区间(通常是置信区间或置信上限),并基于这些置信度来决定选择哪个动作。在选择后,算法会根据观察到的奖励值更新动作值函数,并调整置信区间的大小。如果置信区间较大,则探索性较高,算法更有可能尝试新的动作;如果置信区间较小,则算法更倾向于选择先前被证明为最好的动作。
与其他强化学习策略相比,信赖阈优化策略在学习效率和稳定性方面具有显著优势,并且能够应用于各种实际问题中,如机器人导航、游戏玩法等。
3.单调性改进保证(Monotonic Improvement Guarantee)
在强化学习中,Monotonic Improvement Guarantee(单调性改进保证)是一种保证策略迭代(policy iteration)算法能够不断提高目标收益的性质。针对一般随机策略(General Stochastic Policies),可以使用单调性改进保证来证明某些优化算法的有效性。
具体而言,在单调性改进保证下,一个策略迭代算法必须满足以下条件:
1. 对于任何初始策略 ![]() ,迭代得到的序列
,迭代得到的序列![]() 都是可行的,并且能够不断提高策略的期望收益。
都是可行的,并且能够不断提高策略的期望收益。
2. 对于任何策略 ![]() ,如果有一种新的策略
,如果有一种新的策略 ![]() 满足
满足 ![]() ,则以
,则以 ![]() 为基础的更新策略 $\pi_{k+1}$ 必须满足 $J(\pi_{k+1})\geq J(\pi_k)$。
为基础的更新策略 $\pi_{k+1}$ 必须满足 $J(\pi_{k+1})\geq J(\pi_k)$。
这个性质说明,在单调性改进保证的前提下,任何基于随机策略的优化算法必须能够保持策略的单调性,即在每次迭代中不断提高策略的期望收益。因此,证明一个算法是否能够满足单调性改进保证,可以作为评估其性能和有效性的标准之一。
单调性改进保证被广泛应用于基于策略迭代的强化学习算法中,如TRPO(Trust Region Policy Optimization)和PPO(Proximal Policy Optimization)等。这些算法都采取了不同的方法来保证策略更新的单调性,从而在实际应用中展现出了很高的效率和稳定性。
Part1.
(1). 折扣回报的期望(Expected Discounted Return):
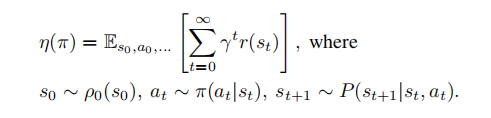
是指在一个马尔可夫决策过程(Markov Decision Process, MDP)中,从当前状态开始,按照策略选择动作并执行后,未来所有奖励的累积值。具体计算方式为将未来每个时间步的奖励乘以一个衰减系数(折扣因子),然后对这些奖励进行累加求和,得到一个期望值。折扣因子通常用于减小远期奖励对当前决策的影响力,使算法更加关注近期奖励。
在TRPO算法中,折扣回报的期望被用作策略评估,通过最大化期望回报来优化策略。而状态值在TRPO中则被用于构造优势函数,用于估计动作价值的优势程度,并进行策略改进。因此,折扣回报的期望和状态值在TRPO算法中有不同的应用和计算方式,分别用于策略评估和策略改进的过程。
(2).动作值函数(action value function)
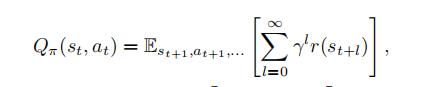
给定当前状态和动作的情况下,折扣回报的期望
(3).值函数 (value function)
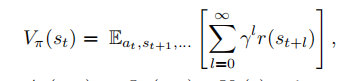
给定当前状态的情况下,折扣回报的期望
(4).优势函数 (advantage function)
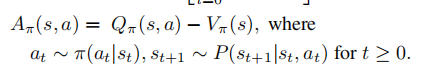
Part2.
新策略的期望值函数
通过part1给出的几个公式,可以把回报函数定义如下:
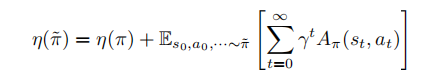 (1)
(1)
让我们逐步解释这个公式中的每个符号:
- η(π) 是原始策略 π 的值函数(Value Function)。
- η(˜π) 是改进后的策略 ˜π 的值函数。
- Es0,a0,···∼˜π 表示按照改进后的策略 ˜π 在时间步 t=0,1,2,... 上进行采样。
公式的右侧部分表示对改进后的策略 ˜π 进行采样,然后根据每个时间步的状态和动作使用原始策略 π 的值函数 Aπ(st, at) 进行加权累积。Aπ(st, at) 是从状态 st 开始,并采取动作 at,按照策略 π 进行后续动作的累积奖励的期望值。
这个公式的目的是对新策略 ˜π 进行评估,以确定它相对于原始策略 π 的价值。通过将原始策略的值函数和改进后策略通过上述方式进行加权累积,可以得到改进后策略的值函数。
令
可得
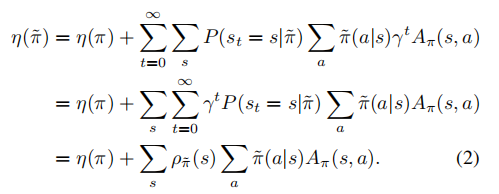
只要保证
![]()
就可以得出更优的策略˜π
然而,在近似设置中,由于估计和近似误差,通常不可避免地会有一些状态的预期优势是负的。并且ρ˜π(s)对˜π的复杂依赖性使得方程(2)难以直接优化。所以将(2)中访问频率为ρ˜π改为ρπ
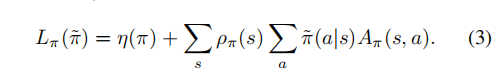
对于任何参数值θ0,
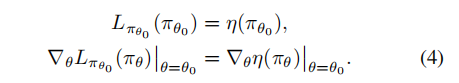
由(4)可知在一个足够小的步骤πθ0→˜π改进Lπθold也会改善η,但是我们并不知道这个足够小的改进到底是多少,所以为了解决这个问题,Kakade & Langford(2002)提出了一种称为保守策略迭代的策略更新方案,它们可以为η的改进提供明确的下界。
新的策略πnew被定义为以下混合策略
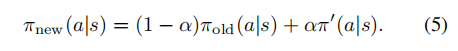
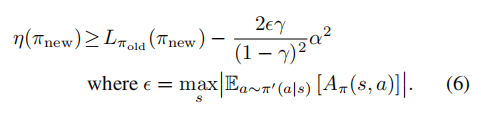
Part3.
对公式(6)的改进
(1)概率分布的差距
方程(6)中的策略改进界可以扩展到一般的随机策略,而不仅仅是混合策略,方法是用π和˜π之间的距离度量代替α,并适当地改变常数,我们使用的距离度量方法是总变差散度(Total Variation Variance)
![]()
得出
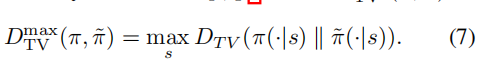
我们使用总变差散度(Total Variation Divergence)作为特定的距离测量方法。总变差散度用于衡量两个离散概率分布之间的差异程度。
1. 对于每个可能的状态 s,计算 ,![]() 即计算在给定状态下两个条件概率分布之间的总变差散度。
即计算在给定状态下两个条件概率分布之间的总变差散度。
2. 从所得到的各状态的总变差散度值中选择最大值。这样就得到了两个离散概率分布之间的最大总变差散度。
(2)改进
令![]()
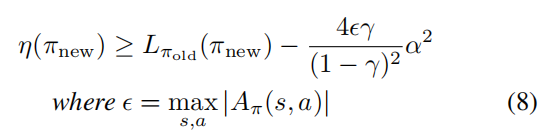
我们注意到总变异散度和KL散度之间的以下关系![]()
使![]()
得出下面的界限
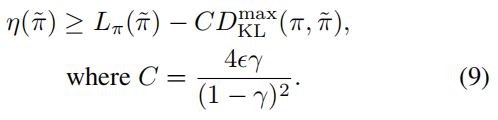
(3)优化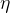
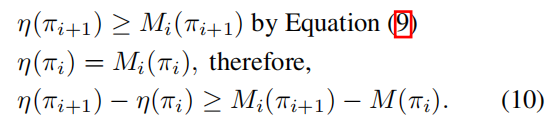
(10)中![]()
通过(10)的证明我们可以知道,对下界优化一定可以优化
(4)算法(1)伪代码

信任区域策略优化,我们将在下面中提出,是算法1的近似,该算法使用对KL散度的约束,而不是惩罚来稳健地允许大的更新。
4.信赖阈优化
(1)引入参数
由于要考虑带参数的参数化策略,所以进行一些符号替代
![]()
![]()
(2)引入信赖阈
由此通过执行以下最大化,我们可以保证改进真正的目标η
![]()
缺点:在实践中,如果我们使用上述理论推荐的惩罚系数C,步长将会非常小
解决:更稳健的扩大步长的方式是使用KL散度来在新策略和就策略之间进行约束,如下:
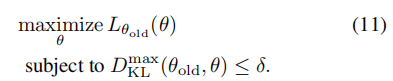
公式(11)中的约束就是信赖阈约束,由之前的
![]()
公式(11)是一种最大化目标函数的优化问题,其中目标函数为 L(θ_old, θ),即希望找到一个参数值 θ,使得 L 函数取得最大值。同时,该问题还包含一个约束条件,即 KL 散度(Kullback-Leibler divergence)在状态空间的每个点都要小于等于 δ。
在强化学习中,通常使用梯度上升法(gradient ascent)或其他优化算法来求解这类目标函数的最大化问题。具体而言,可以通过迭代地调整参数值 θ 来逐步提高目标函数的值,直到满足约束条件。
然而,由于该问题中约束条件的数量巨大,实际求解起来非常困难。大量的约束条件导致计算复杂度很高,并且可能导致优化问题变得不可解。因此,在实践中,我们通常需要使用近似方法或启发式算法来解决这类问题,以便在可接受的时间内获得较好的解。
启发式近似:在问题的求解空间中进行有选择地搜索,而不是穷举所有可能的解。通过借助领域知识和问题特征,设计一些启发式规则来指导搜索的方向和顺序,以期望更快地找到一个满意的解。
我们可以使用一个启发式近似来考虑平均KL散度:
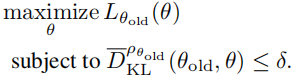
5.信赖阈体现在哪里
1. 策略更新的约束:TRPO通过限制每次策略更新的步长,以保证更新后的策略不会跨越过大的信赖区域。具体而言,TRPO通过定义一个最大的KL散度(Kullback-Leibler Divergence)来衡量策略更新前后的差异。在每次策略更新时,TRPO会尽可能地最大化目标函数的下界,同时限制KL散度的增加不超过设定的阈值。这样就确保了策略更新的幅度在可接受的信赖范围内。
2. 策略评估的探索性搜索:TRPO在策略评估中使用一种探索性搜索方法,称为线性搜索(line search)。在每次策略评估的过程中,TRPO会尝试找到一个在信赖区域内最大化目标函数下界的步长。线性搜索的目标是找到一个适当的步长,既能提供有意义的策略改进,又不超出信赖区域。通过逐步调整步长,TRPO可以在保持策略在信赖区域内的情况下,尽可能地提高目标函数的下界。
这两个方面的信赖区域约束使得TRPO在策略优化过程中更加稳定和可靠,避免了更新幅度过大引发的不稳定性,并且能够探索具有更高性能的策略。















 706
706











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









