






import os
import pandas as pd
import matplotlib.pyplot as plt
import csv
def calculate_wavelength_in_nm(energy_joules): # 能量波长转换
# 普朗克常数 h (J·s)
planck_constant = 6.626e-34 # 焦耳·秒
# 光速 c (m/s)
speed_of_light = 3e8 # 米/秒
# 计算波长 (m)
wavelength_m = (planck_constant * speed_of_light) / (energy_joules * 1e-19)
# 将波长换算成纳米 (nm)
wavelength_nm = wavelength_m * 1e9 # 1米 = 10^9纳米
return wavelength_nm
def file_p(file, a, b):
data = []
for root, dirs, files in os.walk(file): # 遍历文件夹下的子文件
for file in files:
# 打开文件
ft = os.path.join(root, file)
data.append(ft) # 储存子文件路径
print(ft)
n = 0
col = ['r', 'g', 'b', 'gold', 'cyan', 'k'] # 颜色列表
nu = 0
for i in data: # 遍历csv文件
new_row_first_column = 'x'
new_row_second_column = 'y'
path = i.strip('"')
fl = path.split('\\')
path_r = '/'.join(fl)
pfl = '/'.join(fl[:-1]) + f'/{fl[-1][:-4]}_mod.csv'
lim = []
x = []
y = []
# 读取原始CSV文件
with open(path_r, 'r', newline='', encoding='utf-8') as csvfile:
reader = csv.reader(csvfile)
rx = [i[0] for i in reader] # 遍历第一列数据
with open(path_r, 'r', newline='', encoding='utf-8') as csvfile:
reader = csv.reader(csvfile)
ry = [i[1] for i in reader] # 遍历第二列数据
"""文件中并不全是我们所需的数据,下面是选取部分区域的数据"""
for i in rx:
if a < float(i) < b:
x.append(i)
for i in x:
y.append(ry[rx.index(i)])
min_l = rx.index(x[0]) # 这个是用来赋值选取后的第一列数值的第一个值(即最小值)
max_l = rx.index(x[-1]) # 这个是用来赋值选取后的第一列数值的最后一个值(即最大值)
lim.append(int(min_l)) # 转换为整数类型
lim.append(int(max_l))
# 写入新CSV文件,包括新添加的行
with open(pfl, 'w', newline='', encoding='utf-8') as newfile:
writer = csv.writer(newfile)
# 写入新行
new_row = [new_row_first_column, new_row_second_column]
writer.writerow(new_row) # 在csv列表中写入新行,即[x,y]
# 写入原始CSV文件的其余内容
for i in range(len(x)):
writer.writerow([x[i], y[i]])
data = pd.read_csv(pfl)
lx, ly = data['x'], data['y']
"""开始绘图"""
plt.figure(figsize=(20, 10), dpi=100)
plt.rcParams["font.size"] = 18
plt.rcParams["font.family"] = "Times New Roman"
plt.grid(visible=True, which='major', linestyle='-')
plt.grid(visible=True, which='minor', linestyle='--', alpha=0.5)
plt.minorticks_on()
pty = [i for i in ly]
ptx = [calculate_wavelength_in_nm(i) for i in lx]
plt.plot(ptx, pty, '-', color="b", label=fl[-1][0:13], linewidth=1)
plt.title(f'{fl[-1][0:13]} Optical Properties(abs)')
plt.xlabel("wavelength/nm")
plt.ylabel("Absorption")
plt.legend()
plt.savefig(cpath + f"{fl[-1][0:-4]}.png")
plt.show()
plt.close()
if __name__ == "__main__":
path = input('输入文件路径:').strip('"') # "C:\Users\wayuper\Desktop\opt"
fl = path.split('\\')
path_r = '/'.join(fl)
cpath = '/'.join(path_r.split("/")[:-1]) + '/figure band/' # 图形导出路径
a, b = 2.43, 28 # 这个使用设置绘画区域
if not os.path.exists(cpath): # 创建这个文件夹
os.makedirs(cpath)
print('存储'+cpath)
file_p(path_r, a, b)
print('运行完毕')本次处理的文件格式是csv,是经castep计算导出的晶体光学特性图(abs),大致包括遍历文件,数值转换,绘图,导出。使用第三方库matplotlib,pandas,csv。
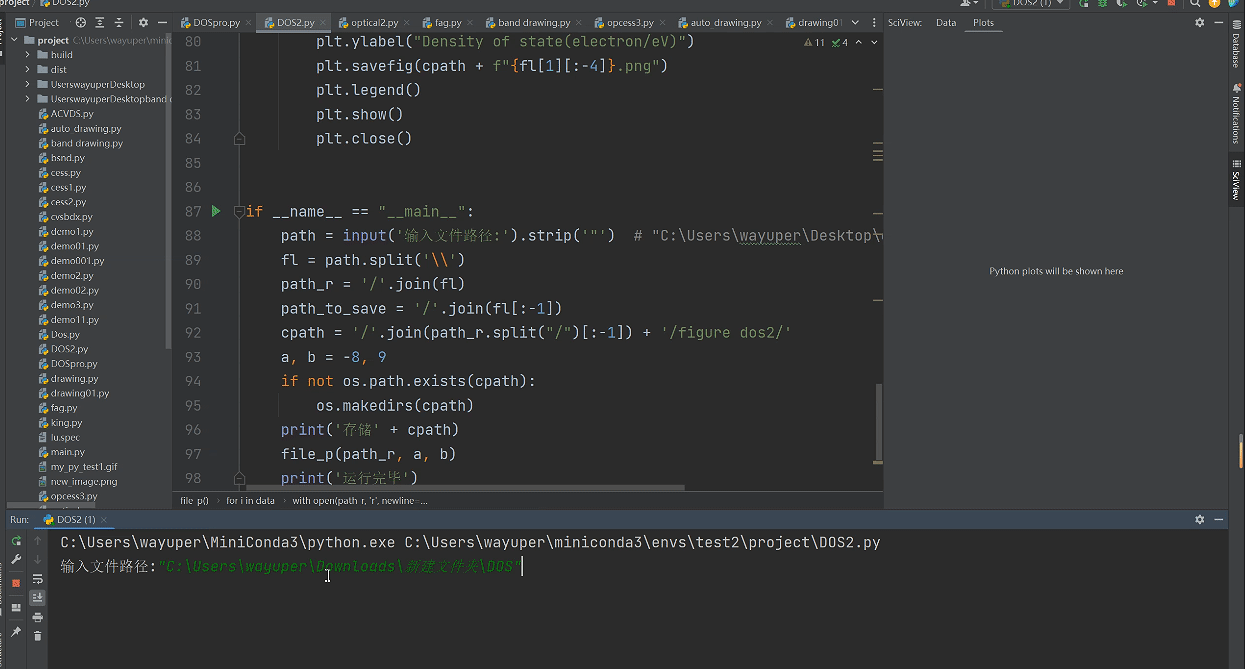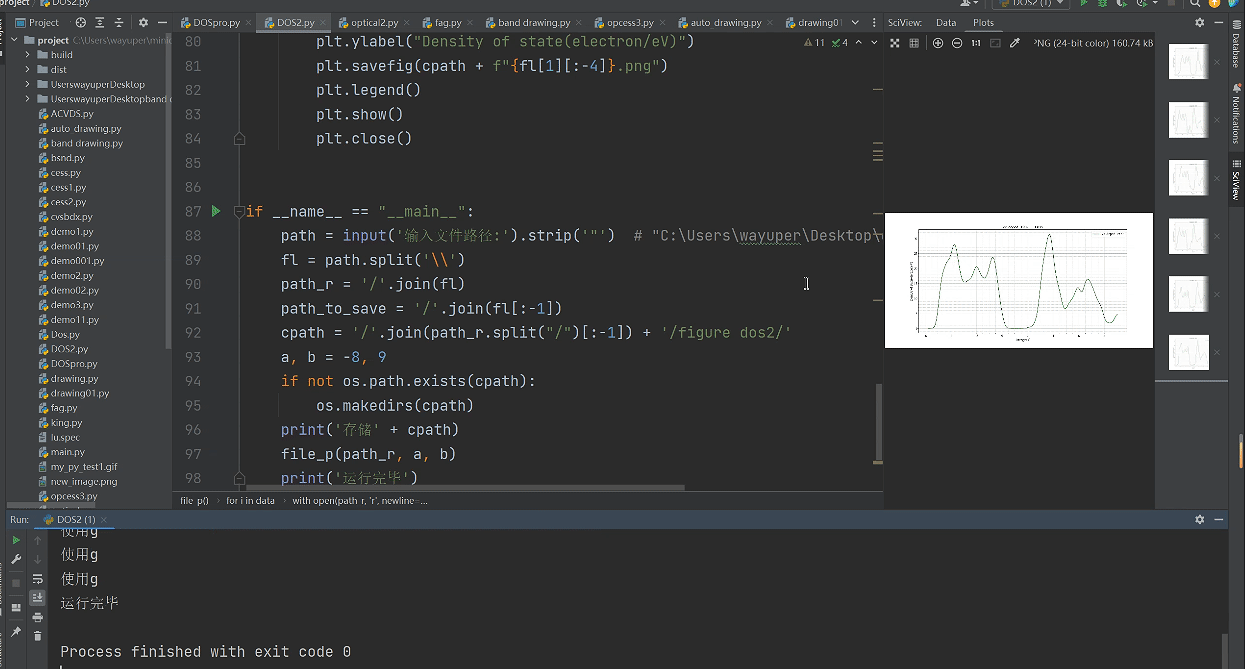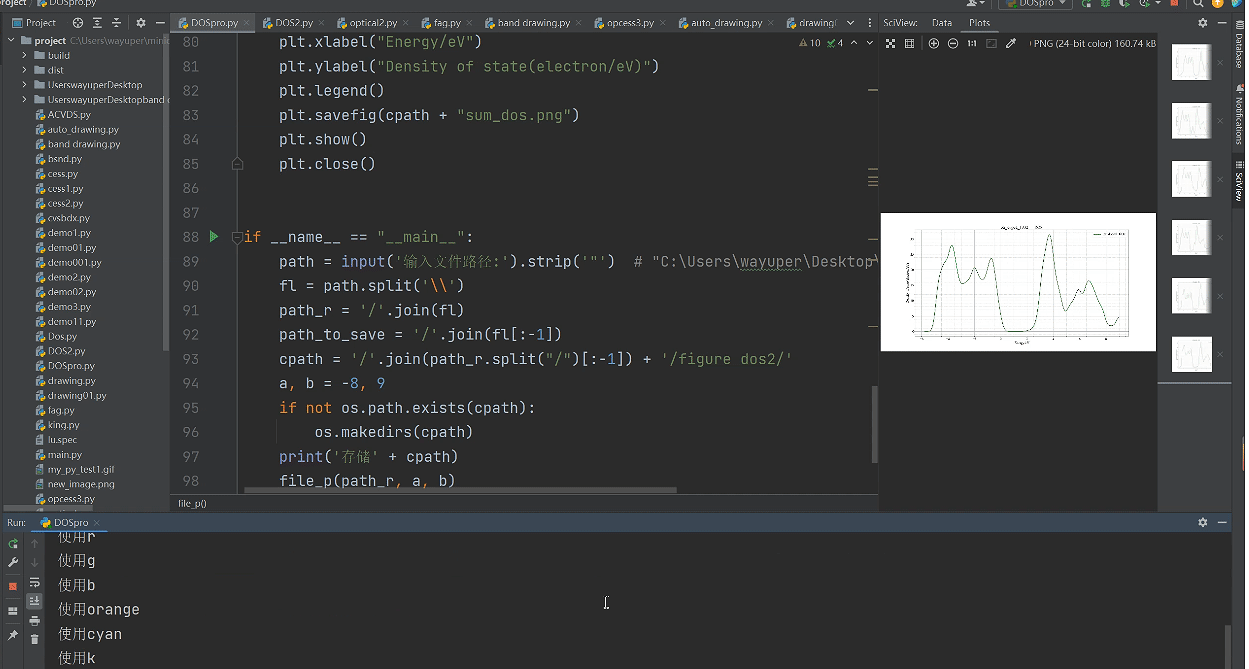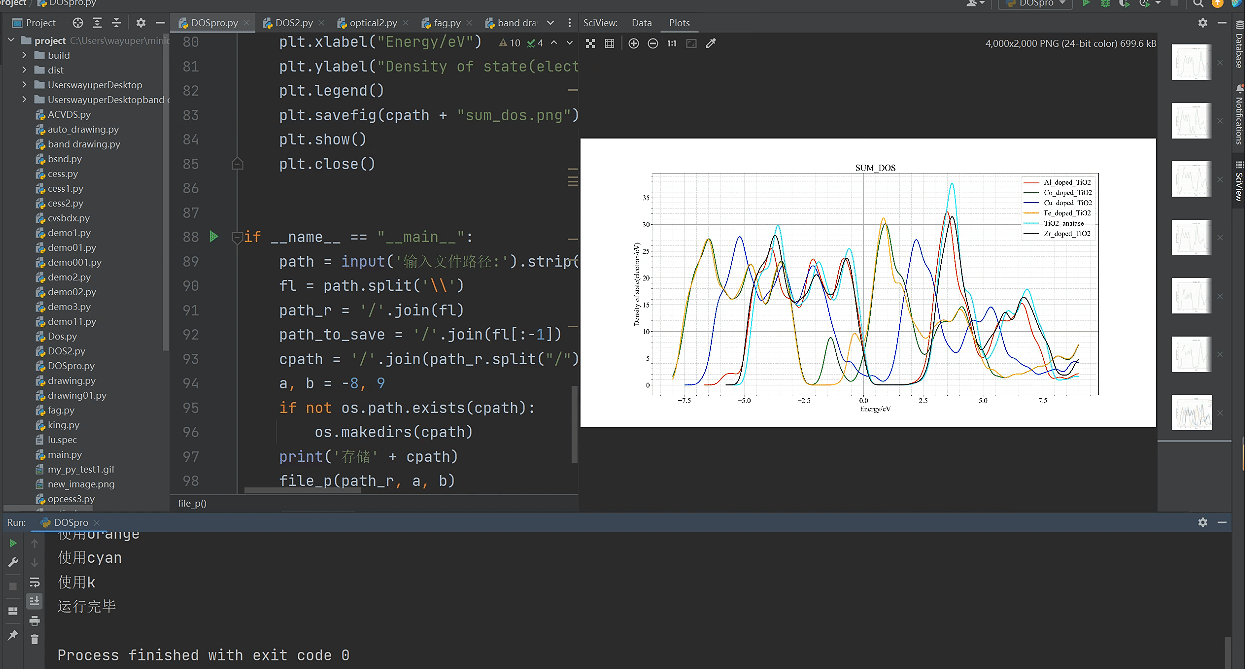
最后绘制汇总图时,改变循环
def file_p(file, a, b):
data = []
for root, dirs, files in os.walk(file): # 遍历文件夹下的子文件
for file in files:
# 打开文件
ft = os.path.join(root, file)
data.append(ft) # 储存子文件路径
print(ft)
n = 0
col = ['r', 'g', 'b', 'orange', 'cyan', 'k'] # 颜色列表
nu = 0
“”“下面这几段代码提前了, 放在了for i in data:外面”“”
plt.figure(figsize=(20, 10), dpi=600)
plt.rcParams["font.size"] = 18
plt.rcParams["font.family"] = "Times New Roman"
plt.grid(visible=True, which='major', linestyle='-')
plt.grid(visible=True, which='minor', linestyle='--', alpha=0.5)
plt.minorticks_on()
for i in data: # 遍历csv文件
new_row_first_column = 'x'
new_row_second_column = 'y'
path = i.strip('"')
fl = path.split('\\')
path_r = '/'.join(fl)
pfl = '/'.join(fl[:-1]) + f'/{fl[-1][:-4]}_mod.csv'
lim = []
x = []
y = []
# 读取原始CSV文件
with open(path_r, 'r', newline='', encoding='utf-8') as csvfile:
reader = csv.reader(csvfile)
rx = [i[0] for i in reader] # 遍历第一列数据
with open(path_r, 'r', newline='', encoding='utf-8') as csvfile:
reader = csv.reader(csvfile)
ry = [i[1] for i in reader] # 遍历第二列数据
"""文件中并不全是我们所需的数据,下面是选取部分区域的数据"""
for i in rx:
if a < float(i) < b:
x.append(i)
for i in x:
y.append(ry[rx.index(i)])
min_l = rx.index(x[0]) # 这个是用来赋值选取后的第一列数值的第一个值(即最小值)
max_l = rx.index(x[-1]) # 这个是用来赋值选取后的第一列数值的最后一个值(即最大值)
lim.append(int(min_l)) # 转换为整数类型
lim.append(int(max_l))
# 写入新CSV文件,包括新添加的行
with open(pfl, 'w', newline='', encoding='utf-8') as newfile:
writer = csv.writer(newfile)
# 写入新行
new_row = [new_row_first_column, new_row_second_column]
writer.writerow(new_row) # 在csv列表中写入新行,即[x,y]
# 写入原始CSV文件的其余内容
for i in range(lim[1]-lim[0]): # 这个
writer.writerow([x[i], y[i]])
data = pd.read_csv(pfl)
lx, ly = data['x'], data['y']
# ptyy = [math.log(1/i, 10) for i in ly]
pty = [i for i in ly]
ptx = [calculate_wavelength_in_nm(i) for i in lx]
# plt.plot(lx, ly, '-', color="b", label='reflectivity', linewidth=2)
plt.plot(ptx, pty, '-', color=col[nu], label=fl[-1][0:13], linewidth=1)
nu += 1
# plt.plot(ptx, ptyy, '-', color="r", label='absorb A=Lg(1/R)', linewidth=1)
# plt.plot(lx1, ly1, '-', color="r", label='reflectivity1', linewidth=2)
# plt.plot(lx1, pt1, '-', color="r", label='absorb1', linewidth=1)
plt.title(f'sum Optical Properties(abs)')
plt.xlabel("wavelength/nm")
plt.ylabel("Absorption")
plt.legend()
plt.savefig(cpath + "sum_Optical Properties.png")
plt.show()
plt.close()
其他代码部分不变。















 1532
1532











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









