






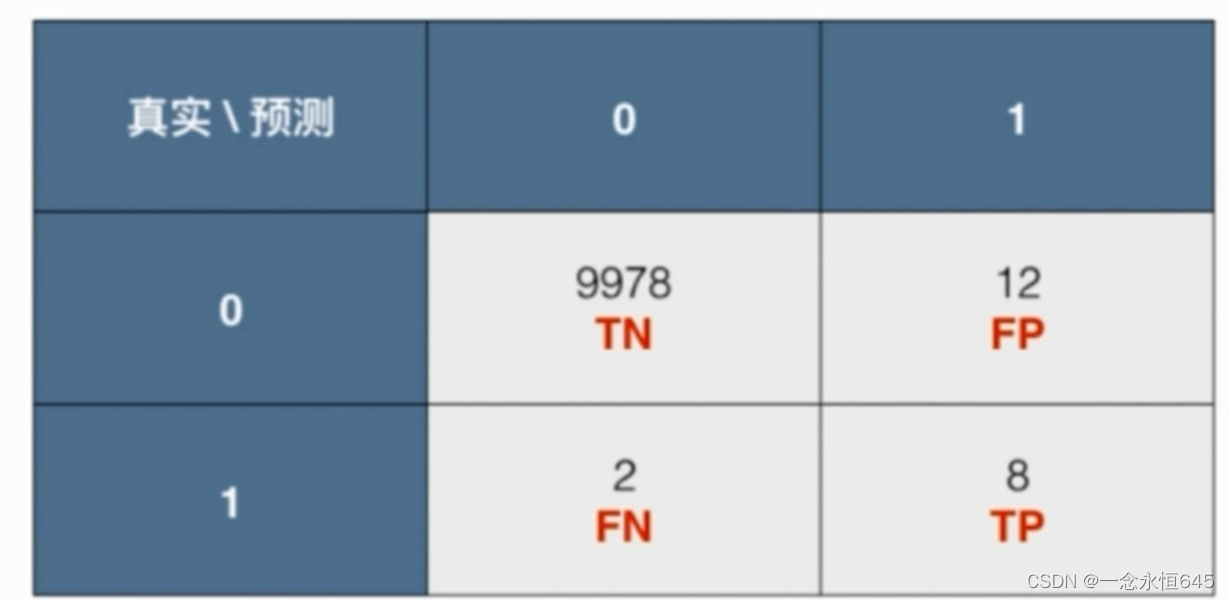
图1.1
其中,TP(True Positive)表示真正例,模型正确预测为正例的样本数量;TN(True Negative)表示真反例,模型正确预测为反例的样本数量;FP(False Positive)表示假正例,模型错误地将反例预测为正例的样本数量;FN(False Negative)表示假反例,模型错误地将正例预测为反例的样本数量
一、准确率
准确率(Accuracy):衡量模型正确预测样本数量与总样本数量之比,公式为:
Accuracy = (TP + TN) / (TP + TN + FP + FN)
使用场景:数据集类别分布均衡的情况。
计算TP ,TN ,FP , FN指标
import matplotlib.pyplot as plt
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import confusion_matrix, roc_curve, auc
# 加载breast cancer数据集
data = load_breast_cancer()
X = data.data
y = data.target
# 划分训练集和测试集
x_train,x_test,y_train,y_test=train_test_split(X,y,random_state=500,test_size=0.2)
# 使用逻辑回归模型进行训练
lr=LogisticRegression().fit(x_train,y_train)
y_pred=lr.predict(x_test)
# 计算混淆矩阵
cm=confusion_matrix(y_test,y_pred)
# 提取混淆矩阵中的相关指标tp,tn,fp,fn
tn=cm[0][0]
fp=cm[0][1]
fn=cm[1][0]
tp=cm[1][1]accuracy=(tp+tn)/(tn+fp+fn+tp)
print("准确率为:",accuracy)二、精准率
精确率(Precision):衡量模型在预测为正例的样本中,真正例的比例。公式为:
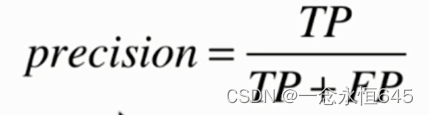
适用场景:注重模型预测的准确性,数据集类别分布不均衡,关注假正例的场景
eg:(1)假如有10000家公司,某一个模型对这10000家公司进行预测是不是造假公司(是:1,不是:0),预测数据图1.1所示
在这些数据里,(真实\预测)11和00的情况对模型来说是最好的,没有坏的影响,那么10和01那个数据对模型影响更大,在这里很明显是01(真实不是造假公司,预测却是造假公司,这会对一个公司造成不可挽回的声誉影响),所以要用一个指标来表示这01的占比,即是:预测为正例的样本中,01的比例,公式为:false-positive=FP/(TP+FP),这个值越小越好(召回率和F值均是同类数值,重点对象不一样而已)
注意:代码和造假公司是两个案例
而精确值:precision=1-false-positive,这个值越大越好
precision=tp/(tp+fp)
print("精准率为:",precision)三、召回率
召回率(Recall):衡量模型在所有真正例中成功预测为正例的比例。公式为:
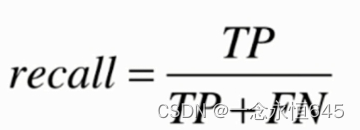
适用场景:注重模型预测的全面性,数据集类别分布不均衡,关注假反例的场景
recall=tp/(fn+tp)
print("召回率为:",recall)四、F值
一般情况下,算法的精确率与召回率是不可兼得的。是用于平衡精确率和召回率的指标,在要求两者都高的情况下,通常是选择两者的综合做为算法效果的度量(F值,精确率和召回率的调和平均值)公式为:
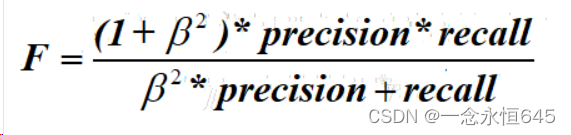
一般取值为1,称为F1值,公式为:
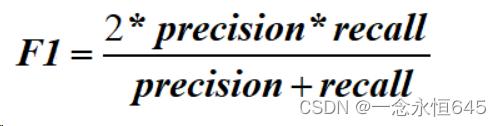
2的存在对优化模型没有很大影响,故也可以写成

适用场景:精确率和召回率都重要的场景。
F1=1.0/(1.0/recall+1.0/precision)
print("F1值为:",F1)五、ROC曲线
ROC曲线(Receiver Operating Characteristic):以真正例率(True Positive Rate)为纵轴,假正例率(False Positive Rate)为横轴绘制的曲线。
适用场景:不同阈值下模型的性能比较。

六、AUC(Area Under the ROC Curve)
AUC:ROC曲线下的面积,用于评估模型的整体性能。ROC曲线下的面积(AUC,Area Under the Curve)被用作评估模型性能的指标。AUC的取值范围在0到1之间,越接近1表示模型性能越好,越接近0.5表示模型性能越差。
适用场景:样本不均衡的情况
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import confusion_matrix, roc_curve, auc
plt.rcParams['font.sans-serif'] = 'SimHei'## 设置中文显示
plt.rcParams['axes.unicode_minus'] = False
# 加载breast cancer数据集
data = load_breast_cancer()
X = data.data
y = data.target
# 划分训练集和测试集
x_train,x_test,y_train,y_test=train_test_split(X,y,random_state=500,test_size=0.2)
# 使用逻辑回归模型进行训练
lr=LogisticRegression().fit(x_train,y_train)
# 计算预测概率大于不同阈值时的混淆矩阵
thresholds = np.linspace(0, 1, num=100)
tprs = []
fprs = []
precisions = []
recalls = []
for threshold in thresholds:
# 根据阈值将预测结果分类
y_p=((lr.predict_proba(x_test)[:,-1]>threshold).astype('int'))
# 计算混淆矩阵
cm=confusion_matrix(y_test,y_p)
# 提取混淆矩阵中的相关指标tp,tn,fp,fn
tn=cm[0][0]
fp=cm[0][1]
fn=cm[1][0]
tp=cm[1][1]
# 计算真阳性率、假阳性率、准确率和召回率tpr,fpr,precision,recall
tpr=tp/(tp+fn)
fpr=fp/(tn+fp)
precision=tp/(tp+fp)
recall=tp/(fn+tp)
tprs.append(tpr)
fprs.append(fpr)
precisions.append(precision)
recalls.append(recall)
# 用roc_curve计算ROC曲线
fprs,tprs,th=roc_curve(y_test,lr.predict_proba(x_test)[:,-1])
# 计算ROC曲线下的面积AUC
auc_scores=auc(fprs,tprs)
# 绘制ROC曲线以及AUC值
plt.figure(figsize=(6, 6))
plt.plot(fprs, tprs, label='AUC = %0.5f' % auc_scores)
plt.xlabel('假正例率fp')
plt.ylabel('真正例率tp')
plt.title('ROC曲线')
plt.legend(loc="lower right")
plt.show()
















 1142
1142

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









