






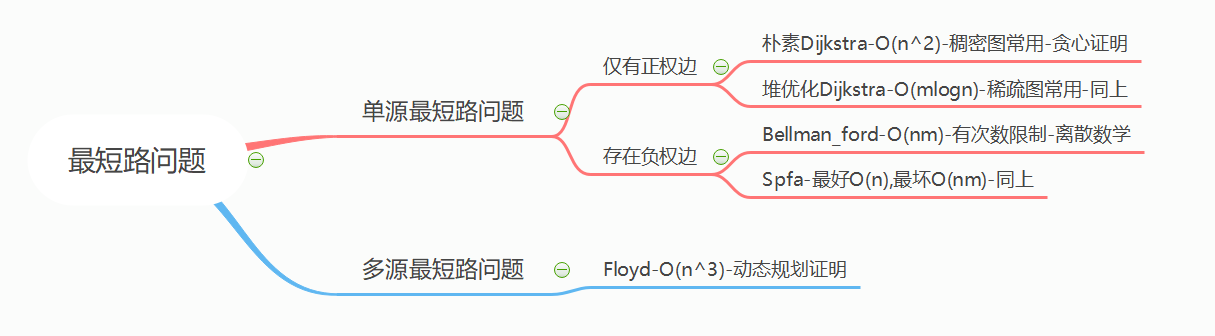
首先告诉大家什么时候用邻接表去存,什么时候用邻接矩阵去存:
根据邻接表和邻接矩阵的结构特性可知,当图为稀疏图、顶点较多,即图结构比较大时,更适宜选择邻接表作为存储结构。
判断稀疏和稠密的因素是判断E(点)和pow(V,2)(边的平方)的大小,如果E远小于pow为稀疏图;如果差不多数量为稠密图
如何选择方法:
一:dijkstra算法求最短路(朴素版)
dijkstra朴素版使用邻接矩阵的存储形式去存储数据,矩阵矩阵,顾名思义就是使用二维数组去a[x][y]去表示x点到y点的距离。
接下来上题目
题目:
给定一个 n 个点 m 条边的有向图,图中可能存在重边和自环,所有边权均为正值。
请你求出 1 号点到 n 号点的最短距离,如果无法从 1 号点走到 n 号点,则输出 −1。
输入格式
第一行包含整数 n 和 m。
接下来 m 行每行包含三个整数 x,y,z,表示存在一条从点 x 到点 y 的有向边,边长为 z。
输出格式
输出一个整数,表示 1 号点到 n 号点的最短距离。
如果路径不存在,则输出 −1。
数据范围
1≤n≤500
1≤m≤10e5,
图中涉及边长均不超过10000。
输入样例:
3 3
1 2 2
2 3 1
1 3 4
输出样例:
3接下来我们上代码,在相关代码上我都有注释帮助大家去理解
#include<iostream>
#include<cstring>
#include<cmath>
using namespace std;
const int N=550;
int g[N][N]; //邻接矩阵去存储
int dist[N]; //表示第x(下标)个点到1号点的距离
int n,m;
int a,b,w; //a点到b点边的权重为w
bool vis[N]; //判断数组,判断当前这个边是不是已经被更新
int dijkstra(){
memset(dist,0x3f,sizeof(dist)); //首先我们初始化所有点到1号点的距离为正无穷
dist[1]=0;
for(int i=1;i<n;i++){ //进行n次或n-1次循环
int t=-1; //这个点第一次进去,用t=-1去标记它
for(int j=1;j<=n;j++)
if(!vis[j]&&(t==-1||dist[t]>dist[j]))
t=j; //这一重循环是为了找到距离1号点最近的点t
//cout<<"3331"<<' '<<t<<' '<<dist[t]<<' ';
vis[t]=true; //t这个点已经更新过了,做标记
for(int j=1;j<=n;j++){
dist[j]=min(dist[j],dist[t]+g[t][j]); //用t这个点去更新其他点的距离
}
// cout<<dist[n]<<endl;
}
if(dist[n]==0x3f3f3f3f) return -1;
return dist[n];
}
int main(){
cin>>n>>m;
memset(g,0x3f,sizeof(g));
while(m--){
cin>>a>>b>>w;
g[a][b]=min(g[a][b],w);
}
int t=dijkstra();
printf("%d",t);
}注意:dijkstra不能处理负边问题,下面有一篇文章讲的挺清楚的,大家可以去看看
https://blog.csdn.net/sugarbliss/article/details/86498323
二:dijkstra算法求最短路(堆优化版)
dijkstra优化版使用邻接表的形式去存储数据,那么我们首先介绍一下邻接表的定义和代码实现
int h[N],e[N],ne[N],idx;
void add(int a,int b){
e[idx]=b;
ne[idx]=h[a];
h[a]=idx++;
}这段代码的含义就是将所有与a相连的边存储形成一个链表,例如 看一个题目的样例
题目:
给定一个 n 个点 m 条边的有向图,图中可能存在重边和自环,所有边权均为非负值。
请你求出 1 号点到 n 号点的最短距离,如果无法从 11 号点走到 nn 号点,则输出 −1−1。
输入格式
第一行包含整数 n 和 m。
接下来 m 行每行包含三个整数 x,y,z,表示存在一条从点 x 到点 y 的有向边,边长为 z。
输出格式
输出一个整数,表示 1 号点到 n 号点的最短距离。
如果路径不存在,则输出 −1。
数据范围
1≤n,m≤1.5×105,
图中涉及边长均不小于 00,且不超过 10000
数据保证:如果最短路存在,则最短路的长度不超过 10e9。
输入样例:
3 3
1 2 2
2 3 1
1 3 4
输出样例:
3那么题目上的三条边是 1 2 2,2 3 1,1 3 4,在进行完我们的加边操作之后,存储的形式就会变成
1-2-3,2-3,就会变成这种形式

明白这个建表方式之后,我们来看看题目该如何去处理
#include<iostream>
#include<queue>
#include<cstring>
using namespace std;
typedef pair<int,int> PII;
const int N=200000;
int h[N],e[N],w[N],ne[N],idx;
bool vis[N];
int dist[N];
int n,m;
int a,b,c;
void add(int x,int y,int z){
e[idx]=y;
w[idx]=z;
ne[idx]=h[x];
h[x]=idx++;
}
int dijkstra(){
memset(dist,0x3f,sizeof dist);
dist[1]=0;
priority_queue<PII,vector<PII>,greater<PII> >heap; //用小根堆去存数据,它会将较小的数据放在堆顶
heap.push({0,1}); //1号点距离1号点的距离是0,{first(距离),second(当前点)}
while(heap.size()){
auto t=heap.top(); //一定是当前队列里距离1号点最近的点;
heap.pop();
int distance=t.first;
int ver=t.second;
if(vis[ver]) continue; //如果已经是最短的了,就进行下一次循环
vis[ver]=true; //不是的话就标记
for(int i=h[ver];i!=-1;i=ne[i]){ //用当前这个距离1号点最近的点去更新与当前这个点(x)相连的所有边(也就是x做链表头的这个链表)
int j=e[i]; //e[i]是这个点b
if(dist[j]>dist[ver]+w[i])
{
dist[j]=dist[ver]+w[i];
heap.push({dist[j],j});
}
}
}
if(dist[n]==0x3f3f3f3f) return -1;
return dist[n];
}
int main(){
memset(h,-1,sizeof(h));
cin>>n>>m;
while(m--){
cin>>a>>b>>c;
add(a,b,c);
}
cout<<dijkstra();
}三:bellman_ford算法求最短路
bellman_ford算法适用于一些有边数限制的最短路问题,我们想一想刚才我们解决的两个问题,他们都是要求1号点到n号点的最短路径是多少,题目并没有给我们一个限制走多少条边,那现在我要求你在5条边之内到达n点,并且要求距离最短,那么你该如何去解决这个问题呢?
接下来我们就来看一道这样的题目:
题目:
给定一个 n 个点 m 条边的有向图,图中可能存在重边和自环, 边权可能为负数。
请你求出从 1号点到 n 号点的最多经过 k 条边的最短距离,如果无法从 1 号点走到 n 号点,输出 impossible。
注意:图中可能 存在负权回路 。
输入格式
第一行包含三个整数 n,m,k。
接下来 mm 行,每行包含三个整数 x,y,z,表示存在一条从点 x 到点 y 的有向边,边长为 z。
点的编号为 1∼n。
输出格式
输出一个整数,表示从 1 号点到 n 号点的最多经过 k 条边的最短距离。
如果不存在满足条件的路径,则输出 impossible。
数据范围
1≤n,k≤500,
1≤m≤10000,
1≤x,y≤n,
任意边长的绝对值不超过 10000。
输入样例:
3 3 1
1 2 1
2 3 1
1 3 3
输出样例:
3大家先看代码,注意代码中的last数组,想一想为什么要多用一个last的数组,而不是直接用dist数组,同时边权可以为负数
#include<iostream>
#include<cstring>
using namespace std;
const int N=510,M=10010;
int n,m,k;
int dist[N],last[N];
int a,b,c;
typedef struct Edge{
int a;
int b;
int w;
}; //用结构体来存边
Edge edges[M];
void bellman_ford(){
dist[1]=0;
for(int i=0;i<k;i++){ //因为要在k条边内解决掉问题,所以我们只需要进行k次循环
memcpy(last,dist,sizeof(dist)); //记录上次迭代的数据
for(int j=0;j<m;j++){
auto e=edges[j]; //更新距离这m条边的距离
dist[e.b]=min(dist[e.b],last[e.a]+e.w);
}
}
}
int main(){
memset(dist,0x3f,sizeof(dist));
cin>>n>>m>>k;
for(int i=0;i<m;i++){
cin>>a>>b>>c;
edges[i]={a,b,c};
}
bellman_ford();
if(dist[n]>0x3f3f3f3f/2) cout<<"impossible";
else cout<<dist[n];
}注意last数组的用途!!!!
看样例,如果把这个last换成dist的话,在更新3号点的时候2号点已经被更新了,那么3号点的更新会在2的基础上更新,更新过后dist[3]=2,但是这个时候用了2条边,超过了k的值,这就是为什么我们要用上一次的迭代结果去执行这次的更新。

不知道大家有没有一个疑问,bellman_ford算法的代码量怎么少,为什么不用他去解决dijkstra的问题呢,只需要把第一层for循环改为n层,起初我也有这样的疑问,所以我也就去尝试了,但是结果是Segmentation Fault ,也就是我们常说的爆内存,在看了这两道题的数据范围后,我认为(仅仅是我认为),
在dijkstra中边是非常多的,m<100000;
在bellman_ford中边是少的,1≤m≤10000,这可能也是他为什么使用结构体来存储边的原因了,所以在边数过多时爆了。
这个问题我还没想明白,如果有大佬明白的话,可以私信帮帮我
四.spfa算法求最短路
题目
给定一个 n 个点 m 条边的有向图,图中可能存在重边和自环, 边权可能为负数。
请你求出 11 号点到 nn 号点的最短距离,如果无法从 1 号点走到 n 号点,则输出 impossible。
数据保证不存在负权回路。
输入格式
第一行包含整数 n 和 m。
接下来 m 行每行包含三个整数 x,y,z,表示存在一条从点 xx 到点 yy 的有向边,边长为 zz。
输出格式
输出一个整数,表示 1 号点到 n 号点的最短距离。
如果路径不存在,则输出 impossible。
数据范围
1≤n,m≤10e5
图中涉及边长绝对值均不超过 10000。
输入样例:
3 3
1 2 5
2 3 -3
1 3 4
输出样例:
2
在理解了上面的几个问题之后,在接着往下看,难度就慢慢减小了。先看点和边,发现范围差不多,所以我们选择邻接表来存
上代码
#include<iostream>
#include<cstring>
#include<queue>
#include<algorithm>
using namespace std;
const int N=1e5+10;
int n,m;
int h[N],w[N],e[N],ne[N],idx;
int dist[N];
bool st[N];
int a,b,c;
//用更新过的点去更新别的点,因为第一次更新进去队列的是距离小的,所以用他去更新其他的点
void add(int a,int b,int c){
e[idx]=b;
w[idx]=c;
ne[idx]=h[a];
h[a]=idx++;
}
int spfa(){
dist[1]=0;
queue<int>q;
q.push(1);
st[1]=true;
while(q.size()){
int t=q.front();
q.pop();
st[t]=false;
for(int i=h[t];i!=-1;i=ne[i]){
int j=e[i];
if(dist[j]>dist[t]+w[i])
{
dist[j]=dist[t]+w[i];
if(!st[j]){
q.push(j);
st[j]=true;
}
}
}
}
return dist[n];
}
int main(){
memset(dist,0x3f,sizeof(dist));
memset(h,-1,sizeof(h));
cin>>n>>m;
while(m--){
cin>>a>>b>>c;
add(a,b,c);
}
// spfa();
int t=spfa();
/*for(int i=1;i<=m;i++){
if(st[i]==true)
cout<<i;
}*/
if(t==0x3f3f3f3f) cout<<"impossible";
else cout<<t;
}
spfa算法的牛逼之处就在于他每次更新都是用的对头元素去更新,而我们发现队列里的元素都是被更新过的,也就是说用更新过的点去更新其他不在队列里的点
看文字不能清楚理解
建议大家去看看这个大佬的图片模拟,看完图之后在回来看代码,会豁然开朗的
https://www.acwing.com/solution/content/105508/
spfa和dijkstra的区别:
st用来检验队列中是否有重复的点
spfa从队列中使用了当前的点,会把该点pop掉,状态数组st[i] = false(说明堆中不存在了) ,更新临边之后,把临边放入队列中, 并且设置状态数组为true,表示放入队列中 。如果当前的点距离变小,可能会再次进入队列,因此可以检验负环:
每次更新可以记录一次,如果记录的次数 > n,代表存在负环(注意这句话,这也就是接下来我们spfa判断是否有负环的理论基础)(环一定是负的,因为只有负环才会不断循环下去)。
五:spfa求负环
题目:
给定一个 n 个点 m 条边的有向图,图中可能存在重边和自环, 边权可能为负数。
请你判断图中是否存在负权回路。
输入格式
第一行包含整数 n 和 m。
接下来 mm 行每行包含三个整数 x,y,z,表示存在一条从点 x 到点 y 的有向边,边长为 z。
输出格式
如果图中存在负权回路,则输出 Yes,否则输出 No。
数据范围
1≤n≤2000,
1≤m≤10000,
图中涉及边长绝对值均不超过 10000。
输入样例:
3 3
1 2 -1
2 3 4
3 1 -4
输出样例:
Yes这个思路就是我们上一题所说的,就直接上代码了
#include<iostream>
#include<algorithm>
#include<cstring>
#include<queue>
using namespace std;
int n,m;
const int N=2010,M=10010;
int dist[N];
int cnt[N];
int h[N],e[M],ne[M],idx,w[M];
bool st[N];
void add(int a,int b,int c){
e[idx]=b;
w[idx]=c;
ne[idx]=h[a];
h[a]=idx++;
}
bool spfa(){
queue<int>q;
for(int i=1;i<=n;i++){
st[i]=true;
q.push(i);
}
while(q.size()){
int t=q.front();
q.pop();
st[t]=false;
for(int i=h[t];i!=-1;i=ne[i]){
int j=e[i];
if(dist[j]>dist[t]+w[i])
{
dist[j]=dist[t]+w[i];
cnt[j]=cnt[t]+1;
if(cnt[j]>=n)
return true;
if(!st[j]){
q.push(j);
st[j]=true;
}
}
}
}
return false;
}
int main(){
scanf("%d%d",&n,&m);
memset(h,-1,sizeof(h));
while(m--){
int a,b,c;
scanf("%d%d%d",&a,&b,&c);
add(a,b,c);
}
if(spfa()) puts("Yes");
else puts("No");
return 0;
}
六:Floyd求最短路
这种方法适用于多源最短路,但是证明和简化代码需要用dp来做支撑,但我还没有掌握dp大法的简化,反而代码不长不难,记起来倒是方便。
题目:
给定一个 n 个点 m 条边的有向图,图中可能存在重边和自环,边权可能为负数。
再给定 k 个询问,每个询问包含两个整数 x 和 y,表示查询从点 x 到点 y 的最短距离,如果路径不存在,则输出 impossible。
数据保证图中不存在负权回路。
输入格式
第一行包含三个整数 n,m,k。
接下来 m 行,每行包含三个整数 x,y,z,表示存在一条从点 x 到点 y 的有向边,边长为 z。
接下来 k 行,每行包含两个整数 x,y,表示询问点 x 到点 y 的最短距离。
输出格式
共 kk 行,每行输出一个整数,表示询问的结果,若询问两点间不存在路径,则输出 impossible。
数据范围
1≤n≤200,
1≤k≤n2
1≤m≤20000,
图中涉及边长绝对值均不超过 10000。
输入样例:
3 3 2
1 2 1
2 3 2
1 3 1
2 1
1 3
输出样例:
impossible
1代码实现
#include<iostream>
#include<algorithm>
using namespace std;
const int N=210,INF=1e9;
int n,m,Q;
int d[N][N];
void floyd(){
for(int k=1;k<=n;k++)
for(int i=1;i<=n;i++)
for(int j=1;j<=n;j++)
d[i][j]=min(d[i][j],d[i][k]+d[k][j]);
}
int main(){
scanf("%d%d%d",&n,&m,&Q);
for(int i=1;i<=n;i++)
for(int j=1;j<=n;j++)
if(i==j)
d[i][j]=0;
else
d[i][j]=INF;
while(m--){
int a,b,w;
scanf("%d%d%d",&a,&b,&w);
d[a][b]=min(d[a][b],w);
}
floyd();
while(Q--){
int a,b;
scanf("%d%d",&a,&b);
if(d[a][b]>INF/2) puts("impossible");
else printf("%d\n",d[a][b]);
}
}
代码量并不多,大家可以背下来
最短路的问题就到这了,这是好久以前学的知识了,最近回过头来一看,搞不明白了,就写了这篇博客帮助自己复习一下,一定要多复习,不然回过头来啥都忘了。能力还很有限,如果有不清楚或错误的地方欢迎大家指出,我继续百度学习 手动狗头狗头















 3525
3525











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









