






二叉树
二叉树的性质
递归性、有序性
完全二叉树:除了最后一层外,其他层的节点数都达到最大,且最后一层的节点都集中在左侧。
满二叉树:满二叉树则是一种特殊的完全二叉树,其中每一层的节点数都达到最大
高度和节点数的关系:对于包含n个节点的二叉树,其高度h至少为log2(n+1),最多为n。
二叉树的遍历
先序遍历序列——根左右,中序遍历序列——左根右,后序遍历序列——左右根,层次遍历:从上到下,从左到右,
哈夫曼树的构建:通常从一组带有权值的叶子结点开始,然后通过特定的算法,不断地将权值最小的两个结点合并为一个新的结点(小的节点在左边),直到只剩下一个结点为止。
已知哈夫曼树,求哈夫曼编码:
- 从哈夫曼树的根节点开始,向左的边表示编码“0”,向右的边表示编码“1”。
- 从根节点开始遍历到某个字符对应的叶子节点,沿途经过的边所对应的编码串联起来,就是该字符的哈夫曼编码。
已知某二叉树的先序遍历序列为ABCDEF、中序遍历序列为BADCFE,则可以确定该二叉树( )
A.是单支树(即非叶子结点都只有一个孩子)
B.高度为4(即结点分布在4层上)
C.根结点的左子树为空
D.根结点的右子树为空
答案:B
根据先序遍历序列(根左右),中序遍历序列(左根右)可推出二叉树模型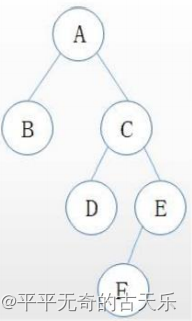
对下面的二叉树进行顺序存储(用数组 MEM 表示),已知结点 A、B、C在 MEM中对应元素的 下标分别为 1、2、3,那么结点 D、E、F 对应的数组元素下标为( )。

A.4、5、6
C. 6、7、8
B. 4、7、10
D. 6、7、14
答案:D
下标即为层次遍历顺序,空的添加虚结点直到最后的F
设某二叉树采用二叉链表表示(即结点的两个指针分别指示左、右孩子)。当该二叉树包含 k个节点时,其二叉链表节点中必有(k+1)个空的孩子指针。
设有二叉排序树(或二叉查找树)建立该二叉树的关键码序列如下图所示不可能是()。
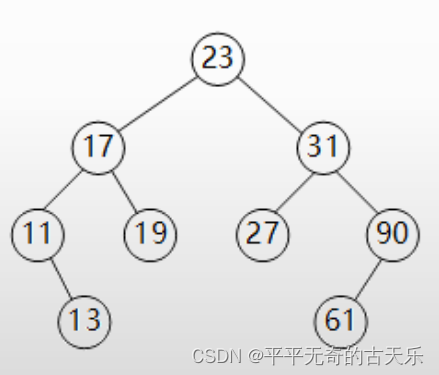
A. 23 31 17 19 11 27 13 90 61 B. 23 17 19 31 27 90 61 11 13
C. 23 17 27 19 31 13 11 90 61 D. 23 31 90 61 27 17 19 11 13
答案:C
从给定的关键码序列中构造二叉排序树
从序列中选择第一0个元素作为根节点。
递归地构建左子树:找到第一个小于根节点的元素。将这个元素作为新的子树根节点,并以这个元素为根节点构建左子树。
递归地构建右子树:找到第一个大于根节点键值的元素。将这个元素作为新的子树根节点,并以这个元素为根节点构建右子树。
可知选项C的二叉查找树并非题目的图
假设某消息中只包含7个字符{a,b,c,d,e,f,g},这7个字符在消息中出现的次数为{5,24,8,17,34,4,13},利用哈夫曼树(最优二叉树)为该消息中的字符构造符合前缀编码要求的不等长编码,
各字符的编码长度分别为()
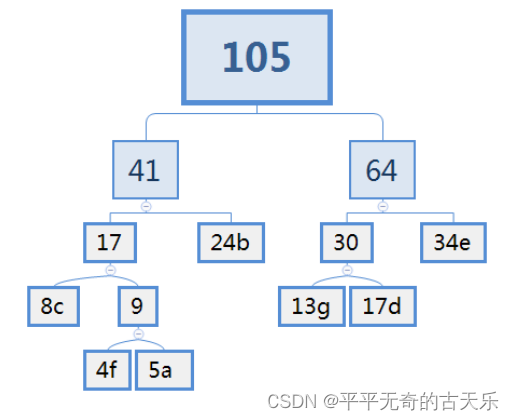
A. a:4,b:2,c:3,d:3,e:2,f:4,g:3
B. a:6 b:2,c:5,d:3,e:1,f:6,g:4
C.a:3,b:3,c:3,d:3,e:3,f:2,g:3
D. a:2,b:6,c:3,d:5,e:6 f:1,g:4
答案:A
看层数即可
图
图的性质
图是由顶点的有穷非空集合和顶点之间边的集合组成,通常表示为G(V,E),G表示一个图,V是图G中顶点的集合,E是图G中边的集合。
图按照边的有无方向分为无向图和有向图。
完全图:指无向图中每对不同的顶点之间都有一条边相连。
连通图:指无向图中任意两个顶点都有连通路径的。
强连通图:有向图中,对于任意两个不同的顶点都含有通路。
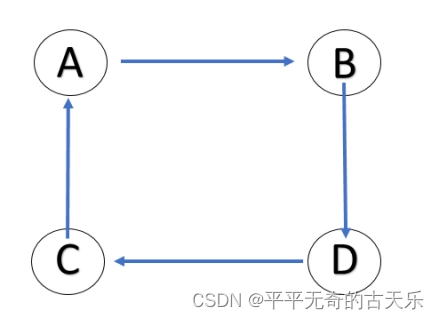
上图为强连通图
图的遍历
广度优先:类似于树的层次遍历
深度优先:类似于树的先序遍历
对于如下所示的有向图,其邻接矩阵是一个( )的矩阵,采用邻接链表存储时顶点2的表结点个数为( )。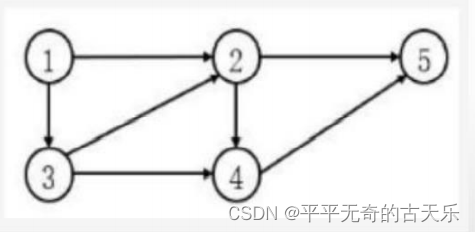
答案:5*5 2
第一空:5个结点
第二空:看弧的数量
图G的邻接矩阵如下图所示(顶点依次表示为v0、v1、v2、v3、v4、v5)G是( )。对G进行广度优先遍历(从v0开始),可能的遍历序列为()。

A.无向图 B.有向图 C.完全图 D.强连通图
A.v0、v1、v2、v3、v4、v5
B.v0、v2、v4、v5、v1、v3
C.v0、v1、v3、v5、v2、v4
D.v0、v2、v4、v3、v5、v1
答案:B A
解析:由题目可推出
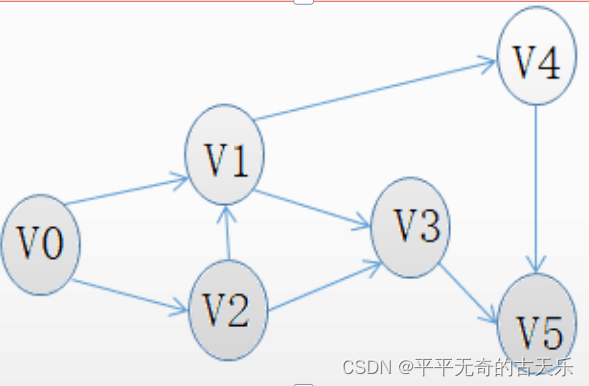
广度优先类似于树的层次遍历,v0后应该是v1、v2。
排序算法
直接插入排序:依次从后向前比较并插入。
希尔排序:分割成为若干子序列分别进行直接插入排序,待整个序列中的记录“基本有序”时,再进行依次直接插入排序。
简单选择排序:在未排序序列中找到最小(或最大)元素,存放到排序序列的起始位置,重复
冒泡排序:依次比较交换两个元素,直不再需要交换·。
归并排序:使用分治法策略。将已有序的子序列合并,得到完全有序 的序列;即先使每个子序列有序,再使子序列段间有序。
快速排序:使用分治法策略。挑出一个元素,称为“基准”,比基准值小的摆放在基准前面,比基准值大的摆在基准的后面。然后重新选择基准,直到所有子序列只剩下一个元素
堆排序:是指利用堆这种数据结构所设计的一种排序算法。堆积是一个近似完全二叉树的结构,并同时满足堆积的性质:即子结点的键值或索引总是小于(或者大于)它的父节点。

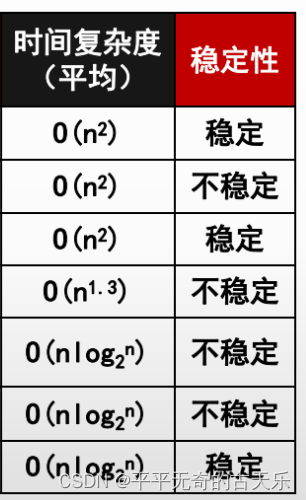
稳定性:若两个记录A 和B 的关键字值相等, 但排序后A 、B 的先后次序保持不变, 则称这种排序算法是稳定的

答案:A A
解析:由基本有序得知计算“最好情况”下的时间复杂度。
查找算法
顺序查找——从尾到头比较插入
优点:简单,适用面广,对表结构没有要求
缺点:效率低,平均查找长度长
平均查找长度:(n+1)/2
时间复杂度(n 是数据集合的大小):O(n)
二分查找——查找时,算法都会将数据集合分成两半,并在包含目标元素的一半中继续查找
条件:有序,采用顺序存储结构
优点:效率高、平均查找长度短
缺点:要求有序,采用顺序存储结构
平均查找长度:log2(n + 1)-1
时间复杂度:O(log n)
哈希查找
优点:效率高、内存使用合理
缺点:哈希函数设计不当导致的哈希冲突会降低效率、需要额外的空间
时间复杂度:
- 平均情况:O(1)(理想情况,取决于哈希函数和冲突解决方法)
- 最坏情况:O(n)(当哈希表完全冲突时)
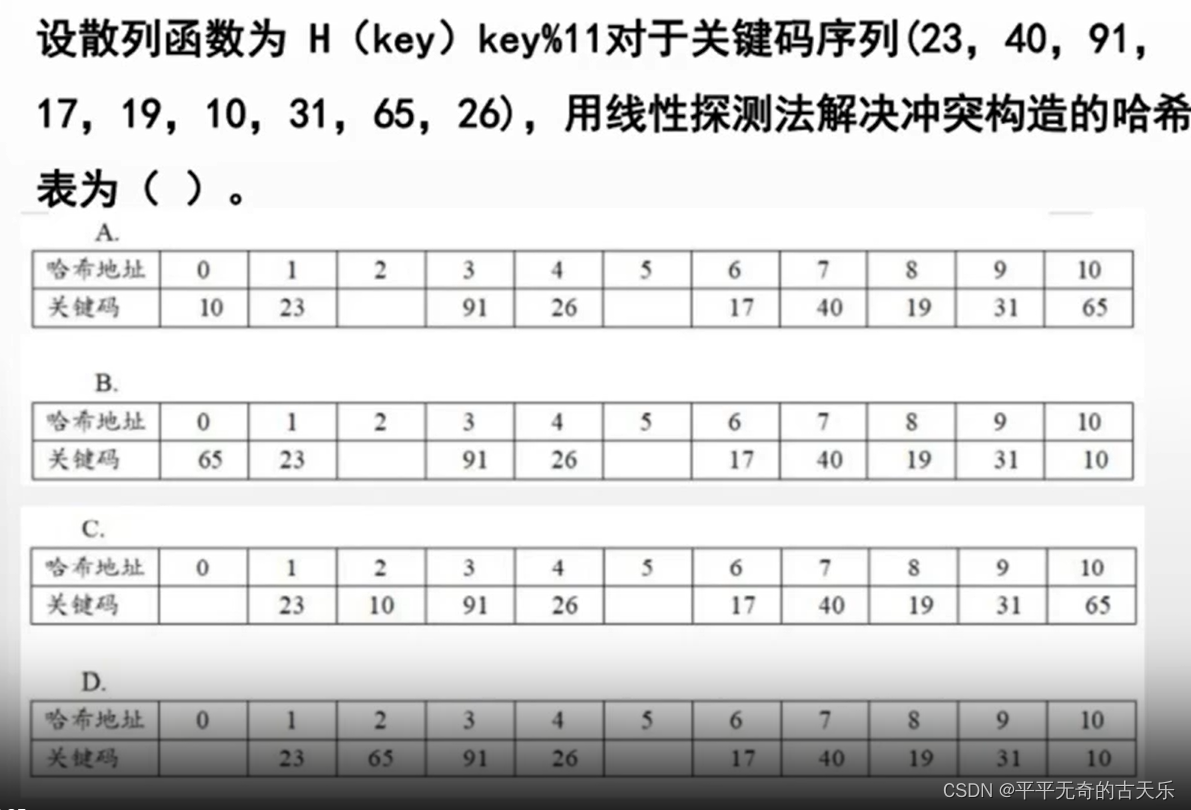
答案:B
解析:冲突时采用线性探测法,向下寻找空的哈希值















 1714
1714











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









