






爬虫实例介绍
由于时间关系,淘宝网站已经升级,需要在慕课原代码中的头部添加cookies字段才能访问淘宝网站,爬取商品信息
实例编写
步骤
获取并解析网络源代码
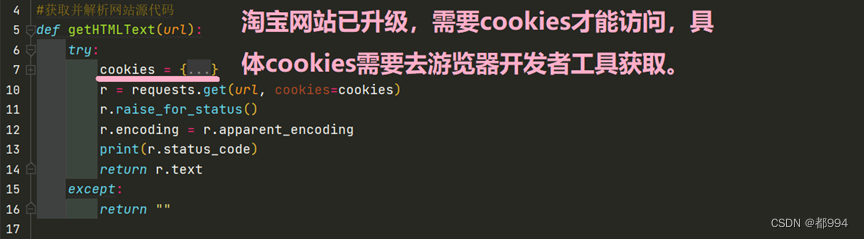
cookies

解析网页代码,提取信息

将提取到的信息输出
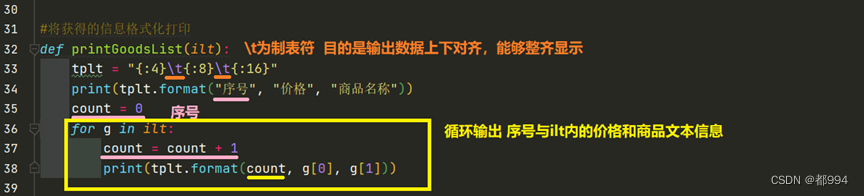
主函数

调用主函数

代码执行结果结果
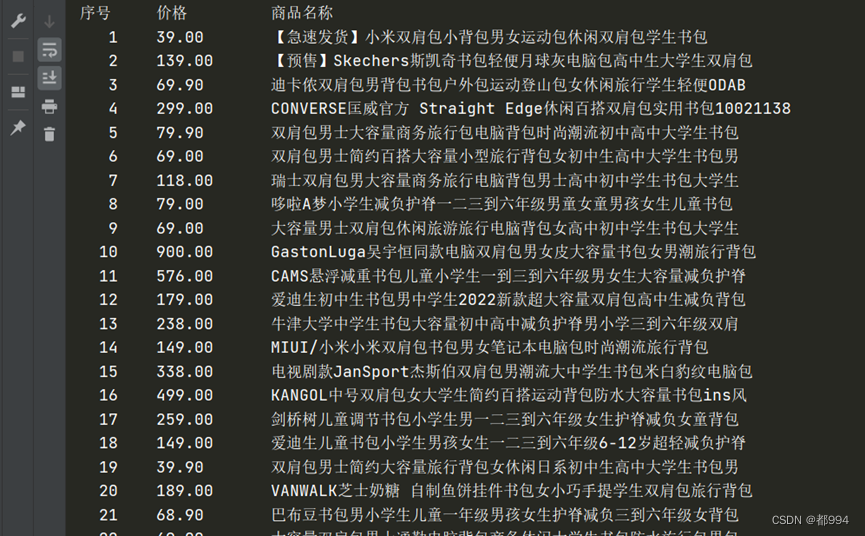
代码
import requests
import re
cookies = {
'cookie':'这里自己去游览器赋值cookies'
}
def getHTMLText(url): #获取并解析网站源代码
try:
r = requests.get(url, cookies=cookies)
r.raise_for_status()
r.encoding = r.apparent_encoding
print(r.status_code)
return r.text
except:
return ""
def parsePage(ilt, html): #对每一个获得页面进行解析 然后获取指定信息,存到ilt变量中
try:
#正则表达式匹配的对象例子 "view_price " : " 39 .00"
plt = re.findall(r'\"view_price\"\:\"[\d\.]*\"', html)
#正则表达式匹配的对象例子 "raw_title " : "【急速发货】小米双肩包小背包男女运动包休闲双肩包学生书包"
tlt = re.findall(r'\"raw_title\"\:\".*?\"', html) #
print(plt)#价格
print(tlt)#文本
for i in range(len(plt)):
price = eval(plt[i].split(':')[1]) #eval函数能够将获得的字符串的最外层的单引号或者双引号去掉
title = eval(tlt[i].split(':')[1]) #split(':')[1]表示以:号为标志获取索引为1的字符串 raw_title的索引为0,后面文本部分索引为1
ilt.append([price, title]) #将获取到的价格和商品文本信息两个合成一个小列表再添加到ilt列表中。(列表中有很多小列表)
except:
print("")
def printGoodsList(ilt):
tplt = "{:4}\t{:8}\t{:16}" #\t为制表符 目的是输出数据上下对齐,能够整齐显示
print(tplt.format("序号", "价格", "商品名称"))
count = 0
for g in ilt: #循环输出ilt内的价格和商品文本信息
count = count + 1
print(tplt.format(count, g[0], g[1]))
#主函数
def main():
goods = '书包' #搜索关键字:书包
depth = 3 #爬取三页
start_url = 'https://s.taobao.com/search?q=' + goods #调用淘宝搜索接口
infoList = [] #对整个输出结果定义一个变量 infolist
for i in range(depth): #循环depth(3)次,爬取depth(3)页
try:
url = start_url + '&s=' + str(44 * i) #淘宝每页有44个商品,通过改变‘&s=’”xx“来跳转淘宝网页
html = getHTMLText(url) #r.txt 调用定制方法来获取网页代码r.txt
parsePage(infoList, html)
except:
continue
printGoodsList(infoList)
#调用主函数
main()以上内容参考https://blog.csdn.net/weixin_43173093/article/details/87716555/















 3360
3360











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









