







往期文章
目录
前言
还没看过前一篇的尽可能去看前一篇文章 有基础的记住不要一来就打开开发者工具就好
一、为什么不能直接打开开发者工具
① 误判开发者工具中的Elements(元素)就是源代码
因为我们发出请求的第一个请求到的文件就是网页的源代码文件(查看源代码快敏键 ctrl + U)
② 为什么源代码和Elements显示的不一样呢?
因为大部分网页是动态的,比如 股票市场 数据是实时更新的 那么我们不可预知,也可能写很多个网页去一个一个替换,用户还要刷新才能得到数据,这是不可能的。
③ 那怎么把实时数据放在网页上呢?
通过JavaScript把接口(api)数据放到html显示的内容中去
④ api(接口)是什么东西?
接口可以类比于银行前台小姐,如果你要取钱,你可以跟小姐说明并且出示你的身份证明,她去给你取出来交给你。这就是接口做的事,你把你的cookie或者请求头给它,它判断你是否能请求到这些数据,然后再把数据交给你。
-
那么说到这了,这不就好办了嘛,我们只要找到接口,然后发起请求,收到数据,再进行整理,可视化做出你想要的东西。
-
二、如何找到api(接口)
emmm 这个找个网站给大家当例子,不是恶意爬取
我就找一个网上应该没有人爬过的国家统计局官网 (放心安全的很 你们也可以自己去搜索国家统计局一样的,点击高级,然后继续访问就可以进入了)
-
进去的时候可以看到这些数据

ok 老方法ctrl+u 看看源代码 可以看出来数据是不在源代码中的 源代码中有很多的JavaScript语句,我们就可以判断这个网站是一个动态的网站

现在我们再打开我们的开发者工具(f12或者fn+f12) 然后在search框中输入居民消费价格指数这句话

你就会发现哦哦哦哦哦 有个文件里面有这么个数据 ok恭喜你找到了api接口

然后点击进入找到网址 这里解释一下network(开发者工具)里面的一些字段含义:
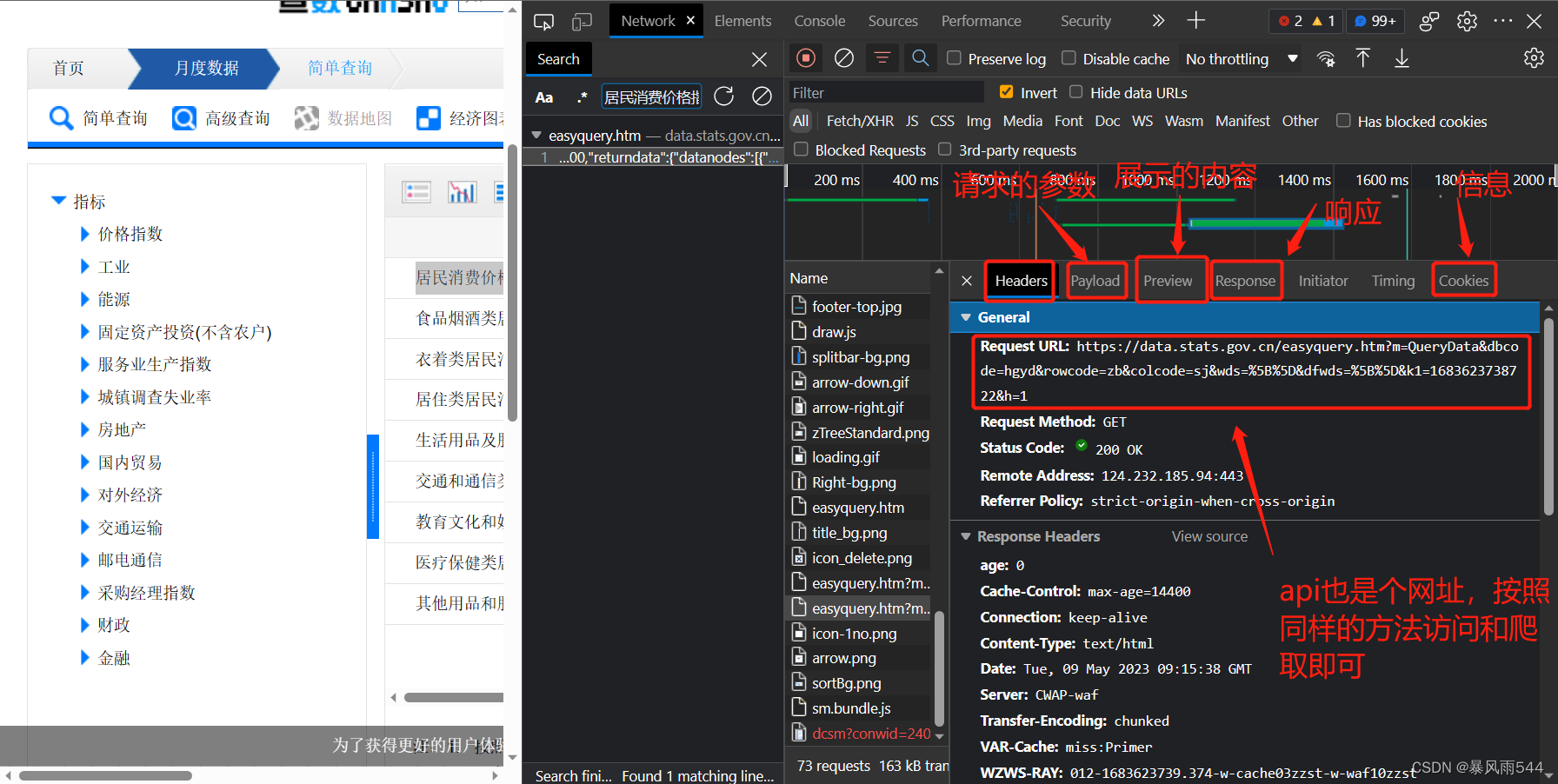
最后先大胆尝试 有不懂的可以私信问我(24h内回)
三、成果展示
把数据放入exel表内

-
然后制作好几副简单的柱状图

ok 这是很久之前的成果了 不是很注重可视化这种东西 不要介意
-
四、完整代码
这个代码做了个异步 其实还好不是很需要 可以看看这串代码然后照着思路打还是比较简单的
import json
import pandas as pd
import matplotlib.pyplot as plt
import asyncio
import aiohttp
import aiofiles
datatool = []
new_data = []
index = []
dname = []
# from functools import wraps #下面和这个都是为了重写close
# from asyncio.proactor_events import _ProactorBasePipeTransport
# def silence_event_loop_closed(func):#重写close
# @wraps(func)
# def wrapper(self, *args, **kwargs):
# try:
# return func(self, *args, **kwargs)
# except RuntimeError as e:
# if str(e) != 'Event loop is closed':
# raise
# return wrapper
#
# _ProactorBasePipeTransport.__del__ = silence_event_loop_closed(_ProactorBasePipeTransport.__del__)###重写close
async def get_url():#获取url
url = "https://data.stats.gov.cn/easyquery.htm?m=QueryData&dbcode=hgyd&rowcode=zb&colcode=sj&wds=%5B%5D&dfwds=%5B%7B%22wdcode%22%3A%22sj%22%2C%22valuecode%22%3A%22LAST36%22%7D%5D&k1=1657617147842"
urln = "https://data.stats.gov.cn/easyquery.htm?m=QueryData&dbcode=hgyd&rowcode=zb&colcode=sj&wds=%5B%5D&dfwds=%5B%7B%22wdcode%22%3A%22sj%22%2C%22valuecode%22%3A%22LAST36%22%7D%5D&k1=1657597568517"
await get_double(url,urln)#因为太多io操作如果不用多线程要几分钟
async def get_double(url,urln):#获取源代码
tasks = []
headers = {
"User-Agent": "Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.5060.114 Mobile Safari/537.36 Edg/103.0.1264.49",
"X-Requested-With": "XMLHttpRequest",
"Cookie": "JSESSIONID=SwzsdHSGW6TNLf8RIfCn956tULPRHzkoUL74rrs6_qB4E1Zii07W!1558993049; u=1",
"Host": "data.stats.gov.cn",
"Referer": "https://data.stats.gov.cn/easyquery.htm?cn=A01",
"verify":"False"
}
async with aiohttp.ClientSession(connector=aiohttp.TCPConnector(limit=64,verify_ssl=False)) as session:#因为访问要ssl安全验证,把它去掉,也可以直接在TCPConnector里边修改把verify = Ture
async with session.request('get',url,params=headers) as re:
resp = await re.text(encoding="utf-8")#获取encoding = 'utf'的源代码
async with aiohttp.ClientSession(connector=aiohttp.TCPConnector(limit=64,verify_ssl=False)) as session2:
async with session2.request('get',urln,params=headers) as re2:
respn = await re2.text(encoding="utf-8")
respn_json = json.loads(respn)#转换为字典,python语言
resp_json = json.loads(resp)
tasks.append(asyncio.create_task(find_data(resp_json,respn_json)))#调用find_data
await asyncio.wait(tasks)#创建任务
async def find_data(resp,respn):
tasks = []
for i in range(1,len(resp['returndata']['datanodes'])):
data = resp['returndata']['datanodes'][i]['data']['strdata']#找到基本数据
datatool.append(data)#添加到空列表内
print(len(datatool))
new_data.append(datatool[0:35])
new_data.append(datatool[36:71])
new_data.append(datatool[72:107])
new_data.append(datatool[108:143])
new_data.append(datatool[144:179])
new_data.append(datatool[180:215])
new_data.append(datatool[216:251])
new_data.append(datatool[252:287])
new_data.append(datatool[288:323])#无脑整理一些数据
for n in range(35):
time = respn['returndata']['wdnodes'][1]['nodes'][n]['cname']#获取时间数据
index.append(time)
for item in range(9):
dname.append(resp['returndata']['wdnodes'][0]['nodes'][item]['cname'])#获取标题
tasks.append(asyncio.create_task(save_data(index,dname,new_data)))
await asyncio.wait(tasks)#调用save_data
async def save_data(index,dname,new_data):
df = pd.DataFrame(columns=index,index=dname,data=new_data)#做一个表,标题,横纵坐标数据
pd.set_option('display.max_rows',None)
pd.set_option('display.max_columns',None)#把省略部分显示出来
pd.set_option("display.unicode.ambiguous_as_wide",True)
pd.set_option("display.unicode.east_asian_width",True)#对齐
pd.set_option('display.width',1000)
print(df)
df.to_excel("消费数据.xls")
async with aiofiles.open('消费数据','w',encoding='utf-8') as f:
await f.write(str(df))#保存一下数据
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False##中文显示问题
for page in range(9):#用循环做多个表
a = page
b = a+35
plt.title(dname[page])
plt.bar(index, datatool[a:b])
plt.tick_params(labelsize=7)
plt.xticks(rotation=60)
plt.show()
a = b+1
print('over!')#显示程序成功完成
asyncio.run(get_url())#跑起来















 388
388











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











