







一、手动获取cookie并自动登录
一.找json地址
1.进入谷歌浏览器点击检查,Network,Fetch/XHR,然后刷新,重新获取数据
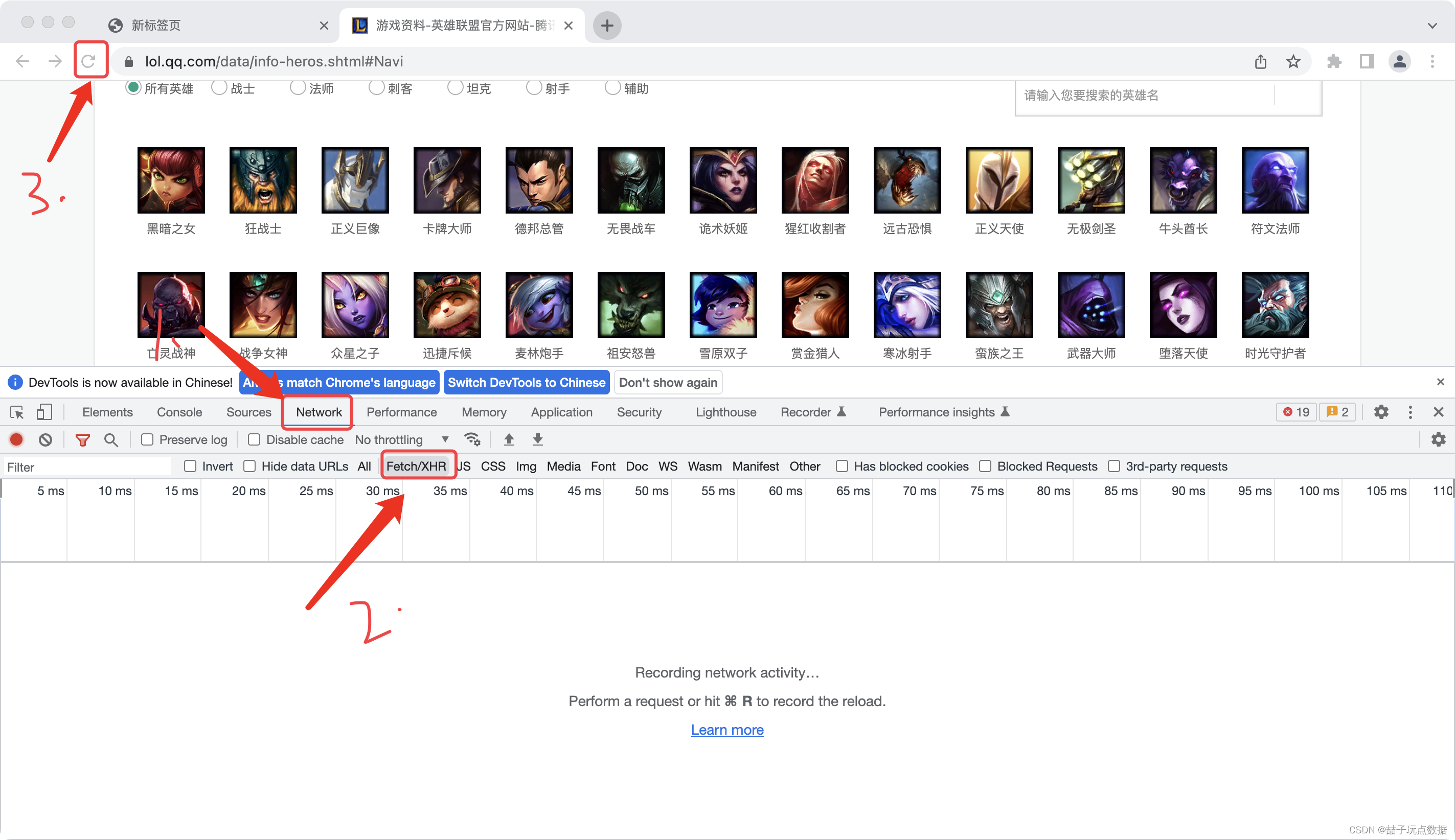
2.在name里面查找需要的数据
3.选择数据:
1)可以通过name判断
2)可以通过size文件大小判断
3)最后点击数据的preview看看是不是自己想要的数据
4.选择成功后,去到他的Headers获取Request URL
二、进入pycharm解析数据
import requests
headers = {
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/106.0.0.0 Safari/537.36'
}
response = requests.get('https://game.gtimg.cn/images/lol/act/img/js/heroList/hero_list.js')
print(response.json())
如果结果显示是你需要的数据,那么选择成功

cookie获取
检查-network-all-name处网页-headers-cookie

二、自动登录
这里用知乎做介绍,即自动登录知乎
因为我们知乎的内容需要登录,账户,而这里的代码可以实现自动登录
import requests
headers = {
'cookie': '_zap=b1124762-828e-435d-b04c-7c59a1786742; _xsrf=774cb199-0e1c-4b28-bb60-8c62b565c8bc; d_c0=AUCYBu3vvBWPTm-arz42Iw6N9McyUzXcK4c=|1666236614; __snaker__id=h9XPzR2HWZU7g32U; gdxidpyhxdE=0E5%2Fpw5xVQk4I8AjL4%5Czi82P 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 448
448











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











