






前几天在做使用Paddle训练模型转换为RK3588所需的rknn模型的一些工作,里面有一些坑,这里进行一些总结,从训练paddle模型开始 。
一.数据集
paddle有自己所需的数据集格式,当你收集到一个数据集时,通常会有Annotations文件和JPEGImages,是就是标签文件和图像文件(这个是我整理好的适用于yolov5训练的文件夹目录,一般刚拿到的数据集只会有Annotations文件和JPEGImages)

Paddle需要的格式是这样的(该文件内容包含所必须文件目录,放在一个文件夹内是因为转换时更方便)
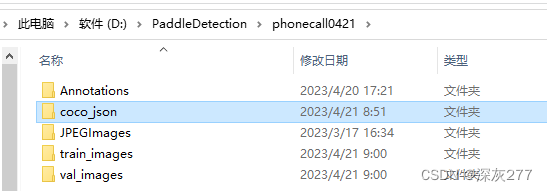
首先转换出coco_json,其中包含,如下图
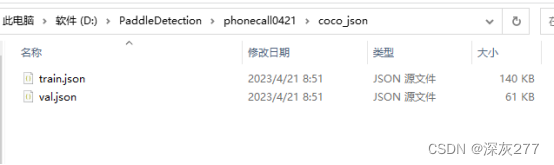
转换时我使用的是自己的py文件
# coding:utf-8
# pip install lxml
import os
import glob
import json
import shutil
import numpy as np
import xml.etree.ElementTree as ET
START_BOUNDING_BOX_ID = 1
def get(root, name):
return root.findall(name)
def get_and_check(root, name, length):
vars = root.findall(name)
# print(root.tag)
if len(vars) == 0:
print(root)
raise NotImplementedError('Can not find %s in %s.' % (name, root.tag))
if length > 0 and len(vars) != length:
raise NotImplementedError('The size of %s is supposed to be %d, but is %d.' % (name, length, len(vars)))
if length == 1:
vars = vars[0]
return vars
def convert(xml_list, json_file):
json_dict = {"info": ['none'], "license": ['none'], "images": [], "annotations": [], "categories": []}
categories = pre_define_categories.copy()
bnd_id = START_BOUNDING_BOX_ID
all_categories = {}
num_count = 1
for index, line in enumerate(xml_list):
# print("Processing %s"%(line))
xml_f = line
tree = ET.parse(xml_f)
root = tree.getroot()
filename = os.path.basename(xml_f)[:-4] + ".jpg"
# print(filename)
# image_id = int(filename.split('.')[0][-8:])
# print('filename is {}'.format(image_id))
image_id =num_count
size = get_and_check(root, 'size', 1)
width = int(get_and_check(size, 'width', 1).text)
height = int(get_and_check(size, 'height', 1).text)
image = {'file_name': filename, 'height': height, 'width': width, 'id': image_id}
json_dict['images'].append(image)
num_count+=1
## Cruuently we do not support segmentation
# segmented = get_and_check(root, 'segmented', 1).text
# assert segmented == '0'
for obj in get(root, 'object'):
category = get_and_check(obj, 'name', 1).text
if category in all_categories:
all_categories[category] += 1
else:
all_categories[category] = 1
if category not in categories:
if only_care_pre_define_categories:
continue
new_id = len(categories) + 1
print(
"[warning] category '{}' not in 'pre_define_categories'({}), create new id: {} automatically".format(
category, pre_define_categories, new_id))
categories[category] = new_id
category_id = categories[category]
bndbox = get_and_check(obj, 'bndbox', 1)
xmin = int(float(get_and_check(bndbox, 'xmin', 1).text))
ymin = int(float(get_and_check(bndbox, 'ymin', 1).text))
xmax = int(float(get_and_check(bndbox, 'xmax', 1).text))
ymax = int(float(get_and_check(bndbox, 'ymax', 1).text))
assert (xmax > xmin), "xmax <= xmin, {}".format(line)
assert (ymax > ymin), "ymax <= ymin, {}".format(line)
o_width = abs(xmax - xmin)
o_height = abs(ymax - ymin)
ann = {'area': o_width * o_height, 'iscrowd': 0, 'image_id':
image_id, 'bbox': [xmin, ymin, o_width, o_height],
'category_id': category_id, 'id': bnd_id, 'ignore': 0,
'segmentation': []}
json_dict['annotations'].append(ann)
bnd_id = bnd_id + 1
for cate, cid in categories.items():
cat = {'supercategory': 'none', 'id': cid, 'name': cate}
json_dict['categories'].append(cat)
json_fp = open(json_file, 'w')
json_str = json.dumps(json_dict)
json_fp.write(json_str)
json_fp.close()
print("------------create {} done--------------".format(json_file))
print("find {} categories: {} -->>> your pre_define_categories {}: {}".format(len(all_categories),
all_categories.keys(),
len(pre_define_categories),
pre_define_categories.keys()))
print("category: id --> {}".format(categories))
print(categories.keys())
print(categories.values())
if __name__ == '__main__':
# xml标注文件夹
xml_dir = r'D:\PaddleDetection\phonecall0421\Annotations/'
# 训练数据的josn文件
save_json_train = r'D:\PaddleDetection\phonecall0421\coco_json/train.json'
# 验证数据的josn文件
save_json_val = r'D:\PaddleDetection\phonecall0421\coco_json/val.json'
# 类别,这里只有dog一个类别,如果是多个类别,往classes中添加类别名字即可,比如['dog', 'person', 'cat']
classes = ['call', 'no_phone', 'phone']
pre_define_categories = {}
for i, cls in enumerate(classes):
pre_define_categories[cls] = i + 1
only_care_pre_define_categories = True
# 训练数据集比例
train_ratio = 0.7
print('xml_dir is {}'.format(xml_dir))
xml_list = glob.glob(xml_dir + "/*.xml")
xml_list = np.sort(xml_list)
# print('xml_list is {}'.format(xml_list))
np.random.seed(100)
np.random.shuffle(xml_list)
train_num = int(len(xml_list) * train_ratio)
print('训练样本数目是 {}'.format(train_num))
print('测试样本数目是 {}'.format(len(xml_list) - train_num))
xml_list_train = xml_list[:train_num]
xml_list_val = xml_list[train_num:]
# 对训练数据集对应的xml进行coco转换
convert(xml_list_train, save_json_train)
# 对验证数据集的xml进行coco转换
convert(xml_list_val, save_json_val)
使用时注意修改xml_dir,save_json_train,save_json_val,classes。
生成json之后,需要根据生成的json文件分别生成相应的imges,也要注意修改dir的路径
import numpy as np
import os
import glob
from PIL import Image
jpg_dir = r"D:\PaddleDetection\phonecall0421\JPEGImages/"
train_dir = r"D:\PaddleDetection\phonecall0421\train_images/"
val_dir = r"D:\PaddleDetection\phonecall0421\val_images/"
train_ratio =0.7
jpg_list = glob.glob(jpg_dir+"/*.jpg")
jpg_list = np.sort(jpg_list)
np.random.seed(100)
np.random.shuffle(jpg_list)
train_num = int(len(jpg_list)*train_ratio)
index =1
for jpg in jpg_list:
# out_name = jpg.split('.')[0][-32:]
file_name = os.path.split(jpg)[1]
out_name = file_name.split('.')[0]
img = Image.open(jpg)
img = img.convert("RGB")
if index<=train_num:
save_path = train_dir+out_name+".jpg"
img.save(save_path)
index+=1
else:
save_path = val_dir+out_name+".jpg"
img.save(save_path)
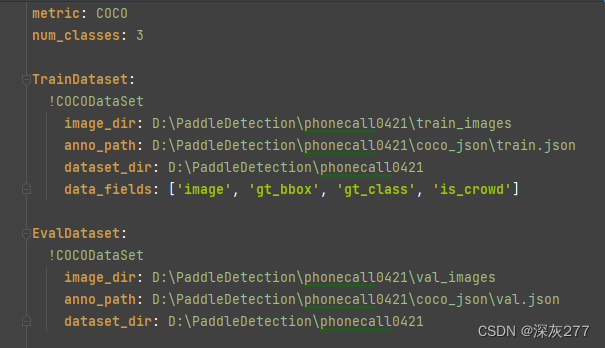
index+=1生成数据之后,更改picodet_s_416_coco_lcnet.yml,文件内容
![]()
最简单的只需要更改这个路径为你自己的路径(其中也可以改训练回合数epoch,与训练模型等),而这个路径文件下的配置是刚才数据集的相应配置。
然后找到tools/train.py,更改训练配置为(如下图)即可
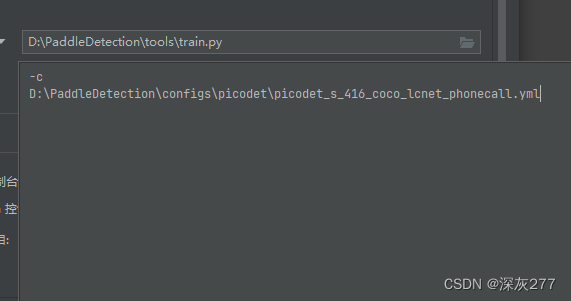
数据集和配置结束
二.paddle模型导出
假设你的训练环境正确,可以正常训练,等到训练结束后你会找到
![]()

使用Paddledetction里的export_model.py,将模型导出,配置如下图
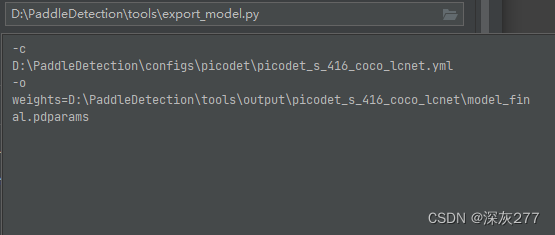
路径什么的可以自己设置,模型导出后你会得到如下图的文件
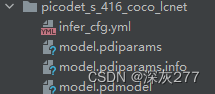
得到这个文件之后,我们需要使用它进行转换onnx和onnx的shape
代码参考FastDeploy快速部署,有参考价值,并不是完全正确,有很多坑,我只说正确的部分。
按照教程中在ubuntu主机上安装conda环境,安装FastDeploy,rknn_toolkits等
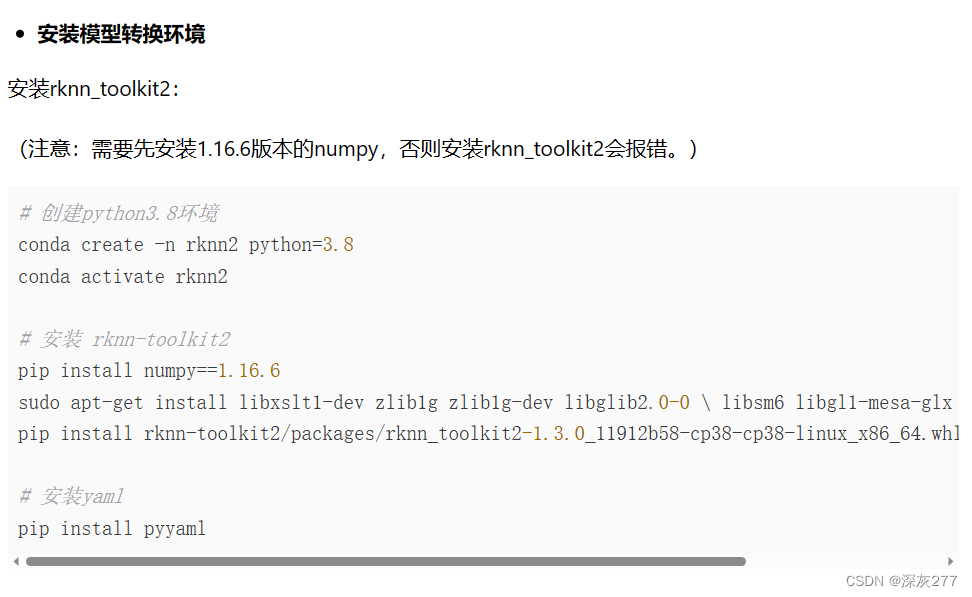
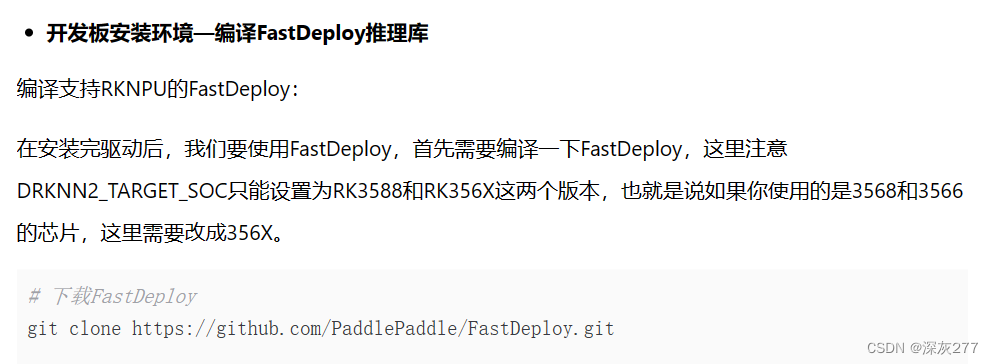
在转换picodet模型时,需要切换到相应目录,我这里是
![]()
# 静态图转ONNX模型
paddle2onnx --model_dir picodet_s_416_coco_lcnet \
--model_filename model.pdmodel \
--params_filename model.pdiparams \
--save_file picodet_s_416_coco_lcnet/picodet_s_416_coco_lcnet.onnx \
--enable_dev_version True
python -m paddle2onnx.optimize \
--input_model picodet_s_416_coco_lcnet/picodet_s_416_coco_lcnet.onnx \
--output_model picodet_s_416_coco_lcnet/picodet_s_416_coco_lcnet.onnx \
--input_shape_dict "{'image':[1,3,416,416]}"修改这些路径到你为你刚生成的模型的路径,--input_shape_dict不用改
然后会在你的设置路径下生成onnx文件
值得注意的是,你需要使用可视化工具可视化你的模型netron,然后找到图中两个节点,查看它们的outputs_nodes,换成自己的
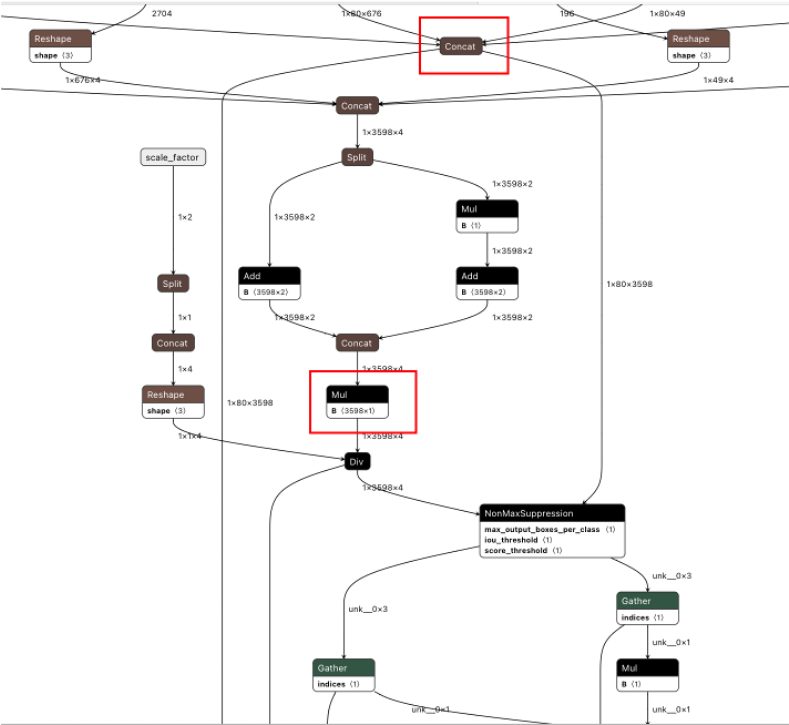
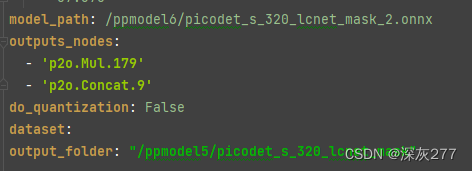
之后切换到FastDeploy根目录下执行,路径都是你自己的
python tools/rknpu2/export.py \
--config_path tools/rknpu2/config/RK3588/picodet_s_416_coco_lcnet.yaml
--target_platform rk3588成了!















 2029
2029











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









