










简介
RK3588是瑞芯微(Rockchip)公司推出的一款高性能、低功耗的集成电路芯片。它采用了先进的28纳米工艺技术,并配备了八核心的ARM Cortex-A76和Cortex-A55处理器,以及ARM Mali-G76 GPU。该芯片支持多种接口和功能,适用于广泛的应用领域。
本篇为yolov5部署在RK3588的教程。
一、yolov5训练数据
请选择v5.0版本:Releases · ultralytics/yolov5 (github.com)
训练方法请按照官方的READEME文件进行。
转换前将model/yolo.py的 Detect 类下的
def forward(self, x):
z = [] # inference output
for i in range(self.nl):
if os.getenv('RKNN_model_hack', '0') != '0':
z.append(torch.sigmoid(self.m[i](x[i])))
continue
x[i] = self.m[i](x[i]) # conv
bs, _, ny, nx = x[i].shape # x(bs,255,20,20) to x(bs,3,20,20,85)
x[i] = x[i].view(bs, self.na, self.no, ny, nx).permute(0, 1, 3, 4, 2).contiguous()
if not self.training: # inference
if self.onnx_dynamic or self.grid[i].shape[2:4] != x[i].shape[2:4]:
self.grid[i], self.anchor_grid[i] = self._make_grid(nx, ny, i)
y = x[i].sigmoid()
if self.inplace:
y[..., 0:2] = (y[..., 0:2] * 2 + self.grid[i]) * self.stride[i] # xy
y[..., 2:4] = (y[..., 2:4] * 2) ** 2 * self.anchor_grid[i] # wh
else: # for YOLOv5 on AWS Inferentia https://github.com/ultralytics/yolov5/pull/2953
xy, wh, conf = y.split((2, 2, self.nc + 1), 4) # y.tensor_split((2, 4, 5), 4) # torch 1.8.0
xy = (xy * 2 + self.grid[i]) * self.stride[i] # xy
wh = (wh * 2) ** 2 * self.anchor_grid[i] # wh
y = torch.cat((xy, wh, conf), 4)
z.append(y.view(bs, -1, self.no))
if os.getenv('RKNN_model_hack', '0') != '0':
return z
return x if self.training else (torch.cat(z, 1),) if self.export else (torch.cat(z, 1), x)
修改为:
def forward(self, x):
z = []
for i in range(self.nl):
x[i] = self.m[i](x[i])
return x出现乱框的现象,可以修改为下面的情况:
def forward(self, x):
z = []
for i in range(self.nl):
x[i] = torch.sigmoid(self.m[i](x[i]))
return x但在训练阶段请勿修改。
接着将训练好的best.pt放在工程文件夹下,使用yolov5工程中的export.py将其转换为onnx模型。
python export.py --weights best.pt二、下载RKNN-Toolkit2
1、下面的请在 Ubuntu下进行,创建一个Python环境
conda create -n rknn152 python=3.8激活环境rknn152
conda activate rknn152拉取rockchip-linux/rknn-toolkit2 at v1.5.2 (github.com)仓库。我是直接下载的1.5.2版本的zip包。
git clone git@github.com:rockchip-linux/rknn-toolkit2.git2、安装依赖(requirements_cp38-1.5.2.txt,在rknn-toolkit2/doc目录下)
pip install -r /home/yuzhou/rknn15/rknn-toolkit2-1.5.2/doc/requirements_cp38-1.5.2.txt -i https://pypi.tuna.tsinghua.edu.cn/simple安装rknn-toolkit2,位置在packages文件夹下面,请选择合适的版本。
pip install /home/yuzhou/rknn15/rknn-toolkit2-1.5.2/packages/rknn_toolkit2-1.5.2+b642f30c-cp38-cp38-linux_x86_64.whl3、开发环境与板子连接
sudo apt-get install adb使用USB-typeC线连接到板子的TypeC0接口,PC端识别到虚拟机中。
在开发环境中检查是否连接成功
adb devices如果连接成功会返回板子的设备ID,如下:
List of devices attached
* daemon not running; starting now at tcp:5037
* daemon started successfully
75370ea69f64098d device
三、onnx转rknn模型
在rknn-toolkit2工程文件夹中浏览至./examples/onnx/yolov5,将我们在yolov5工程中转换得到的best.onnx复制到该文件夹下,需要修改该文件夹下的test.py中的内容。
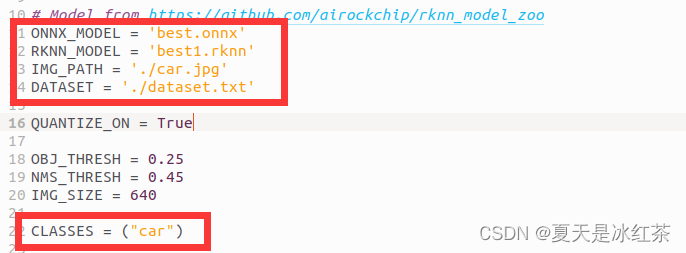
- ONNX_MODEL:模型名;
- RKNN_MODEL:转换后的rknn模型名;
- IMG_PATH:推理的图片路径;
- DATASET:需要打开txt文件修改,改为IMG_PATH的图片名
- CLASSES:修改为自己数据集的类别
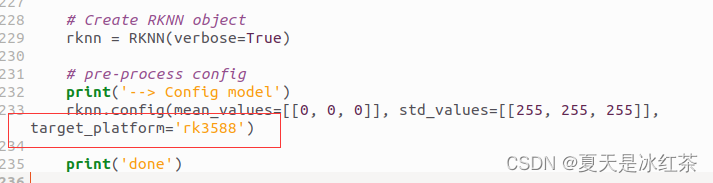
添加target_platform='rk3588'。
进入此目录,运行:
python test.py
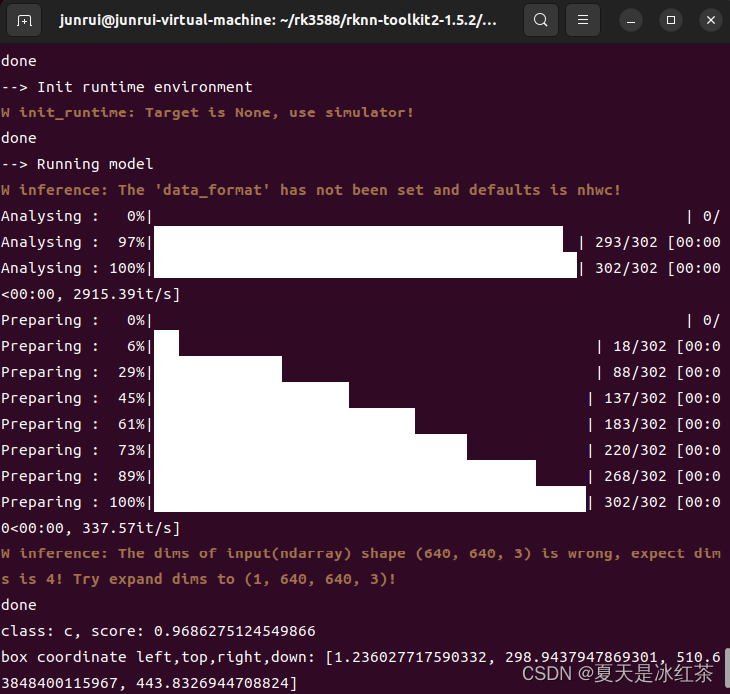
如上图如此,说明没有问题,并且在该目录下会生成一个推理图片,以及转换好的rknn模型。
四、下载NPU工程
git clone https://github.com/rockchip-linux/rknpu2将rknn_server和rknn库发送到板子上
adb push /home/yuzhou/rknn15/rknpu2-1.5.0/runtime/RK3588/Linux/rknn_server/aarch64/usr/bin/rknn_server /usr/bin/adb push /home/yuzhou/rknn15/rknpu2-1.5.0/runtime/RK3588/Linux/librknn_api/aarch64/librknnrt.so /usr/bin/adb push /home/yuzhou/rknn15/rknpu2-1.5.0/runtime/RK3588/Linux/librknn_api/aarch64/librknn_api.so /usr/bin/在板子上运行rknn_server服务
adb shell
root@ok3588:/# chmod +x /usr/bin/rknn_server
root@ok3588:/# rknn_server &
[1] 6932
root@ok3588:/# start rknn server, version:1.5.0 (17e11b1 build: 2023-05-18 21:43:39)
I NPUTransfer: Starting NPU Transfer Server, Transfer version 2.1.0 (b5861e7@2020-11-23T11:50:51)
在开发环境中检测rknn_server是否运行成功
(base) yuzhou@yuzhou-HP:~$ adb shell
root@ok3588:/# pgrep rknn_server
6932
有返回进程id说明运行成功。
git clone https://github.com/rockchip-linux/rknpu2.git
五、部署在rk3588上
在路径 ../rknpu2/examples/rknn_yolov5_demo中
修改include文件中的头文件postprocess.h
#define OBJ_CLASS_NUM 80 #这里的数字修改为数据集的类的个数
修改model目录下的coco_80_labels_list.txt文件,改为自己的类并保存
car将转换后的rknn文件放在model/RK3588目录下
在model目录下放入需要推理的图片
cd /home/yuzhou/rknn15/rknpu2-1.5.0/examples/rknn_yolov5_demo编译,运行shell
bash ./build-linux_RK3588.sh
成功后生成install目录,将文件推到我们的板子上面
adb push /home/yuzhou/rknn15/rknpu2-1.5.0/examples/rknn_yolov5_demo /mydatas/与rk3588进行交互
adb shell
进入我们传入文件的目录下
cd /mydatas/rknn_yolov5_demo_Linux使用npu加速推理
./rknn_yolov5_demo ./model/RK3588/best5s.rknn ./model/6.jpg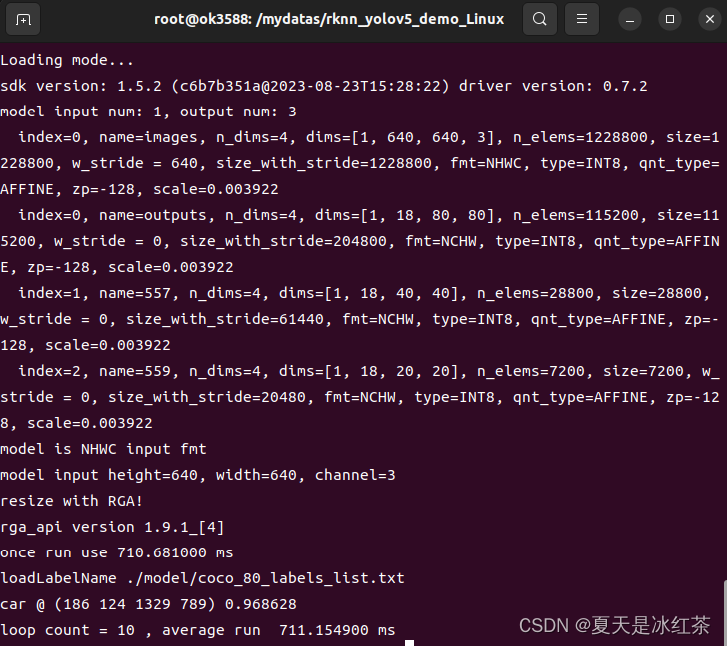
将生成的图片拉取到本地来
adb pull /mydatas/rknn_yolov5_demo_Linux/6out.jpg /home/yuzhou/rknn-toolkit2/examples/onnx/yolov5_rk3588_demo/test六、一些需求修改
假如说,我觉得运行一张的速度太慢了,我想要批量去运行该怎么办,这里我们可以写一个batch_process.sh文件
#!/bin/bash
# 指定图片文件夹路径
IMAGE_DIR="./test"
# 遍历图片文件夹中的所有图片文件
for image_file in "$IMAGE_DIR"/*.jpg; do
if [ -f "$image_file" ]; then
echo "Processing $image_file"
./rknn_yolov5_demo ./model/RK3588/best5s.rknn "$image_file"
fi
done修改权限后:
chmod +x batch_process.sh直接运行即可
./batch_process.sh
七、CPU、GPU、NPU推理速度比较
(1)CPU
YOLOv5 Python-3.8.17 torch-1.8.2+cu111 CPU
image 1/164 480x640 1 car, Done. (1.507s)
image 2/164 480x640 1 car, Done. (1.556s)
image 3/164 480x640 1 car, Done. (1.330s)
image 4/164 480x640 1 car, Done. (1.285s)
image 5/164 480x640 1 car, Done. (1.306s)
image 6/164 480x640 1 car, Done. (1.269s)
image 7/164 480x640 1 car, Done. (1.331s)
image 8/164 480x640 1 car, Done. (1.321s)
image 9/164 480x640 1 car, Done. (1.251s)
image 10/164 480x640 1 car, Done. (1.307s)
平均时间为1.3436 s
YOLOv5 Python-3.7.9 torch-1.13.1+cpu CPU
image 1/164 480x640 1 car, Done. (0.597s)
image 2/164 480x640 1 car, Done. (0.625s)
image 3/164 480x640 1 car, Done. (0.614s)
image 4/164 480x640 1 car, Done. (0.607s)
image 5/164 480x640 1 car, Done. (0.541s)
image 6/164 480x640 1 car, Done. (0.498s)
image 7/164 480x640 1 car, Done. (0.497s)
image 8/164 480x640 1 car, Done. (0.481s)
image 9/164 480x640 1 car, Done. (0.512s)
image 10/164 480x640 1 car, Done. (0.502s)
平均时间为0.5475 s
(2)GPU
YOLOv5 Python-3.8.17 torch-1.8.2+cu111 CUDA:0 (NVIDIA GeForce RTX 4060 Laptop GPU, 8188MiB)
image 1/164 480x640 1 car, Done. (0.034s)
image 2/164 480x640 1 car, Done. (0.034s)
image 3/164 480x640 1 car, Done. (0.032s)
image 4/164 480x640 1 car, Done. (0.030s)
image 5/164 480x640 1 car, Done. (0.030s)
image 6/164 480x640 1 car, Done. (0.029s)
image 7/164 480x640 1 car, Done. (0.030s)
image 8/164 480x640 1 car, Done. (0.030s)
image 9/164 480x640 1 car, Done. (0.030s)
image 10/164 480x640 1 car, Done. (0.030s)
平均时间为0.0309 s
(3)NPU
运行十张所分别用到的时间
69.592200 ms,69.781700 ms,69.510100 ms,69.611600 ms,69.823200 ms,69.638200 ms,69.610600 ms,69.563400 ms,69.200500 ms,69.122900 ms
平均时间为69.54544 ms = 0.06954544 s
参考文章
瑞芯微RK3588开发板:虚拟机yolov5模型转化、开发板上python脚本调用npu并部署 全流程_yolov5模型在rk3588-CSDN博客
yolov5训练pt模型并转换为rknn模型,部署在RK3588开发板上——从训练到部署全过程_yolov5 rknn-CSDN博客
瑞芯微rk3588部署yolov5模型实战_在rk3588上部署yolov5-CSDN博客
yolov5训练并生成rknn模型以及3588平台部署_yolov5 在rk3588上的部署-CSDN博客

















 2905
2905

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











