






 本文介绍了YOLOv5/YOLOv8作为目标检测算法在车牌识别中的应用,以及LPRNet的车牌字符识别能力。通过实例展示了如何将两者结合实现车牌检测与识别,并详细讲解了数据集制作和模型训练的过程。
本文介绍了YOLOv5/YOLOv8作为目标检测算法在车牌识别中的应用,以及LPRNet的车牌字符识别能力。通过实例展示了如何将两者结合实现车牌检测与识别,并详细讲解了数据集制作和模型训练的过程。
YOLOv5 /YOLOv8和 LPRNet:车牌识别系统
随着计算机视觉技术的不断进步,车牌识别技术正变得越来越普遍和重要。在这个领域,YOLO和 LPRNet 是两个备受关注的开源项目,它们为车牌识别带来了新的突破。笔者将会介绍相关功能代码以及自己做的车牌识别系统项目。
YOLO:下一代目标检测算法
YOLO(You Only Look Once)是一种流行的实时目标检测算法,它以其高效的检测速度和准确性而闻名。在之前YOLO 版本的基础YOLOv5/YOLOv8 引入了新的功能和优化,使其成为广泛应用中各种物体检测任务的理想选择。
# YOLOv5 示例代码
import cv2
import yolov5
import numpy as np
model = yolov5.load("path/to/your/yolov5_license.pt")
frame = cv2.imread('path/to/your/license.png')
results = model(frame)
predictions = results.pred[0]
for r in predictions:
x_min, y_min, x_max, y_max = map(int, r[:4])
cv2.rectangle(frame, (int(x_min), int(y_min)), (int(x_max), int(y_max)), (0, 0, 255), 3)
cv2.imshow('detecting', frame)
cv2.waitKey(0)
cv2.destroyAllWindows()
LPRNet:高效的车牌识别网络
LPRNet 是一种专门设计用于车牌识别的深度学习网络,它能够准确地检测并识别车牌中的字符。与传统的基于模板匹配的方法相比,LPRNet 在复杂场景下表现更加稳定和可靠。
# LPRNet 示例代码
import torch
from data.load_data import CHARS
from model.LPRNet import build_lprnet
lpr_max_len = 8
dropout_rate = 0
phase_train = False
pretrained_model = "./weights/Final_LPRNet_model.pth"
lprnet = build_lprnet(lpr_max_len=lpr_max_len, phase=phase_train, class_num=len(CHARS),
dropout_rate=dropout_rate)
state_dict = torch.load(pretrained_model, map_location=torch.device("cpu"))
print(lprnet)
YOLOv5 和 LPRNet 在车牌识别中的应用
将 YOLOv5 /YOLOv8和 LPRNet 结合起来,可以构建一个完整的车牌检测与识别系统。首先,利用 YOLOv5/YOLOv8 对图像中的车辆进行检测,然后将检测到的车牌区域输入到 LPRNet 中进行字符识别,最终实现对车牌的准确识别。
# YOLOv5 和 LPRNet 结合示例代码
for r in detection_results.xyxy[0]:
# 获取检测框坐标
x_min, y_min, x_max, y_max = map(int, r[:4])
# 提取车牌图像
# plate_img = frame[y_min:y_max, x_min:x_max]
plate_number = self.recognize_plate_single_image(self.lprnet, frame, r[:4].squeeze())
# 在原图上绘制检测框
cv2.rectangle(frame, (int(x_min), int(y_min)), (int(x_max), int(y_max)), (0, 0, 255), 3)
这种组合应用不仅可以应用于交通管理、智能停车等领域,还可以扩展到安防监控、智慧城市等更广泛的应用场景中。
制作LPRNet数据集(YOLO标签)
import cv2
import os
from PIL import Image
# 图像文件夹路径
image_folder_path = r'D:\YOLO_LPRNet\datasets\train\images'
# 标签文件夹路径
label_folder_path = r'D:\YOLO_LPRNet\datasets\train\labels'
# LPRNet数据集保存路径
lprnet_data_path = r'D:\YOLO_LPRNet\LPRNet_data\train'
# 遍历图像文件夹
for image_filename in os.listdir(image_folder_path):
# 构建标签文件名
label_filename = os.path.splitext(image_filename)[0] + '.txt'
label_filepath = os.path.join(label_folder_path, label_filename)
# 读取图像
image_filepath = os.path.join(image_folder_path, image_filename)
image = cv2.imread(image_filepath)
# 读取标签
with open(label_filepath, 'r') as label_file:
label_content = label_file.readline().strip().split()
# 提取车牌区域坐标
x_center = float(label_content[1])
y_center = float(label_content[2])
width = float(label_content[3])
height = float(label_content[4])
# 计算边界框左上角和右下角坐标
image_height, image_width, _ = image.shape
xmin = int((x_center - width / 2) * image_width)
xmax = int((x_center + width / 2) * image_width)
ymin = int((y_center - height / 2) * image_height)
ymax = int((y_center + height / 2) * image_height)
# 裁剪车牌区域
plate_region = image[ymin:ymax, xmin:xmax]
# 将图像从 BGR 格式转换为 RGB 格式
plate_rgb = cv2.cvtColor(plate_region, cv2.COLOR_BGR2RGB)
# 调整车牌尺寸
plate_image = Image.fromarray(plate_rgb)
plate_image = plate_image.resize((94, 24), Image.LANCZOS)
# 保存裁剪后的车牌区域
save_filename = os.path.splitext(image_filename)[0] + '_plate.jpg'
save_filepath = os.path.join(lprnet_data_path, save_filename)
plate_image.save(save_filepath)
print("LPRNet数据集制作完成。")
训练LPRNet模型过程(demo)
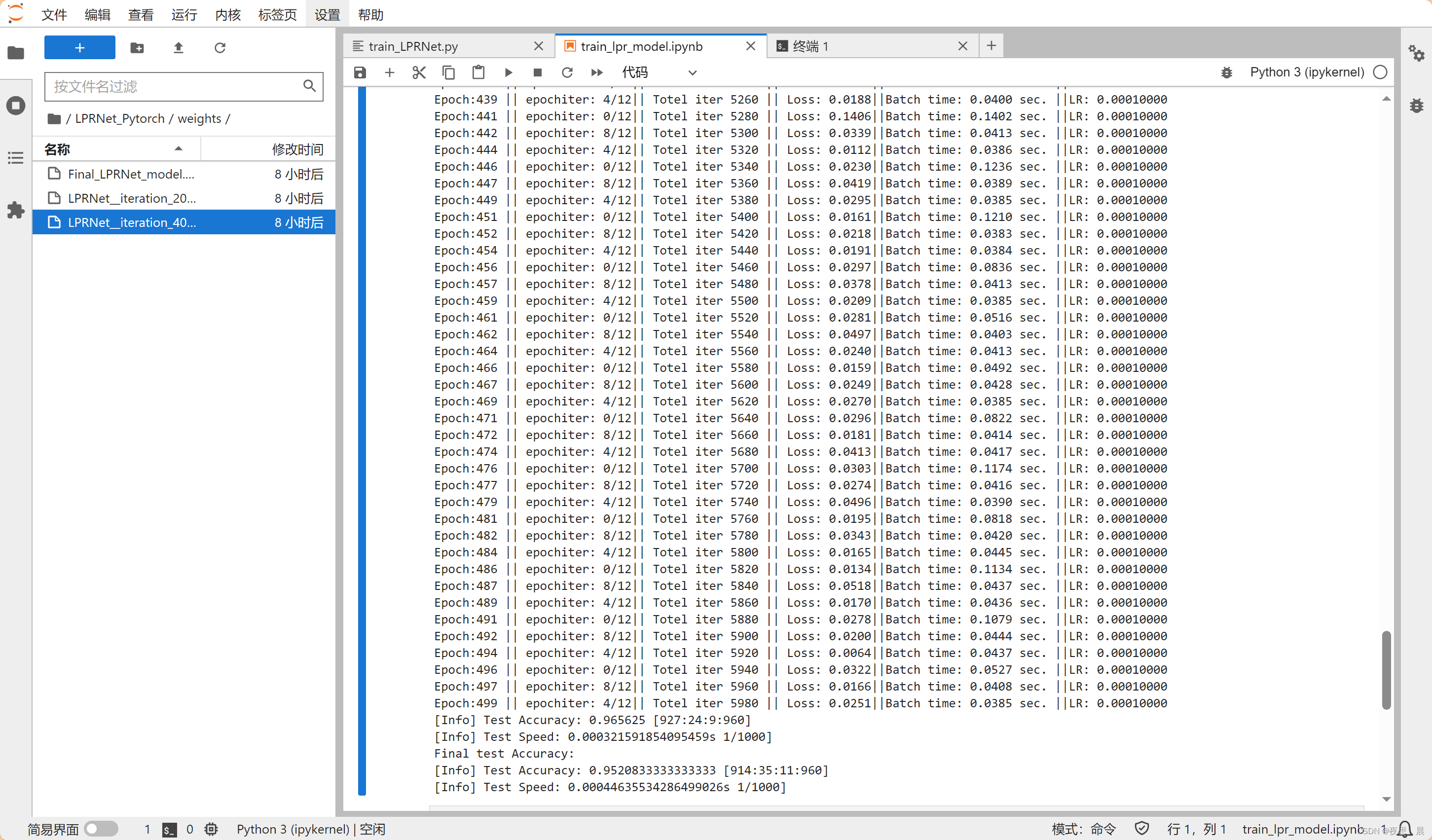
- 附训练LPRNet模型例子:
- 百度网盘链接
链接:https://pan.baidu.com/s/1PUmFHQ9aGrmPgial5VlPfg?pwd=1234
提取码:1234
车牌识别系统项目
- 面包多:https://mbd.pub/o/bread/ZpWTlpZx
- 闲鱼用户:欧阳孤云(头像为🐶)
- 功能:支持图片,本地视频,摄像头车牌识别检测
- 源码包含YOLO车牌数据集和训练好的YOLOv5和YOLOv8车牌模型
- 哔哩哔哩展示

运行说明
- 创建虚拟环境
python -m venv venv
- 激活虚拟环境
activate ./venv/Scripts/activate
或者
./venv/Scripts/activate
如果遇到报错,执行以下指令,然后输入1回车,即可激活虚拟环境
Set-ExecutionPolicy RemoteSigned
Set-ExecutionPolicy -Scope CurrentUser
- 环境安装
pip install yolov5==7.0.13 imutils==0.5.4 -i https://pypi.mirrors.ustc.edu.cn/simple/
- 运行程序
python UI.py
结语
YOLOv5 /YOLOv8和 LPRNet 代表了目标检测和车牌识别领域的最新进展,它们的出现为开发者提供了强大的工具和技术支持。随着深度学习技术的不断发展,我们有理由相信,车牌识别技术将会在更多领域展现出强大的应用价值。
如果你对这个项目感兴趣,不妨亲自动手尝试一下,也许你会发现更多有趣的应用和发现!
参考
https://github.com/sirius-ai/LPRNet_Pytorch
https://github.com/ultralytics/ultralytics

















 7199
7199

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









