







前言
今天完成第二,三问
统计各个省份的浏览量 (需要解析IP)
日志的ETL操作(ETL:数据从来源端经过抽取(Extract)、转换(Transform)、加载(Load)至目的端的过程)
一、项目要求
根据电商日志文件,分析:
-
统计页面浏览量(每行记录就是一次浏览)
-
统计各个省份的浏览量 (需要解析IP)
-
日志的ETL操作(ETL:数据从来源端经过抽取(Extract)、转换(Transform)、加载(Load)至目的端的过程)
为什么要ETL:没有必要解析出所有数据,只需要解析出有价值的字段即可。本项目中需要解析出:ip、url、pageId(topicId对应的页面Id)、country、province、city
二、步骤
1.代码结构
第二问

第三问

2.代码
创建P2Driver 类
负责设置作业的配置和运行
package mr2;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class P2Driver {
public static void main(String[] args) throws Exception {
if (args.length != 2) {
System.err.println("Usage: P2Driver <input path> <output path>");
System.exit(-1);
}
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "Page View Count");
job.setJarByClass(P2Driver.class);
job.setMapperClass(P2Mapper.class);
job.setCombinerClass(P2Reducer.class);
job.setReducerClass(P2Reducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
创建P2Mapper类
处理日志文件并根据IP地址解析出省份信息。每个输入行会被解析成一个或多个键值对输出,其中键是省份名称,值是计数(1)。
package mr2;
import com.bigdata.hadoop.project.utils.LogParser;
import org.apache.commons.lang3.StringUtils;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import com.bigdata.hadoop.project.utils.IPParser;
import com.bigdata.hadoop.project.utils.LogParser;
import java.io.IOException;
import java.util.Map;
public class P2Mapper extends Mapper<LongWritable, Text, Text, IntWritable> {
private static final IntWritable one = new IntWritable(1);
private Text city = new Text();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException, IOException {
// Split the input line into fields based on the delimiter
String[] fields = value.toString().split("\u0001");
if (fields.length > 13) {
// Assuming the IP address is in the 14th field (index 13)
String ip = fields[13];
String log = value.toString();
LogParser parser = new LogParser();
Map<String, String> logInfo = parser.parse(log);
if (StringUtils.isNotBlank(logInfo.get("ip"))) {
IPParser.RegionInfo regionInfo = IPParser.getInstance().analyseIp(logInfo.get("ip"));
String province = regionInfo.getProvince();
if (StringUtils.isNotBlank(province)) {
context.write(new Text(province), new IntWritable(1));
} else {
context.write(new Text("-"), new IntWritable(1));
}
} else {
context.write(new Text("+"), new IntWritable(1));
}
}
}
}
创建P2Reducer类
接收一个省份名称及其对应的计数列表,计算这些计数的总和,并输出省份名称及其总计数。
package mr2;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
class P2Reducer extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
建ETLDriver类
// An highlighted block
package ETL;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class ETLDriver {
public static void main(String[] args) throws Exception {
if (args.length != 2) {
System.err.println("Usage: ETLDriver <input path> <output path>");
System.exit(-1);
}
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "Log ETL");
job.setJarByClass(ETLDriver.class);
job.setMapperClass(ETLMapper.class);
job.setCombinerClass(ETLReducer.class);
job.setReducerClass(ETLReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
建ETLMapper类
// An highlighted block
package ETL;
import com.bigdata.hadoop.project.utils.GetPageId;
import com.bigdata.hadoop.project.utils.LogParser;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.io.IOException;
import java.util.Map;
public class ETLMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
private static final IntWritable one = new IntWritable(1);
private Text outputKey = new Text();
private LogParser logParser = new LogParser();
private Logger logger = LoggerFactory.getLogger(ETLMapper.class);
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 解析日志记录
Map<String, String> logInfo = logParser.parse(value.toString());
if (logInfo == null) {
logger.error("日志记录的格式不正确或解析失败:" + value.toString());
return;
}
// 获取需要的字段
String ip = logInfo.get("ip");
String url = logInfo.get("url");
String country = logInfo.get("country");
String province = logInfo.get("province");
String city = logInfo.get("city");
// 调用 GetPageId 获取 topicId
String topicId = GetPageId.getPageId(url);
logInfo.put("pageId", topicId);
// 检查所有字段是否全部为空
if (ip != null || url != null || topicId != null || country != null || province != null || city != null) {
StringBuilder sb = new StringBuilder();
if (ip != null && !ip.isEmpty()) sb.append("IP: ").append(ip).append(", ");
if (url != null && !url.isEmpty()) sb.append("URL: ").append(url).append(", ");
if (topicId != null && !topicId.isEmpty()) sb.append("PageId: ").append(topicId).append(", ");
if (country != null && !country.isEmpty()) sb.append("Country: ").append(country).append(", ");
if (province != null && !province.isEmpty()) sb.append("Province: ").append(province).append(", ");
if (city != null && !city.isEmpty()) sb.append("City: ").append(city);
// 移除末尾的逗号和空格
String outputString = sb.toString().replaceAll(", $", "");
outputKey.set(outputString);
context.write(outputKey, one);
} else {
logger.error("所有字段为空,日志记录:" + value.toString());
}
}
}
建ETLReducer类
// An highlighted block
package ETL;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class ETLReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
3.打JAR包


4.在Hadoop虚拟机运行提交HDFS

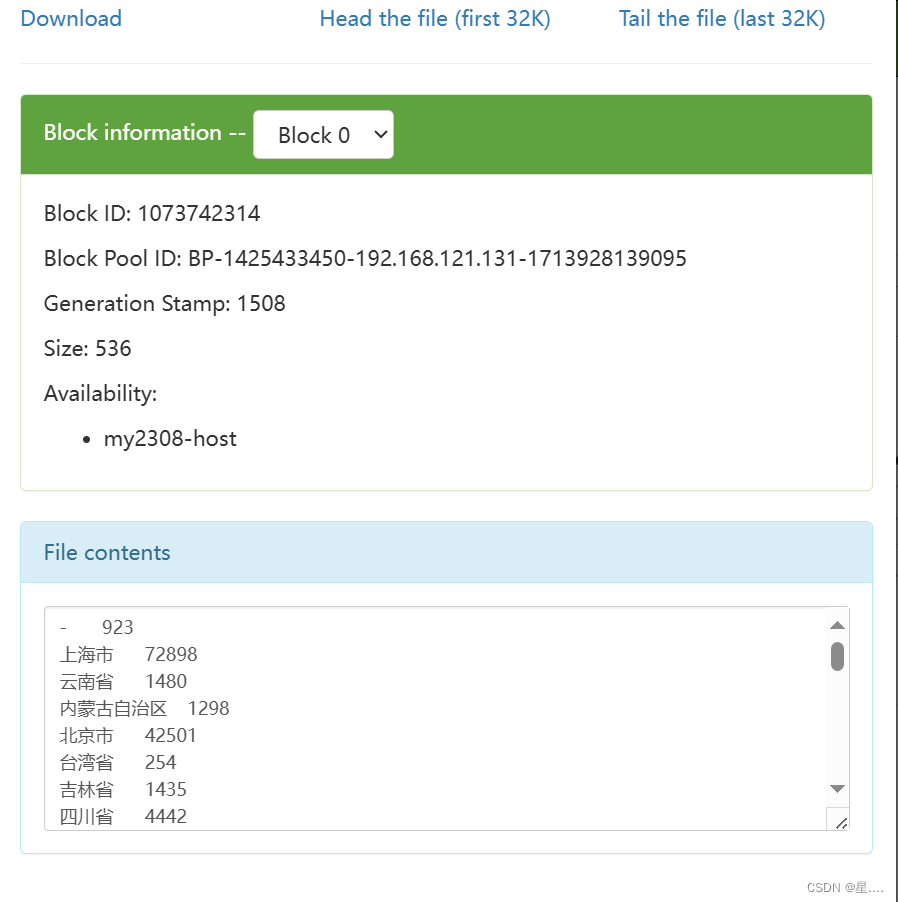
总结
为了统计各个省份的浏览量并进行必要的ETL操作,我们设计了一个Mapper类(P2Mapper),其主要功能包括从日志文件中抽取有价值的字段,并解析IP以获取省份信息。
完整ETL过程
抽取(Extract):从原始日志文件中抽取数据行。
转换(Transform):利用 LogParser 和 IPParser 对数据进行转换。
加载(Load):将转换后的省份信息和计数作为键值对输出,供Reducer阶段汇总统计。















 7560
7560











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









