






逻辑回归是线性回归的一种,事实上他是一个被logistic方程归一化后的线性回归,将样本的特征与发生的概率联系起来。
逻辑回归虽然被成为回归,但其实是分类模型,并常用于二分类。
作用:1.估计某事物的可能性
2.适用于流行病学资料的危险因素分析
1.sigmoid函数
表达式:![]()
图像为:

特点:该函数有一个很好的特性就是在实轴域上y的取值在(0,1),且有很好的对称性,对极大值和极小值不敏感(因为在取向无论是正无穷还是负无穷的时候函数y几乎都很稳定)
基于sigmoid函数的值域在(0,1)之间,正好可以表示一个概率值(暂不考虑该值为0或1的情况)
令![]()
(这里的θ和x可以是一个向量,θ是一个行向量,x是一个列向量。)
上式表示在给定观察值x时,预测y=1的概率。
即当有观察值x时,Y=1的概率为![]()
那么当有观察值x时,Y=0的概率为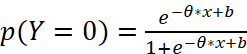
将式1和式2合为一个式子,得

2.求解θ
b可看成是θ的一个分量,这个时候b对应的x值默认为1
方法:1.最大似然估计法
2.从损失函数出发
损失函数
对数损失函数:
![]() (条件概率对数的负数)
(条件概率对数的负数)
(时刻牢记一般情况下这里的P(Y|X)定义为当在观察到X的时候判断Y=1的概率)
当Y=1时,损失函数为:![]()
当Y=0时,损失函数为:![]()
(其中![]() 是观察Y取0的概率)
是观察Y取0的概率)
将以上两个式子进行合并,有损失函数为:
![]()
将![]() 代入上式,有:
代入上式,有:

(这里把Y换成了y,式因为对于宇哥给定样本x和y都是已知的值)
化简上式:
![]()
以上是一个样本损失,那么n个样本损失和就是:

由于这个里面是关于θ和b的未知参数,可以看成是关于θ和b的函数:

由于这个是损失函数,所以满足此函数最小就是我们所求。
求损失函数的最小值使用梯度下降法。
Logistic函数求导时有一个特性,为:
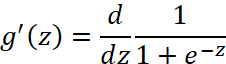
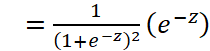
![]()
![]()
逻辑回归本质上是线性回归,只是在特征到结果的映射中加入了一层函数映射,即先把特征线性求和,然后使用函数g(z)将结果作为假设函数来预测。g(z)可以将连续值映射到0到1之间。线性回归模型的表达式代入g(z),就得到逻辑回归的表达式:

通过Logistic函数归一化(0,1)间,y的取值有特殊的含义,它表示结果取准确的概率,如果分类为1,h(x)==1表示预测100%准确,分类为0,h(x)==0表示预测100%准确,因此对于输入x分类结果为类别1和类别0的预测结果准确概率分别为:
![]()
![]()
合并上列表达式
![]()
得到了逻辑回归的表达式,下一步跟线性回归类似,构建似然函数,然后最大似然估计,最终推导出![]() 的迭代更新表达式。只不过这里用的不是梯度下降,而是梯度上升,因为这里是最大化似然函数不是最小化似然函数。
的迭代更新表达式。只不过这里用的不是梯度下降,而是梯度上升,因为这里是最大化似然函数不是最小化似然函数。
![]()
![]()

同样对似然函数取log,转换为:

转换后的似然函数对θ求偏导:

这样我们就得到了梯度上升每次迭代的更新方向,那么θ的迭代表达式为:

3.预测
当求得θ和b值之后,我们就得到了估计p(Y=1|X)![]() 具体的公式(θ和b的值已知,x也是已知),即:
具体的公式(θ和b的值已知,x也是已知),即:

给出预测样本x的值,通过上式可以计算出这是Y=1的概率,接下来一般用一个分段函数例如:
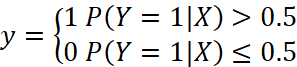
例子:用逻辑回归实现鸢尾花分类
代码如下:
#导入相关包
import numpy as np
from sklearn.linear_model import LogisticRegression
import matplotlib.pyplot as plt
import matplotlib as mpl
from sklearn import datasets
from sklearn import preprocessing
import pandas as pd
from sklearn.preprocessing import StandardScaler
from sklearn.pipeline import Pipeline
# 获取所需数据集
iris = datasets.load_iris()
#每行的数据,一共四列,每一列映射为feature_names中对应的值
X = iris.data
print(X)
#每行数据对应的分类结果值(也就是每行数据的label值),取值为[0,1,2]
Y = iris.target
print(Y)
#归一化处理
X = StandardScaler().fit_transform(X)
print(X)
lr = LogisticRegression() # Logistic回归模型
lr.fit(X, Y) # 根据数据[x,y],计算回归参数
N, M = 500, 500 # 横纵各采样多少个值
x1_min, x1_max = X[:, 0].min(), X[:, 0].max() # 第0列的范围
x2_min, x2_max = X[:, 1].min(), X[:, 1].max() # 第1列的范围
t1 = np.linspace(x1_min, x1_max, N)
t2 = np.linspace(x2_min, x2_max, M)
x1, x2 = np.meshgrid(t1, t2) # 生成网格采样点
x_test = np.stack((x1.flat, x2.flat), axis=1) # 测试点
cm_light = mpl.colors.ListedColormap(['#77E0A0', '#FF8080', '#A0A0FF'])
cm_dark = mpl.colors.ListedColormap(['g', 'r', 'b'])
y_hat = lr.predict(x_test) # 预测值
y_hat = y_hat.reshape(x1.shape) # 使之与输入的形状相同
plt.pcolormesh(x1, x2, y_hat, cmap=cm_light) # 预测值的显示
plt.scatter(X[:, 0], X[:, 1], c=Y.ravel(), edgecolors='k', s=50, cmap=cm_dark)
plt.xlabel('petal length')
plt.ylabel('petal width')
plt.xlim(x1_min, x1_max)
plt.ylim(x2_min, x2_max)
plt.grid()
plt.show()
y_hat = lr.predict(X)
Y = Y.reshape(-1)
result = y_hat == Y
print(y_hat)
print(result)
acc = np.mean(result)
print('准确度: %.2f%%' % (100 * acc))参考:https://blog.csdn.net/qq_46051625/article/details/115208435















 21万+
21万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









