







一、书生·浦语大模型开源历程以及主要亮点
1.首先是简单对比一个专用模型以及通用大模型:在2023年之前,也就是在奥特曼同志的openai还没发布王炸级别的ChatGPT时,针对人工智能领域,一直都崇尚并遵循着“同一模型,针对不同的问题,其性能会不一样的"的原则,这也就是特定问题采用特定模型的时代,也就叫专用模型。后来chatgpt的发布,直接利用transformer框架开发的大模型,直接一个模型应对各种任务,多种模态,直接杀疯,因此国内的众多研究机构也开始投入战斗,InternLM就是其中之一。

2.开源历程见图片。

3.主要亮点,对标ChatGPT,感觉非常不错

4.性能方面,全方位提升,对标ChatGPT3.5

二、书生·浦语全链条开源开放体系
个人觉得,先不说这个InternLM好不好用,这个全链条开源确实是真的爱了爱了ww,下面就来大概介绍一下这个全链条的开源开放体系

1.首先是开放大模型也是所有人工智能模型最关键的”燃料“:训练数据集,在LLM里面就叫作语料数据。InternLM采用的都是高质量的语料数据,无论是质量还是数量方面都是非常nice的,最关键的是还是开放的嘿嘿嘿

2.这个预训练的部分,我不是特别的理解,大概应该是该模型有一个已经训练好的基础模型,你可以直接调用拿来使用,也可以支持拓展,自己把模型训练的好一点点。

3.这里应该就是我刚刚说的 拓展这个预训练模型了,可以自己进行增量续训给模型更新最新的知识库语料数据,也可以有监督训练,让模型根据你自己的需求进行微调

4.评测部分:大模型的性能评测也是一个非常重要的工作。这里是研究团队自己开发的OpenCompass2.0评测体系。还建立自己的高质量评测社区,大佬们可以一起交流。


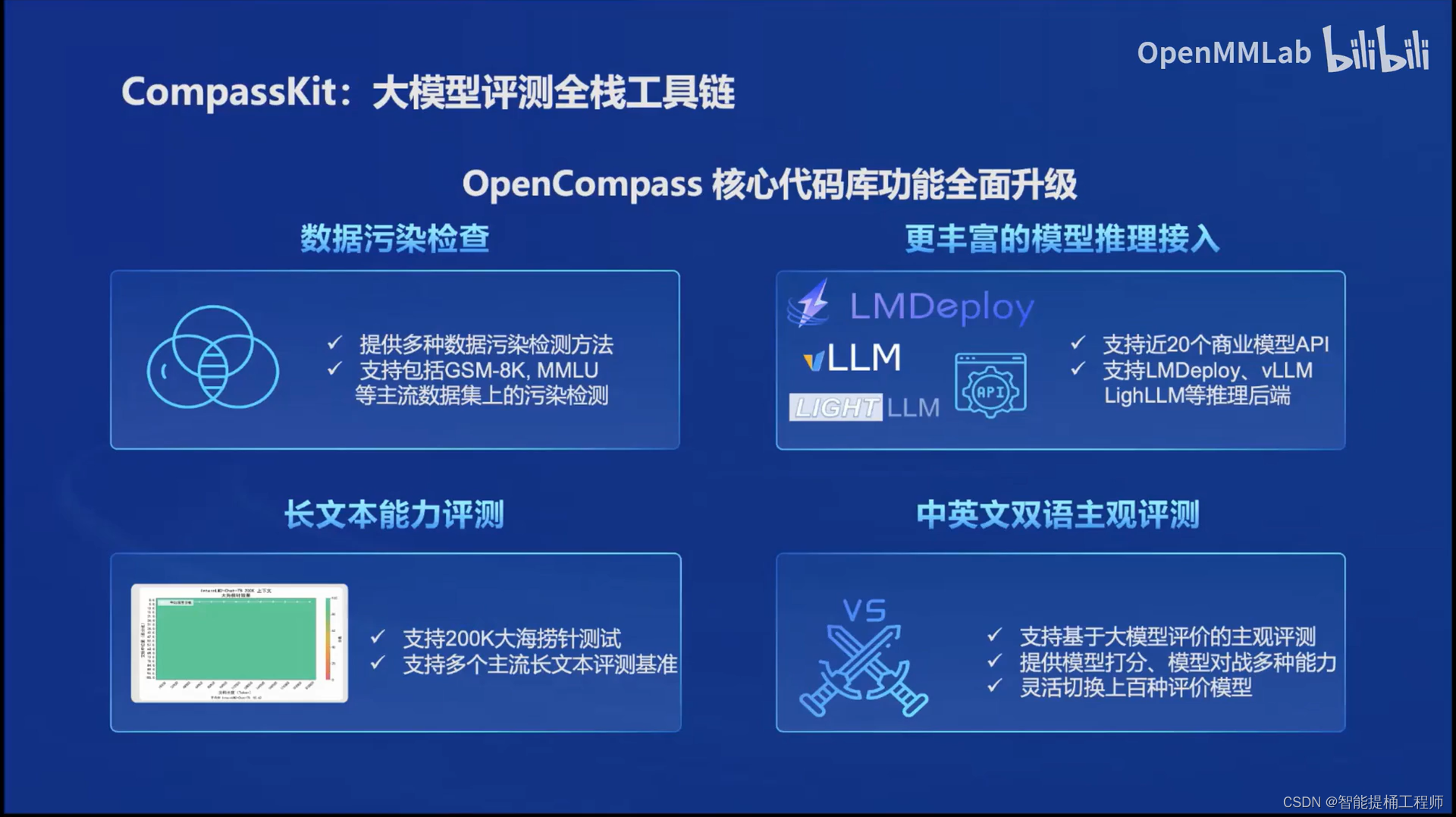


5.最后就是大佬们可以那这些大模型,进行拓展部署用于自己的实际工作以及实际的项目开发。(其实我还是不太懂这个哈哈哈哈)
地址:
github:https://github.com/InternLM
也可以上B站看视频,内容更详细
https://www.bilibili.com/video/BV1Vx421X72D/?spm_id_from=333.999.0.0&vd_source=9ca176d05f12495ce436da9795357be1














 837
837











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









