






安装spark要在hadoop安装成功的情况下进行,这里用的hadoop版本是2.10.2
一、环境搭建
使用清华大学下载站镜像进行下载,网址: https://mirrors.tuna.tsinghua.edu.cn/
1. 点击 apache

2. 在新页面中,使用快捷键 ctrl+f 输入spark 进行查找并点击 spark

3. 选择需要的spark版本,一般直接选择最新版

4. 选择与之前使用的hadoop版本相同的spark
例如:我使用hadoop2.10 就选择 hadoop2 那一项
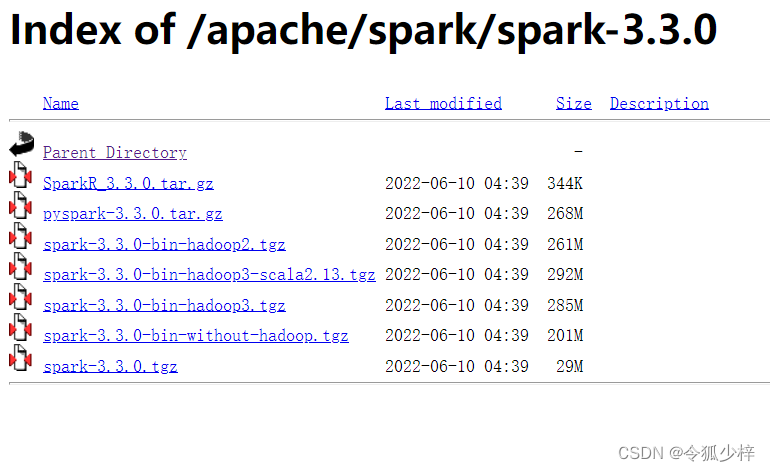
5. 点击下载,下载完毕后移动到一个目录下
我选择的是 /usr/local/,如果权限不够就 root
su root //进入root用户mv spark-3.3.0-bin-hadoop2.tgz /usr/local6.解压文件
sudo tar -zxvf spark-3.3.0-bin-hadoop2.tgz做到这一步环境就配置好了,接下来进入编程环节
二、在pyspark中编写代码,实现统计词频
1. 编写统计词频需要的文件
cd /usr/local/spark
vi file1进入 vi 界面后输入需要统计的内容
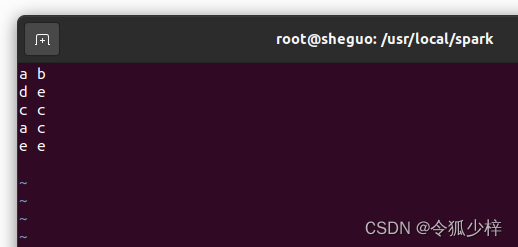
vi操作方法: i 进行编辑 Esc 退出编辑 :wq 保存并退出
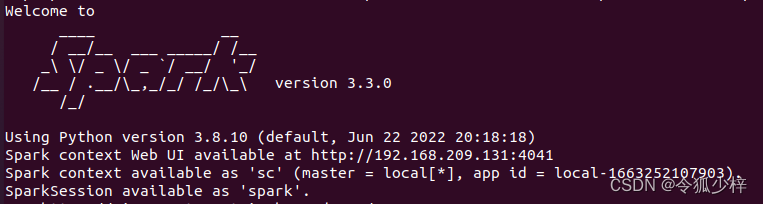
2. 执行以下命令,启动pyspark(默认local模式)
cd /usr/local/spark //进入你之前安装spark的路径
./bin/pyspark显示下面这个超大spark 就是启动成功
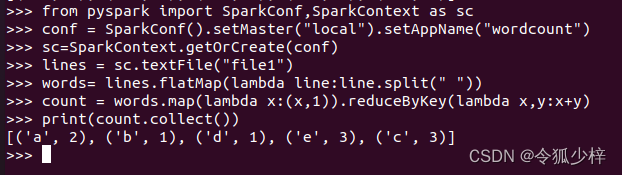
3.在pyspark里输入以下代码
from pyspark import SparkConf,SparkContext as sc
conf = SparkConf().setMaster("local").setAppName("wordcount")sc=SparkContext.getOrCreate(conf)lines = sc.textFile("file") //file就是文件的路径,如果文件在其他地方则更改为相应路径words = lines.flatMap(lambda line:line.split(" ")) //注意split后引号里有空格count = words.map(lambda x:(x,1)).reduceByKey(lambda x,y:x+y)print(count.collect())每打一行按一下回车,如果出现报错基本是输入代码写错了或是文件没读取到,修改一下路径就可以解决
最终运行结果如下图所示
参考文章 http://blog.csdn.net/yan88888888888888888/article/details/118600685















 1514
1514











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









