






🐉一、需求分析:
前几天在视频号上,发现一部 小伙收尸人的解说很有意思。但是却没有了了续集
刚好学了爬虫的正则和requests刚好可以实操
实现逻辑
🐉二、 挑战:
1 如何获取所有链接?
抓取不是简单一个页面就包含文本的链接:
1主链接--10个包含50个章节的链接
2每个章节包含3页内容--3个文本链接
3一共是:10*0-50*3≈1400个链接
2 如何把一个章节3个链接的内容都按顺序放进去?
1使用os获取每个章节的名字保存一个txt到本地一个单独文件夹
2使用with w下创建和写入第一页的内容
3使用with a 在已有的txt 继续写入,第二,第三页的内容
🐉1 爬取对象的额选取
1.1 网上有不少网址是可以免费阅读的。当然70%的需要付费,这个就跳过,源代码看不了的内容爬不了
1.2能够看到章节,但是内容显示不全----pass
1.3浏览一下,发现可以看到所有章节,F12开发者查看,源代码也有文本---保存有所有章节的链接
🐉 2 实现逻辑:
2.1:测试是否可以获得源代码:
环境python3.10,编辑器:jupyter
requests获取源代码,增加多个代理权池子,random.choice,模拟下多个代理访问链接
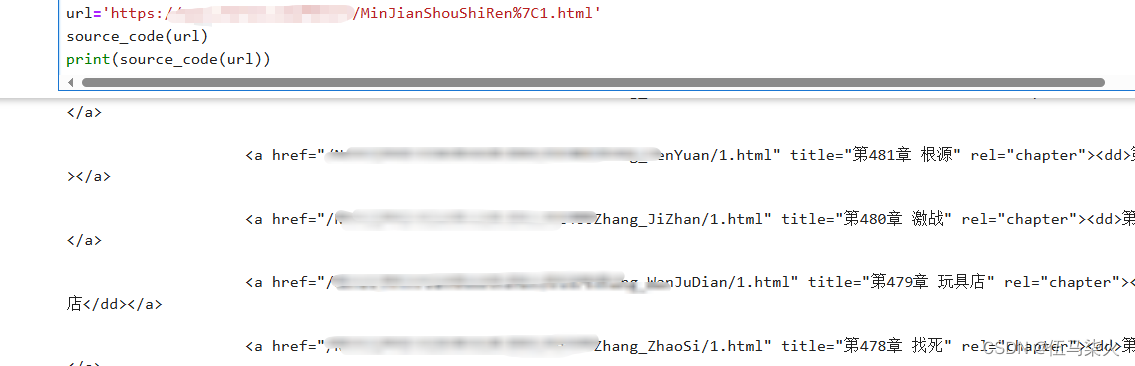
2.2获取所有章节的链接:
2.2.1.大章节的链接列表list:复制主页的源代码中的10个章节的链接,正则去获取绝对链接

![]()
2.2.2 定义一个request和for遍历,获取各个大章节链接中的章节链接

2.2.3获得所有章节链接的池子列表:

2.3获取正文
2.3.1正则表达式:大抓小

🐉 2.3.2获取正文-解决 格式问题:
打印出米的式没有去除格式大内容:
包含了<div id = >和正文结尾<p>
1 去掉不需要的格式--re.sub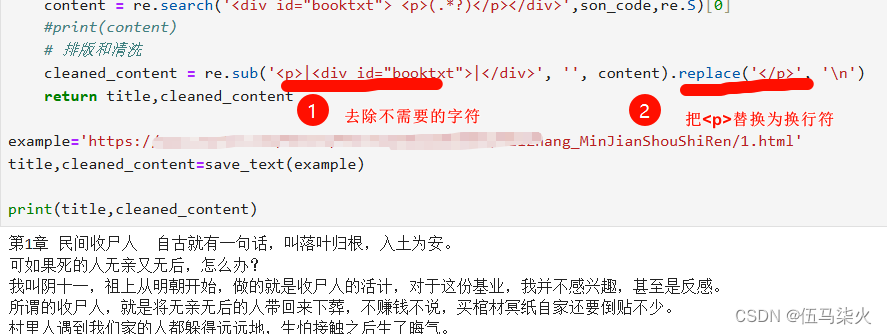
2 加入\nl保证分行---replace
2.4 写以章节标题为名字的txt文本中
2.4.1 name=建立一个自动命名的文件,这里式 收尸人
2.5批量自动化获取和保存
2.5.1 建立for 循环来遍历每个章节list中的url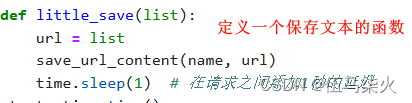
2.5.2 使用pool 多线程来加快获取的速度
 需要的库:
需要的库:
from multiprocessing.dummy import Pool--第三方库 多进程
import time---计时
2.6撒花
🐉 3 遇到的问题
3.1 去除文本中不需要的字符串2种方法
使用re.sub----可以在文本中直接去除自己多个不想要的字符串---替换多种为一种符号![]()
使用 replace('不要的内容','替换的内容'),增加换行\n--缺点只能替换一种对象为一种符号
![]()
3.2 🐉一个章节多个页面---我以为只需要获取一次所有章节的链接就可以完成
实际:昨天阅读的时候发现,内容少了-----查看网页,发现一个章节有3个url的源代码
解决:ai询问是否可以在已有链接情况下,修改尾号的数字--得到所有章节的每一页的链接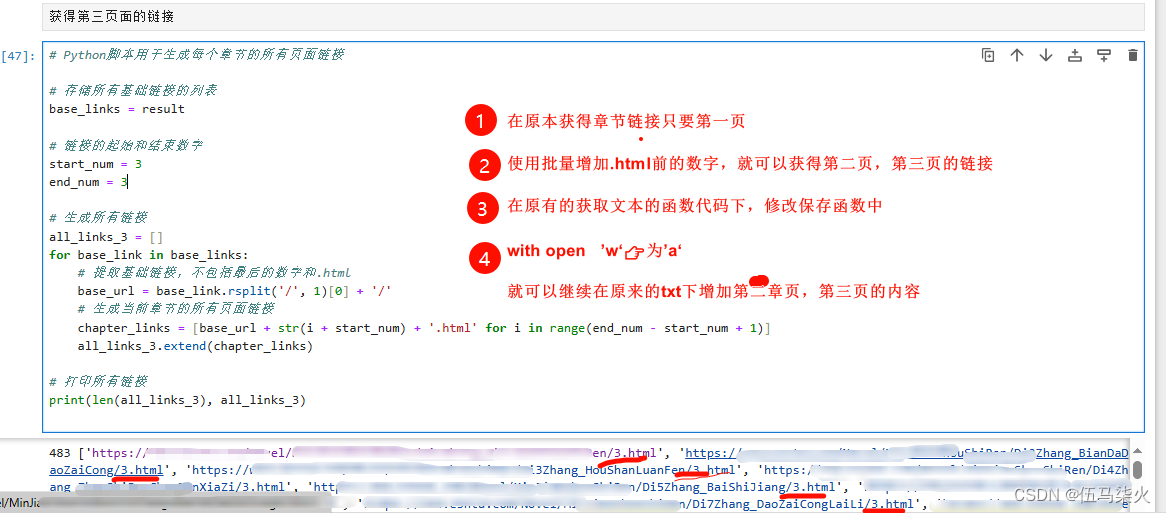
import os
import re
import requests
from multiprocessing.dummy import Pool
import time
# name='收尸人'
一、保存文本的代码
#1 获取单个链接的源代码
def source_code(url):
# 请求头字典
headers = {'User-Agent':dffwefwe---自己弄一个'}
# 发送GET请求,并添加请求头
# 发送GET请求,并添加Cookie
response = requests.get(url, headers=headers)
source_code = response.content.decode('utf-8')
# 检查请求是否成功
if response.status_code == 200:
return source_code
else:
return '无法获取源代码'
#2 获取单个链接的标题和正文
def save_text(url):
son_code = source_code(url)
#print(son_code)
#print(son_code)
#获取标题
title = re.search('bookname.>(.*?)<span style=.font-size',son_code,re.S).group(1)
#获取原文
content = re.search('<div id="booktxt"> <p>(.*?)</p></div>',son_code,re.S)[0]
print(content)
# 排版和清洗
cleaned_content = re.sub('<p>|<div id="booktxt">|</div>', '', content).replace('</p>', '\n')
return title,cleaned_content
#3 保存name的小说的章节包括各个章节的命名保存至一个name的文件夹
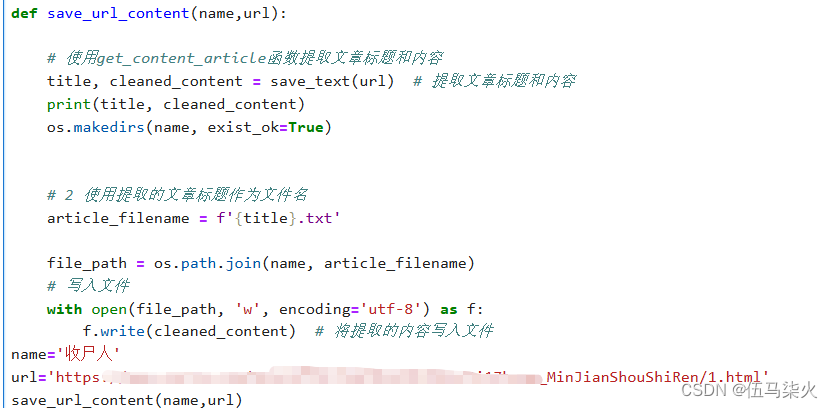
def save_url_content(name,url):
# 使用get_content_article函数提取文章标题和内容
article_title, cleaned_content = save_text(url) # 提取文章标题和内容
os.makedirs(name, exist_ok=True)
# 2 使用提取的文章标题作为文件名
article_filename = f'{article_title}.txt'
file_path = os.path.join(name, article_filename)
# 写入文件
with open(file_path, 'a', encoding='utf-8') as f:
f.write(cleaned_content) # 将提取的内容写入文件
# 7/2 测试
#url='https://=大苏打VS v吧g_BianDaDaoZaiCong/1.html'
#save_text(url)#获得标题和文本
#print(save_text(url))
#name='收尸人'
#save_url_content(name)#获取文本进行写入和命名
# 7/2 打印成功
# 4 保存所有链接的文本
name='收尸人'
def little_save(list):
url = list
save_url_content(name, url)
time.sleep(1) # 在请求之间添加1秒的延迟
start =time.time()
print(len(list))
pool=Pool(400)
pool.map(little_save,list)
end = time.time()
print(f'耗时{end-start}')
二、获取所有链接的代码
# 1 🐉 大批次的章节池
import re
url_list_code='''
主页种有大章节链接的网页源代码---每个链接打开后式50个章节的url
</select>
'''
#1.1 拼凑出绝对地址
url_0='https://www.esnta.com'
url_key = re.findall('option value=.(/Novel/MinJianShouShiRen.*?.html)',url_list_code,re.S)
print(url_key)
#1.2 得到大章节列表
url_2 =[]
for each in url_key:
url_i=f'{url_0}{each}'#获得完整链接
url_2.append(url_i)
print(url_2,len(url_2))
#得到的url_2 包含了所有大章节的链接
# 2 🐉 获取子章节的链接
#获取子章节的链接
import requests
# 2.1定义一个获取源代码的函数
def source_code(url):
# 请求头字典
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/126.0.0.0 Safari/537.36 Edg/126.0.0.0'}
# 发送GET请求,并添加请求头
# 发送GET请求,并添加Cookie
response = requests.get(url, headers=headers)
source_code = response.content.decode('utf-8')
# 检查请求是否成功
if response.status_code == 200:
return source_code
else:
return '无法获取源代码'
# 2.2 把获取的章节(包含文本的章节链接)的源代码制作成绝对地址---for 来获取所有链接
def get_url_3_list(url_2):
url = url_2
code = source_code(url)
#print(code)
main_son_list = re.search('全部章节.共483章.</dt>(.*?)<div class="listpage" >',code,re.S)[0]
dict_list = re.findall('''"(/Novel/MinJianShouShiRen.*?html)".title=''',main_son_list,re.S)
# 不在这一步获取标题,在正文页获取,就可以把正文和标题同时提取后返回得到两个变量后续写入的时候使用:
# 每个批次的50章节的url
dict_url_list =[]
for each in dict_list:
son_url=f'{url_0}{each}'
dict_url_list.append(son_url)
return dict_url_list# 得到列表的列表
# 3 🐉 章节数目太多采用多进程
from multiprocessing.dummy import Pool
import time
start =time.time()
# 2.3 多进程来获取url链接
pool=Pool(10)
#线程的次数
result=pool.map(get_url_3_list,url_2)
#10进程 执行函数get_url_3_list(url_2)
result = [x for sublist in result for x in sublist] # 从列表中的元素,每个元素是list,把其中的元素提取作为新的元素组成新的列表
#print(f'{len(result)}所有的正文链接:{result}')
end =time.time()
print(f'数量{len(result)}\n耗时{end-start}\n正文链接:{result}')















 245
245











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









