






参考机智流官方教程
Llama3-Tutorial/docs/llava.md at main · SmartFlowAI/Llama3-Tutorial (github.com)
在开发机环境下,使用这个代码
studio-conda -t lmdeploy -o pytorch-2.1.2conda activate lmdeploypip install -U lmdeploy[all]
ln -s /root/share/new_models/meta-llama/Meta-Llama-3-8B-Instruct ~/model/Meta-Llama-3-8B-InstructLMDeploy服务(serve)
在前面的章节,我们都是在本地直接推理大模型,这种方式成为本地部署。在生产环境下,我们有时会将大模型封装为 API 接口服务,供客户端访问。
启动API服务器
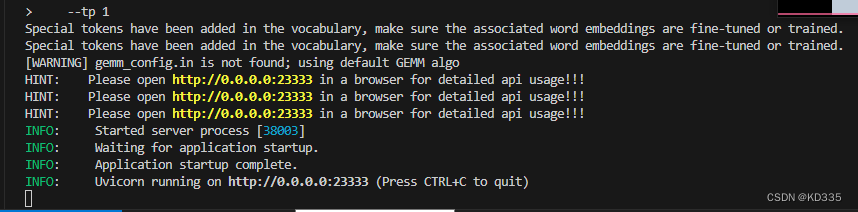
通过以下命令启动API服务器,推理Meta-Llama-3-8B-Instruct模型:
lmdeploy serve api_server \
/root/model/Meta-Llama-3-8B-Instruct \
--model-format hf \
--quant-policy 0 \
--server-name 0.0.0.0 \
--server-port 23333 \
--tp 1model-format、quant-policy这些参数是与第三章中量化推理模型一致的;server-name和server-port表示API服务器的服务IP与服务端口;tp参数表示并行数量(GPU数量)。 通过运行以上指令,我们成功启动了API服务器,请勿关闭该窗口,后面我们要新建客户端连接该服务。

这一步由于Server在远程服务器上,所以本地需要做一下ssh转发才能直接访问。在你本地打开一个cmd窗口,输入命令如下:
ssh -CNg -L 23333:127.0.0.1:23333 root@ssh.intern-ai.org.cn -p 你的ssh端口号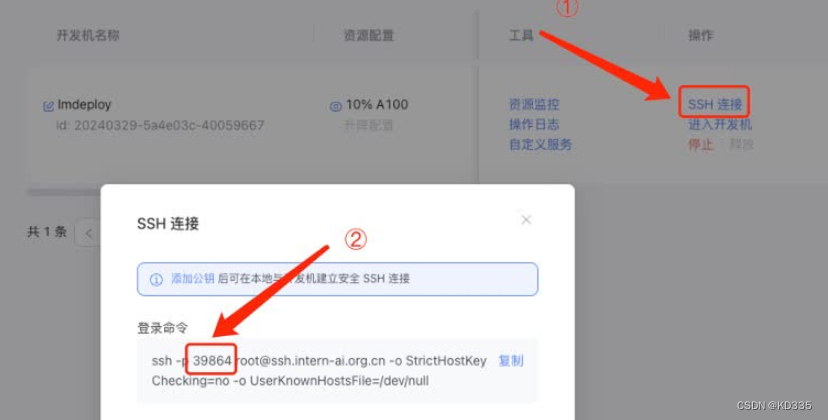
ssh 端口号就是下面图片里的 39864,请替换为你自己的。
然后打开浏览器,访问http://127.0.0.1:23333。
命令行客户端连接API服务器
本节中,我们要新建一个命令行客户端去连接API服务器。首先通过VS Code新建一个终端: 激活conda环境
conda activate lmdeploy
运行命令行客户端:
lmdeploy serve api_client http://localhost:23333运行后,可以通过命令行窗口直接与模型对话
4.3 网页客户端连接API服务器
关闭刚刚的VSCode终端,但服务器端的终端不要关闭。 运行之前确保自己的gradio版本低于4.0.0。
pip install gradio==3.50.2 新建一个VSCode终端,激活conda环境。
新建一个VSCode终端,激活conda环境。
conda activate lmdeploy使用Gradio作为前端,启动网页客户端。
lmdeploy serve gradio http://localhost:23333 \
--server-name 0.0.0.0 \
--server-port 6006打开浏览器,访问地址http://127.0.0.1:6006 然后就可以与模型进行对话了!















 1941
1941

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









