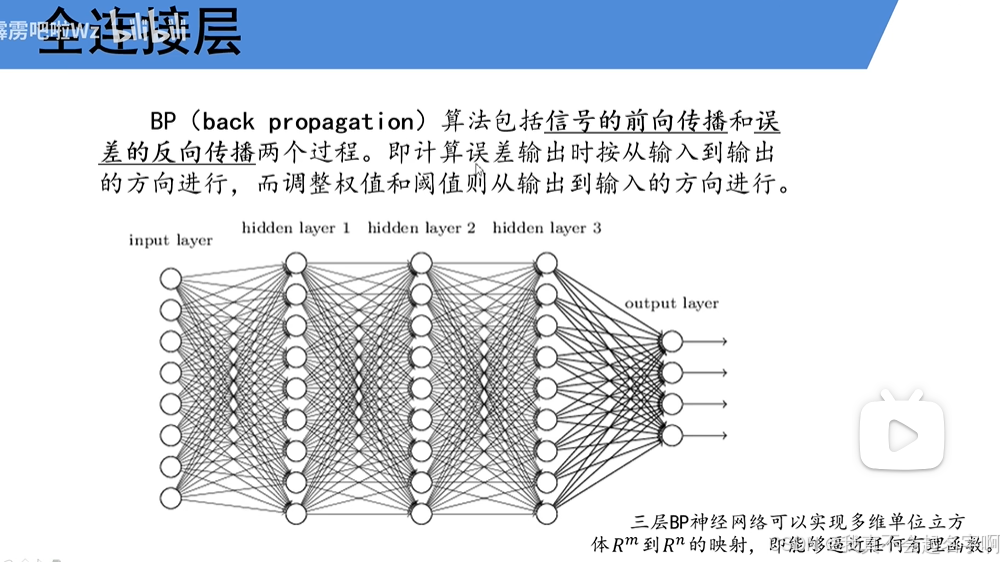
 Python下CNN详解与模型构建
Python下CNN详解与模型构建




目录
对图像的卷积操作其实就是滤波,将图像的空间域映射到频率域,就是进行编辑傅里叶变换编辑傅里叶变换,卷积可以理解为在频域上进行滤波。通过不同的卷积核处理图像后可以得到不同的特征图,卷积的作用就是将特征放大,不同的一些特征就可以组合成特定的物体,卷积就是在图像中将特征过滤出来的操作。
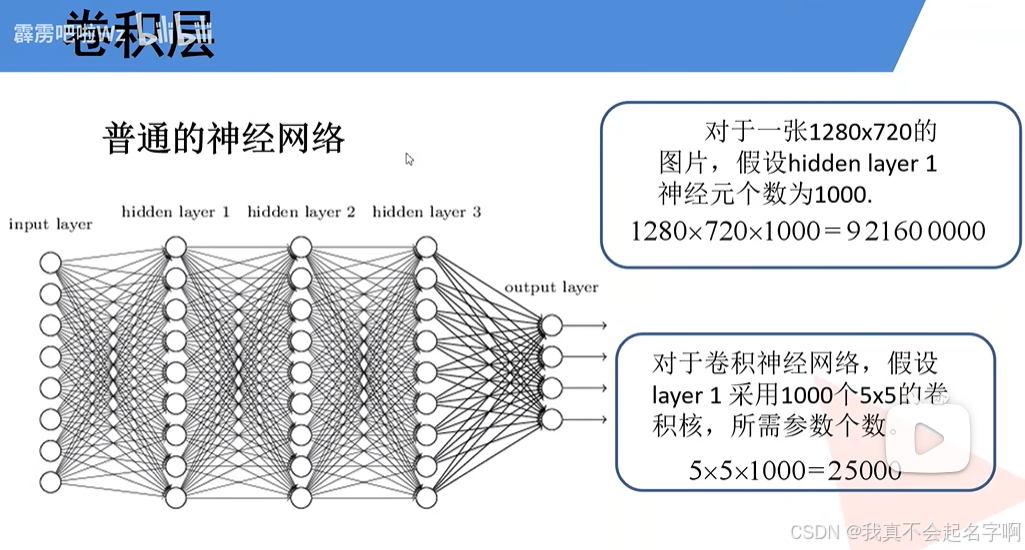
图像识别要满足图像平移旋转和缩放不变,那神经网络最好是一个像素对应一个神经元,但是图像都是几十万 几千万像素的,计算量太大。卷积神经网络的“卷积”不是信号处理的卷积,而是一组对像素的加权平均系数,不断的对图像缩小,缩小后的图像逐渐变形,最后摊平成适合神经网络计算的一维数组。
卷积神经网络(CNN)是一类功能强大的深度学习模型,旨在处理图像等网格状数据。他们通过从原始数据中有效地提取分层特征(边缘、纹理和对象),彻底改变了计算机视觉、图像识别和医学成像等领域。从卷积层、池化层、过滤器(或内核)、填充和步幅等将逐步构建和训练CNN模型。此外还介绍了一些先进的技术,如数据增强、DropOut和迁移学习,以提高性能。
1、简介
卷积神经网络(CNN)受到人类视觉皮层的启发,在从结构化网格数据(如图像)中提取特征的空间层次结构方面特别有效。图像自然地被表示为多维阵列-通常是具有对应于高度、宽度和颜色通道的维度的3D张量(例如,红色、绿色和蓝色)。这种结构化表示使图像成为CNN的理想候选者,CNN利用卷积运算来有效地处理输入数据的局部区域。
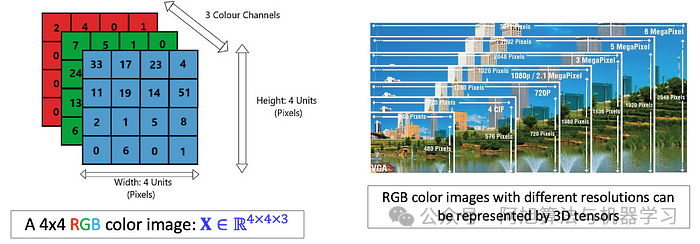
尺寸为4x 4x 3的红绿蓝(RGB)图像的3D张量。
与将输入数据视为平面向量的传统神经网络不同,CNN通过应用在图像上滑动的过滤器(或内核)来保留数据中的空间关系。这些过滤器检测边缘、纹理和形状等模式,使CNN能够逐层构建越来越复杂的特征表示。这种捕捉空间层次结构的独特能力使CNN非常适合涉及图像、视频和其他网格状结构的任务。
2、CNN架构的基础
2.1:卷积层
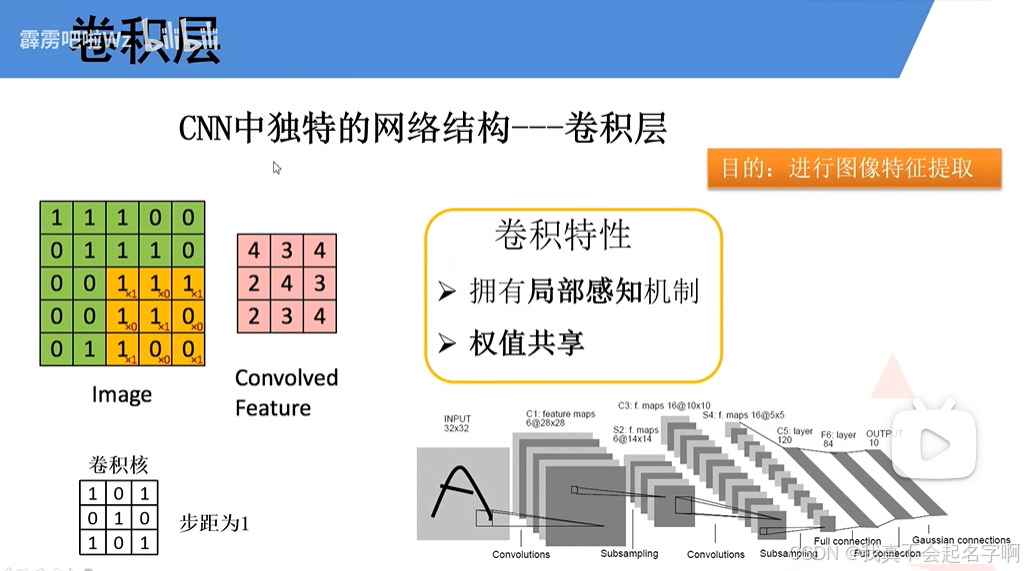
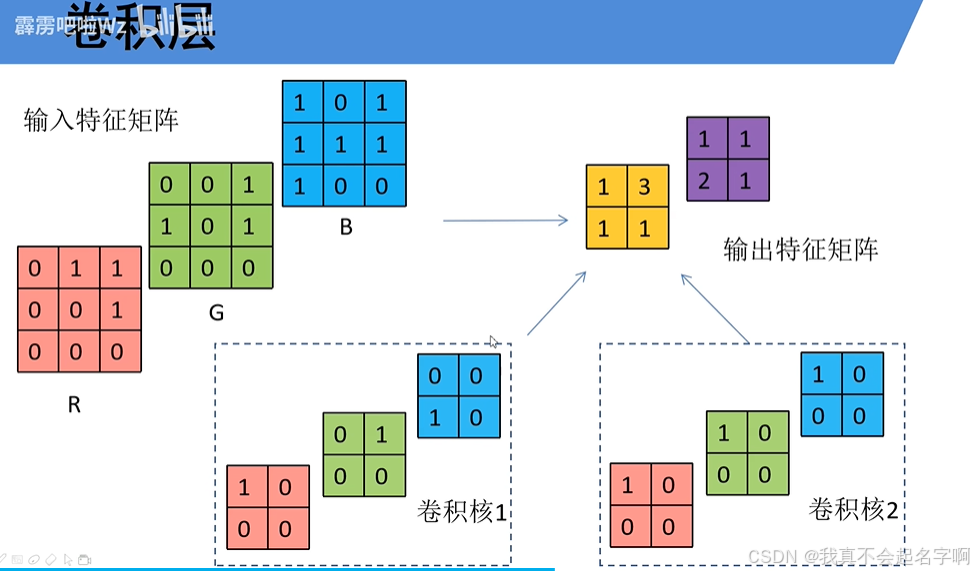
CNN的主干是卷积层,它将过滤器(或内核)应用于输入数据以提取边缘,纹理和模式等特征。这些层负责检测输入中的局部模式并构建数据的分层表示。每个卷积层产生一个或多个特征图,突出显示输入的特定特征。
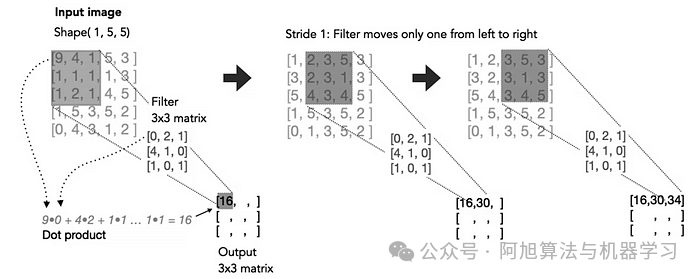
在数学上,卷积运算涉及在输入矩阵上滑动滤波器并计算滤波器权重与输入的对应区域之间的点积。这个过程捕获空间关系,使网络能够学习有意义的特征。


ReLU
MaxPool2d
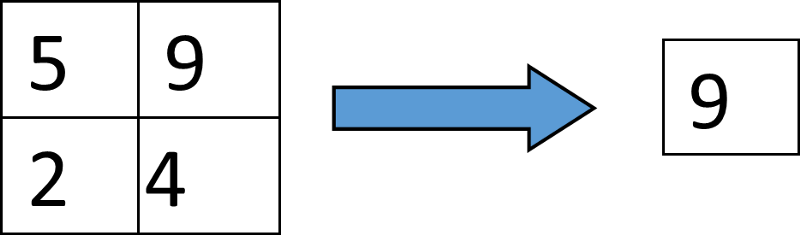
线性层
2.2:卷积核(Kernel):过滤器
核(或滤波器)是一个小的权重矩阵,它在输入数据上滑动以执行卷积运算。核的大小决定卷积的感受野,即,对每次计算有贡献的输入的局部区域。常见的内核大小包括3×3、5×5或7×7。
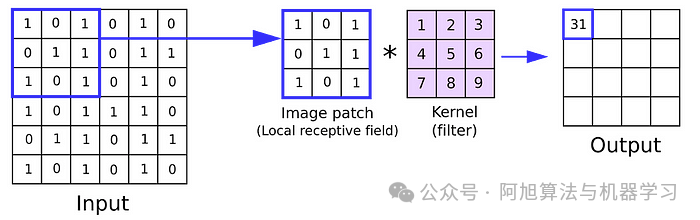
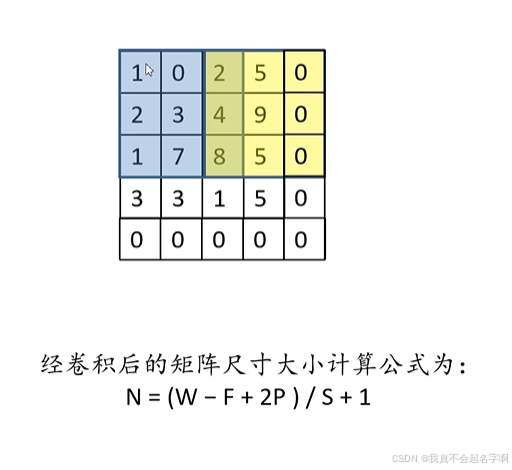
对于给定的大小为H×W的输入矩阵I和大小为K×K的滤波器F,位置(i,j)处的输出特征图O计算为:
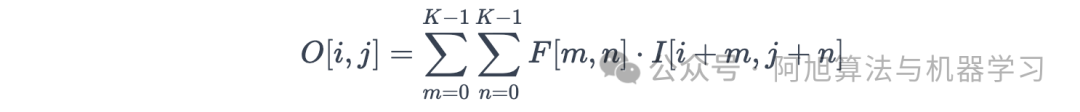
每个过滤器检测特定类型的特征,例如水平边缘、垂直边缘或纹理。通过堆叠多个滤波器,卷积层可以并行捕获各种模式。
2.3:填充Padding
填充涉及在输入矩阵的边界周围添加额外的像素(通常为零)。填充可确保输出特征图保持与输入相同的空间维度,或防止边缘处的信息丢失。
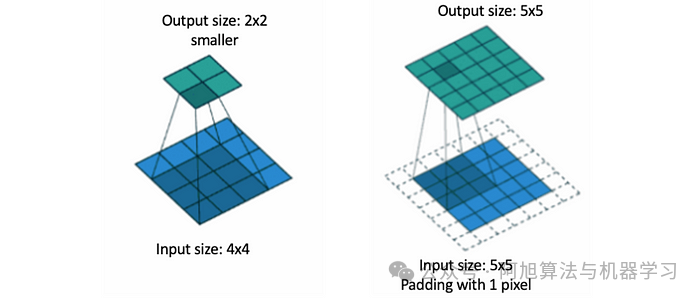
有两种常见的填充类型:
-
有效填充:不应用填充,导致输出特征图较小。
-
相同的填充:添加填充以使输出特征图具有与输入相同的空间维度。
例如,如果您将3×3滤波器应用于具有“相同”填充的5×5输入,则输出仍为5×5。如果没有填充,输出大小将由于过滤器与边缘的重叠而缩小。
2.4:步幅Stride
步幅决定了在卷积运算期间滤波器在输入矩阵上移动的程度。步幅为1意味着过滤器一次移动一个像素,而较大的步幅跳过像素,减少输出特征图的空间维度。
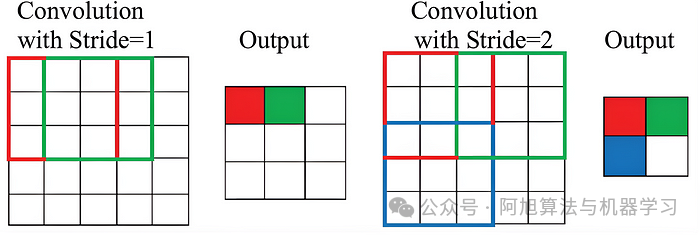
在应用具有步幅S的卷积之后,用于计算输出大小的公式为:
![]()
其中:
-
H和W是输入的高度和宽度,
-
K是卷积核大小,
-
P是填充大小,
-
S是步幅。
例如,步长为2时,过滤器会跳过每隔一个像素,从而有效地将输出特征图的空间维度减半。
2.5:多个过滤器和深度
每个卷积层可以有多个过滤器,每个过滤器检测不同的特征。输出特征图的深度对应于所应用的滤波器的数量。例如,如果您对输入图像应用32个过滤器,则输出将具有32个特征图。
2.6:权重共享
与全连接层不同,卷积层在所有空间位置上共享权重。这减少了参数的数量,并实现了有效的计算。例如,如果将3×3滤波器应用于5×5输入,则在整个输入中重复使用相同的滤波器权重。
2.7:特征图创建
对输入应用过滤器的结果称为特征图。每个特征图突出显示输入数据中的特定模式或特征。例如,一个特征图可能检测水平边缘,而另一个检测垂直边缘。
让我们通过一个例子来巩固这些概念。考虑一个5×5的输入图像和一个3×3的滤波器:
示例1(无填充,步幅为1):输入大小:5×5,内核大小:3×3,步幅:1,填充:无
使用公式:输出大小= 15−3 +1 × 15−3 +1 =3×3
输出特征图的尺寸为3×3。
示例2(相同填充,步幅为2):输入大小:5×5,内核大小:3×3,步幅:2,填充:相同
使用公式:输出大小= 25−3+2(1)+1 × 25−3+2(1)+1 =3×3
输出特征图将保留与输入相同的空间维度(5×5)。
示例3(多个过滤器):假设我们将32个大小为3×3的过滤器应用于5×5的输入,没有填充,步幅为1。每个过滤器产生一个3×3的特征图。由于有32个过滤器,输出将由32个特征图组成,从而产生大小为32×3×3的张量。
通过了解这些基本组件-卷积层,内核,填充,步幅和权重共享-您可以深入了解CNN如何处理图像数据并提取有意义的特征。这些示例说明了每个参数如何影响输出,并展示了CNN在从结构化数据中捕获不同模式方面的灵活性。
2.8、池化层


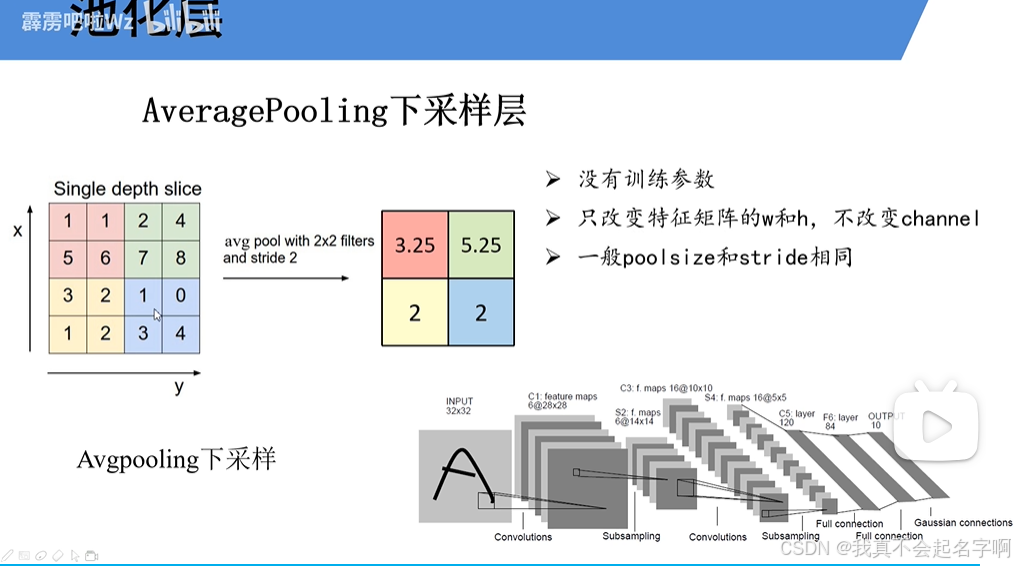
池层在减少特征映射的空间维度方面发挥着至关重要的作用,使模型的计算效率更高,更不容易过拟合。通过总结特征图的局部区域中的信息,池化有助于保留最重要的特征,同时丢弃不太相关的细节。这种降维也减少了后续层中的参数数量,加快了训练和推理。
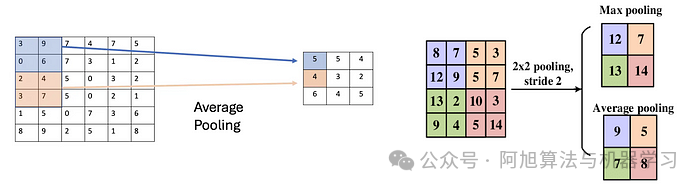
有两种常见的池操作类型:
最大池化:最大池化从特征图的每个局部区域获取最大值。例如,如果我们使用一个2×2的窗口来应用最大池化,则位置(i,j)处的输出计算为:
![]()
最大池化被广泛使用,因为它保留了每个区域中最突出的特征,例如边缘或纹理,这些特征通常是图像分类等任务中信息量最大的。
例如:考虑一个4×4特征图:

应用步长为2的2×2最大池化会导致:
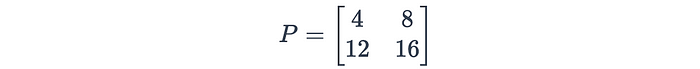
平均池化:平均池化计算每个局部区域的平均值,而不是最大值。此操作平滑了特征图,并提供了输入的更全局的表示。平均池的公式为:
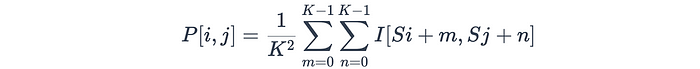
其中K是池化窗口的大小,S是步幅。
示例:使用与上述相同的4×4特征图,应用步长为2的2×2平均池化,结果为:

虽然最大池化强调的是最显著的特征,但平均池化捕捉了更广泛的输入摘要,使其在微妙模式很重要的场景中非常有用。
2.9:全连接层
在CNN的结尾,全连接(FC)层联合收割机结合提取的特征进行预测。这些层基于学习的表示执行分类或回归。在多个卷积层和池化层降低了空间维度并提取了高级特征之后,完全连接的层充当网络的决策组件。
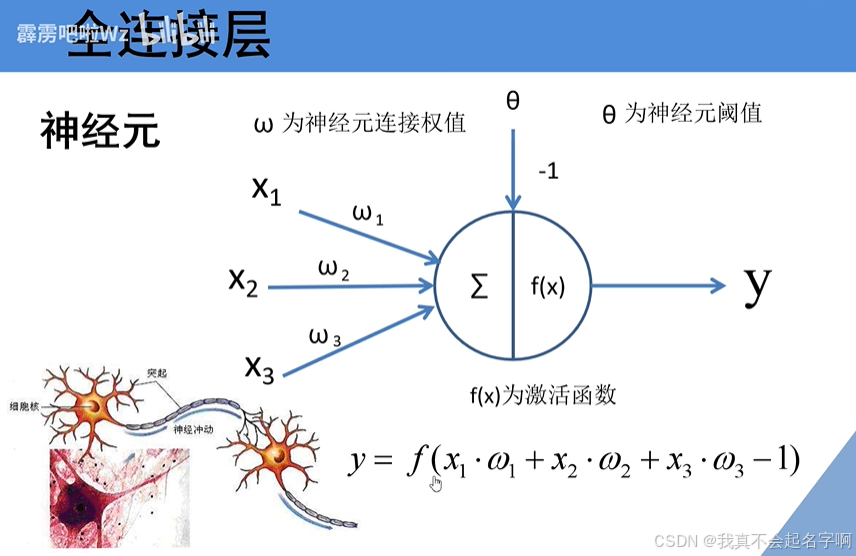
完全连接的图层如何工作
全连接层中的每个神经元都连接到前一层中的每个神经元。全连接层的输出是使用线性变换和激活函数计算的:
![]()
其中:
-
W是权重矩阵,
-
x是输入向量(平坦化特征图),
-
B是偏置项。
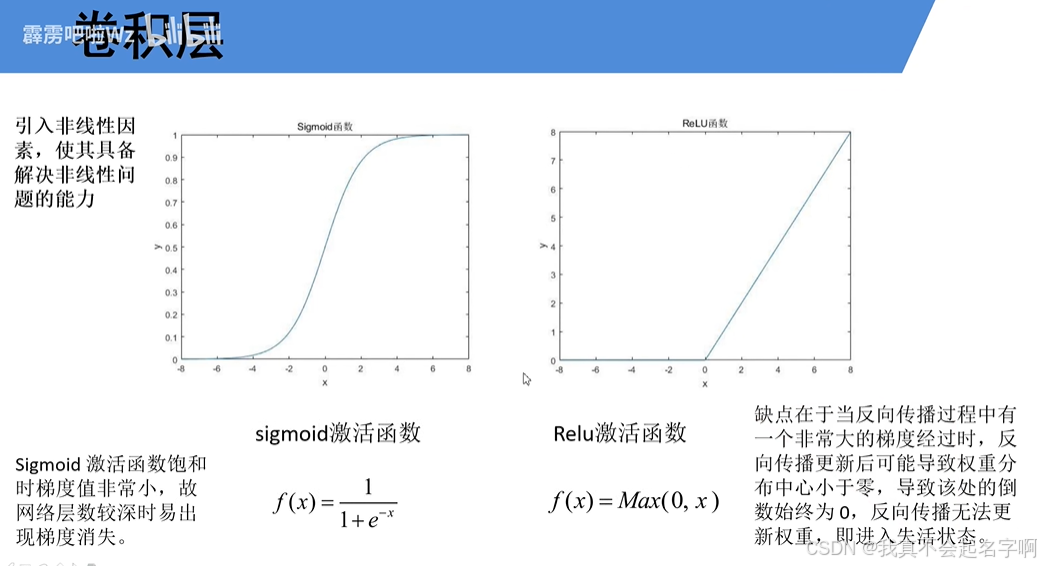
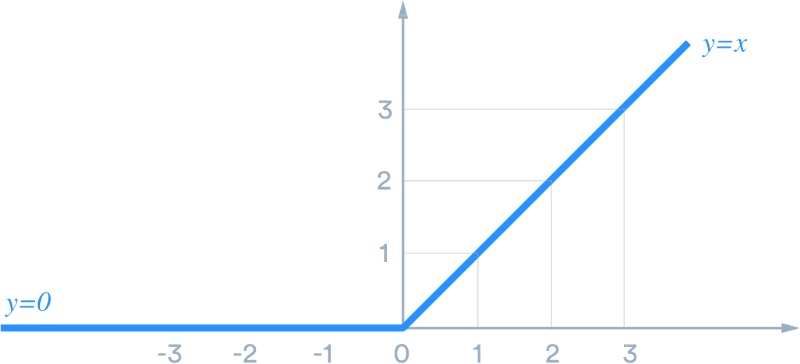
结果通过激活函数(例如,ReLU、softmax)引入非线性并产生最终输出。
示例:具有128个神经元的全连接层
假设最后一个池化层的输出是一个4×4×64张量(高度= 4,宽度= 4,深度= 64)。在将其馈送到全连接层之前,张量被展平为大小为4×4×64=1024的一维向量。如果全连接层具有128个神经元,则权重矩阵W将具有128×1024的维度,并且偏置向量B将具有128个元素。
全连接层中第一个神经元的计算如下:
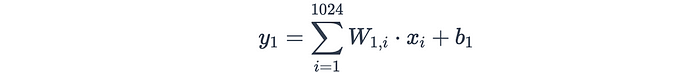
对所有128个神经元重复该过程以产生输出向量。
分类中的作用
在分类任务中,最终的全连接层通常使用softmax激活函数来输出每个类别的概率。例如,在一个10类图像分类问题中,softmax层会生成10类的概率分布:
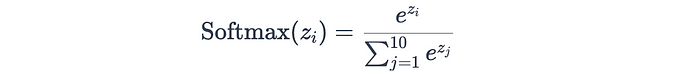
其中z_i是类别i的logit(原始分数)。
为什么全连接层很重要
全连接层集成了卷积层和池化层提取的分层特征,以理解数据。虽然卷积层专注于局部模式,但全连接层提供了全局视图,使网络能够做出明智的预测。
通过了解池化和全连接层的工作原理,您可以全面了解CNN如何将原始像素数据转换为有意义的预测。池化层降低了维度并强调了关键特征,而全连接层联合收割机结合了这些特征来解决分类或回归等特定任务。它们共同构成了现代深度学习架构的支柱。
3:使用PyTorch构建CNN
3.1、配置环境
在深入研究代码之前,请确保您的开发环境已正确设置。安装必要的库:
# Install PyTorch (if not already installed)
!pip install torch torchvision matplotlib
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
import matplotlib.pyplot as plt
3.2、准备数据
下一步是加载和预处理数据集。在这个例子中,我们将使用CIFAR-10数据集,它由10个类中的60,000个32 x32彩色图像组成,每个类6,000个图像。我们将像素值归一化为范围[-1,1],并将数据分为训练集和测试集。
# Define data transformations
transform = transforms.Compose([
transforms.ToTensor(), # Convert images to PyTorch tensors
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)) # Normalize pixel values to [-1, 1]
])
# Load CIFAR-10 dataset
train_dataset = datasets.CIFAR10(root='./data', train=True, download=True, transform=transform)
test_dataset = datasets.CIFAR10(root='./data', train=False, download=True, transform=transform)
# Create data loaders for batching and shuffling
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=64, shuffle=True)
test_loader = torch.utils.data.DataLoader(test_dataset, batch_size=64, shuffle=False)
-
transforms.ToTensor():将PIL图像或NumPy数组转换为PyTorch张量。 -
Normalize():使用均值和标准差对张量进行归一化。这有助于在训练过程中更快地收敛。 -
DataLoader:处理数据的重排序和混洗。
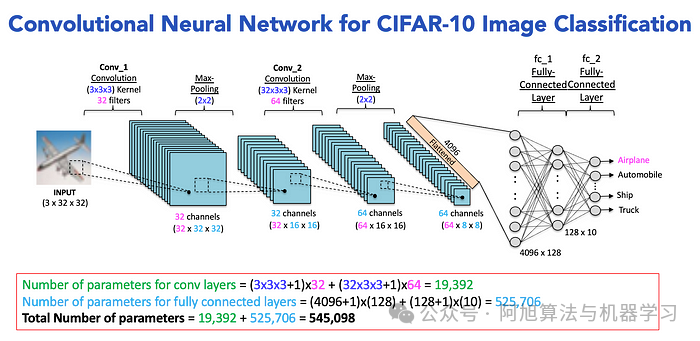
3.3、构建CNN模型
现在,让我们定义CNN的架构。典型的CNN由卷积层、池化层和全连接层组成。下面是一个简单的CNN架构的例子:
# Define the CNN Model
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
# Convolutional Layer 1: Input channels = 3 (RGB), Output channels = 32, Kernel size = 3x3
self.conv1 = nn.Conv2d(3, 32, kernel_size=3, stride=1, padding=1)
# Max Pooling Layer: Reduces spatial dimensions by half
self.pool = nn.MaxPool2d(kernel_size=2, stride=2)
# Convolutional Layer 2: Input channels = 32, Output channels = 64, Kernel size = 3x3
self.conv2 = nn.Conv2d(32, 64, kernel_size=3, stride=1, padding=1)
# Fully Connected Layer 1: Input size = 64 * 8 * 8, Output size = 128
self.fc1 = nn.Linear(64 * 8 * 8, 128)
# Fully Connected Layer 2: Output size = 10 (for 10 classes)
self.fc2 = nn.Linear(128, 10)
def forward(self, x):
# Apply first convolutional layer followed by ReLU activation and max pooling
x = self.pool(torch.relu(self.conv1(x)))
# Apply second convolutional layer followed by ReLU activation and max pooling
x = self.pool(torch.relu(self.conv2(x)))
# Flatten the tensor for the fully connected layer
x = x.view(-1, 64 * 8 * 8)
# Apply fully connected layer 1 with ReLU activation
x = torch.relu(self.fc1(x))
# Apply fully connected layer 2 (output layer)
x = self.fc2(x)
return x
# Instantiate the model
model = CNN()
print(model)
-
卷积层(
nn.Conv2d):从输入图像中提取特征。 -
Pooling Layers(
nn.MaxPool2d):减少特征映射的空间维度。 -
全连接层(
nn.线性):基于提取的特征执行分类。 -
ReLU激活:在模型中引入非线性。
3.4、定义模型
在定义了模型架构之后,我们需要指定损失函数、优化器和评估指标。
# Define the loss function and optimizer
criterion = nn.CrossEntropyLoss() # Cross-Entropy Loss for multi-class classification
optimizer = optim.Adam(model.parameters(), lr=0.001) # Adam optimizer with learning rate 0.001
-
nn.CrossEntropyLoss():将nn.LogSoftmax()和nn.NLLLoss()组合在一个类中。它通常用于多类分类问题。 -
optim.Adam():一种自适应学习率优化算法,广泛用于深度学习。
3.5、训练模型
现在,让我们使用训练数据训练模型,并评估其在测试集上的性能。我们还将在训练期间监测损失。
# Train the model
num_epochs = 10
for epoch in range(num_epochs): # Loop over the dataset multiple times
running_loss = 0.0
for i, data in enumerate(train_loader, 0):
inputs, labels = data
# Zero the parameter gradients
optimizer.zero_grad()
# Forward pass
outputs = model(inputs)
loss = criterion(outputs, labels)
# Backward pass and optimization
loss.backward()
optimizer.step()
# Print statistics
running_loss += loss.item()
if i % 100 == 99: # Print every 100 mini-batches
print(f'Epoch {epoch + 1}, Batch {i + 1}, Loss: {running_loss / 100:.3f}')
running_loss = 0.0
print('Finished Training')
-
Forward Pass:计算给定输入数据的模型输出。
-
反向传递:计算损失相对于模型参数的梯度。
-
优化步骤:使用计算的梯度更新模型参数。
3.6、评估模型
最后,让我们在测试数据集上评估经过训练的模型,以衡量其准确性。
# Evaluate the model on the test set
correct = 0
total = 0
with torch.no_grad(): # Disable gradient computation for evaluation
for data in test_loader:
images, labels = data
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print(f'Accuracy of the model on the test set: {100 * correct / total:.2f}%')
# Accuracy of the model on the test set: 70.78%
-
max():返回指定维度沿着最大值的索引,该维度对应于预测类。 -
准确度计算:将预测标签与真实标签进行比较,以计算准确度。
3.7、可视化结果
import numpy as np
import matplotlib.pyplot as plt
import torchvision
# Function to unnormalize and display images
def imshow(img):
img = img / 2 + 0.5 # Unnormalize
npimg = img.numpy()
plt.imshow(np.transpose(npimg, (1, 2, 0)))
plt.show()
# Get some random test images
dataiter = iter(test_loader)
images, labels = next(dataiter) # Use Python's built-in next() function
# Display images
imshow(torchvision.utils.make_grid(images))
# Predict the labels
outputs = model(images)
_, predicted = torch.max(outputs, 1)
print('Predicted:', ' '.join(f'{predicted[j]}' for j in range(4)))
4、提高模型性能
4.1:数据增强
数据增强是一种通过对输入图像应用随机变换来人为增加训练数据集的大小和多样性的技术。这有助于模型更好地泛化,将其暴露给更广泛的数据,而不需要额外的标记示例。
以下是如何使用PyTorch实现数据增强:
# Define data augmentation transformations
transform = transforms.Compose([
transforms.RandomHorizontalFlip(p=0.5), # Randomly flip images horizontally
transforms.RandomRotation(10), # Randomly rotate images by up to 10 degrees
transforms.RandomResizedCrop(32, scale=(0.8, 1.0)), # Randomly crop and resize images
transforms.ToTensor(), # Convert images to PyTorch tensors
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)) # Normalize pixel values
])
# Load CIFAR-10 dataset with augmented data
train_dataset = datasets.CIFAR10(root='./data', train=True, download=True, transform=transform)
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=64, shuffle=True)
-
RandomHorizontalFlip:以给定概率水平随机翻转图像(例如,50%)。 -
随机旋转:在指定范围内以随机角度旋转图像。 -
RandomResizedCrop:随机裁剪和调整图像大小,引入比例和纵横比的可变性。
这些转换确保模型不会过度拟合训练数据的特定特征,使其对真实世界图像的变化更加鲁棒。
4.2:Dropout
Dropout是一种正则化技术,它随机地“丢弃”(即,使神经元失活)。这可以防止网络变得过于依赖特定的神经元,从而减少过度拟合并提高泛化能力。
class CNNWithDropout(nn.Module):
def __init__(self):
super(CNNWithDropout, self).__init__()
# Convolutional layers
self.conv1 = nn.Conv2d(3, 32, kernel_size=3, stride=1, padding=1)
self.pool = nn.MaxPool2d(kernel_size=2, stride=2)
self.conv2 = nn.Conv2d(32, 64, kernel_size=3, stride=1, padding=1)
# Fully connected layers
self.fc1 = nn.Linear(64 * 8 * 8, 128)
self.fc2 = nn.Linear(128, 10)
# Dropout layer
self.dropout = nn.Dropout(p=0.5) # Dropout with 50% probability
def forward(self, x):
x = self.pool(torch.relu(self.conv1(x)))
x = self.pool(torch.relu(self.conv2(x)))
x = x.view(-1, 64 * 8 * 8) # Flatten the tensor
x = torch.relu(self.fc1(x))
x = self.dropout(x) # Apply dropout before the final layer
x = self.fc2(x)
return x
model = CNNWithDropout()
-
nn.Dropout(p=0.5):在训练期间随机将50%的元素归零。删除层通常在完全连接的层之后应用。 -
有效性:Dropout有助于防止神经元的共同适应,确保网络学习更强大的特征。
4.3:批量标准化
批量规范化(BatchNorm)将输入转换为每个层,稳定和加速训练过程。它减少了内部协变量移位,这种移位发生在训练过程中输入层的分布发生变化时。
以下是如何将批量归一化集成到CNN中:
class CNNWithBatchNorm(nn.Module):
def __init__(self):
super(CNNWithBatchNorm, self).__init__()
# Convolutional layers with batch normalization
self.conv1 = nn.Conv2d(3, 32, kernel_size=3, stride=1, padding=1)
self.bn1 = nn.BatchNorm2d(32) # BatchNorm after first convolutional layer
self.pool = nn.MaxPool2d(kernel_size=2, stride=2)
self.conv2 = nn.Conv2d(32, 64, kernel_size=3, stride=1, padding=1)
self.bn2 = nn.BatchNorm2d(64) # BatchNorm after second convolutional layer
# Fully connected layers
self.fc1 = nn.Linear(64 * 8 * 8, 128)
self.fc2 = nn.Linear(128, 10)
def forward(self, x):
x = self.pool(torch.relu(self.bn1(self.conv1(x)))) # Apply BatchNorm after conv1
x = self.pool(torch.relu(self.bn2(self.conv2(x)))) # Apply BatchNorm after conv2
x = x.view(-1, 64 * 8 * 8) # Flatten the tensor
x = torch.relu(self.fc1(x))
x = self.fc2(x)
return x
model = CNNWithBatchNorm()
-
nn.BatchNorm2d(num_features):将批量归一化转换为2D特征图。它跨批次维度规范化激活。 -
好处:批量归一化提高了训练稳定性,允许更高的学习率,并减少了对仔细权重初始化的需求。
4.4:迁移学习
迁移学习利用预先训练的模型(如ResNet,VGG或Inception),这些模型已经在ImageNet等大型数据集上训练过。通过根据您的特定任务对这些模型进行微调,即使数据有限,您也可以实现高性能。
下面是一个使用预训练的ResNet-18模型进行迁移学习的例子:
import torchvision.models as models
# Load a pre-trained ResNet-18 model
pretrained_model = models.resnet18(pretrained=True)
# Freeze all layers except the final fully connected layer
for param in pretrained_model.parameters():
param.requires_grad = False
# Replace the final fully connected layer for our specific task (10 classes)
num_ftrs = pretrained_model.fc.in_features
pretrained_model.fc = nn.Linear(num_ftrs, 10)
# Move the model to GPU if available
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
pretrained_model = pretrained_model.to(device)
# Define loss function and optimizer
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(pretrained_model.fc.parameters(), lr=0.001)
-
冻结层: 通过冻结预先训练的层,我们可以防止它们在训练过程中被更新,从而使我们能够专注于微调最终层。
-
微调: 冻结后,我们将最终的全连接层替换为针对特定分类任务定制的新层。
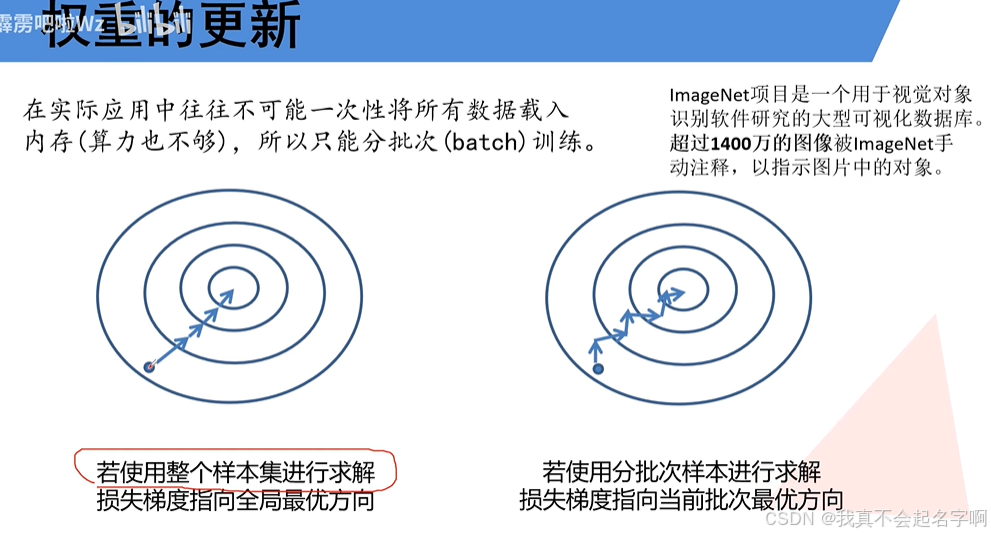
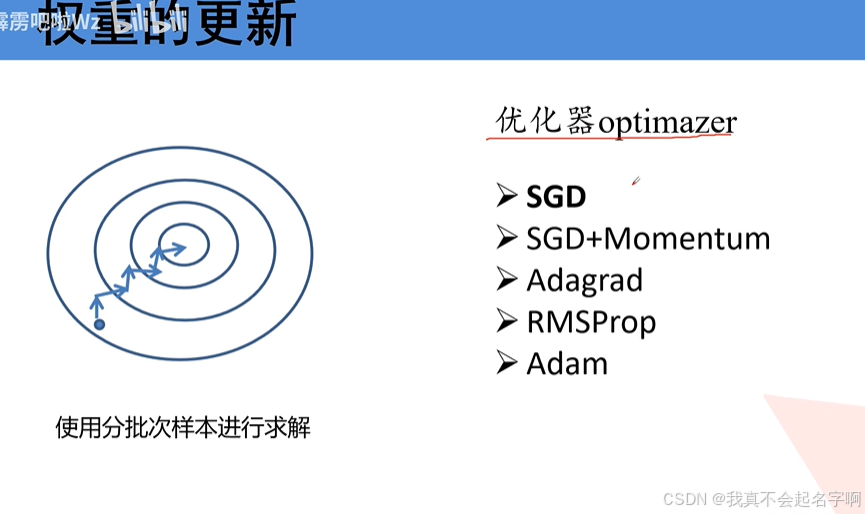
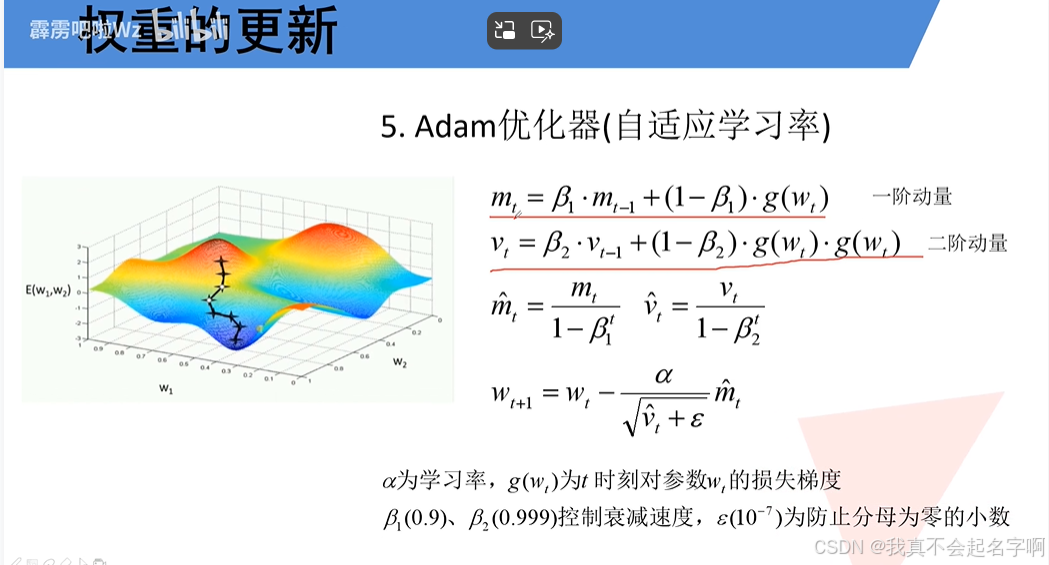
5、补充:



















 786
786

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









