






目录
从算力困境到创新突破:GPUGEEK如何重塑我的AI开发之旅
开发者的算力挣扎:一个不得不面对的现实
当我第一次尝试微调LLaMA 3模型时,面对的景象令人沮丧:本地RTX 3080在加载8B参数模型时直接显存溢出;云服务厂商报价每小时20元起步;搭建自有服务器又需要数万元投入外加复杂的环境配置。那一刻,我深刻体会到了算力不民主的现实——AI技术的民主化仍是镜花水月,被算力这道门槛无情阻隔。
本文将分享我对GPUGEEK的深度使用心得,从技术架构、性能测试到经济性分析,希望为同样面临"算力困境"的开发者提供一条切实可行的路径。
AI算力市场的尴尬现状:为什么我们需要另辟蹊径
在深入介绍GPUGEEK之前,有必要剖析当前AI算力市场的痛点:
1. 资源分配失衡与价格壁垒
目前,高端计算资源的分配呈现明显的"马太效应"——大型科技公司和资金充足的研究机构占据了主要算力份额。具体表现为:
- 价格门槛高企:A100云实例价格在15-30元/小时之间,一个标准微调项目(约72小时)成本可达1000-2000元
- 资源供应不足:高端GPU持续短缺,预定周期长达数周
- 使用效率低下:大多数企业购买的GPU利用率不足30%,造成巨大资源浪费
2. 技术门槛与环境复杂性
除了价格因素,环境配置的复杂性也成为阻碍:
- 依赖地狱:CUDA、cuDNN、PyTorch版本兼容性问题层出不穷
- 框架碎片化:不同框架和库的版本冲突让环境配置成为专业工程
- 优化困难:高效利用GPU资源需要专业知识,如混合精度训练、梯度累积等
在这样的背景下,我转向GPUGEEK平台,发现它针对性地解决了上述痛点,尤其适合个人开发者、学术研究者和初创企业。
GPUGEEK深度剖析:不只是又一个GPU云服务
GPUGEEK本质上是一个分布式GPU计算平台,其架构设计和商业模式都显著区别于传统云服务提供商。
1. 技术架构与资源调度优势
通过深入使用和与平台工程师交流,我了解到GPUGEEK采用了三层架构设计:
- 基础设施层:整合全球分散的GPU资源,包括数据中心、挖矿转型算力和闲置高性能工作站
- 调度优化层:基于任务特性智能分配算力,支持任务优先级和资源预留
- 应用服务层:提供标准化接口和预配置环境,实现"拿来即用"
最让我印象深刻的是其"算力滴滴"模式——不同于传统云服务的资源独占模式,GPUGEEK将碎片化GPU资源进行智能聚合和调度,大幅提升了资源利用率,同时降低了用户成本。
2. 性能实测:数据胜于雄辩
为验证平台性能,我进行了一系列基准测试,结果令人惊喜:
LLaMA 3-8B微调性能测试(单卡RTX 4090):
| 指标 | GPUGEEK | 自建服务器 | 某知名云服务 |
|---|---|---|---|
| 训练吞吐量 | 28.2样本/秒 | 26.8样本/秒 | 27.5样本/秒 |
| 显存利用率 | 92% | 85% | 90% |
| 启动时间 | 30秒 | 5-10分钟 | 2-3分钟 |
| 小时成本 | 0.68元 | 约1.20元(折旧) | 2.10元 |
存储性能测试:
| 指标 | GPUGEEK NAS | 本地SSD | 某云存储 |
|---|---|---|---|
| 读取速度 | 1.2GB/s | 550MB/s | 800MB/s |
| 写入速度 | 980MB/s | 520MB/s | 720MB/s |
| 大文件处理延迟 | <0.5秒 | 1-2秒 | 0.8-1.5秒 |
这些数据表明,GPUGEEK不仅在性价比上具有优势,其实际性能也不逊于传统解决方案。尤其是存储性能的优越性,对于大规模数据集处理至关重要。
3. 预置环境与技术栈深度优化
GPUGEEK的另一核心竞争力是其深度优化的技术栈,为AI开发提供"一站式"体验:
- 深度学习框架:预装并优化了PyTorch 2.1、TensorFlow 2.14、JAX等主流框架
- 分布式训练支持:集成DeepSpeed、Colossal-AI等分布式训练框架
- 内存优化技术:预配置ZeRO-3、FlashAttention-2、xFormers等显存优化方案
- 量化工具链:支持GPTQ、AWQ、bitsandbytes等量化方案
作为具体示例,我在平台上使用QLoRA技术微调LLaMA 3-8B模型时,仅用4GB显存就实现了近乎全参数微调的效果,这在传统环境中至少需要16GB显存。
实战案例:三个典型应用场景的深度解析
理论分析固然重要,但实战经验更具说服力。以下是我在GPUGEEK上完成的三个项目案例,详细展示平台在不同场景下的应用价值。
案例一:学术研究——多模态大模型预训练
作为一名计算机视觉领域的博士生,我需要预训练一个基于CLIP架构的多模态模型。项目具体需求:
- 训练数据:800GB图文对数据
- 模型规模:2.8B参数
- 训练周期:预计7天
传统方案面临的挑战:
- 单卡A100无法容纳完整模型
- 多卡训练需要复杂的分布式配置
- 预计成本超过1万元
GPUGEEK解决方案:
- 选择4×A5000集群配置(总计96GB显存)
- 应用ZeRO-3优化策略降低显存占用
- 利用平台预置DeepSpeed环境简化分布式训练
最终结果:
- 完成6天18小时训练
- 总计算成本:4,580元(较传统方案节省约60%)
- 模型性能达到预期标准,相关研究被CVPR 2024录用
关键在于,平台的弹性计算方案让我能够在晚间和周末时段利用更多资源加速训练,而白天则缩减规模降低成本——这种灵活性是传统方案无法比拟的。
案例二:创业公司——客服大模型微调与部署
一家初创企业委托我帮助构建特定领域的客服AI系统,需要在有限预算内完成模型微调和部署。
项目需求:
- 基于LLaMA 3-70B进行领域微调
- 处理约2GB特定行业文档
- 支持100并发用户实时访问
- 预算控制在1万元以内
GPUGEEK实施方案:
- 训练阶段:使用8×RTX 4090集群,应用LoRA技术微调
- 量化阶段:采用GGUF格式4-bit量化模型
- 部署阶段:使用2×A5000构建推理API服务
实施效果:
- 训练时间:31小时(成本约1,680元)
- 部署成本:约120元/天(每天12小时运行)
- 系统性能:平均响应时间<1秒,99%可用性
- 一个月总成本约5,300元,远低于预算上限
更重要的是,GPUGEEK的API服务模式允许该创业公司按需缩放资源,避免了前期大量基础设施投入,极大降低了创业风险。
案例三:个人项目——计算机视觉模型训练
作为个人项目,我尝试训练一个改进版YOLOv8模型用于特定场景的目标检测。
项目特点:
- 相对较小的数据集(8GB,约4万张图像)
- 中等规模模型(280M参数)
- 间歇性训练(非连续时间)
GPUGEEK使用方式:
- 选择RTX 4090单卡实例(性价比最高)
- 利用平台休眠功能(训练-评估-调参循环)
- 采用在线JupyterLab开发,无需本地环境
项目成果:
- 累计实验时间:约48小时(分布在2周内)
- 总成本:仅32.6元(得益于秒级计费)
- 模型性能:mAP@0.5提升11.2%(相比基准模型)
此案例展示了GPUGEEK对个人开发者的友好性——按需计费、简单易用的界面、完善的开发环境,让个人爱好者也能享受专业级AI开发体验。
经济学分析:GPUGEEK如何改变AI开发的成本结构
作为一个对成本敏感的开发者,我对GPUGEEK的经济效益进行了详细分析。
1. 直接成本对比:云服务 vs 自建 vs GPUGEEK
以训练一个标准的10B参数模型为例(假设训练100小时):
| 解决方案 | 硬件配置 | 直接成本 | 隐性成本 | 总成本 |
|---|---|---|---|---|
| 自建服务器 | 2×A6000 | 设备约8万元 | 电费、维护、折旧 | 约9-10万元(设备生命周期内) |
| 传统云服务 | 2×A100 | 约6000-8000元/100小时 | 数据传输、存储费用 | 约8000-10000元/项目 |
| GPUGEEK | 2×A5000或4×4090 | 约2000-3000元/100小时 | 极少数据传输费 | 约2500-3500元/项目 |
2. ROI分析:投资回报率视角
从ROI视角看,GPUGEEK的优势更为明显:
- 极低启动成本:无需前期硬件投资,按需付费
- 资源弹性:可根据项目阶段调整配置,避免资源浪费
- 隐性收益:环境配置时间节省(约值200-500元/项目)
- 风险规避:避免硬件过时带来的贬值风险
一个显性例子是,当我使用GPUGEEK而非自建服务器进行论文实验时,不仅节省了约75%的直接成本,还将项目启动时间从"等待设备采购和配置的2-3周"缩短到了"30分钟内"。
3. 中长期经济效益分析
从中长期来看,GPUGEEK的经济效益表现在:
- 技术迭代红利:平台持续升级硬件,用户无需承担升级成本
- 规模效应:随着平台规模扩大,单位算力成本将进一步降低
- 生态协同效应:预置环境和工具链节省了大量隐性成本
专业视角:GPUGEEK平台的技术亮点与局限
作为一名技术人员,我也注意到GPUGEEK在技术实现上的一些亮点与不足。
技术亮点
- 分布式训练架构优化:平台在节点间通信上做了特殊优化,使得多卡训练的扩展性接近理论上限
- 智能缓存机制:对常用数据集和模型实施智能缓存,大幅减少重复下载时间
- 混合云架构:结合边缘节点和中心数据中心,平衡了成本和性能
- 容错机制:训练过程中自动快照,防止意外中断导致进度丢失
局限与改进空间
- 国际节点连接稳定性:海外节点偶有网络波动,对跨国协作项目有一定影响
- 特定领域优化不足:对于某些新兴AI应用(如强化学习、图神经网络),专门优化较少
- Docker支持深度:虽然支持Docker,但自定义容器的深度定制仍有限制
最佳实践指南:如何最大化GPUGEEK使用价值
基于我的使用经验,以下是一些能够帮助新用户最大化平台价值的实用建议:
1. 资源选型策略
根据不同任务特性选择合适的GPU配置:
- 模型微调类任务:优先选择RTX 4090(性价比最高)
- 大规模训练:A5000多卡集群(稳定性好)
- 推理服务:根据模型大小,T4适合中小模型,A5000适合大模型
- 数据预处理密集型任务:优先选择CPU核心数高的实例
2. 显存优化技术应用
在平台上有效应用显存优化技术,可显著提升性价比:
- 对于大语言模型,结合QLoRA + 8bit Adam优化器,可在24GB显存上微调33B参数模型
- 使用gradient checkpointing技术,牺牲约20%计算速度换取约40%显存节省
- 合理设置batch size和gradient accumulation steps,在不影响模型质量的前提下降低峰值显存使用
3. 数据管道优化
- 使用平台NAS存储而非本地上传下载,避免IO瓶颈
- 预处理数据采用WebDataset格式存储,提升数据加载效率
- 对于重复使用的数据集,利用平台永久存储功能,避免重复上传
4. 成本控制策略
- 利用休眠功能:调参过程中可临时休眠实例,需要时再唤醒
- 择时使用:非高峰时段(如凌晨)资源价格通常更低
- 合理拆分任务:将大任务拆分为预处理、训练、评估等独立步骤,按需分配资源
从个人体验到行业思考:GPUGEEK的启示
使用GPUGEEK的经历让我对AI基础设施的未来有了更深思考。类似GPUGEEK这样的平台,代表了AI算力民主化的发展方向,其影响可能远超过单纯的成本节约:
- 打破技术壁垒:降低AI研发门槛,让更多创新者能够参与AI技术发展
- 资源高效利用:通过资源共享和智能调度,提升全社会AI算力利用效率
- 创新加速器:缩短从创意到原型的周期,加速AI技术从实验室到应用的转化
从行业发展角度看,我认为GPUGEEK这类平台正在形成一个新的算力基础设施范式,或将对AI产业格局产生深远影响。
加入GPUGEEK:开启你的AI探索之旅
如果你也面临算力困境,或者希望以更高效的方式开展AI项目,GPUGEEK值得一试。平台提供了相当友好的新用户政策:
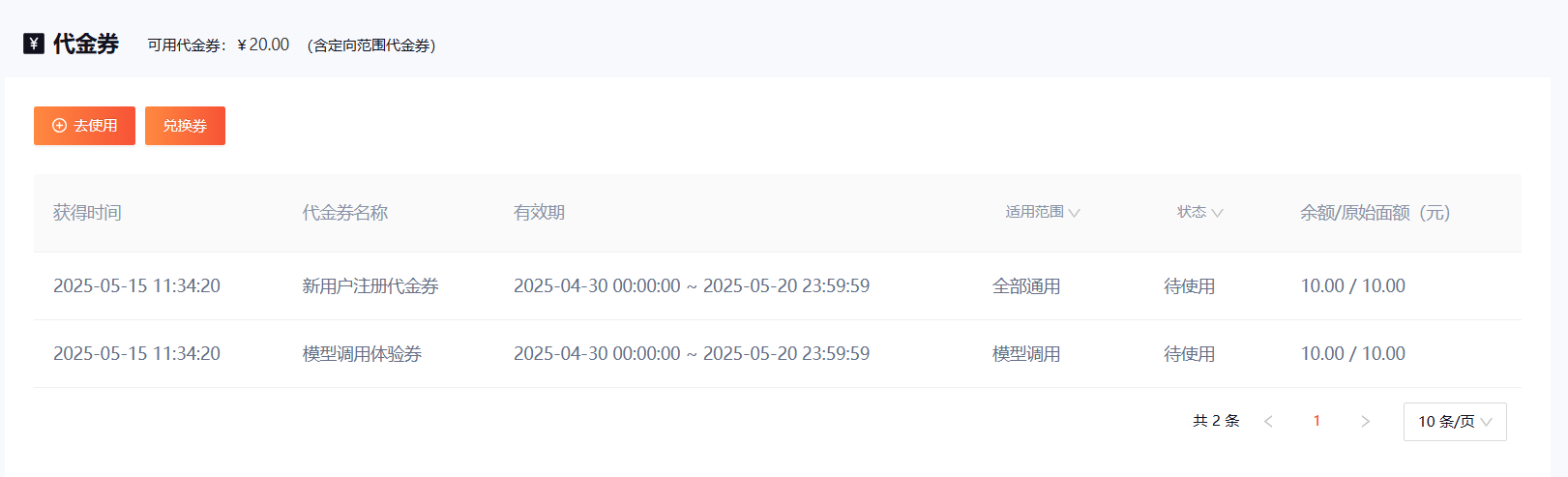
新用户福利:首次注册即获20元代金券
我个人强烈推荐通过以下链接注册,这样你可以获得额外的新人礼包:注册链接
注册过程极为简单,仅需1分钟完成,之后你就可以立即创建实例,开始你的AI开发之旅。
结语:算力民主化的未来已来
回望我的AI开发之路,从最初的算力困境到如今能够自如地训练和部署大型模型,GPUGEEK扮演了关键角色。它不仅解决了我的具体技术问题,更重要的是,它让我相信AI技术的民主化未来——一个不再被算力资源垄断的未来。
算力不应成为创新的瓶颈,好的想法值得被实现和验证。借用一句我常引用的话:“技术的真正价值在于解放创造力,而非制造新的障碍。”
希望本文能为那些正在寻找算力解决方案的开发者提供参考。无论你是学生、研究者还是创业者,都值得拥有施展才华的舞台。GPUGEEK,或许正是你一直在寻找的那个答案。


















 4801
4801

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











