





| Pandas-Series对象详细总结 | ||||
| 格式 | 含义 | 举例 | 结果 | |
| 创建 | 包名.Series() | 创建Series对象 | (1)传入列表 s1=pd.Series([1,2,3]) (2)传入元组 s1=pd.Series((1,2,3)) (3)传入字典 s1=pd.Series({'a':1,'b':2,'c':3)) 传入列表和元组的时候里面可以指定索引列格式为index=['a','b','c'] | (1)和(2)的 结果为: 0 1 1 2 2 3 (3)结果为:a 1 b 2 c 3 |
| Series 常用 属性 | 对象.loc | 根据(索引列)行索引值取一行数据 但是以列的形式表示出来。 第一列为原来的列名,第二列为对应的一行数据,并会打印行索引值以及行索引值的类型 | 可以读取一个csv的文件,这里举例我这里的文件, 文件为: nid name age A 1 温蒂 15 B 2 纳兹 19 C 3 露西 19 D 4 格雷 19 读取操作为:import pandas as pd 读取csv文件的数据,并设置id列为: 索引 data_df =pd.read_csv('/export/data/friends.csv', index_col='id') print(data_df.loc[A]) | 结果为: nid 1 name 温蒂 age 15 Name: A, dtype: object |
| 对象.iloc | 根据行号取一行数据, 也是会用列的形式打印出来,结果同loc属性打印的结果一样 | 承上例data_df的文件数据 print(data_df.iloc[0]),行号就相当于每行数据的索引值,第一行数据的索引值为0 | 结果为: nid 1 name 温蒂 age 15 Name: A, dtype: object | |
| 对象.dtype或dtypes | 查看Series对象的元素类型, 这两个都可以使用 | 我这里就使用data_df.iloc[0]这个数据来看它的数据类型 格式为:print(data_df.iloc[0].dtype) | 结果为:object 表示: 字符串的意思 | |
| 对象.shape | 数据的维度 | print(data_df.iloc[0].shape) | 结果为:(3,) 三行一列,但1通常不显示 | |
| 对象.size | 获取Series元素的数量 | print(data_df.iloc[0].size) | 结果为:3 | |
| 对象.values | 获取Series对象所有的值,也就是 那一行的数据 | print(data_df.iloc[0].values) | 结果为:[1 '温蒂' 15] | |
| 对象.index | 获取Series所有的索引值,也就是获取列名,并输出列名类型 | print(data_df.iloc[0].index) | 结果为: Index(['nid', 'name', 'age'], dtype='object') | |
| Series 常用 方法 | len(对象) | 查看Series对象值的数量(同属性里的size)作用相同 | s2 = pd.Series(data = [2, 2, 4, 4, 5, 7], index=['A', 'B', 'C', 'D', 'E', 'F']) print(len(s2)) | 结果为:6 |
| 对象.sort_values() | 对值进行排序 | print(s2.sort_values()) print(s2.sort_values(ascending=True)) 效果同上. print(s2.sort_values(ascending=False)) # 降序 | 结果为: 升序: 降序: A 2 F 7 B 2 E 5 C 4 D 4 D 4 C 4 E 5 B 2 F 7 A 2 dtype: int64 dtype: int64 | |
| 对象.sort.index() | 对行索引进行排序 | print(s2.sort_index()) print(s2.sort_index(ascending=True)) 效果同上. print(s2.sort_index(ascending=False)) # 降序 | 结果为: 升序: A 2 B 2 C 4 D 4 E 5 F 7 dtype: int64 | |
| 对象.to_list()/tolist() | 把Series转换为列表 | print(s2.to_list()) | 结果为: [2, 2, 4, 4, 5, 7] | |
| 对象.to_frame() | 把Series转换为DataFrame | print(s2.to_frame()) | 结果为: 0 A 2 B 2 C 4 D 4 E 5 F 7 | |
| 对象.count() | 计数: 只统计非null值 | print(s2.count()) | 结果为:6 | |
| 对象.value_counts() | 分组统计不同值数量,并打印类型 | print(s2.value_counts()) | 结果为: 4 2 2 2 7 1 5 1 dtype: int64 | |
| 对象.keys() | 获取索引值,和属性里的index 的作用相同 | print(s2.keys()) | 结果为: Index(['A', 'B', 'C', 'D', 'E', 'F'], dtype='object') | |
| 对象.sum() | 求和 | print(s2.sum()) | 结果为:24 | |
| 对象.min() | 返回最小值 | print(s2.min()) | 结果为:2 | |
| 对象.max() | 返回最大值 | print(s2.max()) | 结果为:7 | |
| 对象.mean() | 返回算术平均值 | print(s2.mean()) | 结果为:4.0 | |
| 对象.median() | 返回中位数 | print(s2.median()) | 结果为:4.0 | |
| 对象.mode() | 返回众数 | print(s2.mode()) | 结果为: 0 2 1 4 dtype: int64 | |
| 对象.quantile() | 返回指定位置的分位数 | print(s2.quantile(.5)) | 结果为:4.0 | |
| 对象.replace() | 用指定值代替Series中的值 | s2.replace(2,3,inplace=True) print(s2) | 结果为: A 3 | |
| 对象.sample() | 返回Series的随机采样值 | print(s2.sample()) | 结果为: E 5 dtype: int64 | |
| 对象.unique() | 去重返回数组 | print(s2.unique()) | 结果为:[2 4 5 7] | |
| 对象.drop_duplicates() | 返回去重之后的Series | print(s2.drop_duplicates()) | 结果为: A 2 C 4 E 5 F 7 dtype: int64 | |
| 对象.head() | 默认查看前5个值,可设置 查看的行数,并打印类型 | print(s2.head(n=3)) | 结果为: A 2 B 2 C 4 dtype: int64 | |
| 对象.tail() | 默认查看后5个值,可设置 查看的行数,并打印类型 | print(s2.tail(n=3)) | 结果为: D 4 E 5 F 7 dtype: int64 | |
| 对象.hist() | 绘制直方图 | print(s2.hist()) | 结果为: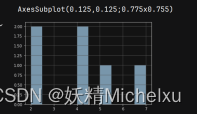 | |
| Series 布尔类型 | 可传入布尔索引,获取某一列指定的数据, 设置为True的则打印,否则不打印 | df1 = pd.DataFrame(data={ ages=df1['age']或ages=df1.age | 结果为: A 15 D 19 Name: age, dtype: int64 | |
| 也可进行检索 | df1['age'][df1['age'] > df1['age'].mean()] 或df1.age[df1.age > df1.age.mean()] | 结果为: B 19 C 19 D 19 Name: age, dtype: int64 | ||
| Series 运算 | Series和数值型变量计算, 变量会与Series中的每个元素逐一进行计算 | print(ages + 7) print(ages * 2) | 结果为: ages + 7 A 22 B 26 C 26 D 26 Name: age, dtype: int64 | |
| 两个Series对象长度一致, 对应索引的内容直接做计算即可. | print(ages + ages) | 结果为: A 30 B 38 C 38 D 38 Name: age, dtype: int64 | ||
| 两个Series对象 长度不一致, 索引匹配的就计算, 不匹配的就用NaN填充. | s3= pd.Series(data=[1, 2],index=['A','G']) print(ages + s1) | 结果为: A 16.0 B NaN C NaN D NaN G NaN dtype: float64 | ||
Pandas—Series对象:常用属性、方法、布尔类型、运算快速理解
最新推荐文章于 2024-06-16 18:20:37 发布
















 1826
1826

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









