







Pandas库介绍和Series对象基本操作
pandas介绍
pandas是一个基于numpy、专门为数据分析而设计的库,它提供了Series和DataFrame两种数据结构,分别用于处理一维和二维的数据。
创建Series对象
ser_obj = pd.Series(['Python', 'Java', 'PHP'])
print(ser_obj)
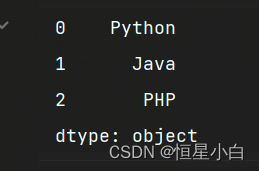
这是比较简单的创建方法,当然我们也可以指定index
ser_obj = pd.Series(data = ser_obj.values, index=['one', 'two', 'three'])
print(ser_obj)
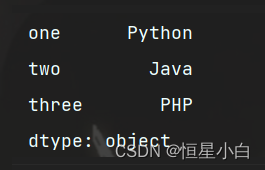
操作也十分简单,只要指定index属性就行
我们也可以通过字典来直接指定Series的data和index,字典的key最终会变为Series的index属性,而value对应data
data = {'one': 'Python', 'two': 'Java', 'three': 'PHP'}
ser_obj2 = pd.Series(data)
print(ser_obj2)
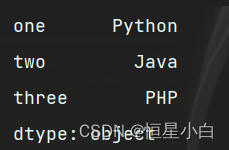
访问Series对象
一个比较简单的访问方式,我们可以直接通过索引来访问
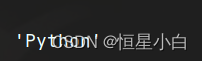
ser_obj2['one']
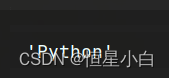
当然我们也可以访问它的整数索引
ser_obj2[0]
但实际上在pandas我们还可以通过loc或iloc来访问
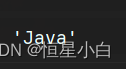
如果采用loc访问,访问的必须是自定义的索引
ser_obj2.loc['two']
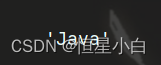
而iloc对应的就必须是自动生成的整数索引
ser_obj2.iloc[1]
Series的多层访问
有时我们遇到的数据可能不会只有一层索引,这时候我们的访问方式也要做出调整,我们先创建一个两层索引的数据
mult_series = pd.Series([95, 103, 80, 80, 90, 91, 91],
index=[['计算机专业', '计算机专业', '计算机专业', '计算机专业',
'体育专业', '体育专业', '体育专业'],
['物联网工程', '软件工程', '网络安全', '信息安全',
'体育教育', '休闲体育', '运动康复']])
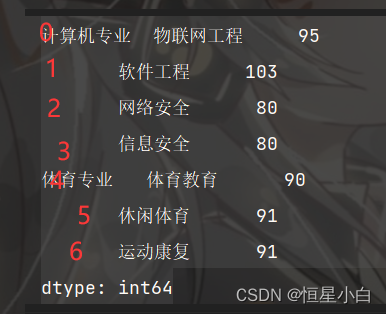
print(mult_series)

我们先用最简单的方式来访问最外层的数据
mult_series['计算机专业']
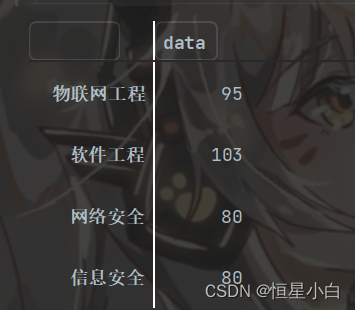
很明显我们所访问到的不只一个数据
查看数据类型
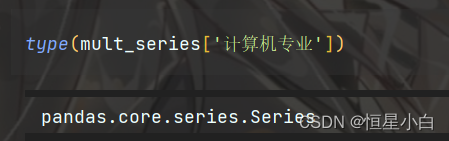
返回的是内层的Series
如果我们要精确得到一个数据也十分简单,多加一层索引就完了
mult_series['计算机专业']['网络安全']
最后返回了80,是对应课程的数据
如果我们使用的是loc和iloc其实也很简单,但是也有点区别loc可以通过多层索引的方式,但是iloc依旧只能通过访问整数索引
先来看loc
mult_series.loc['计算机专业']
这是访问最外层索引的方式

如果想访问第二层
mult_series.loc['计算机专业', '信息安全']
这样就可以实现,最后返回的80,也是对应的数据
iloc和单层用法一致,学会识别整数索引就行
排序
不管是DataFrame还是Series,都会有排序操作,排序的方式也不唯一,
我们可以根据索引来排序,或者值来排
先简单创建一个Series对象
import numpy as np
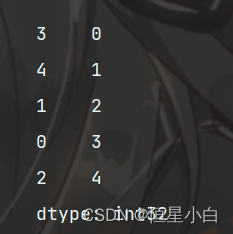
ser_obj3 = pd.Series(data = np.arange(5), index=[3, 4, 1, 0, 2])
print(ser_obj3)
我们先根据索引来排序
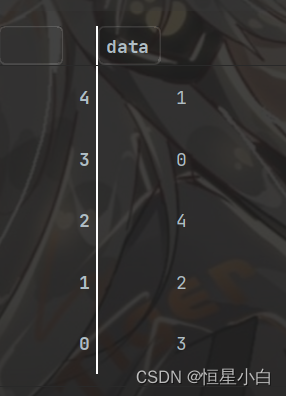
ser_obj3.sort_index()

很明显默认会按照升序来排,如果想改为降序只要将ascending属性设置为False
ser_obj3.sort_index(ascending=False)
按照值来排序也几乎是一样
ser_obj3.sort_values(ascending=False)
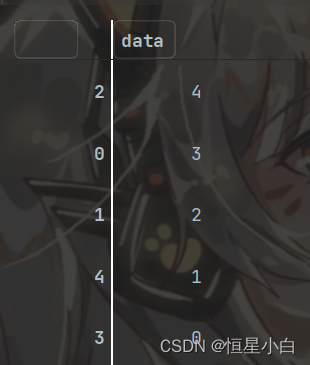
ser_obj3.sort_values()

默认也是升序
















 2943
2943











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











