







8.6 交替方向乘子法(续1)
8.6.4 应用举例
本小节给出一些交替方向乘子法的应用实例. 在实际中,大多数问题并不直接具有问题 (8.6.1) 的形式. 我们需要通过一系列拆分技巧将问题化成 ADMM 的标准形式,同时要求每一个子问题尽量容易求解. 注意,对同一个问题可能有多种拆分方式,不同方式导出的最终算法可能差异巨大,应当选择最容易求解的拆分方式.
1. LASSO 问题
LASSO 问题为
min
μ
∥
x
∥
1
+
1
2
∥
A
x
−
b
∥
2
\min\quad\mu\|x\|_1+\frac{1}{2}\|Ax-b\|^2
minμ∥x∥1+21∥Ax−b∥2
这是典型的无约束复合优化问题,将其写成 ADMM 标准问题形式:
min
x
,
z
f
(
x
)
+
h
(
z
)
s
.
t
.
x
=
z
\begin{aligned}\min_{x,z}\quad &f(x)+h(z)\\\mathrm{s.t.}\quad &x=z\end{aligned}
x,zmins.t.f(x)+h(z)x=z
其中
f
(
x
)
=
1
2
∥
A
x
−
b
∥
2
f(x) = \displaystyle\frac{1}{2}\|Ax-b\|^2
f(x)=21∥Ax−b∥2,
h
(
z
)
=
μ
∥
z
∥
1
h(z) = \mu\|z\|_1
h(z)=μ∥z∥1.
对于此问题,交替方向乘子法迭代格式为
x
k
+
1
=
arg min
x
{
1
2
∥
A
x
−
b
∥
2
+
ρ
2
∥
x
−
z
k
+
1
ρ
y
k
∥
2
2
}
=
(
A
T
A
+
ρ
I
)
−
1
(
A
T
b
+
ρ
z
k
−
y
k
)
z
k
+
1
=
arg min
z
{
μ
∥
z
∥
1
+
ρ
2
∥
x
k
+
1
−
z
+
1
ρ
y
k
∥
2
}
=
p
r
o
x
(
μ
/
ρ
)
∥
⋅
∥
1
(
x
k
+
1
+
1
ρ
y
k
)
y
k
+
1
=
y
k
+
τ
ρ
(
x
k
+
1
−
z
k
+
1
)
\begin{aligned}&x^{k+1}=\argmin_{x}\left\{\frac{1}{2}\|Ax-b\|^{2}+\frac{\rho}{2}\|x-z^{k}+\frac{1}{\rho}y^{k}\|_{2}^{2}\right\}=(A^{\mathrm{T}}A+\rho I)^{-1}(A^{\mathrm{T}}b+\rho z^{k}-y^{k})\\&z^{k+1}=\argmin_{z}\left\{\mu\|z\|_{1}+\frac{\rho}{2}\|x^{k+1}-z+\frac{1}{\rho}y^{k}\|^{2}\right\}=\mathrm{prox}_{(\mu/\rho)\|\cdot\|_{1}}\left(x^{k+1}+\frac{1}{\rho}y^{k}\right)\\&y^{k+1}=y^{k}+\tau\rho(x^{k+1}-z^{k+1})\end{aligned}
xk+1=xargmin{21∥Ax−b∥2+2ρ∥x−zk+ρ1yk∥22}=(ATA+ρI)−1(ATb+ρzk−yk)zk+1=zargmin{μ∥z∥1+2ρ∥xk+1−z+ρ1yk∥2}=prox(μ/ρ)∥⋅∥1(xk+1+ρ1yk)yk+1=yk+τρ(xk+1−zk+1)
注意,因为 ρ > 0 \rho>0 ρ>0, 所以 A T A + ρ I A^{\mathrm{T}}A+\rho I ATA+ρI 总是可逆的. x x x 迭代本质上是计算一个岭回归问题 ( ℓ 2 \ell_2 ℓ2 范数平方正则化的最小二乘问题); 而对 z z z 的更新为 ℓ 1 \ell_1 ℓ1 范数的邻近算子,同样有显式解. 在求解 x x x 迭代时,若使用固定的罚因子 ρ \rho ρ, 我们可以缓存矩阵 A T A + ρ I A^\mathrm{T}A+\rho I ATA+ρI 的初始分解,从而减小后续迭代中的计算量. 需要注意的是,在 LASSO 问题中,矩阵 A ∈ R m × n A\in\mathbb{R}^{m\times n} A∈Rm×n 通常有较多的列 (即 m ≪ n m\ll n m≪n), 因此 A T A ∈ R n × n A^\mathrm{T}A\in\mathbb{R}^{n\times n} ATA∈Rn×n 是一个低秩矩阵,二次罚项的作用就是将 A T A A^\mathrm{T}A ATA 增加了一个正定项. 该 ADMM 主要运算量来自更新 x x x 变量时求解线性方程组,复杂度为 O ( n 3 ) \mathcal{O}(n^3) O(n3) (若使用缓存分解技术或 SMW 公式则可进一步降低每次迭代的运算量).
接下来考虑 LASSO 问题的对偶问题
m
i
n
b
T
y
+
1
2
∥
y
∥
2
s
.
t
.
∥
A
T
y
∥
∞
⩽
μ
(
8.6.26
)
\begin{aligned} \mathrm{min}\quad&b^{\mathrm{T}}y+\frac{1}{2}\|y\|^{2}\\\mathrm{s.t.}\quad&\|A^{\mathrm{T}}y\|_{\infty}\leqslant\mu\end{aligned}\qquad(8.6.26)
mins.t.bTy+21∥y∥2∥ATy∥∞⩽μ(8.6.26)
将
∥
A
T
y
∥
∞
⩽
μ
\|A^\mathrm{T}y\|_\infty\leqslant\mu
∥ATy∥∞⩽μ 变成示性函数放在目标函数中,并引入约束
A
T
y
+
z
=
0
A^\mathrm{T}y+z=0
ATy+z=0, 可以得到如下等价问题:
min
b
T
y
+
1
2
∥
y
∥
2
⏟
f
(
y
)
+
I
∥
z
∥
∞
⩽
μ
(
z
)
⏟
h
(
z
)
s
.
t
.
A
T
y
+
z
=
0
(
8.6.27
)
\begin{aligned}\min\quad&\underbrace{b^{\mathrm{T}}y+\frac{1}{2}\|y\|^{2}}_{f(y)}+\underbrace{I_{\|z\|_{\infty}\leqslant\mu}(z)}_{h(z)}\\\mathrm{s.t.}\quad& A^{\mathrm{T}}y+z=0\end{aligned}\qquad(8.6.27)
mins.t.f(y)
bTy+21∥y∥2+h(z)
I∥z∥∞⩽μ(z)ATy+z=0(8.6.27)
对约束
A
T
y
+
z
=
0
A^{\mathrm{T}}y+z=0
ATy+z=0 引入乘子
x
x
x, 对偶问题的增广拉格朗日函数为
L
ρ
(
y
,
z
,
x
)
=
b
T
y
+
1
2
∥
y
∥
2
+
I
∥
z
∥
∞
⩽
μ
(
z
)
−
x
T
(
A
T
y
+
z
)
+
ρ
2
∥
A
T
y
+
z
∥
2
L_{\rho}(y,z,x)=b^{\mathrm{T}}y+\frac{1}{2}\|y\|^{2}+I_{\|z\|_{\infty}\leqslant\mu}(z)-x^{\mathrm{T}}(A^{\mathrm{T}}y+z)+\frac{\rho}{2}\|A^{\mathrm{T}}y+z\|^{2}
Lρ(y,z,x)=bTy+21∥y∥2+I∥z∥∞⩽μ(z)−xT(ATy+z)+2ρ∥ATy+z∥2
在这里故意引入符号
x
x
x 作为拉格朗日乘子,
x
x
x 恰好对应的是原始问题的自变量.
以下说明如何求解每个子问题. 当固定
y
,
x
y,x
y,x 时,对
z
z
z 的更新即向无穷范数球
{
z
∣
∥
z
∥
∞
⩽
μ
}
\{z|\|z\|_\infty\leqslant\mu\}
{z∣∥z∥∞⩽μ} 做欧几里得投影,即将每个分量截断在区间
[
−
μ
,
μ
]
[-\mu,\mu]
[−μ,μ] 中;当固定
z
,
x
z,x
z,x 时,对
y
y
y 的更新即求解线性方程组
(
I
+
ρ
A
A
T
)
y
=
A
(
x
k
−
ρ
z
k
+
1
)
−
b
(I+\rho AA^\mathrm{T})y=A(x^k-\rho z^{k+1})-b
(I+ρAAT)y=A(xk−ρzk+1)−b
因此得到 ADMM 迭代格式为
z
k
+
1
=
P
∥
z
∥
∞
⩽
μ
(
x
k
ρ
−
A
T
y
k
)
y
k
+
1
=
(
I
+
ρ
A
A
T
)
−
1
(
A
(
x
k
−
ρ
z
k
+
1
)
−
b
)
x
k
+
1
=
x
k
−
τ
ρ
(
A
T
y
k
+
1
+
z
k
+
1
)
\begin{aligned}&z^{k+1}=\mathcal{P}_{\|z\|_{\infty}\leqslant\mu}\left(\frac{x^{k}}{\rho}-A^{\mathrm{T}}y^{k}\right) \\&y^{k+1}=(I+\rho AA^{\mathrm{T}})^{-1}\Big(A(x^{k}-\rho z^{k+1})-b\Big) \\&x^{k+1}=x^{k}-\tau\rho(A^{\mathrm{T}}y^{k+1}+z^{k+1})\end{aligned}
zk+1=P∥z∥∞⩽μ(ρxk−ATyk)yk+1=(I+ρAAT)−1(A(xk−ρzk+1)−b)xk+1=xk−τρ(ATyk+1+zk+1)
虽然 ADMM 应用于对偶问题也需要求解一个线性方程组,但由于 LASSO 问题的特殊性
(
m
≪
n
)
(m\ll n)
(m≪n), 求解
y
y
y 更新的线性方程组需要的计算量是
O
(
m
3
)
\mathcal{O}(m^3)
O(m3), 使用缓存分解技巧后可进一步降低至
O
(
m
2
)
\mathcal{O}(m^2)
O(m2), 这大大小于针对原始问题的 ADMM.
对原始问题,另一种可能的拆分方法是
min
μ
∥
x
∥
1
⏟
f
(
x
)
+
1
2
∥
z
∥
2
⏟
h
(
z
)
s
.
t
.
z
=
A
x
−
b
\begin{aligned}\min\quad&\underbrace{\mu\|x\|_{1}}_{f(x)}+\underbrace{\frac{1}{2}\|z\|^{2}}_{h(z)}\\\mathrm{s.t.}\quad& z=Ax-b\end{aligned}
mins.t.f(x)
μ∥x∥1+h(z)
21∥z∥2z=Ax−b
可以写出其增广拉格朗日函数为
L
ρ
(
x
,
z
,
y
)
=
μ
∥
x
∥
1
+
1
2
∥
z
∥
2
+
y
T
(
A
x
−
b
−
z
)
+
ρ
2
∥
A
x
−
b
−
z
∥
2
L_\rho(x,z,y)=\mu\|x\|_1+\frac{1}{2}\|z\|^2+y^{\mathrm{T}}(Ax-b-z)+\frac{\rho}{2}\|Ax-b-z\|^2
Lρ(x,z,y)=μ∥x∥1+21∥z∥2+yT(Ax−b−z)+2ρ∥Ax−b−z∥2
但是如果对这种拆分方式使用 ADMM, 求解 x x x 的更新本质上还是在求解一个 LASSO 问题!这种变形方式将问题绕回了起点,因此并不是一个实用的方法.
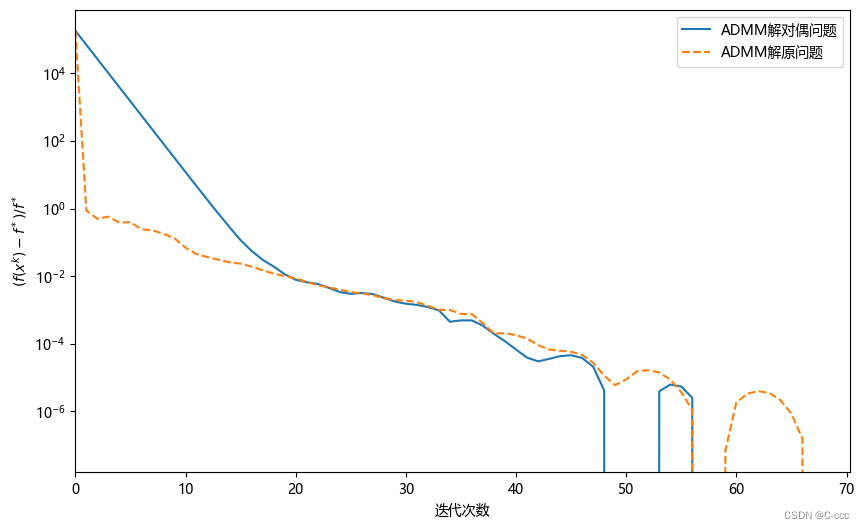
用同第 6.2 节中一样的 A A A 和 b b b, 并取 μ = 1 0 − 3 \mu=10^-3 μ=10−3, 分别使用 ADMM 求解原始问题和对偶问题,这里取 τ = 1.618 \tau=1.618 τ=1.618, 原始问题和对偶问题的参数 ρ \rho ρ 分别为 0.01 和 100, 终止条件设为 ∣ f ( x k ) − f ( x k − 1 ) ∣ < 1 0 − 8 |f(x^k)-f(x^{k-1})|<10^{-8} ∣f(xk)−f(xk−1)∣<10−8 和最大迭代步数 2000. 此外,对于原始问题的 ADMM, 我们还添加终止条件 ∥ x k − z k ∥ < 1 0 − 10 \|x^k-z^k\|<10^{-10} ∥xk−zk∥<10−10; 相应地,对于对偶问题,额外的终止条件取为 ∥ A T y k + z k ∥ < 1 0 − 10 \|A^\mathrm{T}y^k+z^k\|<10^{-10} ∥ATyk+zk∥<10−10. 算法结果见图8.9. 这里的 ADMM 没有使用连续化策略来调整 μ \mu μ, 因此可以看出 ADMM 相对其他算法的强大之处.此外,对于这个例子,求解原问题需要的迭代步数较少,但求解对偶问题每一次迭代所需要的时间更短,综合来看 ADMM 求解对偶问题时更快.
import numpy as np
import scipy.sparse as sp
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['Microsoft YaHei']
def f_prox(x, threshold):
return np.sign(x) * np.maximum(np.abs(x) - threshold, 0)
def solve_primal(A, b, mu, rho, tau, max_iter=2000, tol=1e-8):
m, n = A.shape
x = np.zeros((n, 1))
z = np.zeros((n, 1))
y = np.zeros((n, 1))
k = 0
history = []
while k < max_iter:
x_new = np.linalg.solve(A.T @ A + rho * np.eye(n), A.T @ b + rho * z - y)
z_new = f_prox(x_new + y / rho, mu / rho)
y_new = y + tau * rho * (x_new - z_new)
obj_val = mu * np.linalg.norm(x, ord=1) + 0.5 * np.linalg.norm(A @ x - b)**2
history.append(obj_val)
if k > 0 and (np.abs(history[-1] - history[-2]) < tol or np.linalg.norm(x_new - z_new) < tol):
break
x = x_new
z = z_new
y = y_new
k += 1
return history, k
def solve_dual(A, b, mu, rho, tau, max_iter=2000, tol=1e-8):
m, n = A.shape
y = np.zeros((m, 1))
z = np.zeros((n, 1))
x = np.zeros((n, 1))
k = 0
history = []
while k < max_iter:
z_new = np.maximum(np.minimum(x / rho - A.T @ y, mu), -mu)
y_new = np.linalg.solve(np.eye(m) + rho * A @ A.T, A @ (x - rho * z_new) - b)
x_new = x - tau * rho * (A.T @ y_new + z_new)
obj_val = mu * np.linalg.norm(x, ord=1) + 0.5 * np.linalg.norm(A @ x - b)**2
history.append(obj_val)
if k > 0 and (np.abs(history[-1] - history[-2]) < tol or np.linalg.norm(A.T @ y + z) < tol):
break
x = x_new
z = z_new
y = y_new
k += 1
return history, k
np.random.seed(42)
m = 512
n = 1024
A = np.random.randn(m, n)
u = sp.random(n, 1, density=0.1).toarray()
b = np.dot(A, u)
mu = 1e-3
tau = 1.618
rho_primal = 0.01
rho_dual = 100
primal_history, k_primal = solve_primal(A, b, mu, rho_primal, tau)
dual_history, k_dual = solve_dual(A, b, mu, rho_dual, tau)
plt.figure(figsize=(10, 6))
# 创建对数坐标轴的折线图
plt.semilogy((np.array(dual_history) - dual_history[-1]) / (dual_history[-1]), label='ADMM解对偶问题')
plt.semilogy((np.array(primal_history) - primal_history[-1]) / (primal_history[-1]), linestyle='--', label='ADMM解原问题')
plt.xlabel('迭代次数')
plt.ylabel('$(f(x^k) - f^*) / f^*$')
plt.legend()
plt.xlim(0)
plt.grid(False)
plt.show()
2. 广义 LASSO 问题
广义 LASSO 问题的定义为
min
x
μ
∥
F
x
∥
1
+
1
2
∥
A
x
−
b
∥
2
(
8.6.28
)
\min_x\quad\mu\|Fx\|_1+\frac{1}{2}\|Ax-b\|^2\qquad(8.6.28)
xminμ∥Fx∥1+21∥Ax−b∥2(8.6.28)
在 LASSO 问题中,增加
∥
x
∥
1
\|x\|_1
∥x∥1 项是要保证
x
x
x 的稀疏性,而对许多问题,
x
x
x 本身不稀疏,但在某种变换下是稀疏的. 一个重要的例子是当
F
∈
R
(
n
−
1
)
×
n
F\in\mathbb{R}^{(n-1)\times n}
F∈R(n−1)×n 是一阶差分矩阵
F
i
j
=
{
1
,
j
=
i
+
1
−
1
,
j
=
i
0
,
其他
F_{ij}=\begin{cases}1,&j=i+1\\-1,&j=i\\0,&\text{其他}\end{cases}
Fij=⎩
⎨
⎧1,−1,0,j=i+1j=i其他
且
A
=
I
A=I
A=I 时,广义 LASSO 问题为
min
x
1
2
∥
x
−
b
∥
2
+
μ
∑
i
=
1
n
−
1
∣
x
i
+
1
−
x
i
∣
\min\limits_{x}\quad\frac{1}{2}\|x-b\|^2+\mu\sum\limits_{i=1}^{n-1}|x_{i+1}-x_i|
xmin21∥x−b∥2+μi=1∑n−1∣xi+1−xi∣
这个问题就是图像去噪问题的 TV 模型; 当
A
=
I
A=I
A=I 且
F
F
F 是二阶差分矩阵时,问题 (8.6.28) 被称为一范数趋势滤波.
下面介绍如何使用 ADMM 求解问题 (8.6.28).通过引入约束
F
x
=
z
Fx=z
Fx=z,将问题 (8.6.28) 写为交替方向乘子法所对应问题的形式:
min
x
,
z
1
2
∥
A
x
−
b
∥
2
+
μ
∥
z
∥
1
s
.
t
.
F
x
−
z
=
0
(
8.6.29
)
\begin{aligned}\min_{x,z}\quad&\frac{1}{2}\|Ax-b\|^{2}+\mu\|z\|_{1}\\\mathrm{s.t.}\quad& Fx-z=0\end{aligned}\qquad(8.6.29)
x,zmins.t.21∥Ax−b∥2+μ∥z∥1Fx−z=0(8.6.29)
引入乘子
y
y
y, 其增广拉格朗日函数为
L
ρ
(
x
,
z
,
y
)
=
1
2
∥
A
x
−
b
∥
2
+
μ
∥
z
∥
1
+
y
T
(
F
x
−
z
)
+
ρ
2
∥
F
x
−
z
∥
2
L_\rho(x,z,y)=\dfrac{1}{2}\|Ax-b\|^2+\mu\|z\|_1+y^\mathrm{T}(Fx-z)+\dfrac{\rho}{2}\|Fx-z\|^2
Lρ(x,z,y)=21∥Ax−b∥2+μ∥z∥1+yT(Fx−z)+2ρ∥Fx−z∥2
此问题的
x
x
x 迭代是求解方程组
(
A
T
A
+
ρ
F
T
F
)
x
=
A
T
b
+
ρ
F
T
(
z
k
−
y
k
ρ
)
(A^\mathrm{T}A+\rho F^\mathrm{T}F)x=A^\mathrm{T}b+\rho F^\mathrm{T}\left(z^k-\frac{y^k}{\rho}\right)
(ATA+ρFTF)x=ATb+ρFT(zk−ρyk)
而
z
z
z 迭代依然通过
ℓ
1
\ell_1
ℓ1 范数的邻近算子.
因此交替方向乘子法所产生的迭代为
x
k
+
1
=
(
A
T
A
+
ρ
F
T
F
)
−
1
(
A
T
b
+
ρ
F
T
(
z
k
−
y
k
ρ
)
)
z
k
+
1
=
p
r
o
x
(
μ
/
ρ
)
∥
⋅
∥
1
(
F
x
k
+
1
+
y
k
ρ
)
y
k
+
1
=
y
k
+
τ
ρ
(
F
x
k
+
1
−
z
k
+
1
)
\begin{aligned}&x^{k+1}=(A^{\mathrm{T}}A+\rho F^{\mathrm{T}}F)^{-1}\left(A^{\mathrm{T}}b+\rho F^{\mathrm{T}}\left(z^{k}-\frac{y^{k}}{\rho}\right)\right)\\&z^{k+1}=\mathrm{prox}_{(\mu/\rho)\|\cdot\|_{1}}\left(Fx^{k+1}+\frac{y^{k}}{\rho}\right)\\&y^{k+1}=y^{k}+\tau\rho(Fx^{k+1}-z^{k+1})\end{aligned}
xk+1=(ATA+ρFTF)−1(ATb+ρFT(zk−ρyk))zk+1=prox(μ/ρ)∥⋅∥1(Fxk+1+ρyk)yk+1=yk+τρ(Fxk+1−zk+1)
在这个问题中,ADMM 迭代的主要计算量仍在 x x x 更新上. 由于图像去噪问题涉及的变量数量可能有上百万,这一步迭代就要涉及求解一个百万量级的线性方程组. 在这种数据规模下不适合再使用矩阵分解的方式求解方程组,而应当注意系数矩阵的特殊结构. 对于全变差去噪问题, A T A + ρ F T F A^\mathrm{T}A+\rho F^\mathrm{T}F ATA+ρFTF 是三对角矩阵,所以此时 x x x 迭代可以在 O ( n ) \mathcal{O}(n) O(n) 的时间复杂度内解决; 对于图像去模糊问题, A A A 是卷积算子,则利用傅里叶变换可将求解方程组的复杂度降低至 O ( n log n ) \mathcal{O}(n\log n) O(nlogn); 对于一范数趋势滤波问题, A T A + ρ F T F A^\mathrm{T}A+\rho F^\mathrm{T}F ATA+ρFTF 是五对角矩阵,所以 x x x 迭代仍可以在 O ( n ) \mathcal{O}(n) O(n) 的时间复杂度内解决.
五对角矩阵是一种特殊的方阵,其除了主对角线外,还有上方和下方各有两条对角线。换句话说,五对角矩阵中除了主对角线外,只有相邻的第一条对角线和第二条对角线上有非零元素。
A = ( a 1 b 1 c 1 d 2 a 2 b 2 c 2 e 3 d 3 a 3 ⋱ ⋱ e 4 ⋱ ⋱ c n − 2 ⋱ a n − 1 b n − 1 e n d n a n ) \boldsymbol{A}=\begin{pmatrix}a_1&b_1&c_1\\d_2&a_2&b_2&c_2\\e_3&d_3&a_3&\ddots&\ddots\\&e_4&\ddots&\ddots&&c_{n-2}\\&&\ddots&&a_{n-1}&b_{n-1}\\&&&e_n&d_n&a_n\end{pmatrix} A= a1d2e3b1a2d3e4c1b2a3⋱⋱c2⋱⋱en⋱an−1dncn−2bn−1an
3. 逆协方差矩阵估计
第三章介绍了概率图模型和逆协方差矩阵估计问题.该问题的基本形式是
min
X
⟨
S
,
X
⟩
−
ln
det
X
+
μ
∥
X
∥
1
(
8.6.30
)
\min_X\quad\langle S,X\rangle-\ln\det X+\mu\|X\|_1\quad(8.6.30)
Xmin⟨S,X⟩−lndetX+μ∥X∥1(8.6.30)
其中
S
S
S 是已知的对称矩阵,通常由样本协方差矩阵得到. 变量
X
∈
S
+
+
n
,
∥
⋅
∥
1
X\in\mathcal{S}_{++}^n,\ \|\cdot\|_1
X∈S++n, ∥⋅∥1 定义为矩阵所有元素绝对值的和. 接下来说明如何应用交替方向乘子法.
目标函数由光滑项和非光滑项组成,因此引入约束
X
=
Z
X=Z
X=Z 将问题的两部分分离:
min
⟨
S
,
X
⟩
−
ln
det
X
⏟
f
(
X
)
+
μ
∥
Z
∥
1
⏟
h
(
Z
)
s
.
t
.
X
=
Z
\begin{aligned}\min\quad&\underbrace{\langle S,X\rangle-\ln\det X}_{f(X)}+\underbrace{\mu\|Z\|_1}_{h(Z)}\\\mathrm{s.t.}\quad&X=Z\end{aligned}
mins.t.f(X)
⟨S,X⟩−lndetX+h(Z)
μ∥Z∥1X=Z
引入乘子
U
U
U 作用在约束
X
−
Z
=
0
X-Z=0
X−Z=0 上,可得增广拉格朗日函数为
L
ρ
(
X
,
Z
,
U
)
=
⟨
S
,
X
⟩
−
ln
det
X
+
μ
∥
Z
∥
1
+
⟨
U
,
X
−
Z
⟩
+
ρ
2
∥
X
−
Z
∥
F
2
L_\rho(X,Z,U)=\langle S,X\rangle-\ln\det X+\mu\|Z\|_1+\langle U,X-Z\rangle+\frac{\rho}{2}\|X-Z\|_F^2
Lρ(X,Z,U)=⟨S,X⟩−lndetX+μ∥Z∥1+⟨U,X−Z⟩+2ρ∥X−Z∥F2
注意,针对矩阵情形应当使用
F
F
F 范数替换
ℓ
2
\ell_{2}
ℓ2 范数作为增广拉格朗日函数法的罚项. 接下来分别写出 ADMM 子问题的显式解. 首先,固定
Z
k
,
U
k
Z^k,U^k
Zk,Uk, 则
X
X
X 子问题是凸光滑问题,对
X
X
X 求矩阵导数并令其为零,
S
−
X
−
1
+
U
k
+
ρ
(
X
−
Z
k
)
=
0
S-X^{-1}+U^k+\rho(X-Z^k)=0
S−X−1+Uk+ρ(X−Zk)=0
这是一个关于
X
X
X 的矩阵方程,可以求出满足上述矩阵方程的唯一正定的
X
X
X 为
X
k
+
1
=
Q
D
i
a
g
(
x
1
,
x
2
,
⋯
,
x
n
)
Q
T
X^{k+1}=Q\mathrm{Diag}(x_1,x_2,\cdots,x_n)Q^\mathrm{T}
Xk+1=QDiag(x1,x2,⋯,xn)QT
其中
Q
Q
Q 包含矩阵
S
−
ρ
Z
k
+
U
k
S-\rho Z^k+U^k
S−ρZk+Uk 的所有特征向量,
x
i
x_i
xi 的表达式为
x
i
=
−
d
i
+
d
i
2
+
4
ρ
2
ρ
x_i=\frac{-d_i+\sqrt{d_i^2+4\rho}}{2\rho}
xi=2ρ−di+di2+4ρ
d i d_{i} di 为矩阵 S − ρ Z k + U k S-\rho Z^k+U^k S−ρZk+Uk 的第 i i i 个特征值. 其次,固定 X k + 1 , U k X^{k+1},U^k Xk+1,Uk, 则 Z Z Z 的更新为矩阵形 ℓ 1 \ell_{1} ℓ1 范数的邻近算子. 最后是常规的乘子更新.
4. 矩阵分离问题
考虑矩阵分离问题 (3.8.2):
min
X
,
S
∥
X
∥
∗
+
μ
∥
S
∥
1
s
.
t
.
X
+
S
=
M
(
8.6.31
)
\begin{aligned}\min_{X,S}\quad&\|X\|_{*}+\mu\|S\|_{1} \\\mathrm{s.t.}\quad&X+S=M\end{aligned}\qquad(8.6.31)
X,Smins.t.∥X∥∗+μ∥S∥1X+S=M(8.6.31)
其中
∥
⋅
∥
∗
\|\cdot\|_*
∥⋅∥∗ 与
∥
⋅
∥
1
\|\cdot\|_1
∥⋅∥1 分别表示矩阵核范数与
ℓ
1
\ell_1
ℓ1 范数. 引入乘子
Y
Y
Y 作用在约束
X
+
S
=
M
X+S=M
X+S=M 上,可以得到此问题的增广拉格朗日函数
L
ρ
(
X
,
S
,
Y
)
=
∥
X
∥
∗
+
μ
∥
S
∥
1
+
⟨
Y
,
X
+
S
−
M
⟩
+
ρ
2
∥
X
+
S
−
M
∥
F
2
(
8.6.32
)
L_\rho(X,S,Y)=\|X\|_*+\mu\|S\|_1+\langle Y,X+S-M\rangle+\frac{\rho}{2}\|X+S-M\|_F^2\qquad(8.6.32)
Lρ(X,S,Y)=∥X∥∗+μ∥S∥1+⟨Y,X+S−M⟩+2ρ∥X+S−M∥F2(8.6.32)
在第
(
k
+
1
)
(k+1)
(k+1) 步,交替方向乘子法分别求解关于
X
X
X 和
S
S
S 的子问题来更新得到
X
k
+
1
X^{k+1}
Xk+1 和
S
k
+
1
S^{k+1}
Sk+1. 对于
X
X
X 子问题,
X
k
+
1
=
arg min
X
L
ρ
(
X
,
S
k
,
Y
k
)
=
arg min
X
{
∥
X
∥
∗
+
ρ
2
∥
X
+
S
k
−
M
+
Y
k
ρ
∥
F
2
}
=
arg min
X
{
1
ρ
∥
X
∥
∗
+
1
2
∥
X
+
S
k
−
M
+
Y
k
ρ
∥
F
2
}
=
U
D
i
a
g
(
p
r
o
x
(
1
/
ρ
)
∥
⋅
∥
1
(
σ
(
A
)
)
)
V
T
\begin{aligned}X^{k+1}&=\argmin_{X}\quad L_{\rho}(X,S^{k},Y^{k})\\&=\argmin_{X}\quad\left\{\|X\|_{*}+\frac{\rho}{2}\left\|X+S^{k}-M+\frac{Y^{k}}{\rho}\right\|_{F}^{2}\right\}\\&=\argmin_{X}\quad\left\{\frac{1}{\rho}\|X\|_{*}+\frac{1}{2}\left\|X+S^{k}-M+\frac{Y^{k}}{\rho}\right\|_{F}^{2}\right\}\\&=U\mathrm{Diag}\Big(\mathrm{prox}_{(1/\rho)\|\cdot\|_{1}}(\sigma(A))\Big)V^{\mathrm{T}}\end{aligned}
Xk+1=XargminLρ(X,Sk,Yk)=Xargmin{∥X∥∗+2ρ
X+Sk−M+ρYk
F2}=Xargmin{ρ1∥X∥∗+21
X+Sk−M+ρYk
F2}=UDiag(prox(1/ρ)∥⋅∥1(σ(A)))VT
其中
A
=
M
−
S
k
−
Y
k
ρ
,
σ
(
A
)
A=M-S^k-\dfrac{Y^k}\rho,\ \sigma(A)
A=M−Sk−ρYk, σ(A) 为
A
A
A 的所有非零奇异值构成的向量并且
U
U
UDiag
(
σ
(
A
)
)
V
T
(\sigma(A))V^{\mathrm{T}}
(σ(A))VT 为
A
A
A 的约化奇异值分解. 对于
S
S
S 子问题,
S
k
+
1
=
arg min
S
L
ρ
(
X
k
+
1
,
S
,
Y
k
)
=
arg min
S
{
μ
∥
S
∥
1
+
ρ
2
∥
X
k
+
1
+
S
−
M
+
Y
k
ρ
∥
F
2
}
=
p
r
o
x
(
μ
/
ρ
)
∥
⋅
∥
1
(
M
−
X
k
+
1
−
Y
k
ρ
)
\begin{aligned}S^{k+1}&=\argmin_{S}\quad L_{\rho}(X^{k+1},S,Y^{k})\\&=\argmin_{S}\quad\left\{\mu\|S\|_{1}+\frac{\rho}{2}\left\|X^{k+1}+S-M+\frac{Y^{k}}{\rho}\right\|_{F}^{2}\right\}\\&=\mathrm{prox}_{(\mu/\rho)\|\cdot\|_{1}}\left(M-X^{k+1}-\frac{Y^{k}}{\rho}\right)\end{aligned}
Sk+1=SargminLρ(Xk+1,S,Yk)=Sargmin{μ∥S∥1+2ρ
Xk+1+S−M+ρYk
F2}=prox(μ/ρ)∥⋅∥1(M−Xk+1−ρYk)
对于乘子
Y
Y
Y, 依然使用常规更新,即
Y
k
+
1
=
Y
k
+
τ
ρ
(
X
k
+
1
+
S
k
+
1
−
M
)
Y^{k+1}=Y^{k}+\tau\rho(X^{k+1}+S^{k+1}-M)
Yk+1=Yk+τρ(Xk+1+Sk+1−M)
那么, 交替方向乘子法的迭代格式为
X
k
+
1
=
U
D
i
a
g
(
p
r
o
x
(
1
/
ρ
)
∥
⋅
∥
1
(
σ
(
A
)
)
)
V
T
S
k
+
1
=
p
r
o
x
(
μ
/
ρ
)
∥
⋅
∥
1
(
M
−
L
k
+
1
−
Y
k
ρ
)
Y
k
+
1
=
Y
k
+
τ
ρ
(
X
k
+
1
+
S
k
+
1
−
M
)
\begin{aligned}X^{k+1}&=U\mathrm{Diag}\Big(\mathrm{prox}_{(1/\rho)\|\cdot\|_{1}}(\sigma(A))\Big)V^{\mathrm{T}} \\S^{k+1}&=\mathrm{prox}_{(\mu/\rho)\|\cdot\|_{1}}\left(M-L^{k+1}-\frac{Y^{k}}{\rho}\right)\\ Y^{k+1}&=Y^{k}+\tau\rho(X^{k+1}+S^{k+1}-M)\end{aligned}
Xk+1Sk+1Yk+1=UDiag(prox(1/ρ)∥⋅∥1(σ(A)))VT=prox(μ/ρ)∥⋅∥1(M−Lk+1−ρYk)=Yk+τρ(Xk+1+Sk+1−M)
5. 全局一致性优化问题
第 8.6.1 小节介绍了全局一致性优化问题
min
x
∑
i
=
1
N
ϕ
i
(
x
)
\min_x\quad\sum_{i=1}^N\phi_i(x)
xmini=1∑Nϕi(x)
并给出了一个拆分方式
min
x
i
,
z
∑
i
=
1
N
ϕ
i
(
x
i
)
s
.
t
.
x
i
−
z
=
0
,
i
=
1
,
2
,
⋯
,
N
\begin{aligned}\min_{x_{i},z}&\quad\sum_{i=1}^{N}\phi_{i}(x_{i})\\\mathrm{s.t.}&\quad x_{i}-z=0,\ i=1,2,\cdots,N\end{aligned}
xi,zmins.t.i=1∑Nϕi(xi)xi−z=0, i=1,2,⋯,N
其增广拉格朗日函数为
L
ρ
(
x
1
,
x
2
,
⋯
,
x
N
,
z
,
y
1
,
y
2
,
⋯
,
y
N
)
=
∑
i
=
1
N
ϕ
i
(
x
i
)
+
∑
i
=
1
N
y
i
T
(
x
i
−
z
)
+
ρ
2
∑
i
=
1
N
∥
x
i
−
z
∥
2
L_{\rho}(x_{1},x_{2},\cdots,x_{N},z,y_{1},y_{2},\cdots,y_{N})=\sum_{i=1}^{N}\phi_{i}(x_{i})+\sum_{i=1}^{N}y_{i}^{\mathrm{T}}(x_{i}-z)+\frac{\rho}{2}\sum_{i=1}^{N}\|x_{i}-z\|^{2}
Lρ(x1,x2,⋯,xN,z,y1,y2,⋯,yN)=i=1∑Nϕi(xi)+i=1∑NyiT(xi−z)+2ρi=1∑N∥xi−z∥2
固定
z
k
,
y
i
k
z^k,y_i^k
zk,yik, 更新
x
i
x_i
xi 的公式为
x
i
k
+
1
=
arg min
x
{
ϕ
i
(
x
)
+
ρ
2
∥
x
−
z
k
+
y
i
k
ρ
∥
2
}
(
8.6.33
)
x_i^{k+1}=\argmin_{x}\left\{\phi_i(x)+\frac{\rho}{2}\left\|x-z^k+\frac{y_i^k}{\rho}\right\|^2\right\}\qquad(8.6.33)
xik+1=xargmin{ϕi(x)+2ρ
x−zk+ρyik
2}(8.6.33)
在这里注意,虽然表面上看增广拉格朗日函数有
(
N
+
1
)
(N+1)
(N+1) 个变量块,但本质上还是两个变量块. 这是因为在更新某
x
i
x_i
xi 时并没有利用其他
x
i
x_i
xi 的信息,所有
x
i
x_{i}
xi 可以看成一个整体. 相应地,所有乘子
y
i
y_i
yi 也可以看成一个整体. 迭代式 (8.6.33) 的具体计算依赖于
ϕ
i
\phi_i
ϕi 的形式,在一般情况下更新
x
i
x_i
xi 的表达式为
x
i
k
+
1
=
p
r
o
x
ϕ
i
/
ρ
(
z
k
−
y
i
k
ρ
)
x_i^{k+1}=\mathrm{prox}_{\phi_i/\rho}\left(z^k-\frac{y_i^k}{\rho}\right)
xik+1=proxϕi/ρ(zk−ρyik)
固定
x
i
k
+
1
,
y
i
k
x_i^{k+1},y_i^k
xik+1,yik, 问题关于
z
z
z 是二次函数,因此可以直接写出显式解:
z
k
+
1
=
1
N
∑
i
=
1
N
(
x
i
k
+
1
+
y
i
k
ρ
)
z^{k+1}=\frac{1}{N}\sum_{i=1}^{N}\left(x_{i}^{k+1}+\frac{y_{i}^{k}}{\rho}\right)
zk+1=N1i=1∑N(xik+1+ρyik)
综上,该问题的交替方向乘子法迭代格式为
x
i
k
+
1
=
p
r
o
x
ϕ
i
/
ρ
(
z
k
−
y
i
k
ρ
)
,
i
=
1
,
2
,
⋯
,
N
z
k
+
1
=
1
N
∑
i
=
1
N
(
x
i
k
+
1
+
y
i
k
ρ
)
y
i
k
+
1
=
y
i
k
+
τ
ρ
(
x
i
k
+
1
−
z
k
+
1
)
,
i
=
1
,
2
,
⋯
,
N
\begin{aligned} &x_{i}^{k+1} =\mathrm{prox}_{\phi_{i}/\rho}\left(z^{k}-\frac{y_{i}^{k}}{\rho}\right), i=1,2,\cdots,N\\ &z^{k+1} =\frac1N\sum_{i=1}^N\left(x_i^{k+1}+\frac{y_i^k}\rho\right)\\ &y_{i}^{k+1} ={y_{i}}^{k}+\tau\rho({x_{i}}^{k+1}-z^{k+1}), i=1,2,\cdots,N \end{aligned}
xik+1=proxϕi/ρ(zk−ρyik),i=1,2,⋯,Nzk+1=N1i=1∑N(xik+1+ρyik)yik+1=yik+τρ(xik+1−zk+1),i=1,2,⋯,N
6. 非凸集合上的优化问题
非凸集合上的优化问题可以表示为
min
f
(
x
)
s
.
t
.
x
∈
S
(
8.6.34
)
\begin{aligned}\min\quad&f(x)\\\mathrm{s.t.}\quad&x\in S\end{aligned}\qquad(8.6.34)
mins.t.f(x)x∈S(8.6.34)
其中
f
f
f 是闭凸函数,但
S
S
S 是非凸集合. 利用例 8.21 的技巧,对集合
S
S
S 引入示性函数
I
S
(
z
)
I_S(z)
IS(z) 并做拆分,可得到问题 (8.6.34) 的等价优化问题:
min
f
(
x
)
+
I
S
(
z
)
s
.
t
.
x
−
z
=
0
(
8.6.35
)
\begin{aligned}\min\quad&f(x)+I_{S}(z)\\\mathrm{s.t.}\quad& x-z=0\end{aligned}\qquad(8.6.35)
mins.t.f(x)+IS(z)x−z=0(8.6.35)
其增广拉格朗日函数为
L
ρ
(
x
,
z
,
y
)
=
f
(
x
)
+
I
S
(
z
)
+
y
T
(
x
−
z
)
+
ρ
2
∥
x
−
z
∥
2
L_\rho(x,z,y)=f(x)+I_S(z)+y^\mathrm{T}(x-z)+\frac{\rho}{2}\|x-z\|^2
Lρ(x,z,y)=f(x)+IS(z)+yT(x−z)+2ρ∥x−z∥2
由于
f
f
f 是闭凸函数,固定
z
,
y
z,y
z,y 后对
x
x
x 求极小就是计算邻近算子:
x
k
+
1
=
p
r
o
x
f
/
ρ
(
z
k
−
y
k
ρ
)
x^{k+1}=\mathrm{prox}_{f/\rho}\left(z^k-\frac{y^k}{\rho}\right)
xk+1=proxf/ρ(zk−ρyk)
固定
x
,
y
x,y
x,y, 对
z
z
z 求极小实际上是到非凸集合上的投影问题:
z
k
+
1
=
arg min
z
∈
S
1
2
∥
z
−
(
x
k
+
1
+
y
k
ρ
)
∥
2
=
P
S
(
x
k
+
1
+
y
k
ρ
)
z^{k+1}=\argmin_{z\in S}\frac{1}{2}\left\|z-\left(x^{k+1}+\frac{y^k}{\rho}\right)\right\|^2=\mathcal{P}_S\left(x^{k+1}+\frac{y^k}{\rho}\right)
zk+1=z∈Sargmin21
z−(xk+1+ρyk)
2=PS(xk+1+ρyk)
一般来说,由于
S
S
S 是非凸集合,计算
P
s
P_\mathrm{s}
Ps 是比较困难的 (例如不能保证存在性和唯一性), 但是当
S
S
S 有特定结构时,到
S
S
S 上的投影可以精确求解.
(1) 基数:如果
S
=
{
x
∣
∥
x
∥
0
⩽
c
}
S=\{x\mid\|x\|_0\leqslant c\}
S={x∣∥x∥0⩽c}, 其中
∥
⋅
∥
0
\|\cdot\|_0
∥⋅∥0 表示
ℓ
0
\ell_0
ℓ0 范数,即非零元素的数目,那么计算任意向量
v
v
v 到
S
S
S 中的投影就是保留
v
v
v 分量中绝对值从大到小排列的前
c
c
c 个,其余分量变成 0. 假设
v
v
v 的各个分量满足
∣
v
i
1
∣
⩾
∣
v
i
2
∣
⩾
⋯
⩾
∣
v
i
n
∣
|v_{i_1}|\geqslant|v_{i_2}|\geqslant\cdots\geqslant|v_{i_n}|
∣vi1∣⩾∣vi2∣⩾⋯⩾∣vin∣
则投影算子可写成
(
P
S
(
v
)
)
i
=
{
v
i
,
i
∈
{
i
1
,
i
2
,
⋯
,
i
c
}
,
0
,
其他
.
(\mathcal{P}_S(v))_i=\begin{cases}v_i,&i\in\{i_1,i_2,\cdots,i_c\},\\[2ex]0,&\text{其他}.\end{cases}
(PS(v))i=⎩
⎨
⎧vi,0,i∈{i1,i2,⋯,ic},其他.
(2) 低秩投影:当变量
x
∈
R
m
×
n
x\in\mathbb{R}^{m\times n}
x∈Rm×n 是矩阵时,一种常见的非凸约束是在低秩矩阵空间中进行优化问题求解,即
S
=
{
x
∣
r
a
n
k
(
x
)
⩽
r
}
S=\{x\mid \mathrm{rank}(x)\leqslant r\}
S={x∣rank(x)⩽r}. 此时到低秩矩阵空间上的投影等价于对
x
x
x 做截断奇异值分解. 设
x
x
x 的奇异值分解为
x
=
∑
i
=
1
min
{
m
,
n
}
σ
i
u
i
v
i
T
x=\sum_{i=1}^{\min\{m,n\}}\sigma_iu_iv_i^\mathrm{T}
x=i=1∑min{m,n}σiuiviT
其中
σ
1
⩾
⋯
⩾
σ
min
{
m
,
n
}
⩾
0
\sigma_1\geqslant\cdots\geqslant\sigma_{\min\{m,n\}}\geqslant0
σ1⩾⋯⩾σmin{m,n}⩾0 为奇异值,
u
i
,
v
i
u_i,v_i
ui,vi 为对应的左右奇异向量,则
P
S
\mathcal{P}_S
PS 的表达式为
P
S
(
x
)
=
∑
i
=
1
r
σ
i
u
i
v
i
T
\mathcal{P}_S(x)=\sum_{i=1}^r\sigma_iu_iv_i^\mathrm{T}
PS(x)=i=1∑rσiuiviT
(3) 布尔 (Bool) 约束:如果限制变量 x x x 只能在 { 0 , 1 } \{0,1\} {0,1} 中取值,即 S = { 0 , 1 } n S=\{0,1\}^n S={0,1}n, 容易验证 P S ( v ) \mathcal{P}_S(v) PS(v) 就是简单地把 v v v 的每个分量 v i v_i vi 变为 0 和 1中离它更近的数,一种可能的实现方式是分别对它们做四舍五入操作.
7. 非负矩阵分解和补全
非负矩阵分解和补全可以看作非负矩阵分解问题和低秩矩阵补全问题的结合,即已知一个非负矩阵的部分元素,求其非负分解.
假设我们有从一个非负、秩为
r
r
r 的矩阵
M
∈
R
m
×
n
M\in\mathbb{R}^{m\times n}
M∈Rm×n 中采样的部分元素
M
i
,
j
,
(
i
,
j
)
∈
Ω
⊂
{
1
,
2
,
⋯
,
m
}
×
{
1
,
2
,
⋯
,
n
}
M_{i,j},(i,j)\in\Omega\subset\{1,2,\cdots,m\}\times\{1,2,\cdots,n\}
Mi,j,(i,j)∈Ω⊂{1,2,⋯,m}×{1,2,⋯,n}, 目标是要找到非负矩阵
X
∈
R
m
×
q
,
Y
∈
R
q
×
n
X\in\mathbb{R}^{m\times q},Y\in\mathbb{R}^{q\times n}
X∈Rm×q,Y∈Rq×n 使得
∥
M
−
X
Y
∥
F
2
\|M-XY\|_F^2
∥M−XY∥F2 极小. 一般地,因为数据和应用问题的不同,
q
q
q 可以等于、小于或者大于
r
r
r. 定义矩阵
P
∈
R
m
×
n
P\in\mathbb{R}^{m\times n}
P∈Rm×n:
P
i
j
=
{
1
,
(
i
,
j
)
∈
Ω
0
,
其他
P_{ij}=\begin{cases}1,&(i,j)\in\Omega \\0,&\text{其他}\end{cases}
Pij={1,0,(i,j)∈Ω其他
则非负矩阵分解和补全问题可以写成如下形式:
min
X
,
Y
∥
P
⊙
(
X
Y
−
M
)
∥
F
2
s
.
t
.
X
i
j
⩾
0
,
Y
i
j
⩾
0
,
∀
i
,
j
\begin{aligned}\min_{X,Y}\quad&\|P\odot(XY-M)\|_{F}^{2} \\\mathrm{s.t.}\quad& X_{ij}\geqslant0,Y_{ij}\geqslant 0,\forall i,j\end{aligned}
X,Ymins.t.∥P⊙(XY−M)∥F2Xij⩾0,Yij⩾0,∀i,j
注意,这个问题是非凸的.
为了利用交替方向乘子法的优势,我们考虑如下等价形式:
min
U
,
V
,
X
,
Y
,
Z
1
2
∥
X
Y
−
Z
∥
F
2
s
.
t
.
X
=
U
,
Y
=
V
U
⩾
0
,
V
⩾
0
P
⊙
(
Z
−
M
)
=
0
\begin{aligned} \min_{U,V,X,Y,Z}\quad&\frac{1}{2}\|XY-Z\|_{F}^{2}\\ \mathrm{s.t.}\quad&X=U,Y=V\\ &U\geqslant 0,V\geqslant 0\\ &P\odot(Z-M)=0\end{aligned}
U,V,X,Y,Zmins.t.21∥XY−Z∥F2X=U,Y=VU⩾0,V⩾0P⊙(Z−M)=0
对于等式约束
X
=
U
X=U
X=U 和
Y
=
V
Y=V
Y=V 分别引入拉格朗日乘子
Λ
\Lambda
Λ 和
Π
\Pi
Π, 并保留非负约束
U
⩾
0
,
V
⩾
0
U\geqslant 0,V\geqslant 0
U⩾0,V⩾0 和观测值约束
P
⊙
(
Z
−
M
)
=
0
P\odot(Z-M)=0
P⊙(Z−M)=0, 则增广拉格朗日函数为
L
α
,
β
(
X
,
Y
,
Z
,
U
,
V
,
Λ
,
Π
)
=
1
2
∥
X
Y
−
Z
∥
F
2
+
⟨
Λ
,
X
−
U
⟩
+
⟨
Π
,
Y
−
V
⟩
+
α
2
∥
X
−
U
∥
F
2
+
β
2
∥
Y
−
V
∥
F
2
(
8.6.36
)
\begin{aligned}&L_{\alpha,\beta}(X,Y,Z,U,V,\Lambda,\Pi) \\=&\frac{1}{2}\|XY-Z\|_{F}^{2}+\langle \Lambda,X-U\rangle+\langle\Pi,Y-V\rangle+\frac{\alpha}{2}\|X-U\|_{F}^{2}+\frac{\beta}{2}\|Y-V\|_{F}^{2}\end{aligned}\qquad(8.6.36)
=Lα,β(X,Y,Z,U,V,Λ,Π)21∥XY−Z∥F2+⟨Λ,X−U⟩+⟨Π,Y−V⟩+2α∥X−U∥F2+2β∥Y−V∥F2(8.6.36)
应用交替方向乘子法,可得
X
k
+
1
=
arg min
X
L
α
,
β
(
X
,
Y
k
,
Z
k
,
U
k
,
V
k
,
Λ
k
,
Π
k
)
Y
k
+
1
=
arg min
Y
L
α
,
β
(
X
k
+
1
,
Y
,
Z
k
,
U
k
,
V
k
,
Λ
k
,
Π
k
)
Z
k
+
1
=
arg min
P
⊙
(
Z
−
M
)
=
0
L
α
,
β
(
X
k
+
1
,
Y
k
+
1
,
Z
,
U
k
,
V
k
,
Λ
k
,
Π
k
)
U
k
+
1
=
arg min
U
⩾
0
L
α
,
β
(
X
k
+
1
,
Y
k
+
1
,
Z
k
+
1
,
U
,
V
k
,
Λ
k
,
Π
k
)
V
k
+
1
=
arg min
V
⩾
0
L
α
,
β
(
X
k
+
1
,
Y
k
+
1
,
Z
k
+
1
,
U
k
+
1
,
V
,
Λ
k
,
Π
k
)
Λ
k
+
1
=
Λ
k
+
τ
α
(
X
k
+
1
−
U
k
+
1
)
Π
k
+
1
=
Π
k
+
τ
β
(
Y
k
+
1
−
V
k
+
1
)
\begin{aligned} &X^{k+1} =\argmin_{X} L_{\alpha,\beta}(X,Y^{k},Z^{k},U^{k},V^{k},\Lambda^{k},\Pi^{k})\\ &Y^{k+1} =\argmin_{Y} L_{\alpha,\beta}(X^{k+1},Y,Z^{k},U^{k},V^{k},\Lambda^{k},\Pi^{k})\\ &Z^{k+1} = \argmin_{P\odot(Z-M)=0} L_{\alpha,\beta}(X^{k+1},Y^{k+1},Z,U^{k},V^{k},\Lambda^{k},\Pi^{k})\\ &U^{k+1} =\argmin_{U\geqslant0} L_{\alpha,\beta}(X^{k+1},Y^{k+1},Z^{k+1},U,V^{k},\Lambda^{k},\Pi^{k})\\ &V^{k+1} =\argmin_{V\geqslant0} L_{\alpha,\beta}(X^{k+1},Y^{k+1},Z^{k+1},U^{k+1},V,\Lambda^{k},\Pi^{k})\\ &\Lambda^{k+1} =\Lambda^{k}+\tau\alpha(X^{k+1}-U^{k+1})\\ &\Pi^{k+1} =\Pi^{k}+\tau\beta(Y^{k+1}-V^{k+1}) \end{aligned}
Xk+1=XargminLα,β(X,Yk,Zk,Uk,Vk,Λk,Πk)Yk+1=YargminLα,β(Xk+1,Y,Zk,Uk,Vk,Λk,Πk)Zk+1=P⊙(Z−M)=0argminLα,β(Xk+1,Yk+1,Z,Uk,Vk,Λk,Πk)Uk+1=U⩾0argminLα,β(Xk+1,Yk+1,Zk+1,U,Vk,Λk,Πk)Vk+1=V⩾0argminLα,β(Xk+1,Yk+1,Zk+1,Uk+1,V,Λk,Πk)Λk+1=Λk+τα(Xk+1−Uk+1)Πk+1=Πk+τβ(Yk+1−Vk+1)
将子问题求解,可得
X
k
+
1
=
(
Z
k
(
Y
k
)
T
+
α
U
k
−
A
k
)
(
Y
k
(
Y
k
)
T
+
α
I
)
−
1
Y
k
+
1
=
(
(
X
k
+
1
)
T
X
k
+
1
+
β
I
)
−
1
(
(
X
k
+
1
)
T
Z
k
+
β
V
k
−
Π
k
)
Z
k
+
1
=
X
k
+
1
Y
k
+
1
+
P
⊙
(
M
−
X
k
+
1
Y
k
+
1
)
U
k
+
1
=
P
+
(
X
k
+
1
+
Λ
k
α
)
V
k
+
1
=
P
+
(
Y
k
+
1
+
Π
k
β
)
Λ
k
+
1
=
Λ
k
+
τ
α
(
X
k
+
1
−
U
k
+
1
)
P
i
k
+
1
=
P
i
k
+
τ
β
(
Y
k
+
1
−
V
k
+
1
)
\begin{aligned}&X^{k+1}=(Z^{k}(Y^{k})^{\mathrm{T}}+\alpha U^{k}-A^{k})(Y^{k}(Y^{k})^{\mathrm{T}}+\alpha I)^{-1}\\ &Y^{k+1}=((X^{k+1})^{\mathrm{T}}X^{k+1}+\beta I)^{-1}((X^{k+1})^{\mathrm{T}}Z^{k}+\beta V^{k}-\Pi^{k})\\ &Z^{k+1}=X^{k+1}Y^{k+1}+P\odot(M-X^{k+1}Y^{k+1})\\&U^{k+1}=\mathcal{P}_{+}\left(X^{k+1}+\frac{\Lambda^{k}}{\alpha}\right)\\ &V^{k+1}=\mathcal{P}_{+}\left(Y^{k+1}+\frac{\Pi^{k}}{\beta}\right)\\&\Lambda^{k+1}=\Lambda^{k}+\tau\alpha(X^{k+1}-U^{k+1})\\ &Pi^{k+1}=Pi^{k}+\tau\beta(Y^{k+1}-V^{k+1})\end{aligned}
Xk+1=(Zk(Yk)T+αUk−Ak)(Yk(Yk)T+αI)−1Yk+1=((Xk+1)TXk+1+βI)−1((Xk+1)TZk+βVk−Πk)Zk+1=Xk+1Yk+1+P⊙(M−Xk+1Yk+1)Uk+1=P+(Xk+1+αΛk)Vk+1=P+(Yk+1+βΠk)Λk+1=Λk+τα(Xk+1−Uk+1)Pik+1=Pik+τβ(Yk+1−Vk+1)
其中 ( P + ( A ) ) i j = max { a i j , 0 } (\mathcal{P}_{+}(A))_{ij}=\max\{a_{ij},0\} (P+(A))ij=max{aij,0}. 注意, 该格式为多块交替方向乘子法, 其收敛性可能要要较强假设.
8. 多块交替方向乘子法的反例
这里给出一个多块交替方向乘子法的例子,并且从数值上说明若直接采用格式 (8.6.25),则算法未必收敛.
考虑最优化问题
min
0
s
.
t
.
A
1
x
1
+
A
2
x
2
+
A
3
x
3
=
0
(
8.6.37
)
\begin{aligned}\min\quad&0 \\\mathrm{s.t.}\quad& A_1x_1+A_2x_2+A_3x_3=0\end{aligned}\qquad(8.6.37)
mins.t.0A1x1+A2x2+A3x3=0(8.6.37)
其中
A
i
∈
R
3
,
i
=
1
,
2
,
3
A_i\in\mathbb{R}^{3},i=1,2,3
Ai∈R3,i=1,2,3 为三维空间中的非零向量,
x
i
∈
R
,
i
=
1
,
2
,
3
x_i\in \mathbb{R}, i=1,2,3
xi∈R,i=1,2,3 是自变量. 问题 (8.6.37) 实际上就是求解三维空间中的线性方程组,若
A
1
,
A
2
,
A
3
A_1,A_2,A_3
A1,A2,A3 之间线性无关,则问题 (8.6.37) 只有零解. 此时容易计算出最优解对应的乘子为
y
=
(
0
,
0
,
0
)
T
y=(0,0,0)^\mathrm{T}
y=(0,0,0)T.
现在推导多块交替方向乘子法的格式. 问题 (8.6.37) 的增广拉格朗日函数为
L
ρ
(
x
,
y
)
=
0
+
y
T
(
A
1
x
1
+
A
2
x
2
+
A
3
x
3
)
+
ρ
2
∥
A
1
x
1
+
A
2
x
2
+
A
3
x
3
∥
2
L_\rho(x,y)=0+y^\mathrm{T}(A_1x_1+A_2x_2+A_3x_3)+\frac{\rho}{2}\|A_1x_1+A_2x_2+A_3x_3\|^2
Lρ(x,y)=0+yT(A1x1+A2x2+A3x3)+2ρ∥A1x1+A2x2+A3x3∥2
当固定
x
2
,
x
3
,
y
x_2,x_3,y
x2,x3,y 时,对
x
1
x_1
x1 求最小可推出
A
1
T
y
+
ρ
A
1
T
(
A
1
x
1
+
A
2
x
2
+
A
3
x
3
)
=
0
A_1^\mathrm{T}y+\rho A_1^\mathrm{T}(A_1x_1+A_2x_2+A_3x_3)=0
A1Ty+ρA1T(A1x1+A2x2+A3x3)=0
整理可得
x
1
=
−
1
∥
A
1
∥
2
A
1
T
(
y
ρ
+
A
2
x
2
+
A
3
x
3
)
x_1=-\frac{1}{\|A_1\|^2}A_1^\mathrm{T}\left(\frac{y}{\rho}+A_2x_2+A_3x_3\right)
x1=−∥A1∥21A1T(ρy+A2x2+A3x3)
可类似地计算
x
2
,
x
3
x_2,x_3
x2,x3 的表达式,因此多块交替方向乘子法的迭代格式可以写为
x
1
k
+
1
=
−
1
∥
A
1
∥
2
A
1
T
(
y
k
ρ
+
A
2
x
2
k
+
A
3
x
3
k
)
x
2
k
+
1
=
−
1
∥
A
2
∥
2
A
2
T
(
y
k
ρ
+
A
1
x
1
k
+
1
+
A
3
x
3
k
)
x
3
k
+
1
=
−
1
∥
A
3
∥
2
A
3
T
(
y
k
ρ
+
A
1
x
1
k
+
1
+
A
2
x
2
k
+
1
)
y
k
+
1
=
y
k
+
ρ
(
A
1
x
1
k
+
1
+
A
2
x
2
k
+
1
+
A
3
x
3
k
+
1
)
(
8.6.38
)
\begin{aligned}&x_{1}^{k+1}=-\frac{1}{\|A_{1}\|^{2}}A_{1}^{\mathrm{T}}\left(\frac{y^{k}}{\rho}+A_{2}x_{2}^{k}+A_{3}x_{3}^{k}\right)\\&x_{2}^{k+1}=-\frac{1}{\|A_{2}\|^{2}}A_{2}^{\mathrm{T}}\left(\frac{y^{k}}{\rho}+A_{1}x_{1}^{k+1}+A_{3}x_{3}^{k}\right)\\&x_{3}^{k+1}=-\frac{1}{\|A_{3}\|^{2}}A_{3}^{\mathrm{T}}\left(\frac{y^{k}}{\rho}+A_{1}x_{1}^{k+1}+A_{2}x_{2}^{k+1}\right)\\&y^{k+1}=y^{k}+\rho(A_{1}x_{1}^{k+1}+A_{2}x_{2}^{k+1}+A_{3}x_{3}^{k+1})\end{aligned}\qquad(8.6.38)
x1k+1=−∥A1∥21A1T(ρyk+A2x2k+A3x3k)x2k+1=−∥A2∥21A2T(ρyk+A1x1k+1+A3x3k)x3k+1=−∥A3∥21A3T(ρyk+A1x1k+1+A2x2k+1)yk+1=yk+ρ(A1x1k+1+A2x2k+1+A3x3k+1)(8.6.38)
对此问题而言,罚因子取不同值仅仅是将乘子
y
k
y^k
yk 缩放了常数倍,所以罚因子
ρ
\rho
ρ 的任意取法 (包括动态调节) 都是等价的.
在数值实验中我们不妨取
ρ
=
1
\rho=1
ρ=1.
格式 (8.6.38) 的收敛性与
A
i
,
i
=
1
,
2
,
3
A_i,i=1,2,3
Ai,i=1,2,3 的选取有关. 为了方便,令
A
=
[
A
1
,
A
2
,
A
3
]
A=[A_{1},A_{2},A_{3}]
A=[A1,A2,A3], 以及
x
=
(
x
1
,
x
2
,
x
3
)
T
x=(x_1,x_{2},x_{3})^{\mathrm{T}}
x=(x1,x2,x3)T, 并选取
A
A
A 为
A
~
=
[
1
1
1
1
1
2
1
2
2
]
或
A
^
=
[
1
1
2
0
1
1
0
0
1
]
\widetilde{A}=\begin{bmatrix}1&1&1\\1&1&2\\1&2&2\end{bmatrix}\quad\text{或}\quad\widehat{A}=\begin{bmatrix}1&1&2\\0&1&1\\0&0&1\end{bmatrix}
A
=
111112122
或A
=
100110211
在迭代中,自变量初值选为(1,1,1), 乘子选为(0,0,0).
import numpy as np
import matplotlib.pyplot as plt
#A_tilde = np.array([[1, 1, 1], [1, 1, 2], [1, 2, 2]])
A1_tilde = np.array([1, 1, 1])
A2_tilde = np.array([1, 1, 2])
A3_tilde = np.array([1, 2, 2])
# A_hat = np.array([[1, 1, 2], [0, 1, 1], [0, 0, 1]])
A1_hat = np.array([1, 1, 2])
A2_hat = np.array([0, 1, 1])
A3_hat = np.array([0, 0, 1])
# Define the norm square of Ai
norm_A1_tilde_sq = np.linalg.norm(A1_tilde)**2
norm_A2_tilde_sq = np.linalg.norm(A2_tilde)**2
norm_A3_tilde_sq = np.linalg.norm(A3_tilde)**2
norm_A1_hat_sq = np.linalg.norm(A1_hat)**2
norm_A2_hat_sq = np.linalg.norm(A2_hat)**2
norm_A3_hat_sq = np.linalg.norm(A3_hat)**2
def admm(A1, A2, A3, norm_A1_sq, norm_A2_sq, norm_A3_sq, num_iterations=100):
x1, x2, x3 = 1, 1, 1
y = np.zeros(3)
rho = 1
x_norms = []
y_norms = []
for k in range(num_iterations):
x1 = -1 / norm_A1_sq * A1.T.dot(y / rho + A2 * x2 + A3 * x3)
x2 = -1 / norm_A2_sq * A2.T.dot(y / rho + A1 * x1 + A3 * x3)
x3 = -1 / norm_A3_sq * A3.T.dot(y / rho + A1 * x1 + A2 * x2)
y = y + rho * (A1 * x1 + A2 * x2 + A3 * x3)
x_norms.append(np.linalg.norm([x1, x2, x3]))
y_norms.append(np.linalg.norm(y))
return x_norms, y_norms
x_norms_tilde, y_norms_tilde = admm(A1_tilde, A2_tilde, A3_tilde, norm_A1_tilde_sq, norm_A2_tilde_sq, norm_A3_tilde_sq)
x_norms_hat, y_norms_hat = admm(A1_hat, A2_hat, A3_hat, norm_A1_hat_sq, norm_A2_hat_sq, norm_A3_hat_sq)
plt.figure(figsize=(6, 8))
# tilde A
plt.subplot(2, 1, 1)
plt.plot(x_norms_tilde, label='$||x||$')
plt.plot(y_norms_tilde, linestyle='--', label='$||y||$')
plt.title('ADMM Convergence for $\widetilde{A}$')
plt.xlabel('Iterations')
plt.xlim(0)
plt.legend()
# hat A
plt.subplot(2, 1, 2)
plt.plot(x_norms_hat, label='$||x||$')
plt.plot(y_norms_hat, linestyle='--', label='$||y||$')
plt.title('ADMM Convergence for $\widehat{A}$')
plt.xlabel('Iterations')
plt.xlim(0)
plt.yscale('log')
plt.legend()
plt.tight_layout()
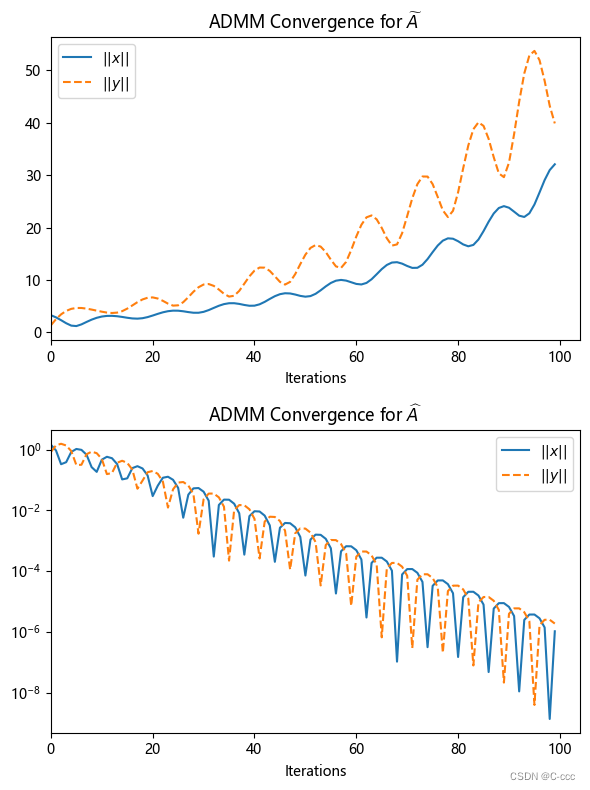
上图记录了在两种不同 A A A 条件下, x x x 和 y y y 的 ℓ 2 \ell_2 ℓ2 范数随迭代的变化过程. 可以看到当 A = A ~ A=\widetilde{A} A=A 时数值结果表明迭代是发散的,而当 A = A ^ A=\widehat{A} A=A 时数值结果表明迭代是收敛的. 另一个比较有趣的观察是,在下子图 中 ∥ x ∥ \|x\| ∥x∥ 与 ∥ y ∥ \|y\| ∥y∥ 并不是单调下降的,而是在下降的同时有规律地振荡.















 873
873











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









