







6.2 梯度类算法
本节介绍梯度类算法,其本质是仅仅使用函数的一阶导数信息选取下降方向 d k d^k dk。这其中最基本的算法是梯度下降法,即直接选择负梯度作为下降方向 d k d^k dk。梯度下降法的方向选取非常直观,实际应用范围非常广,因此它在优化算法中的地位可相当于高斯消元法在线性方程组算法中的地位。此外也会介绍 BB 方法。该方法作为一种梯度法的变形,虽然理论性质目前仍不完整,但由于它有优秀的数值表现,也是在实际应用中使用较多的一种算法。
6.2.1 梯度下降法
对于光滑函数
f
(
x
)
f(x)
f(x),在迭代点
x
k
x^k
xk 处,需要选择一个较为合理的
d
k
d^{k}
dk 作为下降方向。注意到
ϕ
(
α
)
=
f
(
x
k
+
α
d
k
)
\phi(\alpha)=f(x^k+\alpha d^k)
ϕ(α)=f(xk+αdk) 有泰勒展开
ϕ
(
α
)
=
f
(
x
k
)
+
α
∇
f
(
x
k
)
T
d
k
+
O
(
α
2
∥
d
k
∥
2
)
\phi(\alpha)=f(x^{k})+\alpha\nabla f(x^{k})^{\mathrm{T}}d^{k}+\mathcal{O}(\alpha^{2}\|d^{k}\|^{2})
ϕ(α)=f(xk)+α∇f(xk)Tdk+O(α2∥dk∥2)
根据柯西不等式,当
α
\alpha
α 足够小时,取
d
k
=
−
∇
f
(
x
k
)
d^k=-\nabla f(x^k)
dk=−∇f(xk) 会使得函数下降最快。因此梯度法就是选取
d
k
=
−
∇
f
(
x
k
)
d^k=-\nabla f(x^k)
dk=−∇f(xk) 的算法,它的迭代格式为
x
k
+
1
=
x
k
−
α
k
∇
f
(
x
k
)
(
6.2.1
)
x^{k+1}=x^{k}-\alpha_{k}\nabla f(x^{k})\qquad(6.2.1)
xk+1=xk−αk∇f(xk)(6.2.1)
步长 α k \alpha_k αk 的选取可依赖于线搜索算法,也可直接选取固定的 α k \alpha_k αk。
为了直观地理解梯度法的迭代过程,以二次函数为例来展示该过程。
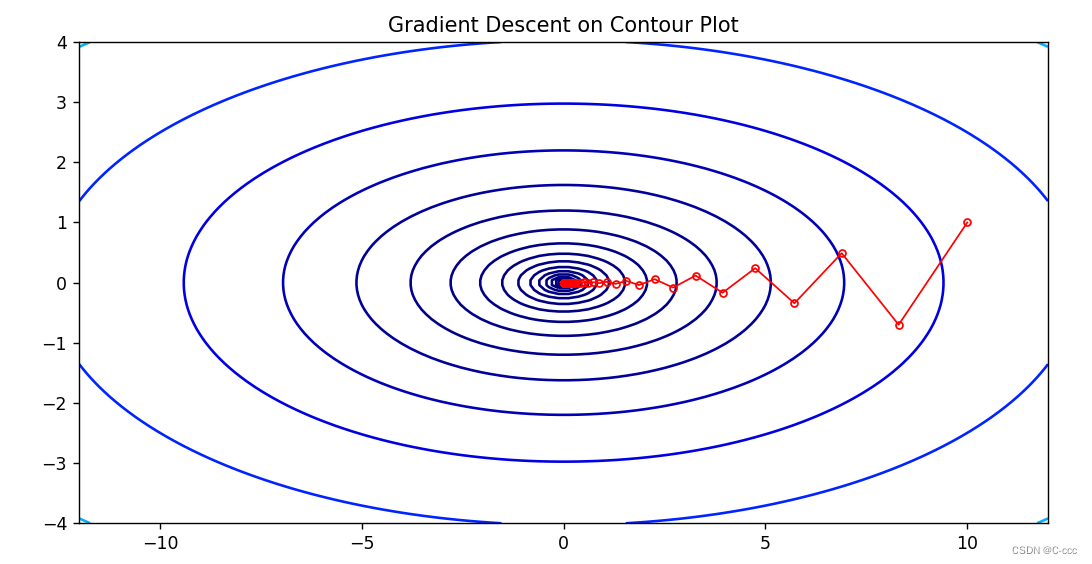
例 6.2 (二次函数的梯度法) 设二次函数 f ( x , y ) = x 2 + 10 y 2 f(x,y)=x^2+10y^2 f(x,y)=x2+10y2, 初始点 ( x 0 , y 0 ) (x^0,y^0) (x0,y0) 取为 (10,1),取固定步长 α k = 0.085 \alpha_k=0.085 αk=0.085。使用梯度法 x k + 1 = x k − α k ∇ f ( x k ) x^{k+1}=x^{k}-\alpha_{k}\nabla f(x^{k}) xk+1=xk−αk∇f(xk) 进行 15 次迭代,结果下图所示。
# 例 6.2
import numpy as np
import matplotlib.pyplot as plt
# 定义二次函数
def f(x):
return x[0]**2 + 10*x[1]**2
# 定义梯度计算函数
def grad_f(x):
return np.array([2*x[0], 20*x[1]])
# 定义梯度下降算法
def gradient_descent(x, alpha, iter = 300, tol = 1e-6):
x_history = [x]
k = 0
while k < iter:
x = x - alpha * grad_f(x)
x_history.append(x)
k = k + 1
if np.linalg.norm(grad_f(x)) < tol:
break
return x_history, k
# 设置初始点和迭代参数
x0 = np.array([10, 1])
alpha = 0.085
# 进行梯度下降迭代
gd_history, k = gradient_descent(x0, alpha)
print("Optimal solution:", gd_history[-1])
'''Optimal solution: [ 4.32619814e-07 -8.01533432e-15]'''
print("迭代次数:", k)
'''迭代次数: 91'''
# 定义网格点
x = np.linspace(-12, 12, 100)
y = np.linspace(-4, 4, 100)
X, Y = np.meshgrid(x, y)
Z = X**2 + 10*Y**2 # 定义目标函数
# 绘制等高线图
plt.figure(figsize=(10, 5))
plt.contour(X, Y, Z, levels=np.logspace(-2, 3, 20), cmap='jet') # levels 参数控制等高线的密集程度
plt.plot([x[0] for x in gd_history], [x[1] for x in gd_history], marker='o',markersize=4, linewidth=1, color = 'red', markerfacecolor='none', label='Gradient Descent')
plt.title('Gradient Descent on Contour Plot')
plt.show()
定理 6.2 (二次函数的收敛定理) 考虑正定二次函数
f ( x ) = 1 2 x T A x − b T x f(x)=\frac{1}{2}x^\mathrm{T}Ax-b^\mathrm{T}x f(x)=21xTAx−bTx其最优值点为 x ∗ x^* x∗。若使用梯度法 (6.2.1) 并选取 α k \alpha_k αk 为精确线搜索步长,即
α k = ∥ ∇ f ( x k ) ∥ 2 ∇ f ( x k ) T A ∇ f ( x k ) ( 6.2.2 ) \alpha_k=\frac{\|\nabla f(x^k)\|^2}{\nabla f(x^k)^\text{T}A\nabla f(x^k)}\qquad(6.2.2) αk=∇f(xk)TA∇f(xk)∥∇f(xk)∥2(6.2.2)则梯度法关于迭代点列 { x k } \{x^k\} {xk} 是 Q-线性收敛的,即
∥ x k + 1 − x ∗ ∥ A 2 ⩽ ( λ 1 − λ n λ 1 + λ n ) 2 ∥ x k − x ∗ ∥ A 2 \|x^{k+1}-x^*\|_A^2\leqslant\left(\frac{\lambda_1-\lambda_n}{\lambda_1+\lambda_n}\right)^2\|x^k-x^*\|_A^2 ∥xk+1−x∗∥A2⩽(λ1+λnλ1−λn)2∥xk−x∗∥A2其中 λ 1 , λ n \lambda_1,\lambda_n λ1,λn 分别为 A A A 的最大、最小特征值, ∥ x ∥ A = d e f x T A x \|x\|_A\xlongequal{\mathrm{def}}\sqrt{x^{\mathrm{T}}Ax} ∥x∥AdefxTAx 为由正定矩阵 A A A 诱导的范数。
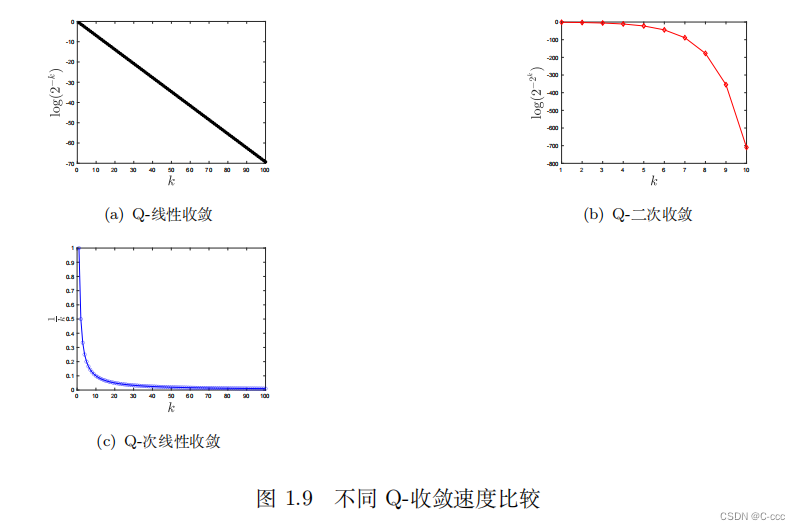
回顾 Q-收敛速度
以点列的 Q-收敛速度 (Q 的含义为“quotient”) 为例 (函数值的 Q-收敛速度可以类似地定义)。设 { x k } \{x^k\} {xk} 为算法产生的迭代点列且收敛于 x ∗ x^* x∗,若对充分大的 k k k 有
∥ x k + 1 − x ∗ ∥ ∥ x k − x ∗ ∥ ⩽ a , a ∈ ( 0 , 1 ) , \frac{\|x^{k+1}-x^*\|}{\|x^k-x^*\|}\leqslant a,\quad a\in(0,1), ∥xk−x∗∥∥xk+1−x∗∥⩽a,a∈(0,1),则称算法 (点列) 是 Q-线性收敛的;若满足
lim k → ∞ ∥ x k + 1 − x ∗ ∥ ∥ x k − x ∗ ∥ = 0 , \lim\limits_{k\to\infty}\frac{\|x^{k+1}-x^*\|}{\|x^k-x^*\|}=0, k→∞lim∥xk−x∗∥∥xk+1−x∗∥=0,称算法(点列)是 Q-超线性收敛的;若满足
lim k → ∞ ∥ x k + 1 − x ∗ ∥ x k − x ∗ = 1 , \lim\limits_{k\to\infty}\frac{\|x^{k+1}-x^*\|}{x^k-x^*}=1, k→∞limxk−x∗∥xk+1−x∗∥=1,称算法 (点列) 是 Q-次线性收敛的. 若对充分大的 k k k 满足
∥ x k + 1 − x ∗ ∥ ∥ x k − x ∗ ∥ 2 ⩽ a , a > 0 , \frac{\lVert x^{k+1}-x^*\rVert}{\lVert x^k-x^*\rVert^2}\leqslant a,\quad a>0, ∥xk−x∗∥2∥xk+1−x∗∥⩽a,a>0,则称算法 (点列) 是 Q-二次收敛的. 类似地,也可定义更一般的 Q-r 次收敛( r > 1 r>1 r>1).
点列 { 2 − k } \{2^{-k}\} {2−k} 是 Q-线性收敛的,点列 { 2 − 2 k } \{2^{-2^k}\} {2−2k} 是 Q-二次收敛的 (也是 Q-超线性收敛的), 点列 { 1 k } \{\frac1k\} {k1} 是 Q-次线性收敛的. 一般来说,具有 Q-超线性收敛速度和 Q-二次收敛速度的算法是收敛较快的.
R-收敛速度
以点列的 R-收敛速度 (R 的含义为“root”) 为例,设 { x k } \{x^k\} {xk} 为算法产生的迭代点列且收敛于 x ∗ x^* x∗,若存在 Q-线性收敛于 0 的非负序列 { t k } \{t_k\} {tk} 并且
∥ x k − x ∗ ∥ ⩽ t k \|x^k-x^*\|\leqslant t_k ∥xk−x∗∥⩽tk对任意的 k k k 成立,则称算法 (点列) 是 R-线性收敛的. 类似地,可定义 R-超线性收敛和 R-二次收敛等收敛速度. 从 R-收敛速度的定义可以看出序列 { ∥ x k − x ∗ ∥ } \{\|x^k-x^*\|\} {∥xk−x∗∥} 被另一趋于 0 的序列 { t k } \{t_k\} {tk} 控制. 当知道 t k t_k tk 的形式时,我们也称算法 (点列) 的收敛速度为 O ( t k ) \mathcal{O}(t_k) O(tk).
定理 6.2 指出使用精确线搜索的梯度法在正定二次问题上有 Q-线性收敛速度。线性收敛速度的常数和矩阵 A A A 最大特征值与最小特征值之比有关。从等高线角度来看,这个比例越大则 f ( x ) f(x) f(x) 的等高线越扁平,迭代路径折返频率会随之变高,梯度法收敛也就越慢。这个结果其实说明了梯度法的一个很重大的缺陷:当目标函数的海瑟矩阵条件数较大时,它的收敛速度会非常缓慢。
接下来介绍当
f
(
x
)
f(x)
f(x) 为梯度利普希茨连续的凸函数时,梯度法 (6.2.1) 的收敛性质。
首先,回顾一下定义 2.4 梯度利普希茨连续:给定可微函数
f
f
f,若存在
L
>
0
L>0
L>0,对任意的 $x, y\in
∗
∗
d
o
m
∗
∗
**dom**
∗∗dom∗∗f$ 有
∥
∇
f
(
x
)
−
∇
f
(
y
)
∥
≤
L
∥
x
−
y
∥
,
\|\nabla f(x)-\nabla f(y)\|\leq L\|x-y\|,
∥∇f(x)−∇f(y)∥≤L∥x−y∥,
则称
f
f
f 是梯度利普希茨连续的,相应利普希茨常数为
L
L
L。有时也简记为梯度
L
L
L-利普希茨连续或
L
L
L-光滑。
引理 2.1 二次上界引理:设可微函数
f
(
x
)
f(x)
f(x) 的定义域 dom
f
=
R
n
f=\mathbb{R}^n
f=Rn,且为梯度
L
L
L-利普希茨连续的,则函数
f
(
x
)
f(x)
f(x) 有二次上界:
f
(
y
)
≤
f
(
x
)
+
∇
f
(
x
)
T
(
y
−
x
)
+
L
2
∥
y
−
x
∥
2
,
∀
x
,
y
∈
d
o
m
f
f(y)\leq f(x)+\nabla f(x)^{\mathrm{T}}(y-x)+\frac L2\|y-x\|^2,\quad\forall\:x,y\in\mathrm{dom}f
f(y)≤f(x)+∇f(x)T(y−x)+2L∥y−x∥2,∀x,y∈domf
定理 6.3 (梯度法在凸函数上的收敛性) 设函数 f ( x ) f(x) f(x) 为凸的梯度 L L L-利普希茨连续函数,极小值 f ∗ = f ( x ∗ ) = inf x f ( x ) f^*=f(x^*)=\inf\limits_x f(x) f∗=f(x∗)=xinff(x) 存在且可达。如果步长 α k \alpha_k αk 取为常数 α \alpha α 且满足 0 < α < 1 L 0<\alpha<\displaystyle\frac{1}{L} 0<α<L1,那么由迭代 x k + 1 = x k − α k ∇ f ( x k ) x^{k+1}=x^{k}-\alpha_{k}\nabla f(x^{k}) xk+1=xk−αk∇f(xk) 得到的点列 { x k } \{x^k\} {xk} 的函数值收敛到最优值,且在函数值的意义下收敛速度为 O ( 1 k ) \mathcal{O}\left(\displaystyle\frac{1}{k}\right) O(k1).
证明. 因为函数 f f f 是利普希茨可微函数,对任意的 x x x, 根据二次上界引理得到,
f ( x − α ∇ f ( x ) ) ⩽ f ( x ) − α ( 1 − L α 2 ) ∥ ∇ f ( x ) ∥ 2 ( 6.2.3 ) \begin{aligned}f(x-\alpha\nabla f(x))\leqslant f(x)-\alpha\left(1-\frac{L\alpha}{2}\right)\|\nabla f(x)\|^2\end{aligned}\qquad(6.2.3) f(x−α∇f(x))⩽f(x)−α(1−2Lα)∥∇f(x)∥2(6.2.3)记 x ~ = x − α ∇ f ( x ) \tilde{x}=x-\alpha\nabla f(x) x~=x−α∇f(x) 并限制 0 < α < 1 L 0<\alpha<\frac1L 0<α<L1, 我们有
f ( x ~ ) ⩽ f ( x ) − α 2 ∥ ∇ f ( x ) ∥ 2 ⩽ f ∗ + ∇ f ( x ) T ( x − x ∗ ) − α 2 ∥ ∇ f ( x ) ∥ 2 = f ∗ + 1 2 α ( ∥ x − x ∗ ∥ 2 − ∥ x − x ∗ − α ∇ f ( x ) ∥ 2 ) = f ∗ + 1 2 α ( ∥ x − x ∗ ∥ 2 − ∥ x ~ − x ∗ ∥ 2 ) \begin{aligned} f(\tilde{x})& \leqslant f(x)-\frac{\alpha}{2}\|\nabla f(x)\|^{2} \\ &\leqslant f^{*}+\nabla f(x)^{\mathrm{T}}(x-x^{*})-\frac{\alpha}{2}\|\nabla f(x)\|^{2} \\ &=f^*+\frac{1}{2\alpha}\left(\|x-x^*\|^2-\|x-x^*-\alpha\nabla f(x)\|^2\right) \\ &=f^{*}+\frac{1}{2\alpha}(\|x-x^{*}\|^{2}-\|\tilde{x}-x^{*}\|^{2}) \end{aligned} f(x~)⩽f(x)−2α∥∇f(x)∥2⩽f∗+∇f(x)T(x−x∗)−2α∥∇f(x)∥2=f∗+2α1(∥x−x∗∥2−∥x−x∗−α∇f(x)∥2)=f∗+2α1(∥x−x∗∥2−∥x~−x∗∥2)其中第一个不等式是由于 0 < α < 1 L 0<\alpha<\frac1L 0<α<L1,第二个不等式为 f f f 的凸性. 在上式中取 x = x i − 1 , x ~ = x i x=x^{i-1},\tilde{x}=x^i x=xi−1,x~=xi 并将不等式对 i = 1 , 2 , ⋅ ⋅ ⋅ , k i=1,2,···,k i=1,2,⋅⋅⋅,k 求和得到
∑ i = 1 k ( f ( x i ) − f ∗ ) ⩽ 1 2 α ∑ i = 1 k ( ∥ x i − 1 − x ∗ ∥ 2 − ∥ x i − x ∗ ∥ 2 ) = 1 2 α ( ∥ x 0 − x ∗ ∥ 2 − ∥ x k − x ∗ ∥ 2 ) ⩽ 1 2 α ∥ x 0 − x ∗ ∥ 2 \begin{aligned}\sum_{i=1}^k(f(x^i)-f^*)&\leqslant\frac{1}{2\alpha}\sum_{i=1}^k(\|x^{i-1}-x^*\|^2-\|x^i-x^*\|^2)\\&=\frac{1}{2\alpha}(\|x^0-x^*\|^2-\|x^k-x^*\|^2)\\&\leqslant\frac{1}{2\alpha}\|x^0-x^*\|^2\end{aligned} i=1∑k(f(xi)−f∗)⩽2α1i=1∑k(∥xi−1−x∗∥2−∥xi−x∗∥2)=2α1(∥x0−x∗∥2−∥xk−x∗∥2)⩽2α1∥x0−x∗∥2由于 f ( x i ) f(x^i) f(xi) 是非增的,所以
f ( x k ) − f ∗ ⩽ 1 k ∑ i = 1 k ( f ( x i ) − f ∗ ) ⩽ 1 2 k α ∥ x 0 − x ∗ ∥ 2 f(x^k)-f^*\leqslant\frac{1}{k}\sum_{i=1}^k(f(x^i)-f^*)\leqslant\frac{1}{2k\alpha}\|x^0-x^*\|^2 f(xk)−f∗⩽k1i=1∑k(f(xi)−f∗)⩽2kα1∥x0−x∗∥2
如果函数 f f f 还是 m m m-强凸函数,则梯度法的收敛速度会进一步提升为 Q Q Q-线性收敛。
在给出收敛性证明之前,我们需要以下的引理来揭示凸的梯度 L L L-利普希茨连续函数的另一个重要性质。
引理 6.1 设函数 f ( x ) f(x) f(x) 是 R n \mathbb{R}^n Rn 上的凸可微函数,则以下结论等价:
(1) f f f 的梯度为 L L L-利普希茨连续的;
(2) 函数 g ( x ) = d e f L 2 x T x − f ( x ) g(x)\stackrel{\mathrm{def}}{=}\displaystyle\frac{L}{2}x^\mathrm{T}x-f(x) g(x)=def2LxTx−f(x) 是凸函数;
(3) ∇ f ( x ) \nabla f(x) ∇f(x) 有余强制性,即对任意的 x , y ∈ R n x,y\in\mathbb{R}^n x,y∈Rn,有
( ∇ f ( x ) − ∇ f ( y ) ) T ( x − y ) ⩾ 1 L ∥ ∇ f ( x ) − ∇ f ( y ) ∥ 2 ( 6.2.4 ) (\nabla f(x)-\nabla f(y))^{\mathrm{T}}(x-y)\geqslant\frac{1}{L}\|\nabla f(x)-\nabla f(y)\|^{2}\qquad(6.2.4) (∇f(x)−∇f(y))T(x−y)⩾L1∥∇f(x)−∇f(y)∥2(6.2.4)证明.
( 1 ) ⟹ ( 2 ) (1)\Longrightarrow(2) (1)⟹(2)
我们已知 f ( x ) f(x) f(x) 是凸可微函数且其梯度为 L L L -利普希茨连续的,则我们需要证明函数 g ( x ) = L 2 x T x − f ( x ) g(x)=\frac L2x^{\mathrm{T}}x-f(x) g(x)=2LxTx−f(x) 是凸函数。为了证明 g ( x ) g(x) g(x) 是凸函数,我们需要证明对于任意的 x , y ∈ R n x,y\in\mathbb{R}^n x,y∈Rn 和 0 ⩽ λ ⩽ 1 0\leqslant\lambda\leqslant1 0⩽λ⩽1,有
g ( λ x + ( 1 − λ ) y ) ⩽ λ g ( x ) + ( 1 − λ ) g ( y ) g(\lambda x+(1-\lambda)y)\leqslant\lambda g(x)+(1-\lambda)g(y) g(λx+(1−λ)y)⩽λg(x)+(1−λ)g(y)即需要证明 g ( x ) g(x) g(x) 的上凸性。首先,由于 f ( x ) f(x) f(x) 是凸函数,则根据凸函数的定义,对于任意的 x , y ∈ R n x,y\in\mathbb{R}^n x,y∈Rn 和 0 ≤ λ ≤ 1 0\leq\lambda\leq1 0≤λ≤1,有
f ( λ x + ( 1 − λ ) y ) ⩽ λ f ( x ) + ( 1 − λ ) f ( y ) f(\lambda x+(1-\lambda)y)\leqslant\lambda f(x)+(1-\lambda)f(y) f(λx+(1−λ)y)⩽λf(x)+(1−λ)f(y)因为 g ( x ) = L 2 x T x − f ( x ) g(x)=\frac L2x^{\mathrm{T}}x-f(x) g(x)=2LxTx−f(x),所以我们可以把上式左右两边都加上 L 2 ( λ x + ( 1 − λ ) y ) T ( λ x + ( 1 − λ ) y ) \frac L2(\lambda x+(1-\lambda)y)^{\mathrm{T}}(\lambda x+(1-\lambda)y) 2L(λx+(1−λ)y)T(λx+(1−λ)y),得到
g ( λ x + ( 1 − λ ) y ) + L 2 ( λ x + ( 1 − λ ) y ) T ( λ x + ( 1 − λ ) y ) ⩽ λ g ( x ) + L 2 x T x − f ( x ) + ( 1 − λ ) g ( y ) + L 2 y T y − f ( y ) g(\lambda x+(1-\lambda)y)+\frac L2(\lambda x+(1-\lambda)y)^\mathrm{T}(\lambda x+(1-\lambda)y)\leqslant\lambda g(x)+\frac L2x^\mathrm{T}x-f(x)+(1-\lambda)g(y)+\frac L2y^\mathrm{T}y-f(y) g(λx+(1−λ)y)+2L(λx+(1−λ)y)T(λx+(1−λ)y)⩽λg(x)+2LxTx−f(x)+(1−λ)g(y)+2LyTy−f(y)简化后可得
g ( λ x + ( 1 − λ ) y ) ⩽ λ g ( x ) + ( 1 − λ ) g ( y ) + L 2 λ ( 1 − λ ) ( x − y ) T ( x − y ) g(\lambda x+(1-\lambda)y)\leqslant\lambda g(x)+(1-\lambda)g(y)\:+\frac L2\lambda(1-\lambda)(x-y)^{\mathrm{T}}(x-y) g(λx+(1−λ)y)⩽λg(x)+(1−λ)g(y)+2Lλ(1−λ)(x−y)T(x−y)因为 L L L 是 f ( x ) f(x) f(x) 的梯度的 Lipschitz 常数,因此有
∥ ∇ f ( x ) − ∇ f ( y ) ∥ ≤ L ∥ x − y ∥ \|\nabla f(x)-\nabla f(y)\|\leq L\|x-y\| ∥∇f(x)−∇f(y)∥≤L∥x−y∥根据梯度的定义,我们有
∇ f ( x ) T ( x − y ) ⩾ f ( x ) − f ( y ) + L 2 ∥ x − y ∥ 2 \nabla f(x)^{\mathrm{T}}(x-y)\geqslant f(x)-f(y)+\frac L2\|x-y\|^2 ∇f(x)T(x−y)⩾f(x)−f(y)+2L∥x−y∥2同样地,我们可以得到
∇ f ( y ) T ( x − y ) ⩾ f ( x ) − f ( y ) + L 2 ∥ x − y ∥ 2 \nabla f(y)^{\mathrm{T}}(x-y)\geqslant f(x)-f(y)+\frac L2\|x-y\|^2 ∇f(y)T(x−y)⩾f(x)−f(y)+2L∥x−y∥2将两式相减,可得
( ∇ f ( x ) − ∇ f ( y ) ) T ( x − y ) ⩾ L ∥ x − y ∥ 2 (\nabla f(x)-\nabla f(y))^{\mathrm{T}}(x-y)\geqslant L\|x-y\|^2 (∇f(x)−∇f(y))T(x−y)⩾L∥x−y∥2根据此式,我们可以继续推导得到
g ( λ x + ( 1 − λ ) y ) ⩽ λ g ( x ) + ( 1 − λ ) g ( y ) + L 2 λ ( 1 − λ ) ∥ x − y ∥ 2 = λ g ( x ) + ( 1 − λ ) g ( y ) + L 2 ∥ λ x + ( 1 − λ ) y − x ∥ 2 g(\lambda x+(1-\lambda)y)\leqslant\lambda g(x)+(1-\lambda)g(y)+\frac L2\lambda(1-\lambda)\|x-y\|^2=\lambda g(x)+(1-\lambda)g(y)+\frac L2\|\lambda x+(1-\lambda)y-x\|^2 g(λx+(1−λ)y)⩽λg(x)+(1−λ)g(y)+2Lλ(1−λ)∥x−y∥2=λg(x)+(1−λ)g(y)+2L∥λx+(1−λ)y−x∥2由此可知 g ( x ) g(x) g(x) 是凸的。
( 2 ) ⟹ ( 3 ) (2)\Longrightarrow (3) (2)⟹(3) 构造辅助函数
f x ( z ) = f ( z ) − ∇ f ( x ) T z f y ( z ) = f ( z ) − ∇ f ( y ) T z \begin{aligned}f_{x}(z)=f(z)-\nabla f(x)^{\mathrm{T}}z\\ f_y(z)=f(z)-\nabla f(y)^\mathrm{T}z \end{aligned} fx(z)=f(z)−∇f(x)Tzfy(z)=f(z)−∇f(y)Tz首先验证 f x ( z ) f_x(z) fx(z) 为凸函数。考虑 f x ( z ) f_x(z) fx(z),其定义为 f x ( z ) = f ( z ) − ∇ f ( x ) T z f_x(z)=f(z)-\nabla f(x)^{\mathrm{T}}z fx(z)=f(z)−∇f(x)Tz。要证明 f x ( z ) f_x(z) fx(z) 是凸函数,需要验证对于任意的 z 1 , z 2 ∈ R n z_1,z_2\in\mathbb{R}^n z1,z2∈Rn 和 0 ≤ λ ≤ 1 0\leq\lambda\leq1 0≤λ≤1,有
f x ( λ z 1 + ( 1 − λ ) z 2 ) ≤ λ f x ( z 1 ) + ( 1 − λ ) f x ( z 2 ) f_x(\lambda z_1+(1-\lambda)z_2)\leq\lambda f_x(z_1)+(1-\lambda)f_x(z_2) fx(λz1+(1−λ)z2)≤λfx(z1)+(1−λ)fx(z2)考虑左边的表达式:
f x ( λ z 1 + ( 1 − λ ) z 2 ) = f ( λ z 1 + ( 1 − λ ) z 2 ) − ∇ f ( x ) T ( λ z 1 + ( 1 − λ ) z 2 ) = λ f ( z 1 ) + ( 1 − λ ) f ( z 2 ) − λ ∇ f ( x ) T z 1 − ( 1 − λ ) ∇ f ( x ) T z 2 \begin{aligned} f_x(\lambda z_1+(1-\lambda)z_2)& =f(\lambda z_1+(1-\lambda)z_2)-\nabla f(x)^{\mathrm{T}}(\lambda z_1+(1-\lambda)z_2) \\ &=\lambda f(z_1)+(1-\lambda)f(z_2)-\lambda\nabla f(x)^\mathrm{T}z_1-(1-\lambda)\nabla f(x)^\mathrm{T}z_2 \end{aligned} fx(λz1+(1−λ)z2)=f(λz1+(1−λ)z2)−∇f(x)T(λz1+(1−λ)z2)=λf(z1)+(1−λ)f(z2)−λ∇f(x)Tz1−(1−λ)∇f(x)Tz2再考虑右边的表达式:
λ f x ( z 1 ) + ( 1 − λ ) f x ( z 2 ) = λ ( f ( z 1 ) − ∇ f ( x ) T z 1 ) + ( 1 − λ ) ( f ( z 2 ) − ∇ f ( x ) T z 2 ) = λ f ( z 1 ) + ( 1 − λ ) f ( z 2 ) − λ ∇ f ( x ) T z 1 − ( 1 − λ ) ∇ f ( x ) T z 2 \begin{aligned} \lambda f_x(z_1)+(1-\lambda)f_x(z_2)& =\lambda(f(z_1)-\nabla f(x)^\mathrm{T}z_1)+(1-\lambda)(f(z_2)-\nabla f(x)^\mathrm{T}z_2) \\ &=\lambda f(z_1)+(1-\lambda)f(z_2)-\lambda\nabla f(x)^\mathrm{T}z_1-(1-\lambda)\nabla f(x)^\mathrm{T}z_2 \end{aligned} λfx(z1)+(1−λ)fx(z2)=λ(f(z1)−∇f(x)Tz1)+(1−λ)(f(z2)−∇f(x)Tz2)=λf(z1)+(1−λ)f(z2)−λ∇f(x)Tz1−(1−λ)∇f(x)Tz2由上述计算可知, f x ( z ) f_x(z) fx(z) 满足凸函数的定义,因此 f x ( z ) f_x(z) fx(z) 是凸函数。同理可证明 f y ( z ) f_y(z) fy(z) 也是凸函数。
根据已知条件, g x ( z ) = L 2 z T z − f x ( z ) g_x(z)=\frac L2z^\mathrm{T}z-f_x(z) gx(z)=2LzTz−fx(z) 关于 z z z 是凸函数. 根据凸函数的性质,我们有
g x ( z 2 ) ⩾ g x ( z 1 ) + ∇ g x ( z 1 ) T ( z 2 − z 1 ) , ∀ z 1 , z 2 ∈ R n . g_{x}(z_{2})\geqslant g_{x}(z_{1})+\nabla g_{x}(z_{1})^{\mathrm{T}}(z_{2}-z_{1}),\quad\forall\:z_{1},z_{2}\in\mathbb{R}^{n}. gx(z2)⩾gx(z1)+∇gx(z1)T(z2−z1),∀z1,z2∈Rn.将 g x ( z ) g_x(z) gx(z) 展开得:
g x ( z 2 ) = L 2 z 2 T z 2 − f x ( z 2 ) g x ( z 1 ) = L 2 z 1 T z 1 − f x ( z 1 ) \begin{gathered} g_{x}(z_{2}) =\frac L2z_{2}^{\mathrm{T}}z_{2}-f_{x}(z_{2}) \\ g_{x}(z_{1}) =\frac{L}{2}z_{1}^{\mathrm{T}}z_{1}-f_{x}(z_{1}) \end{gathered} gx(z2)=2Lz2Tz2−fx(z2)gx(z1)=2Lz1Tz1−fx(z1)将上述两个式子代入凸函数性质的公式中,得到
L 2 z 2 T z 2 − f x ( z 2 ) ≥ L 2 z 1 T z 1 − f x ( z 1 ) + ∇ g x ( z 1 ) T ( z 2 − z 1 ) \frac L2z_2^\mathrm{T}z_2-f_x(z_2)\geq\frac L2z_1^\mathrm{T}z_1-f_x(z_1)+\nabla g_x(z_1)^\mathrm{T}(z_2-z_1) 2Lz2Tz2−fx(z2)≥2Lz1Tz1−fx(z1)+∇gx(z1)T(z2−z1)移项整理得到
f x ( z 1 ) − f x ( z 2 ) ≤ L 2 ( z 2 T z 2 − z 1 T z 1 ) − ∇ g x ( z 1 ) T ( z 2 − z 1 ) f_{x}(z_{1})-f_{x}(z_{2})\leq\frac{L}{2}(z_{2}^{\mathrm{T}}z_{2}-z_{1}^{\mathrm{T}}z_{1})-\nabla g_{x}(z_{1})^{\mathrm{T}}(z_{2}-z_{1}) fx(z1)−fx(z2)≤2L(z2Tz2−z1Tz1)−∇gx(z1)T(z2−z1)因为 f x ( z 1 ) − f x ( z 2 ) f_x(z_1)-f_x(z_2) fx(z1)−fx(z2) 在右端是一个二次函数,所以 f x ( z ) f_x(z) fx(z) 有二次上界,且对应的系数为 L L L 。
注意到 ∇ f x ( x ) = 0 \nabla f_x(x)=0 ∇fx(x)=0, 这说明 x x x 是 f x ( z ) f_x(z) fx(z) 的最小值点. 再由梯度 L L L-利普希茨函数的性质,
f x ( y ) − f x ( x ) = f ( y ) − f ( x ) − ∇ f ( x ) T ( y − x ) ⩾ 1 2 L ∥ ∇ f x ( y ) ∥ 2 = 1 2 L ∥ ∇ f ( y ) − ∇ f ( x ) ∥ 2 . \begin{aligned} f_{x}(y)-f_{x}(x)& =f(y)-f(x)-\nabla f(x)^{\mathrm{T}}(y-x) \\ &\geqslant\frac{1}{2L}\|\nabla f_{x}(y)\|^{2}=\frac{1}{2L}\|\nabla f(y)-\nabla f(x)\|^{2}. \end{aligned} fx(y)−fx(x)=f(y)−f(x)−∇f(x)T(y−x)⩾2L1∥∇fx(y)∥2=2L1∥∇f(y)−∇f(x)∥2.同理,对 f y ( z ) f_y(z) fy(z) 进行类似的分析可得
f ( x ) − f ( y ) − ∇ f ( y ) T ( x − y ) ⩾ 1 2 L ∥ ∇ f ( y ) − ∇ f ( x ) ∥ 2 . f(x)-f(y)-\nabla f(y)^{\mathrm{T}}(x-y)\geqslant\frac{1}{2L}\|\nabla f(y)-\nabla f(x)\|^{2}. f(x)−f(y)−∇f(y)T(x−y)⩾2L1∥∇f(y)−∇f(x)∥2.将以上两式不等号左右分别相加,可得余强制性 (6.2.4).
( 3 ) ⟹ ( 1 ) (3)\implies(1) (3)⟹(1) 由余强制性和柯西不等式,
1 L ∥ ∇ f ( x ) − ∇ f ( y ) ∥ 2 ⩽ ( ∇ f ( x ) − ∇ f ( y ) ) T ( x − y ) ⩽ ∥ ∇ f ( x ) − ∇ f ( y ) ∥ ∥ x − y ∥ \begin{aligned} \frac{1}{L}\|\nabla f(x)-\nabla f(y)\|^{2}& \leqslant(\nabla f(x)-\nabla f(y))^{\mathrm{T}}(x-y) \\ &\leqslant\|\nabla f(x)-\nabla f(y)\|\|x-y\| \end{aligned} L1∥∇f(x)−∇f(y)∥2⩽(∇f(x)−∇f(y))T(x−y)⩽∥∇f(x)−∇f(y)∥∥x−y∥整理后即可得到 f ( x ) f(x) f(x) 是梯度 L L L-利普希茨连续的.
引理 6.1 说明在 f f f 为凸函数的条件下,梯度 L-利普希茨连续、二次上界、余强制性三者是等价的,知道其中一个性质就可推出剩下两个。接下来给出梯度法在强凸函数下的收敛性。
定理 6.4 (梯度法在强凸函数上的收敛性) 设函数 f ( x ) f(x) f(x) 为 m m m-强凸的梯度 L L L-利普希茨连续函数, f ∗ = f ( x ∗ ) = inf x f ( x ) f^*=f(x^*)=\inf\limits_x f(x) f∗=f(x∗)=xinff(x) 存在且可达。如果步长 α \alpha α 满足 0 < α ⩽ 2 m + L 0<\alpha\leqslant\displaystyle\frac{2}{m+L} 0<α⩽m+L2,那么由梯度下降法 (6.2.1) 迭代得到的点列 { x k } \{x^k\} {xk} 收敛到 x ∗ x^* x∗,且为 Q Q Q-线性收敛。
证明. 首先根据 f f f 强凸且 ∇ f \nabla f ∇f 利普希茨连续,可得
g ( x ) = f ( x ) − m 2 x T x g(x)=f(x)-\frac{m}{2}x^{\mathrm{T}}x g(x)=f(x)−2mxTx为凸函数且 L − m 2 x T x − g ( x ) \displaystyle\frac{L-m}{2}x^{\mathrm{T}}x-g(x) 2L−mxTx−g(x)为凸函数. 由引理 6.1 可得 g ( x ) g(x) g(x) 是梯度 ( L − m L-m L−m)-利普希茨连续的. 再次利用引理 6.1 可得关于 g ( x ) g(x) g(x) 的余强制性
( ∇ g ( x ) − ∇ g ( y ) ) T ( x − y ) ⩾ 1 L − m ∥ ∇ g ( x ) − ∇ g ( y ) ∥ 2 ( 6.2.5 ) (\nabla g(x)-\nabla g(y))^{\mathrm{T}}(x-y)\geqslant\frac{1}{L-m}\|\nabla g(x)-\nabla g(y)\|^2\qquad(6.2.5) (∇g(x)−∇g(y))T(x−y)⩾L−m1∥∇g(x)−∇g(y)∥2(6.2.5)代入 g ( x ) g(x) g(x) 的表达式,可得
( ∇ f ( x ) − ∇ f ( y ) ) T ( x − y ) ⩾ m L m + L ∥ x − y ∥ 2 + 1 m + L ∥ ∇ f ( x ) − ∇ f ( y ) ∥ 2 . ( 6.2.6 ) \begin{aligned}(\nabla f(x)-\nabla f(y))^\text{T}(x-y)\geqslant\frac{mL}{m+L}\|x-y\|^2+\frac{1}{m+L}\|\nabla f(x)-\nabla f(y)\|^2.\end{aligned}\qquad(6.2.6) (∇f(x)−∇f(y))T(x−y)⩾m+LmL∥x−y∥2+m+L1∥∇f(x)−∇f(y)∥2.(6.2.6)再估计固定步长下梯度法的收敛速度. 设步长 α ∈ ( 0 , 2 m + L ] \alpha\in\left(0,\displaystyle\frac{2}{m+L}\right] α∈(0,m+L2], 对 x k , x ∗ x^k,x^∗ xk,x∗ 应用上式并注意到 ∇ f ( x ∗ ) = 0 \nabla f(x^*)=0 ∇f(x∗)=0 得
∥ x k + 1 − x ∗ ∥ 2 = ∥ x k − α ∇ f ( x k ) − x ∗ ∥ 2 = ∥ x k − x ∗ ∥ 2 − 2 α ∇ f ( x k ) T ( x k − x ∗ ) + α 2 ∥ ∇ f ( x k ) ∥ 2 ⩽ ( 1 − α 2 m L m + L ) ∥ x k − x ∗ ∥ 2 + α ( α − 2 m + L ) ∥ ∇ f ( x k ) ∥ 2 ⩽ ( 1 − α 2 m L m + L ) ∥ x k − x ∗ ∥ 2 \begin{aligned} \|x^{k+1}-x^{*}\|^{2}& =\|x^{k}-\alpha\nabla f(x^{k})-x^{*}\|^{2} \\ &=\|x^{k}-x^{*}\|^{2}-2\alpha\nabla f(x^{k})^{\mathrm{T}}(x^{k}-x^{*})+\alpha^{2}\|\nabla f(x^{k})\|^{2} \\ &\leqslant\left(1-\alpha\frac{2mL}{m+L}\right)\|x^{k}-x^{*}\|^{2}+\alpha\left(\alpha-\frac{2}{m+L}\right)\|\nabla f(x^{k})\|^{2} \\ &\leqslant\left(1-\alpha\frac{2mL}{m+L}\right)\|x^{k}-x^{*}\|^{2} \end{aligned} ∥xk+1−x∗∥2=∥xk−α∇f(xk)−x∗∥2=∥xk−x∗∥2−2α∇f(xk)T(xk−x∗)+α2∥∇f(xk)∥2⩽(1−αm+L2mL)∥xk−x∗∥2+α(α−m+L2)∥∇f(xk)∥2⩽(1−αm+L2mL)∥xk−x∗∥2⟹ ∥ x k − x ∗ ∥ 2 ⩽ c k ∥ x 0 − x ∗ ∥ 2 , c = 1 − α 2 m L m + L < 1 , \Longrightarrow\|x^k-x^*\|^2\leqslant c^k\|x^0-x^*\|^2,\quad c=1-\alpha\frac{2mL}{m+L}<1, ⟹∥xk−x∗∥2⩽ck∥x0−x∗∥2,c=1−αm+L2mL<1,
即在强凸函数的条件下,梯度法是 Q Q Q-线性收敛的.
6.2.2 Barzilai-Borwein 方法
由上一小节可以知道,当问题的条件数很大,也即问题比较病态时,梯度下降法的收敛性质会受到很大影响。Barzilai-Borwein (BB) 方法是一种特殊的梯度法,经常比一般的梯度法有着更好的效果。从形式上来看,BB 方法的下降方向仍是点
x
k
x^k
xk 处的负梯度方向
−
∇
f
(
x
k
)
-\nabla f(x^k)
−∇f(xk),但步长
α
k
\alpha_k
αk 并不是直接由线搜索算法给出的。考虑梯度下降法的格式:
x
k
+
1
=
x
k
−
α
k
∇
f
(
x
k
)
⟺
x
k
+
1
=
x
k
−
D
k
∇
f
(
x
k
)
x^{k+1}=x^{k}-\alpha_{k}\nabla f(x^{k})\Longleftrightarrow x^{k+1}=x^{k}-D^{k}\nabla f(x^{k})
xk+1=xk−αk∇f(xk)⟺xk+1=xk−Dk∇f(xk)
其中
D
k
=
α
k
I
D^k=\alpha_kI
Dk=αkI。BB 方法选取的
α
k
\alpha_k
αk 是如下两个最优问题之一的解:
min
α
∥
α
y
k
−
1
−
s
k
−
1
∥
2
(
6.2.7
)
\min_{\alpha}\quad\|\alpha y^{k-1}-s^{k-1}\|^{2}\qquad(6.2.7)
αmin∥αyk−1−sk−1∥2(6.2.7)
min α ∥ y k − 1 − α − 1 s k − 1 ∥ 2 ( 6.2.8 ) \min_{\alpha}\quad\|y^{k-1}-\alpha^{-1}s^{k-1}\|^{2}\qquad(6.2.8) αmin∥yk−1−α−1sk−1∥2(6.2.8)
其中引入记号 s k − 1 = d e f x k − x k − 1 s^{k-1}\overset{\mathrm{def}}{\operatorname*{=}}x^k-x^{k-1} sk−1=defxk−xk−1 以及 y k − 1 = d e f ∇ f ( x k ) − ∇ f ( x k − 1 ) y^{k-1}\overset{\mathrm{def}}{\operatorname*{=}}\nabla f(x^k)-\nabla f(x^{k-1}) yk−1=def∇f(xk)−∇f(xk−1)。
对问题 (6.2.7) 和 (6.2.8) 分别求导取零,得到的解分别为
α
B
B
1
k
=
d
e
f
(
s
k
−
1
)
T
y
k
−
1
(
y
k
−
1
)
T
y
k
−
1
和
α
B
B
2
k
=
d
e
f
(
s
k
−
1
)
T
s
k
−
1
(
s
k
−
1
)
T
y
k
−
1
(
6.2.9
)
\alpha_{\mathrm{BB1}}^{k}\stackrel{\mathrm{def}}{=}\frac{(s^{k-1})^{\mathrm{T}}y^{k-1}}{(y^{k-1})^{\mathrm{T}}y^{k-1}}\quad\text{和}\quad\alpha_{\mathrm{BB2}}^{k}\stackrel{\mathrm{def}}{=}\frac{(s^{k-1})^{\mathrm{T}}s^{k-1}}{(s^{k-1})^{\mathrm{T}}y^{k-1}}\qquad(6.2.9)
αBB1k=def(yk−1)Tyk−1(sk−1)Tyk−1和αBB2k=def(sk−1)Tyk−1(sk−1)Tsk−1(6.2.9)
因此可以得到 BB 方法的两种迭代格式:
x
k
+
1
=
x
k
−
α
BB
1
k
∇
f
(
x
k
)
(
6.2.10
a
)
x
k
+
1
=
x
k
−
α
BB
2
k
∇
f
(
x
k
)
(
6.2.10
b
)
\begin{aligned}x^{k+1}&=x^k-\alpha_{\text{BB}1}^k\nabla f(x^k)\qquad(6.2.10a)\\x^{k+1}&=x^k-\alpha_{\text{BB}2}^k\nabla f(x^k)\qquad(6.2.10b)\end{aligned}
xk+1xk+1=xk−αBB1k∇f(xk)(6.2.10a)=xk−αBB2k∇f(xk)(6.2.10b)
计算两种 BB 步长的任何一种仅仅需要函数相邻两步的梯度信息和迭代点信息,不需要任何线搜索算法即可选取算法步长。BB 方法计算出的步长可能过大或过小,因此我们还需要将步长做上界和下界的截断,即选取 0 < α m < α M 0<\alpha_m<\alpha_M 0<αm<αM 使得
α m ⩽ α k ⩽ α M \alpha_{m}\leqslant\alpha_{k}\leqslant\alpha_{M} αm⩽αk⩽αM
还需注意的是,BB 方法本身是非单调方法,有时也配合非单调收敛准则使用以获得更好的实际效果。算法 6.2 给出了一种 BB 方法的框架。

# 算法 6.2 非单调线搜索的 BB 方法
import numpy as np
# 定义Barzilai-Borwein方法函数
def BB_method(x0, alpha0, M, c1, beta, epsilon, alpha_m, alpha_M):
x = x0
alpha = alpha0
k = 0 #迭代次数
x_history = [x]
# 开始迭代,直到梯度满足精度要求
while np.linalg.norm(grad(x)) > epsilon:
while f(x - alpha * grad(x)) >= max([f(x - j) for j in range(min(k, M) + 1)]) - c1 * alpha * np.linalg.norm(grad(x))**2:
alpha = beta * alpha
x_next = x - alpha * grad(x)
if k > 0:
s = x - x_prev
y = grad(x) - grad(x_prev)
alpha = np.dot(s, y) / np.dot(y, y)
# alpha_BB2 = np.dot(s, s) / np.dot(s, y)
alpha = np.clip(alpha, alpha_m, alpha_M) # 使用clip函数限制alpha的取值范围
x_prev = x
x = x_next
x_history.append(x)
k = k + 1
return x_history, k
我们仍然使用例 6.2 来说明 BB 方法的迭代过程.
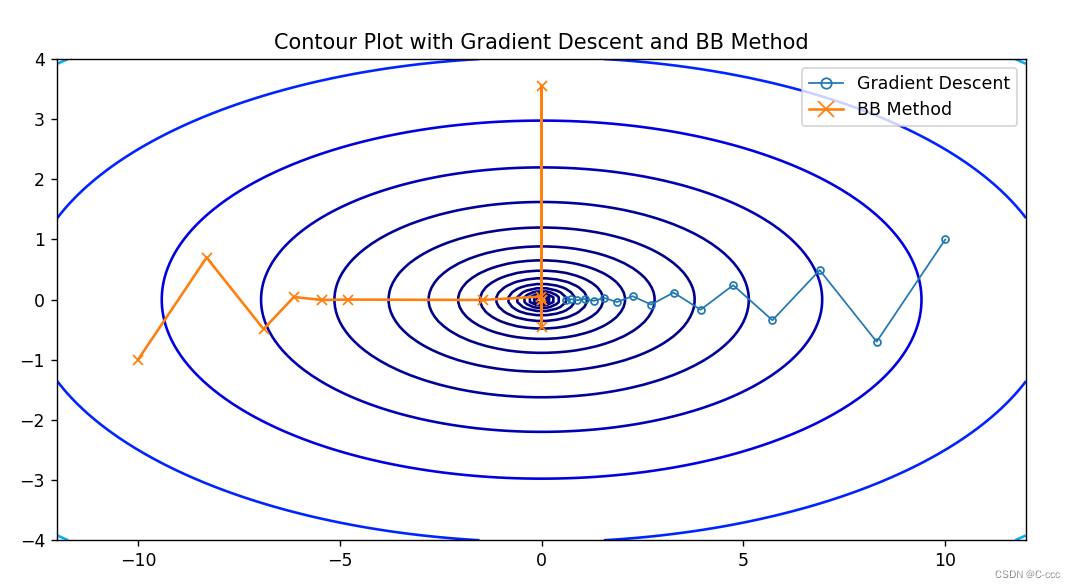
例 6.3 (二次函数的 BB 方法) 设二次函数 f ( x , y ) = x 2 + 10 y 2 f(x,y)=x^2+10y^2 f(x,y)=x2+10y2,并使用 BB 方法进行迭代,初始点为 (-10,-1),结果如图 6.5 所示。为了方便对比,我们也在此图中描绘了梯度法的迭代过程,可以很明显看出 BB 方法的收敛速度较快,在经历 11 次迭代后已经接近最优值点。BB 方法是非单调方法。实际上,对于正定二次函数,BB 方法有 R-线性收敛速度。
# 定义目标函数和其梯度函数
import numpy as np
import matplotlib.pyplot as plt
def f(x):
return x[0]**2 + 10 * x[1]**2
def grad(x):
return np.array([2*x[0], 20*x[1]])
# 梯度下降法
def gradient_descent(x0, alpha, epsilon, max_iter):
x = x0
k = 0
x_history = [x]
while np.linalg.norm(grad(x)) > epsilon and k < max_iter:
x = x - alpha * grad(x)
x_history.append(x)
k += 1
return x_history, k
x0 = np.array([10, 1])
x1 = np.array([-10, -1])
alpha0 = 0.085
M = 5
c1 = 0.1
beta = 0.5
epsilon = 1e-6
alpha_m = 1e-6
alpha_M = 1e6
# 运行梯度下降法
max_iter = 15
gd_history, gd_k = gradient_descent(x0, alpha0, epsilon, max_iter)
# 运行Barzilai-Borwein方法
bb_history, bb_k = BB_method(x1, alpha0, M, c1, beta, epsilon, alpha_m, alpha_M)
print("gd迭代次数:",gd_k,", bb迭代次数:",bb_k)
'''gd迭代次数: 15 , bb迭代次数: 11'''
# 定义网格点
x = np.linspace(-12, 12, 100)
y = np.linspace(-4, 4, 100)
X, Y = np.meshgrid(x, y)
Z = X**2 + 10*Y**2 # 定义目标函数
# 绘制目标函数的等高线图及优化路径
plt.figure(figsize=(10, 5))
plt.contour(X, Y, Z, levels=np.logspace(-2, 3, 20), cmap='jet') # levels 参数控制等高线的密集程度
plt.plot([x[0] for x in gd_history], [x[1] for x in gd_history], marker='o',markersize=4, linewidth=1, markerfacecolor='none', label='Gradient Descent')
plt.plot([x[0] for x in bb_history], [x[1] for x in bb_history], marker='x', label='BB Method') # 添加优化路径
plt.legend(loc='best', markerscale=1.5) # 设置标签位置为最佳位置,调整图例的大小
plt.title('Contour Plot with Gradient Descent and BB Method')
plt.show()















 3127
3127











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









