







Science Forum: Ten common statistical mistakes to watch out for when writing or reviewing a manuscript
《Science Forum: Ten common statistical mistakes to watch out for when writing or reviewing a manuscript》是一篇由Makin和de Xivry于2019年发表在eLife上的文章,旨在帮助研究者在论文写作或审稿中识别和避免常见的统计错误,从而提升研究的严谨性与透明度。
现在网上也有很多中文翻译版本。本文可以看作一个更容易阅读理解个人的学习笔记,对此进行了总结归纳或者注释,希望在帮助自己理解的同时方便大家学习。
继续上次的,第六个问题:
6. Circular analysis
循环验证。循环验证指以任何形式,回溯地选择数据的某个特征作为因变量进行分析,从而扭曲统计检验结果(Kriegeskorte et al., 2010)。
我觉得可以理解为先有预设,再根据这个选择观察的区域或者数据,甚至据此剔除数据。这里作者举例:
数据分割导致的伪交互效应 假设一群神经元在刺激前后活动整体而言没有变化,但是集群中有的激活,有的抑制,当研究者根据基线活动水平将神经元分组(如“低响应组”和“高响应组”)后,可能观察到显著的干预效应(如低响应组活动增强,高响应组活动减弱)。
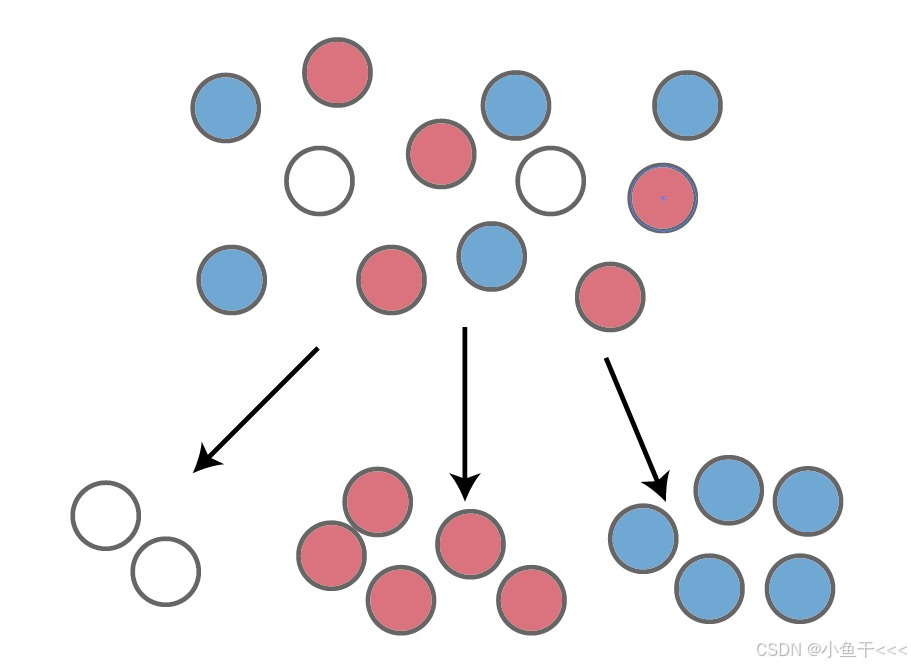
变量循环依赖的虚假相关性 若自变量(如干预后响应)与因变量(如干预前后响应差值)共享同一测量数据(干预后值),会导致相关性被夸大。 统计学上因变量与自变量的定义重叠,使随机波动被错误解释为规律性关联。
7. Flexibility of analysis: p-hacking
分析方法的多样性:p-hacking。即数据分析灵活性导致的假阳性风险。例如:通过随意调整参数(如切换变量、增减协变量、事后剔除数据)或多次检验,人为提高获得显著性p值的概率。
原因在于统计检验基于概率,分析自由度越大,假阳性率越高。 同一结果变量采用不同计算标准或者临床试验中途更改结局指标,都会导致结论不可靠。
作者因此呼吁标准化与透明化:预注册研究设计及分析流程,减少分析自由度。 接受阴性结果,鼓励严谨但可能无显著性的研究发现。
8. Failing to correct for multiple comparisons
没有进行多重比较的矫正。
分组数越多,或者因子数量越多,可以进行的检验就越多,观察到假阳性的可能性就越大。Family-wise error rate(FWER) 是统计学中用于衡量多重假设检验中至少出现一次第一类错误(假阳性)的概率。当对同一数据集进行多个独立或相关的假设检验时,每个检验的显著性水平(如α=0.05)仅控制单个检验的错误率。然而,随着检验次数的增加,至少出现一次错误的概率会显著上升。
可以通过严格校正方法(如Bonferroni、Holm等)控制这一整体错误率。但是可能过于保守,导致第二类错误(漏检真实效应)的风险增加。(这个矫正以后打算也写一写吧)。通俗解释可以理解为“连环选择题全对的概率”。假设你同时回答10道判断题,每道题有5%的可能会蒙错。如果不对错误概率加以控制,10道题中至少错一道的概率会高达40%。矫正的目标就是通过更严格的标准(比如每道题只允许0.5%的错误率),让这10道题全部正确的概率保持在95%以上。但这样严格的标准也可能让你对一些原本正确的答案过于谨慎,反而漏掉正确答案。
对此,首先要强调校正必要性:即使有初步预测,若涉及多变量/多测试,必须校正(如Bonferroni、FDR等),其次还是要标准化与透明化:公开所有测量变量和分析步骤,区分探索性与验证性分析;不同校正方法有效性差异大(参考Bennett与Eklund的研究),需在method中言明。
9. Over-interpreting non-significant results
过度解释不显著结果。
该问题可以归结为1. p值阈值的局限性:α=0.05的统计显著性标准具有主观性,且无法区分“效应不存在”与“数据不敏感”两类情况。 2.不显著结果的歧义性:未达显著性可能意味着零效应、统计效力不足掩盖的真实效应,或效应方向/强度不明确,甚至实验设计缺陷。
因此需要审慎解读结果,不显著结果需结合统计效力、效应量、置信区间等指标综合判断; 还是标准化与透明化,在文章中要明确实验设计的局限性,报告p值的同时报告效应量; 考虑使用其他补充统计方法,比如贝叶斯统计或等效检验。
贝叶斯统计(Bayesian Statistics): 基于贝叶斯定理,结合先验知识(prior)与当前数据(likelihood),计算假设的后验概率(posterior)。通过贝叶斯因子(Bayes Factor, BF)可以直接比较H₀与H₁的相对支持程度: BF₀₁ > 1:数据更支持H₀; BF₀₁ < 1:数据更支持H₁; BF₀₁ ≈ 1:数据无法区分两者(证据模糊)。 直接给出H₀或H₁的概率,避免二元化结论。 区分“无效应”与“数据不足”:
等效检验(Equivalence Test),是一种用于确定两个处理、测量或条件之间是否存在实际差异的统计方法。与传统的显著性检验不同,等效检验关注的是效果大小是否在某个预定义的等效区间内。需要研究人员根据专业知识或实际需求确定一个等效区间,该区间表示在实际应用中可以忽略不计的效果大小范围。
10. Correlation and causation
相关和因果。
这个我觉得其实也是总体实验设计的问题,也是老生常谈了,即研究者常误将相关性(correlation)等同于因果关系(causation)。即使两个变量显著相关(如巧克力消费量与诺贝尔奖得主数量的高相关性),也不能直接推断其存在因果联系。需要考虑以下原因:
直接或反向因果(如A导致B,或B导致A);
共同原因(如第三方变量同时影响两者);
偶然性(统计显著但无实际关联)。
一般来说,得到”因果“的结论,都需要实验操纵变量,直接操纵变量以检验因果的实验,而不仅仅是观察性的实验是最有说服力的,否则应该避免因果表述。 在pure统计上,也可以一定程度改进:
1. 引入第三方变量分析:通过分层模型或中介分析探索潜在机制(需确保统计功效)
2. 模型竞争检验:比较不同理论模型的支持度;
最后,作者讨论了p值的争议性: 当前学术界对零假设显著性检验(NHST)和显著性阈值存在广泛质疑(如p值无法直接反映效应真实性或重要性); 但完全禁用p值未必能解决推断错误问题,其仍可通过负责任的使用(如结合效应量、置信区间)辅助科学交流(尤其在新共识形成前)。 p值需谨慎解读,不可单独作为结论依据; 部分错误(如缺乏对照组)与p值无关,但多数问题(如过度依赖显著性)与其直接相关; 科学界需探索新统计范式,但现阶段p值仍具描述性价值。
这文章到后面居然一个图也没有,可能懒了不想写了吧。喜欢可以打赏请作者喝咖啡。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











