







前言回顾
算法的特性包括:有穷性;确定性;能行性;输入;输出。
数据结构是存在特定关系的数据元素的集合,根据数据元素的逻辑关系,可以分为:线性结构;树结构;图结构。目录
一、数据库
1.关系数据库
基本概念:
数据 (Data):描述事物的符号记录。
数据库 (DataBase,DB):长期存储在计算机内、有组织的、可共享的大量数据的集合。
数据库管理系统 (DataBase Management System,DBMS):一个管理数据库的系统软件。
数据库系统 (DataBase System,DBS):由数据库、数据库管理系统 (及其应用开发工具)、应用程序和数据库管理员组成的存储、管理、处理和维护数据的系统。
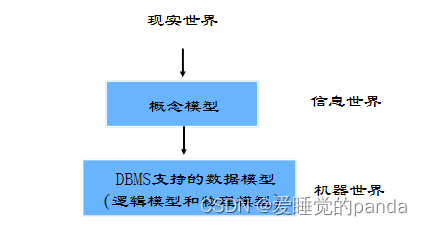
数据模型:
概念模型——E-R模型:用于数据库设计
逻辑模型——关系模型:用于数据库实现
数据结构:关系 (二维表)
数据操作:关系操作,包括查询、插入、删除、更新
完整性约束:实体完整性、参照完整性、用户定义完整性2.SQL语言
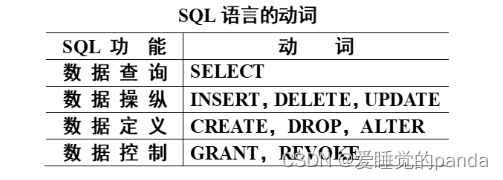
结构化查询语言:交互式;嵌入式。
①查询
基本语句格式:
二、数据挖掘
1.关联规则
关联规则:用于发现大量事务数据中项集之间有趣的关联关系或者相关关系。
设 I = { i1,i2,… ,im }是项集合,T = { t1,t2,… ,tn }是事务集合且∀tj ⊆ I (1≤j≤n)。
关联规则:形如A=>B,其中A⊂I,B⊂I,且A∩B=Ø。
关联规则的支持度:在事务集合T中,包含A∪B的事务占全部事务的百分比,记为support(A=>B) = p(A∪B) = s。
关联规则的置信度:在事务集合T中,包含A∪B的事务占A的事务的百分比,记为confidence(A=>B) = p(B|A) = c
强规则:同时满足最小支持度阈值 (min_sup) 和最小置信度阈值 (min_conf) 的规则。
关联规则挖掘步骤:
①产生频繁项集 (支持度测试):
k项集Ik:包含k个项的集合,比如说:{ i1,i2,i5 };Ik的支持计数sup_count(Ik) (出现频率):事务集合T中,包含Ik的事务数;
频繁k项集:满足最小支持度阈值min_sup的Ik,或满足sup_count(Ik)≥n*min_sup的Ik频繁k项集的集合记为Lk;
由频繁项集的项组成的关联规则满足最小支持度阈值。
②产生强关联规则 (置信度测试)
注:第一步是关键,它的效率影响整个算法的效率。因此,该算法的核心是频繁项集产生的方法。2.Apriori算法
Apriori算法:采用组曾搜索策略产生所有频繁项集,同时根据Apriori性质压缩搜索空间。
Apriori性质:如果一个项集 Ii是频繁项集,则它的所有非空子集 Ij一定也是频繁项集。如果某个 (k+1)项集是频繁项集,则它的所有k项集一定也是频繁项集;反之,如果某个k项集不是频繁项集,则包含它的所有 (k+1)项集也不是频繁项集。
因此,当逐层搜索频繁项集时,频繁 (k+1)项集的产生可以在频繁k项集的基础上通过连接、剪枝和支持计数完成,从而压缩搜索空间。Apriori算法的基本步骤:
①产生所有频繁项集 (支持度测试):
首先,扫描一次事务集合,找出频繁1项集集合L1;
基于L1,产生所有可能频繁的2项集,即候选2项集集合C2 (连接);基于L1,优化C2 (剪枝);
基于C2,再扫描一次事务集合,找出频繁2项集集合L2 (支持度计数);
依次类推,直至不能找到频繁项集为止;
②在所有频繁项集中产生强关联规则 (置信度测试)
对于每个频繁项集L及其非空真子集Lu,如果Lu=> (L - Lu)满足置信度阈值,则Lu=> (L - Lu)是强规则。注:
连接:基于频繁k项集结合Lk,产生所有可能频繁的 (k+1)项集,即候选 (k+1)项集结合Ck+1。根据Apriori性质,如果某个k项集不是频繁项集即不属于Lk,则包含这个k项集的 (k+1)项集肯定不是 (k+1)项集,可以不考虑即不属于Ck+1。
剪枝:基于频繁k项集集合Lk,对候选 (k+1)项集集合Ck+1中的所有 (k+1)项集进行子集测试,删除非频繁 (k+1)项集,优化Ck+1。根据Apriori性质,如果Ck+1中某个 (k+1)项集有一个k项集不是频繁项集即不属于Lk,则这个 (k+1)项集肯定不是频繁 (k+1)项集,可以从Ck+1中删除。
支持计数:基于候选 (k+1)项集集合Ck+1,扫描一次事务集合,找出Ck+1中频繁的 (k+1项集),即频繁 (k+1)项集集合Lk+1。3.分类
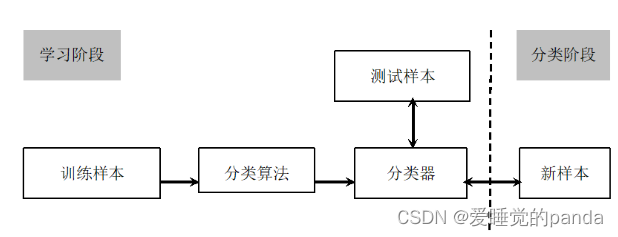
分类的任务:通过分析由已知类别的数据对象组成的训练数据集,建立描述并区分数据对象的类别的分类器 (分类函数或分类模型)。
分类的目的:利用分类器预测未知类别的数据对象的类别。
分类的过程:学习阶段;分类阶段。
4.决策树分类算法
决策树:由一个根结点,一组内部节点和一组叶节点组成。每个内部节点 (包括根节点)表示在一个属性上的测试,每个分枝表示一个测试输出。每个枝节点表示一个类,不同的叶节点可以表示相同的类。
建立决策树,需要解决的主要问题为:①如何选择测试属性?②如何停止划分样本?
①测试属性的选择顺序影响决策树的结构甚至决策树的准确率,可以根据信息增益选择测试属性。
②从根节点测试属性开始,每个内部节点测试属性都把训练数据集划分为若干个数据子集,通常:当某个节点对应的数据子集同类时;当某个节点对应的数据子集为空时;当某个节点对应的属性子集为空时。

















 338
338











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











