







 DataX是一个数据同步工具,用于在不同系统间迁移数据,如从HDFS到MySQL。配置文件是JSON格式,包括reader和writer参数,分别定义数据源和目标。reader参数如path指定HDFS文件位置,writer参数如writeMode设定MySQL的写入方式。此文章适合初学者快速了解DataX基础用法。
DataX是一个数据同步工具,用于在不同系统间迁移数据,如从HDFS到MySQL。配置文件是JSON格式,包括reader和writer参数,分别定义数据源和目标。reader参数如path指定HDFS文件位置,writer参数如writeMode设定MySQL的写入方式。此文章适合初学者快速了解DataX基础用法。
datax的使用以及参数解释
前言
本文我们介绍一下datax的基础用法,让初学者能够实现快速入门,即刻应用
一、datax是什么?
首先,来了解一下datax是什么,datax简单可以理解为数据同步的一个工具,将一个系统中存储的数据存储到另一个系统中。
举例来说,我们将数据存储到了HDFS中,但是现在我们想要使用这些数据来进行可视化分析,那么我们就要用到datax,将HDFS中的数据同步到MYSQL中,便于可视化的使用。
二、文件配置说明
文件安装我们就不多赘述了,直接开始讲解datax如何使用。
1.查看配置文件
{
"job": {
"setting": {
"speed": {
"channel": 3
}
},
"content": [
{
"reader": {
"name": "hdfsreader",
"parameter": {
"path": "/user/spark_design/output/user_anaylse/",
"defaultFS": "hdfs://master:9000",
"column": [
{
"index": 0,
"type": "string"
},
{
"index": 1,
"type": "long"
}
],
"fileType": "text",
"encoding": "UTF-8",
"fieldDelimiter": ","
}
},
"writer": {
"name": "mysqlwriter",
"parameter": {
"writeMode": "insert",
"username": "root",
"password": "123456",
"column": [
"province",
"number"
],
"preSql": [
"delete from user_anaylse"
],
"connection": [
{
"jdbcUrl": "jdbc:mysql://127.0.0.1:3306/spark_design?useUnicode=true&characterEncoding=UTF-8",
"table": [
"user_anaylse"
]
}
]
}
}
}
]
}
}
2. 配置参数解释
上面的部分的代码是datax使用必须配置的json文件,没有这个文件datax是不能使用的,这个文件规定了数据的来源和同步位置。
首先channel这个数据,规定的是异步的线程数,快速入门的化可以先不管这个参数。
我们主要看content中的reader和writer部分
3. reader参数解释
首先我们要知道,这个配置文件是一个简单的从HDFS中将数据同步到MySQL的json文件
reader部分:顾名思义,reader就是数据原本的位置。
name–起个名字即可
path–就是文件在HDFS中存储的位置,需要的化直接将这个json文件中的路径改为自己文件在HDFS中的路径即可
defaultFS–就是Hadoop主节点的ip+端口
column–就是数据存储的文件中的列数,列数从0开始,在规定列的位置的同时需要规定好该列的数据类型
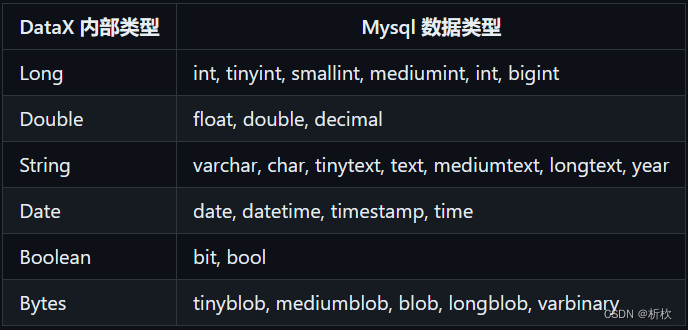
filetype–数据文件的类型,虽然由csv文件这个选项,时间上我们将csv文件进行同步时选择text类型,将fieldDelimiter设置为”,“ 即可即可。
encoding–文件编码格式,就UTF-8即可,无需更改。
fieldDelimiter–数据中的分隔符,类似于hive中的field delimited

4. writer参数解释
name–一样。起个名字即可
writeMode–控制写入数据到目标表采用 insert into 或者 replace into 或者 ON DUPLICATE KEY UPDATE 语句
username–数据库的用户名
password–数据库的密码
column–数据库表中的列名以及数据类型,这个数据类型按照MySQL中的数据类型即可(由于这个的writer的目标是MySQL)
preSql–数据插入之前执行的SQL语句
jdbcUrl–数据库的连接信息
table–要插入的表
总结
本文仅限于datax的快速入门,简单理解为,零时抱佛脚系列文章
具体学习还是看datax官网: 点我跳转

















 7255
7255

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









