






1 实验目的
(1)通过实验掌握 Spark SQL 的基本编程方法;
(2)熟悉 RDD 到 DataFrame 的转化方法;
(3)熟悉利用 Spark SQL 管理来自不同数据源的数据。
2 实验平台
操作系统: Ubuntu16.04及以上
Spark版本3.4.0
数据库:MySQL
3 实验要求
使用 Spark SQL 向 MySQL 数据库中写入内容。并且再使用 Spark SQL 从 MySQL 数据库中把内容读出。
4 实验内容和步骤(操作结果要附图)
1.准备工作(前提安装好mysql,参考教程Ubuntu安装MySQL及常用操作_厦大数据库实验室博客 (xmu.edu.cn) https://dblab.xmu.edu.cn/blog/1002/
https://dblab.xmu.edu.cn/blog/1002/
service mysql start #启动服务
mysql -u root -p #运行mysql,选择用户然后输入密码在MySQL数据库中新建数据库spark,再建表student,包含下列两行数据
mysql> create database spark;
mysql> use spark;
mysql> create table student (id int(4), name char(20), gender char(4), age int(4));
mysql> insert into student values(1,'Xueqian','F',23);
mysql> insert into student values(2,'Weiliang','M',24);
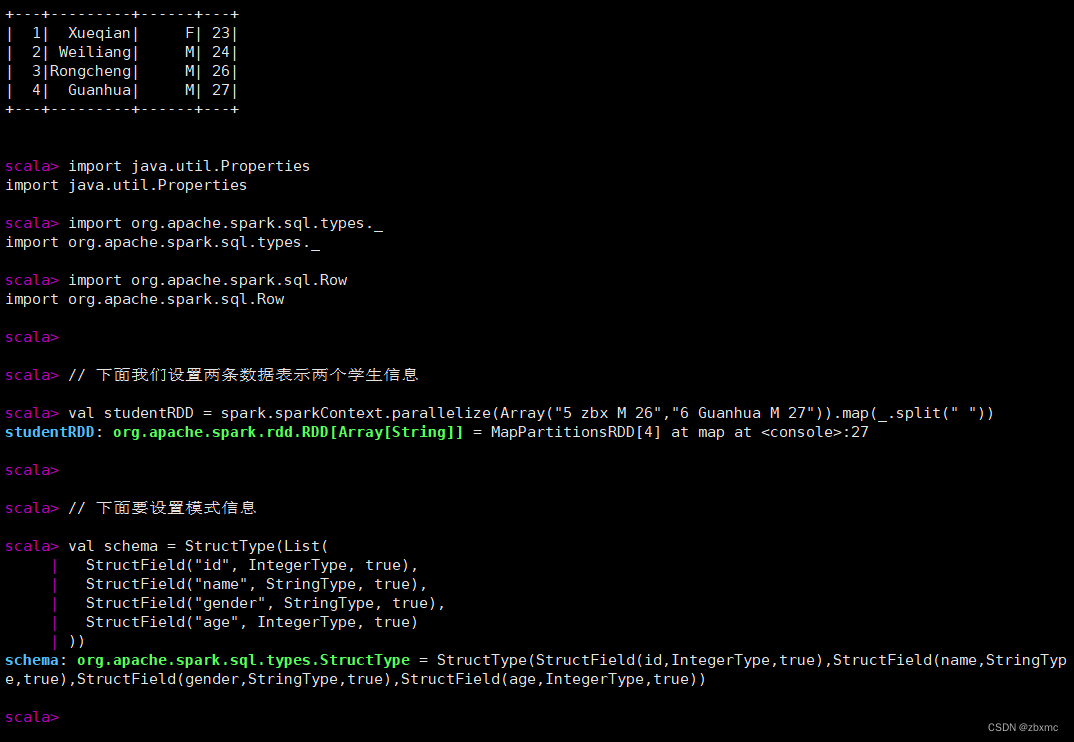
mysql> select * from student;
2.读取mysql数据库中的数据
下载MySQL的JDBC驱动程序,比如mysql-connector-java-5.1.40.tar.gz
链接: https://pan.baidu.com/s/1Mv30gzWdk-EpCWqhpj5hng?pwd=1234 提取码: 1234
把该驱动程序拷贝到spark的安装目录” /usr/local/spark/jars”下
启动一个spark-shell,启动Spark Shell时,必须指定mysql连接驱动jar包
cd /usr/local/spark
./bin/spark-shell \
--jars /usr/local/spark/jars/mysql-connector-java-5.1.40/mysql-connector-java-5.1.40-bin.jar \
--driver-class-path /usr/local/spark/jars/mysql-connector-java-5.1.40/mysql-connector-java-5.1.40-bin.jar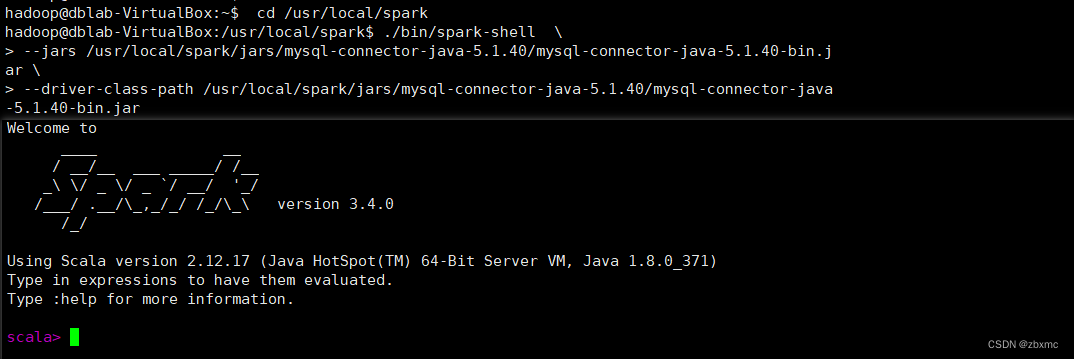
执行以下命令连接数据库,读取数据
val jdbcDF = spark.read.format("jdbc").
| option("url","jdbc:mysql://localhost:3306/spark?useUnicode=true&useSSL=false&characterEncoding=utf-8&serverTimezone=Asia/Shanghai&useAffectedRows=true&allowMultiQueries=true").
| option("driver","com.mysql.jdbc.Driver").
| option("dbtable", "student").
| option("user", "root").
| option("password", "123456").
| load()
3.向mysql数据库写入数据
现在开始在spark-shell中编写程序,往spark.student表中插入两条记录
import java.util.Properties
import org.apache.spark.sql.types._
import org.apache.spark.sql.Row
// 下面我们设置两条数据表示两个学生信息
val studentRDD = spark.sparkContext.parallelize(Array("5 zbx M 26","6 Guanhua M 27")).map(_.split(" "))
// 下面要设置模式信息
val schema = StructType(List(
StructField("id", IntegerType, true),
StructField("name", StringType, true),
StructField("gender", StringType, true),
StructField("age", IntegerType, true)
))
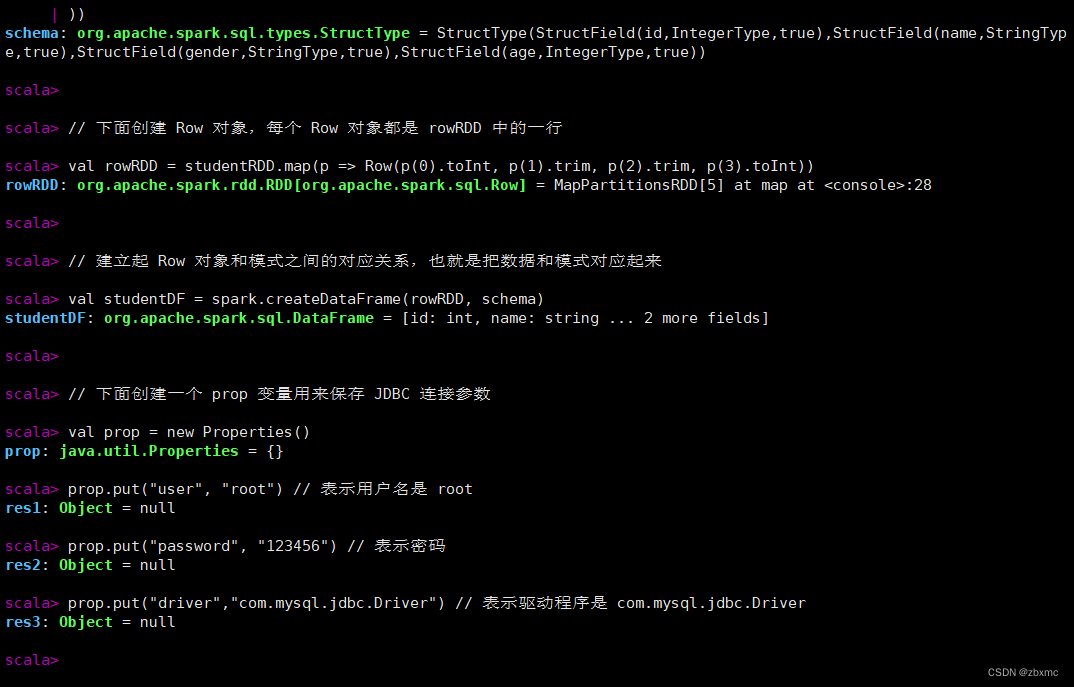
// 下面创建 Row 对象,每个 Row 对象都是 rowRDD 中的一行
val rowRDD = studentRDD.map(p => Row(p(0).toInt, p(1).trim, p(2).trim, p(3).toInt))
// 建立起 Row 对象和模式之间的对应关系,也就是把数据和模式对应起来
val studentDF = spark.createDataFrame(rowRDD, schema)
// 下面创建一个 prop 变量用来保存 JDBC 连接参数
val prop = new Properties()
prop.put("user", "root") // 表示用户名是 root
prop.put("password", "123456") // 表示密码
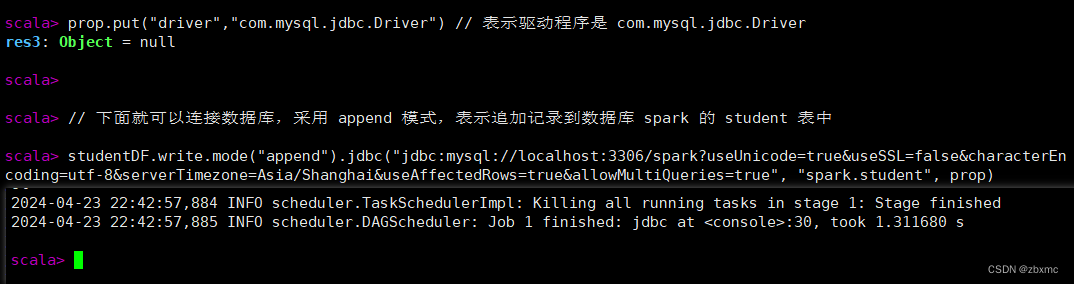
prop.put("driver","com.mysql.jdbc.Driver") // 表示驱动程序是 com.mysql.jdbc.Driver
// 下面就可以连接数据库,采用 append 模式,表示追加记录到数据库 spark 的 student 表中
studentDF.write.mode("append").jdbc("jdbc:mysql://localhost:3306/spark?useUnicode=true&useSSL=false&characterEncoding=utf-8&serverTimezone=Asia/Shanghai&useAffectedRows=true&allowMultiQueries=true", "spark.student", prop)命令行可以快速判断哪一行代码发生错误,以便改正,然后一路报绿。
可以看一下效果,看看MySQL数据库中的spark.student表发生了什么变化
select * from student;
5 实验总结
理解Spark SQL的核心概念:首先要理解Spark SQL的核心概念,包括DataFrame、Dataset、SQL查询等。DataFrame是一种分布式的数据集合,可以通过编程接口进行操作;Dataset是对DataFrame的进一步封装,提供了类型安全的API;SQL查询则是使用标准的SQL语句进行数据查询和处理。
数据加载和保存:掌握如何从不同的数据源加载数据,比如从文件系统、Mysql、关系型数据库等加载数据,并且了解如何将处理后的数据保存到不同的数据源。
数据转换和处理:学会使用Spark SQL提供的各种函数和操作来进行数据转换和处理,比如筛选、聚合、排序、连接等操作。
















 3149
3149

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











