






前言
本文教程均来自b站【小白也能听懂的人工智能原理】,感兴趣的可自行到b站观看。
代码及工具箱
本专栏的代码和工具函数已经上传到GitHub:1571859588/xiaobai_AI: 零基础入门人工智能 (github.com),可以找到对应课程的代码
正文
对于时间上有关联性的数据,如语音和文字,我们需要一种能够理解序列数据的神经网络。这种网络就是循环神经网络(RNN)。RNN的设计理念是利用记忆来处理序列数据,它的隐藏层不仅取决于当前输入,还取决于上一个时间点的隐藏状态。
以处理文字为例,我们首先需要将文字转换为计算机能够理解的数字形式,这通常是通过嵌入层实现的。嵌入层将每个单词映射为一个固定长度的向量,这个向量能够捕捉单词的语义信息。
接下来,这些向量序列被输入到RNN中。RNN的每个时间点都会处理一个单词向量,并更新其内部状态,这个状态包含了之前所有单词的信息。这样,RNN能够在整个句子层面上理解单词的上下文。
最后,RNN的输出可以被用来进行分类任务,比如判断评论是正面的还是负面的。通过训练,RNN学会在序列的每个时间点捕捉到关键信息,并能够在整个序列处理完成后做出决策。
总结来说,对于时间序列数据,我们使用RNN来处理,因为它能够记住序列中的信息,并利用这些信息来理解和预测序列的下一个状态。
如何把文字转成计算机能够识别的数字?
词典索引
在自然语言处理中,我们通常将词作为处理的基本单位,因为词能够更好地捕捉语言的语义。为了将词转换为数字,我们可以使用一种叫做“词袋”模型的方法。这种方法简单来说,就是给每个词分配一个唯一的数字ID。
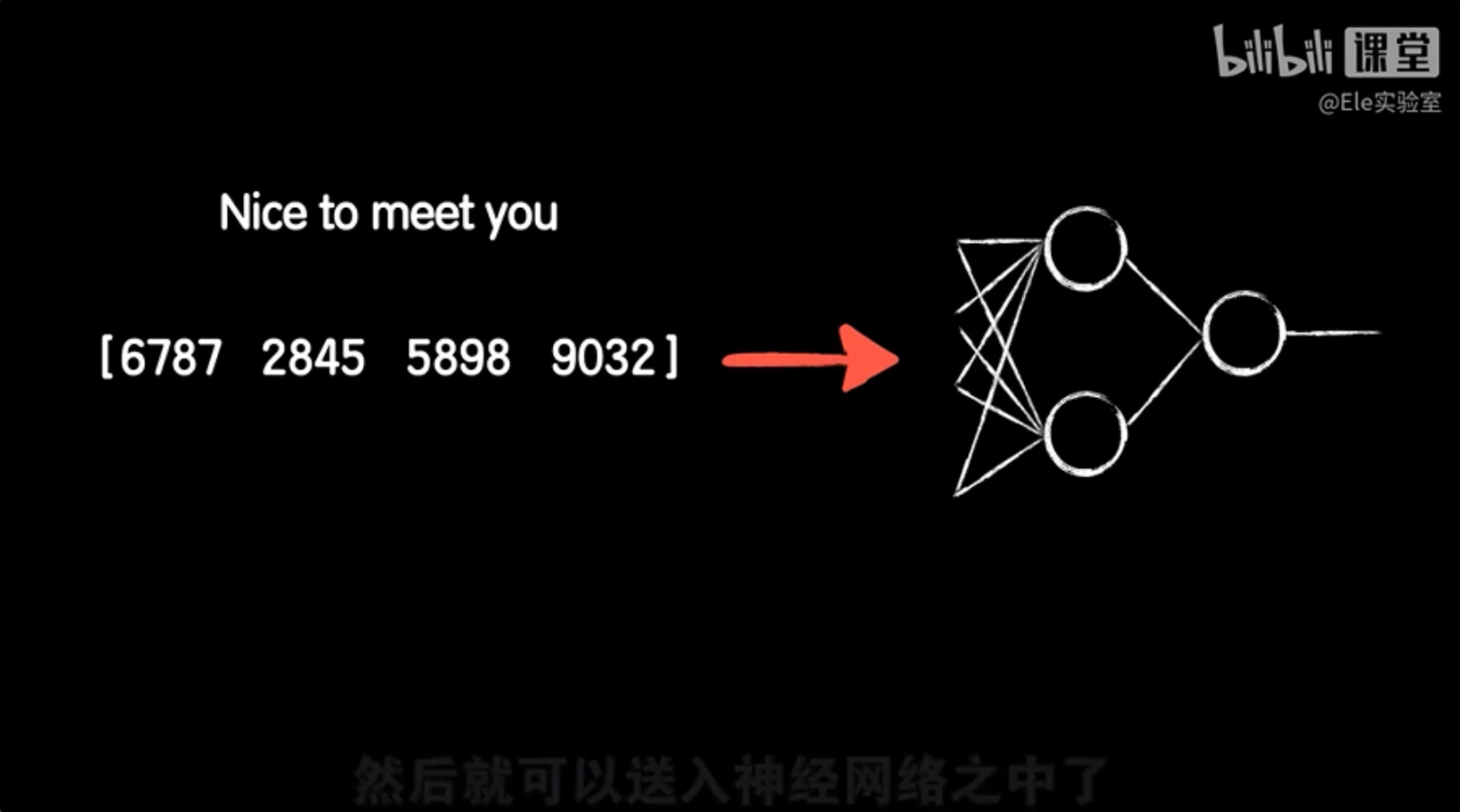
例如,我们可以通过查词典,找到每个词在词典中的位置,这个位置就可以作为这个词的数字表示。比如,“nice”是第6787个词,“to”是第2845个词,“meet”是第5898个词,“you”是第9032个词。这样,整句话“nice to meet you”就可以被转换为数字序列[6787, 2845, 5898, 9032]。
这种转换后的数字序列可以作为神经网络的输入。然而,这种方法有一个缺点,就是它没有考虑到词之间的上下文关系。为了更好地捕捉词的语义和上下文信息,我们通常使用词嵌入技术,如Word2Vec或GloVe,这些技术可以将每个词映射到一个高维空间中的向量,其中向量之间的距离反映了词之间的语义关系。这样,神经网络就能更好地理解和处理自然语言数据。
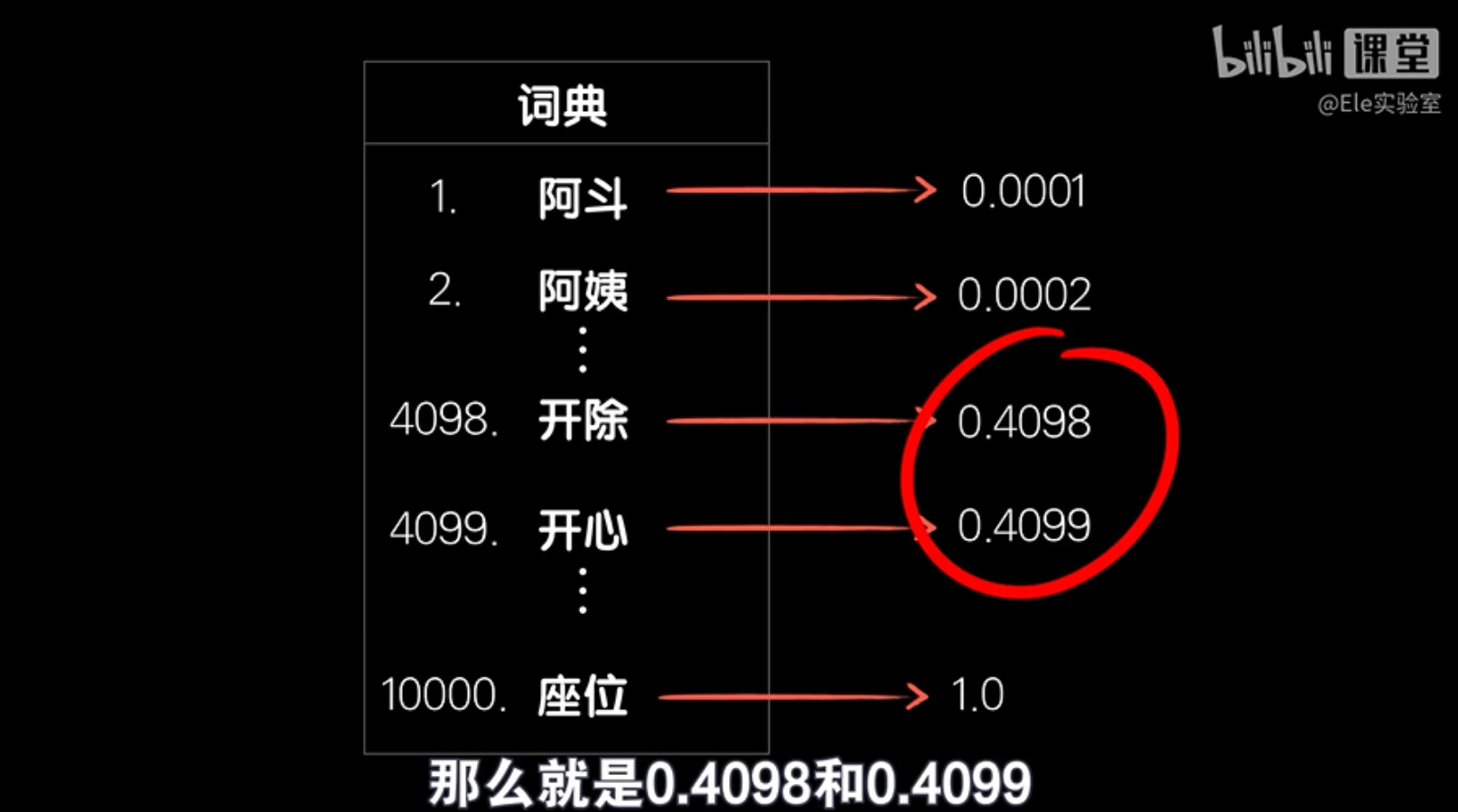
处理中文文本时,我们首先需要进行分词,因为中文没有像英文那样的自然空格来分隔单词。分词是将句子切割成一个个有意义的词的过程。一旦我们有了分好的词汇,我们就可以像处理英文那样,将每个词转换成它在词典中的位置,也就是一个数字。
但是,这种方法可能会遇到一个问题。如果两个词在词典中的位置很接近,比如“开除”和“开心”,它们在数字表示上可能非常相似,尤其是在进行归一化处理后。这种相似性可能会误导我们的模型,因为它没有考虑到词的具体含义和上下文。
为了解决这个问题,我们可以使用词嵌入技术,比如Word2Vec或GloVe,这些技术不仅考虑到词的位置,还考虑到词的上下文,能够为每个词生成一个更加丰富的向量表示。这样,即使“开除”和“开心”在词典中的位置接近,它们的向量表示也能够体现出它们在语义上的差异,从而帮助模型更好地理解中文文本。
onehot编码
在自然语言处理中,为了避免词汇之间的混淆,我们通常使用一种叫做one-hot编码的方法。这种编码方式将每个词表示为一个很长的向量,这个向量的维度等于词典中词汇的总数。在这个向量中,只有一个元素是1,其他所有元素都是0。这个1的位置就代表了特定的词。
比如,如果我们有一个包含1万个词的词典,那么“苹果”这个词可能会被编码为一个向量,其中第500个位置是1,其他位置都是0。同样,“香蕉”这个词可能会被编码为另一个向量,其中第800个位置是1,其他位置都是0。这样,每个词都有了自己独特的编码,不会有任何混淆。
使用one-hot编码后,每个词都是完全不一样的,因为每个词的向量都有一个唯一的1。这样,即使是“开除”和“开心”这样在词典中位置接近的词,在one-hot编码后也会是完全不同的向量。不过,one-hot编码并没有考虑到词之间的语义关系,所以通常我们还会使用词嵌入技术来进一步处理这些编码,以便更好地捕捉词的语义。

但问题是我们严格把每个词都变得完全不一样的同时,也丢失了词汇之间的关联性,比如猫和狗这两个词在数据上应该更加接近,苹果和西瓜更加接近,而猫和苹果的差距应该更大,但呆板的onehot编码却无法体现这一点,因为这种人为的随意且呆板的词表示方法完全不能体现语言中词语的特点,而特征提取不当的数据会让神经网络变得难以训练和泛化。

再者onehot的编码会让输入数据非常的大,比如我们使用一个有1万个词的词典,这样每个词的onehot的编码都是一个1万倍的向量,那么一个有4个词的句子,那么输入数据就是4万个元素。

词向量
在自然语言处理中,为了让计算机更好地理解词汇,人们提出了词向量的概念。词向量是一种将词汇表示为向量(即一组数字)的方法,这些数字代表了词汇的不同特征。就像我们用多个特征(如大小、颜色、硬度)来描述一个物体一样,词向量也是通过提取词汇的不同特征来形成的。
例如,“狗”这个词可以被认为有一些特征:它是一个名词(0.9的概率),它是动物(不是植物),它有皮毛,有尾巴等。这些特征可以被转换成数字,从而形成一个向量。这样,“狗”这个词就被表示为一个多维空间中的一个点,这个点在空间中的位置反映了“狗”这个词的特征。
词向量使得计算机能够更好地理解词汇的语义,因为向量之间的距离可以表示词汇之间的相似性。如果两个词向量在空间中的距离很近,那么它们在语义上可能很相似。这种方法比简单的one-hot编码更加强大,因为它能够捕捉到词汇的语义和上下文信息。
词向量通常是通过机器学习算法在大规模文本数据上训练得到的,这些算法能够自动从文本中学习词汇的特征。常见的词向量训练工具有Word2Vec、GloVe等。这些词向量在许多自然语言处理任务中都非常有用,比如文本分类、情感分析、机器翻译等。















 771
771

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









