






 本文介绍了几种关键的深度学习模块,包括标准卷积、CSPBottleneck(带有三个卷积的CSP瓶颈)、SPPF(空间金字塔池化-快速)以及TransformerBlock,展示了它们在卷积神经网络中的结构和功能,尽管某些模块如大卷积和Transformer的效果被证实不如预期,但仍对现代IT技术中的图像处理有重要影响。
本文介绍了几种关键的深度学习模块,包括标准卷积、CSPBottleneck(带有三个卷积的CSP瓶颈)、SPPF(空间金字塔池化-快速)以及TransformerBlock,展示了它们在卷积神经网络中的结构和功能,尽管某些模块如大卷积和Transformer的效果被证实不如预期,但仍对现代IT技术中的图像处理有重要影响。
1:卷积块
class Conv(nn.Module):
# Standard convolution
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True): # ch_in, ch_out, kernel, stride, padding, groups
"""
Standard convolution conv+BN+act
:params c1: 输入的channel值
:params c2: 输出的channel值
:params k: 卷积的kernel_size
:params s: 卷积的stride
:params p: 卷积的padding 一般是None 可以通过autopad自行计算需要pad的padding数
:params g: 卷积的groups数 =1就是普通的卷积 >1就是深度可分离卷积
:params act: 激活函数类型 True就是SiLU()/Swish False就是不使用激活函数
类型是nn.Module就使用传进来的激活函数类型
"""
super().__init__()
self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p), groups=g, bias=False)
self.bn = nn.BatchNorm2d(c2)
self.act = nn.SiLU() if act is True else (act if isinstance(act, nn.Module) else nn.Identity())
def forward(self, x):
return self.act(self.bn(self.conv(x)))
def forward_fuse(self, x):
return self.act(self.conv(x))
2:C3卷积块
class C3(nn.Module):
# CSP Bottleneck with 3 convolutions
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansion
super().__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c1, c_, 1, 1)
self.cv3 = Conv(2 * c_, c2, 1) # act=FReLU(c2)
self.m = nn.Sequential(*(Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)))
# self.m = nn.Sequential(*[CrossConv(c_, c_, 3, 1, g, 1.0, shortcut) for _ in range(n)])
def forward(self, x):
return self.cv3(torch.cat((self.m(self.cv1(x)), self.cv2(x)), dim=1))
class Bottleneck(nn.Module):
# Standard bottleneck
def __init__(self, c1, c2, shortcut=True, g=1, e=0.5): # ch_in, ch_out, shortcut, groups, expansion
super().__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_, c2, 3, 1, g=g)
self.add = shortcut and c1 == c2
def forward(self, x):
return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))

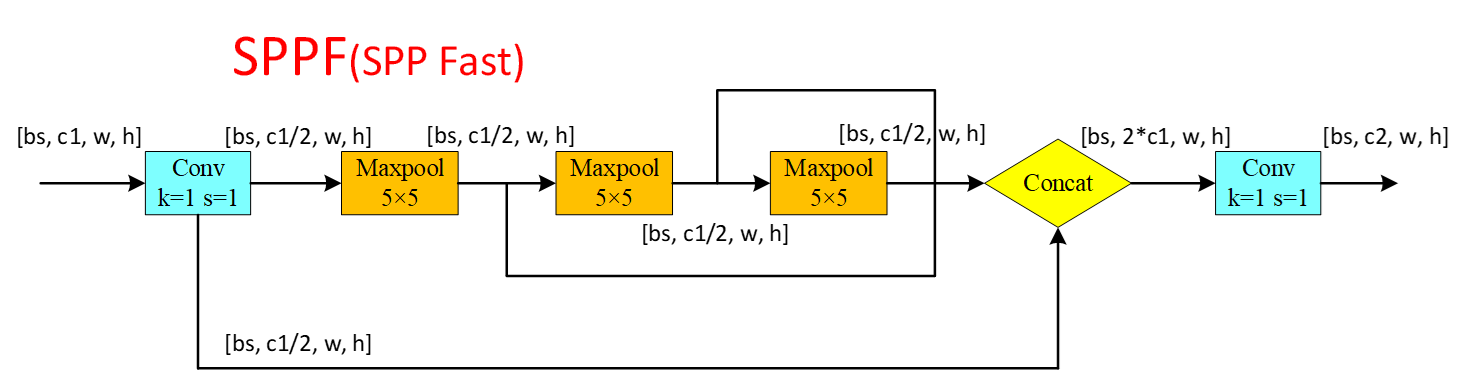
3:SPPF模块
class SPPF(nn.Module):
# Spatial Pyramid Pooling - Fast (SPPF) layer for YOLOv5 by Glenn Jocher
def __init__(self, c1, c2, k=5): # equivalent to SPP(k=(5, 9, 13))
super().__init__()
c_ = c1 // 2 # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_ * 4, c2, 1, 1)
self.m = nn.MaxPool2d(kernel_size=k, stride=1, padding=k // 2)
def forward(self, x):
x = self.cv1(x)
with warnings.catch_warnings():
warnings.simplefilter('ignore') # suppress torch 1.9.0 max_pool2d() warning
y1 = self.m(x)
y2 = self.m(y1)
return self.cv2(torch.cat([x, y1, y2, self.m(y2)], 1))
已经弃用的
1:focus
class Focus(nn.Module):
# Focus wh information into c-space
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True): # ch_in, ch_out, kernel, stride, padding, groups
super().__init__()
self.conv = Conv(c1 * 4, c2, k, s, p, g, act)
# self.contract = Contract(gain=2)
def forward(self, x): # x(b,c,w,h) -> y(b,4c,w/2,h/2)
return self.conv(torch.cat([x[..., ::2, ::2], x[..., 1::2, ::2], x[..., ::2, 1::2], x[..., 1::2, 1::2]], 1))
# return self.conv(self.contract(x))
换成大卷积和来提升感受视野
2:transformer
class TransformerBlock(nn.Module):
# Vision Transformer https://arxiv.org/abs/2010.11929
def __init__(self, c1, c2, num_heads, num_layers):
super().__init__()
self.conv = None
if c1 != c2:
self.conv = Conv(c1, c2)
self.linear = nn.Linear(c2, c2) # learnable position embedding
self.tr = nn.Sequential(*(TransformerLayer(c2, num_heads) for _ in range(num_layers)))
self.c2 = c2
def forward(self, x):
if self.conv is not None:
x = self.conv(x)
b, _, w, h = x.shape
p = x.flatten(2).permute(2, 0, 1)
return self.tr(p + self.linear(p)).permute(1, 2, 0).reshape(b, self.c2, w, h)
class TransformerLayer(nn.Module):
# Transformer layer https://arxiv.org/abs/2010.11929 (LayerNorm layers removed for better performance)
def __init__(self, c, num_heads):
super().__init__()
self.q = nn.Linear(c, c, bias=False)
self.k = nn.Linear(c, c, bias=False)
self.v = nn.Linear(c, c, bias=False)
self.ma = nn.MultiheadAttention(embed_dim=c, num_heads=num_heads)
self.fc1 = nn.Linear(c, c, bias=False)
self.fc2 = nn.Linear(c, c, bias=False)
def forward(self, x):
x = self.ma(self.q(x), self.k(x), self.v(x))[0] + x
x = self.fc2(self.fc1(x)) + x
return x
实测效果不如大卷积,也已经弃用















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









