






常见术语
病毒:(永恒之蓝、你从网上下载了个文件后打开运行,然后你的系统乱码了)恶意文件,植入后会破坏操作系统原有功能、自动转播
木马:监听、操作对方机器的
CMS:(内容信息管理系统) 别人已经开发好的一套站点系统
框架:代码的大体逻辑,登录、注册的、访问 身份认证的框架(shiro、thinkphp)
厂商系统:OA(办公系统)、(web网站) VPN、CRM
漏洞:这套系统、这个网站、软件所存在的缺陷。
0day : 未公开的漏洞
1day : 最近所公开漏洞细节的漏洞
nday : 已经公开好久了,历史漏洞
旁站:同一个服务器的不同网站(IIS,80 8080)
C段:ip地址在同一个网段内 192.168.1.0/24
poc:漏洞验证程序
exp:漏洞利用程序
payload:攻击载荷
渗透测试
概念
渗透测试指渗透人员在不同的位置(比如内网、外网等位置)利用各种手段对某个特定的网络进行安全测试,以发现和挖掘系统中存在的漏洞 ,然后输出渗透测试报告,并提交给网络所有者。网络所有者根据渗透人员提供的渗透测试报告,可以清晰知晓系统中存在的安全隐患和问题,从而去解决。
类型
黑盒测试:
⼜称为功能测试,渗透者完全处于对系统⼀⽆所知的状态,通常这类型测试,
(我们⽬前只知道对方网站的地址,并不知道网站的源代码、后台账号密码、⽹络拓扑等信息。)
白盒测试:
也称为结构测试,与⿊箱测试恰恰相反,测试者可以通过正常渠道向被测单位取得各种资料,包括⽹络拓扑、员⼯资料甚⾄⽹站或其它程序的代码⽚段,也能够与单位的其它员⼯进⾏⾯对⾯的沟通。这类测试的⽬的是模拟企业内部雇员的越权操作。
(白盒:客户会给到我们⽹站源代码、账户密码等信息、我们根据提供的信息进行测试)
灰盒测试:
是介于白盒测试与⿊盒测试之间的⼀种测试,通常情况下,接受渗透测试的单位网络管理部门会收到通知:在某些时段进行测试。因此能够监测⽹络中出现的变化。但灰盒测试被测单位也仅有极少数人知晓测试的存在,因此能够有效地检验单位中的信息安全事件监控、响应、恢复做得是否到位。
目的
为了比黑客提前发现该应用存在的安全威胁。 从而进行修复以降低相应的安全风险。
流程
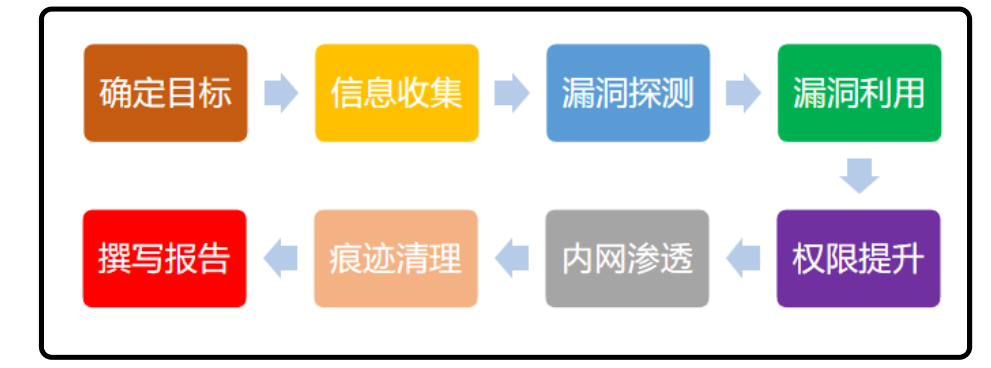
1.前期交互(确认我们要测试目标范围、测试时限制的条件、参与人员、授权书)
2.信息收集(去扩大我们测试的资产面)小米公司(去收集相关的域名、app、小程序等信息)
3.漏洞探测(我们去挖掘漏洞)挖掘目标系统漏洞
4.漏洞利用(利用发现的漏洞,实现我们的目的) 利用挖掘到漏洞去获取系统权限、账户密码、敏感信息
5.权限提升(将我们获取的低权限用户提甚至高权限)
当我们获取到小米的系统主机权限后如果为一个普通用户则需要将其提升到管理员用户
6.内网渗透(针对受害者服务器的内部网络进行攻击)
7.痕迹清理(针对我们入侵的过程中所产生的文件、日志等进行清楚操作)
8.撰写报告(针对我们入侵的过程所产生的成果进行汇报总结)
常见防护设施
入侵检测系统 (Intrusion Detection System, IDS)
入侵防御系统(Intrusion Prevent System, IPS)
终端检测系统 (Endpoint Detection and Response, EDR)
WAF(web应⽤防⽕墙)
资产信息收集
概念
通过各种方式获取所需要的信息,以便我们在后续的渗透过程中更好的进行。
常收集内容:IP、域名、小程序、APP、端⼝信息、系统架构、手机号、邮箱等。
信息收集包含资产收集但不限于资产收集。
意义
信息收集对于渗透测试前期来说非常重要。只有我们掌握了目标网站或主机足够多的信息之后,才更好的进行渗透测试。同时测试漏洞的资产面也会增加。那么意味着挖到漏洞的几率就大些。
方法
主动信息收集:
通过直接访问网站在网站上进行操作,对网站进行扫描等,这种是有网络流量经过目标服务器的信息收集方式。
缺点是容易被目标机器记录操作信息或屏蔽,如:nmap等,但这种方式收集的信息较为准确。
被动式信息搜集 :
通过第三方服务来获取目标网络相关信息。如通过搜索引擎方式(fofa,鹰图)来搜集信息。
区别
主动方式:你能获取更多的信息,但是目标主机可能会记录你的操作记录。
被动方式:你收集的信息会相对较少,但是你的行动并不会被目标主机发现。
分类
资产收集:指企业的一些备案域名、APP、小程序、公众号、企业资料、手机号、邮箱、IP地址等。
站点收集:收集单个站点信息,例:bilibili的网站架构、B站网站服务器IP开放的端口、网站的功能等。
资产方面
资产相关
通过备案号查询域名
查询备案号的方式有两种:
1.通过⻚⾯显⽰的备案号直接进⾏查询 。
2.通过公司名称进⾏查询。
网站:
ICP备案查询网:ICP备案查询网 - 网站备案查询 - 工信部域名备案查询实时数据
工信部网站备案查询:https://beian.miit.gov.cn/#/Integrated/index
天眼查网站备案查询:天眼查-商业查询平台_企业信息查询_公司查询_工商查询_企业信用信息系统
国家企业信用信息公示系统:https://www.gsxt.gov.cn/index.html
whois查询域名注册信息
解释
whois(读作"Who is") ,是一个用来查询域名注册状态及域名注册信息的数据库,是当前域名系统中一项不可或 缺的信息服务。
通过 whois查询 ,我们可以得知目标域名是否被注册 , 域名所有者是谁 , 域名注册商在哪 ,为我们注册域名或了解域名信息提供参考依据。
对域名注册服务机构而言,通过whois查询工具,还能够确认域名数 据是否已经正确注册到所属的服务机构。
作用
在渗透测试中可通过whois查询我们可以查询到注册商、注册人、邮件、DNS解析服务器、注册人联系电话等信息。
网址
站长之家:域名Whois查询 - 站长工具
腾讯云: 域名信息查询 - 腾讯云
中国万网:https://whois.aliyun.com/
子域名查询
收集子域名的目的
假设目标资产数量庞大,一般来说主域都是防护重点,管理上可能会谨慎,防护也相对严格,因此从子域名入手便成了很好的选择,子域往往在防护上会相对更加的松懈,然后再慢慢向目标系统渗透, 所以子域名的收集便显得尤为的重要。
工具枚举
Layer子域名挖掘机
下载地址:https://github.com/euphrat1ca/LayerDomainFinder/releases/tag/3
Oneforall综合工具
下载地址:https://github.com/shmilylty/OneForAll/releases/tag/v0.4.5
优点:收集子域信息很全,包括子域、子域IP、 子域常用端口、子域Title、子域Banner、子域状态等 。
项目的依赖库安装:
python -m pip install -r requirements.txt使用方法:
单域名:
python3 oneforall.py --target 域名 run
多个域名:
python3 oneforall.py --targets 域名.txt run
收集结果会输出同级result目录下 。
单域名收集的结果保存在results目录下,以收集的域名为名称创建一个.csv文件 baidu.com.csv
多域名收集,结果也在results下,all_subdomain_当前的时间日期_随机数.csv
比如:all_subdomain_result_20230810_161331.csv选项:
--alive=True
//选值True,False分别表示导出存活,全部子域结果
--dns=DNS
//DNS解析子域(默认True)
--req=REQ
//HTTP请求子域(默认True)
--port=PORT
//请求验证子域的端口范围(默认只探测80端口)
--fmt=FMT
//结果保存格式(默认csv)
--path=PATH
//结果保存路径(默认None)
--takeover=TAKEOVER
//检查子域接管(默认False)subDomainBrute
下载地址:https://github.com/lijiejie/subDomainsBrute
参数介绍
--version //显示程序的版本号并退出
-h, --help //显示此帮助信息并退出
-f FILE //文件包含新行分隔的子文件,默认为子域名称.txt。
--full //全扫描,将使用NAMES FILE subnames_full.txt 野蛮
-i, --ignore-intranet //忽略指向私有 IP 的域
-w, --wildcard //通配符测试失败后强制扫描
-t 线程,--threads=线程 //扫描线程数,默认256
-p 进程, --process=进程 //扫描进程数,默认为6
-o 输出, --output=OUTPUT //输出文件名。 默认为 {target}.txt
应用案例
python3 subDomainsBrute.py baidu.com --full -i -t 30 -o baidu.txt
//结果将输出到 "tmp/(域名_时间)/baidu.txt" 文件内空间搜索引擎
搜索引擎:
fofa:网络空间测绘,网络空间安全搜索引擎,网络空间搜索引擎,安全态势感知 - FOFA网络空间测绘系统
钟馗之眼:ZoomEye - Cyberspace Search Engine
语法:
鹰图:domain="baidu.com"
Fofa:domain="baidu.com"
Zoomeye:site:baidu.com
Shodan:hostname:"baidu.com"在线网站查询
网站查询:
DNSDB:https://dnsdb.io/zh-cn/
在线子域名查询:https://phpinfo.me/domain/
ip或域名查询:ip查询 查ip 网站ip查询 同ip网站查询 iP反查域名 iP查域名 同ip域名
威胁情报平台
VT:https://www.virustotal.com/gui/domain/{domain}/relations
搜索引擎查询
原理:通过搜索引擎获取已经爬取的子域名;
语法:site:360.cn
使用"-"减号来去除已知子域名:site:target.com-www-blog
DNS数据集收集子域
原理:
利用dns记录公开数据收集
查询网站:(domain换成要查询的域名)
○ ip138:ip查询 查ip 网站ip查询 同ip网站查询 iP反查域名 iP查域名 同ip域名 //好使
○ 百度云观测:http://ce.baidu.com/index/getRelatedSites?site_address={domain} //好使
○ hackertarget:Find DNS Host Records | Subdomain Finder | HackerTarget.com //好使
○ riddler:https://riddler.io/search?q=pld:{domain}
○ dnsdb:https://dnsdb.io/zh-cn/search?q=xiaomi.com //好使
○ netcraft:https://searchdns.netcraft.com/ //好使
○ dnsdumpster:DNSDumpster - Find & lookup dns records for recon & research
○ sitedossier:Sitedossier - profiles for millions of sites on the web
○ findsubdomains:https://findsubdomains.com/ //好使
HTTPS证书透明度查询
查询网站
● crtsh:crt.sh | Certificate Search
● facebook:https://developers.facebook.com/tools/ct
● entrust:https://www.entrust.com/ct-search/
● certspotter:Certificate Transparency Search API by SSLMate
● spyse:https://spyse.com/search/certificate
● censys:https://censys.io/certificates
● google: https://google.com/transparencyreport/https/ct/
IP发查域名
ip-adress:https://www.ip-adress.com/reverse-ip-lookup
IPIP:专业精准的IP库服务商_IPIP
爱站:121.36.42.44属于北京市 华为云 数据中心_IP反查域名_同IP站点查询_同ip网站查询_爱站网
站点相关
C段
同一内网段,不同服务器;
举例:192.168.0.1,A段就是192,B段就是168,C段就是0,D段就是1。而C段攻击嗅探的意思就是拿下它同一 C段中的其中一台机器,也就是说是D段1-255中的一台服务器,然后利用拿下该台服务器。
网站:
在线 webscan:https://webscan.cc/
fofa、shodan 在线工具:ip="106.15.141.18/24"
nmap:nmap 192.168.1.0/24 -p 443,80
masscan:masscan 10.11.0.0/16 -p 443,80
潮汐指纹:TideFinger 潮汐指纹 TideFinger 潮汐指纹
旁站
同一ip下不同端口的站点进行渗透,从而获取目标站点的权限
网站:
潮汐指纹:TideFinger 潮汐指纹 TideFinger 潮汐指纹
yougetsignal:Reverse IP Lookup - Find Other Web Sites Hosted on a Web Server
站长工具:网站IP查询_IP反查域名_同IP网站查询 - 站长工具
爱站:121.36.42.44属于北京市 华为云 数据中心_IP反查域名_同IP站点查询_同ip网站查询_爱站网
同 ip 网站查询:Hamm.cn
webscan:https://www.webscan.cc/
指纹识别
当我们需要在大量资产中获取易受攻击的系统,就需要对资产进行指纹识别( CMS、OA 系统、框架、中间件、厂商系统、VPN等系统 。
CMS/框架识别
CMS(内容管理系统),可用来快速搭建网站、管理和发布内容
框架:如shiro、thinkphp已编写完后端逻辑,等待用户编写对应的页面即可
常见CMS:
- B2C 商城系统:商派 shopex、ecshop、hishop、xpshop、niushop
- 门户建站系统:DedeCMS(织梦)、帝国 CMS、PHPCMS、动易、cmstop
- 博客系统:wordpress、Z-Blog
- 论坛社区:discuz、phpwind、wecenter
- 问题系统:Tipask、whatsns
- 人才招聘网站系统:骑士CMS、PHP 云人才管理系统
- 电影网站系统:苹果cms、ctcms、movcms
- 小说文学建站系统:JIEQI CMS
常用的:z-blog shopxo wordpress discuz dedecms
在线识别
国外识别平台:
https://whatcms.org/
国内识别平台:
bugscaner:http://whatweb.bugscaner.com/
whatweb:https://www.whatweb.net/
云悉:https://www.yunsee.cn/
潮汐:http://finger.tidesec.net/
TSscan:https://scan.dyboy.cn/web/工具识别
更多工具github搜索 :https://github.com/search?q=cms&type=repositories 识别
EHole
下载地址:https://github.com/EdgeSecurityTeam/EHole
使用方法:
Ehole.exe -u url #单个识别
Ehole.exe -l urls.txt -json result.json # 批量识别,结果输出至Result.json中TideFinger
下载地址:【红队】一个Go版(更强大)的TideFinger指纹识别工具
网页插件自动识别:Wappalyzer
下载地址:404 Not Found
Wappalyzer是一款功能强大的、且非常实用的网站技术分析插件,通过该插件能够分析目标网站所采用的平台 构架。
手工识别
识别目标主要有: 开发语言/开发框架/第三方组件/CMS 程序/数据库
开发语言识别
方法一:看网站文件后缀;.asp、.php、.jsp、.aspx、.jspx
方法二:通过抓功能点数据包查看与后台的交互信息
方法三:查看http请求头以及响应头
Cookie: PHPSESSID--> php , JSPSESSID-->jsp , ASPSESSID-- >asp)
方法四:想办法让网站程序报错(访问不存在的路径或提交非法字符)
开发框架识别(CMS、框架)
方法一:根据favicon图标识别https://www.thinkphp.cn/index/index
方法二:根据Robots.txt文件及站点路由判断
robots.txt文件识别:(相关厂商下的cms(内容管理系统)程序文件包含说明当前 cms 名称及版本的特征码)
Disallow: /plus/feedback_js.php
Disallow: /plus/mytag_js.php
Disallow: /plus/rss.php
Disallow: /plus/search.php
看到这个基本可以判断为 dedecms中间件识别
方法一:wappalyzer插件识别
方法二:网站默认页面
1.HTTP相应数据包中查看Server字段*BP抓包*F12*curl http://www.baidu.com -i > ip.txt
2.根据报错信息判断,访问为存在⻚⾯
3.根据默认⻚⾯判断,“Welcome to nginx”
4.通过端⼝服务探测,Tomcat/Jboss-->8080端⼝ Weblogic-->7001端⼝
数据库识别
方式一:常规判断:asp-->sql server , php-->mysql , jsp-->oracle
方式二:端⼝服务:1433-->sql server , 3306-->mysql , 1521-->oracle ,PostgreSQL-->-5432
方式三:⽹站错误信息
操作系统:
url路径大小写判断
总结
指纹识别
1. 框架、cms、三方系统 : ehole、在线网站、kali上工具、wappalyzer、手工识别、报错
2. 语言:查看网站文件的后缀名、抓取交互功能点数据包去看后缀名、查看cookie的session名称、报错
3. 数据库:端口扫描、报错
4. 中间件:wappalyzer、默认页面
5. 操作系统:大小写站点目录
扫描目录主要为了发现网站新的功能点进行测试
#目的:
1.寻找网站后台登录地址
2.寻找未授权访问(本身需要权限认证界面目录,因为配置错误,可以直接访问到)的页面、以及网站的不同的功能点。
3.寻找⽹站更多隐藏的信息、敏感信息
#常见后台路径
admin/ 、admin.后缀、admin/login.后缀 、manage 、webmanager、webadmin等等
#robots.txt
Robots协议 "网络爬虫排除标准",网站通过Robots协议告诉搜索引擎哪些页面可以抓取,哪些页面不能抓取;同时
也记录网站所具有的基本的目录;--》 查看robots.txt能够获取到网站的部分目录文件信息。爆破枚举
# 爆破枚举
原理:通过字典匹配网站是否返回响应正确状态码,然后列出存在的目录;
爆破可能会触发网站防火墙规则拦截,造成封禁IP现象;
# 相关字典
kali默认字典存放位置:
cd /usr/share/wordlists/
在kali中推荐安装secwordlists
sudo apt install seclists
/usr/share/wordlists/seclists
# 网上字典下载:
https://github.com/SexyBeast233/SecDictionary *
https://gitee.com/molok/Blasting_dictionary
https://github.com/TheKingOfDuck/fuzzDicts
https://github.com/fuzz-security/SuperWordlist
https://mp.weixin.qq.com/s/SL9NG2mmD9ABC1eq2ZfVmQ
字典1:https://github.com/3had0w/Fuzzing-Dicts
字典2:https://github.com/shadowabi/S-BlastingDictionarydirB(kali命令)
dirb <url>
自定义爆破字典
dirb http://url/ /usr/share/dirb/wordlists/vulns/apache.txtdirsearch
下载地址:
# kali中
apt-get update
apt-get install dirsearch
# 安装依赖
pip3 install -r requirements.txt
# 常用参数
dirsearch -u https://target
-u 指定url
-l 指定url文件
-e 指定语言 -e php,jsp,asp,tar,zip,rar,js.html 默认 php, aspx, jsp, html, js
-x 排除status_code Example: 301,500-599
-i 只要包含status_code : Example: 200,300-399
-w 字典路径
-r 递归的对目录扫描
-o 输出到指定文件
-t 线程数 默认30
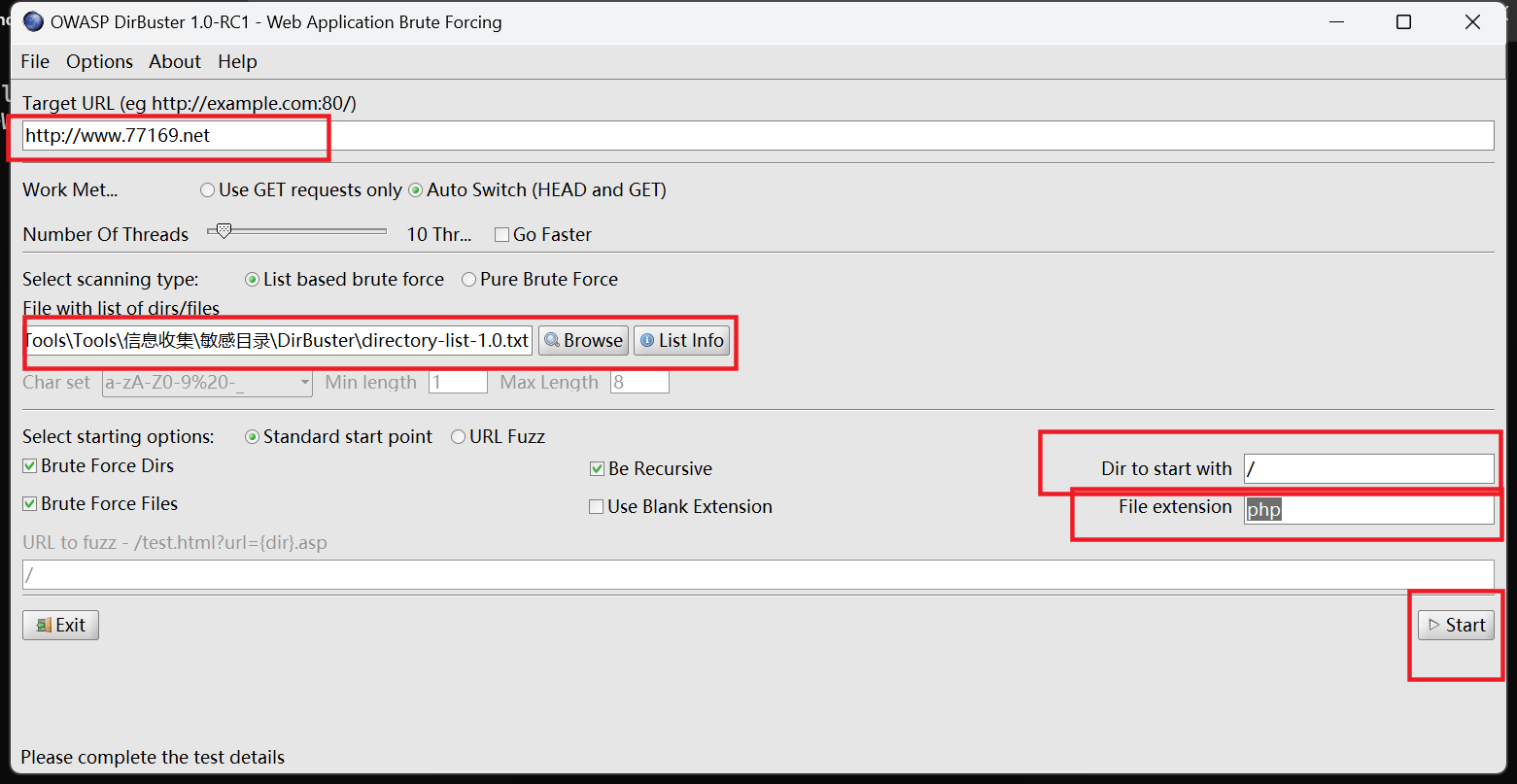
dirbuster(windos可用)
下载地址: https://sourceforge.net/projects/dirbuster/
7KBScan/layer(早期工具,windows可用)
下载地址: https://github.com/7kbstorm/7kbscan-WebPathBrute
物理路径(网站根路径)
1.报错信息
网站报错信息,想办法让网站报错,如果报错时处理不当就会导致路径泄露。(比如访问不存在文件、在url上传递垃圾字符)具体要根据实际情况操作;
报错方法:
- 有动态URL的地方可以替换参数 替换参数值为不存在的,很多时候都能爆物理路径;
- 访问不存在的文件名 文件 或者改正常后缀为不支持的后缀;
- IIS7.0以上,如果没有修改404页面,只要浏览web任意不存在的文件,都会直接暴出绝对路径;
- 同理,thinkphp也有这个性质。 在id=1的注入点,使用各种不支持的字符,比如id=1’ id=? id=-1 id=\ id=/ 都有可能暴出绝对路径;
- 数据库语句报错时也会带出
2.后台地址
可以登录后台的话,后台首页一般都有服务器信息的,大部分情况下物理路径都在里面;
探针文件:
site.php
info.php
phpinfo.php
1.php
a.php
test.php
ceshi.php
3.配置文件找路径
如果注入点有文件读取权限,就可以手工load_file或工具读取配置文件,各平台下Web服务器和PHP的配置文件默
认路径可以上网查;
常见配置文件:
○ c:\windows\php.ini php配置文件
○ c:\windows\system32\inetsrv\MetaBase.xml IIS虚拟主机配置文件
○ C:\xampp\apache\conf\httpd.conf
○ /var/www/conf/httpd.conf
4.常见集成环境默认目录,后面往往还有以域名命名的目录:
○ C:\Inetpub\wwwroot
○ C:\xampp\htdocs
○ D:\phpStudy\WWW
○ /home/wwwroot/
○ /www/users/
5. 默认路径
linux还可以用瞎蒙大法;
○ /var/www/html/网站名
○ /etc/php.ini php配置文件
○ /etc/httpd/conf.d/php.conf
○ /etc/httpd/conf/httpd.conf Apache配置文件
○ /usr/local/apache/conf/httpd.conf
○ /usr/local/apache2/conf/httpd.conf
○ /usr/local/apache/conf/extra/httpd-vhosts.conf 虚拟目录配置文件
敏感文件信息
网站敏感信息
配置文件:x.config 、.conf、.inf、.log
备份文件:.bak、.zip、.rar、.7z、.sql
数据库文件:.sql
网站源码备份文件:web.zip\www.zip\website.zip\www-data.zip
JS敏感信息
每个站点基本上都会使用JavaScript脚本,在JS文件中可能会存放各种接口(目录和文件)提供给前端调用,获取某个接口存在敏感信息返回、未授权访问等漏洞。
findsomeing插件:
会在测试时根据访问网站统计出,HTML\JS中存放的接口与URL信息。
JSlinks插件
BurpSutie插件,在我们进行安全测试时,Burp是我们必备的抓包工具,我们可以通过在Burp下载插件,当流量经过Burp时,该插件会对响应中的文件内容进行读取,提取其中接口URL信息。
jsfinder工具
命令
python JSFinder.py -u http://www.mi.com #普通爬取
python JSFinder.py -u http://www.mi.com -d #深度爬取
python JSFinder.py -u http://www.mi.com -d -ou url.txt -os domain.txt
解释:
-u http://www.mi.com
指定目标 URL(这里是小明的官网),脚本会从该页面开始分析。
-d
通常表示 深度搜索(递归爬取),脚本不仅分析首页的 JS 文件,还会跟踪页面中的其他链接(如子页面、嵌套的 JS 文件),以发现更多隐藏资源。
-ou url.txt
将提取到的 URL(如 API 接口、资源路径) 保存到 url.txt 文件中。
-os domain.txt
将提取到的 域名或子域名(如 api.mi.com、cdn.mi.com)保存到 domain.txt 文件中。手工查找
检查/fn+f12->找JS文件,寻找url
GitHub搜索敏感信息
# 搜索语法
in:name test #仓库标题搜索含有关键字test
in:descripton test #仓库描述搜索含有关键字
in:readme test #Readme文件搜素含有关键字
path:*.env ( NOT homestead NOT root NOT example NOT gmail NOT sample NOT localhost NOT
marutise) password outlook.com
# 搜索实例
eg: stmp 58.com password 3306
# Github关键词监控
下载地址:https://www.codercto.com/a/46640.html其他方式搜索敏感信息
# Google
google配合github搜索敏感信息
● site:Github.com sa password
● site:Github.com root password
● site:Github.com User ID='sa';Password
● site:Github.com inurl:sql
# SVN信息收集
google配合github搜索SVN敏感信息
● site:Github.com svn
● site:Github.com svn username
● site:Github.com svn password
● site:Github.com svn username password
# 综合信息收集
● site:Github.com password
● site:Github.com ftp ftppassword
● site:Github.com 密码
● site:Github.com 内部
# 扩展参考
● https://blog.csdn.net/qq_36119192/article/details/99690742
● http://www.361way.com/github-hack/6284.html
● https://docs.github.com/cn/github/searching-for-information-on-github/searching-ongithub/searching-code
● https://github.com/search?q=smp+bilibili.com&type=code源码泄露
git源码泄露
svn源码泄露
hg源码泄漏
网站备份压缩文件
WEB-INF/web.xml 泄露
DS_Store 文件泄露
SWP 文件泄露
CVS泄露
GitHub源码泄漏
Git
Git是开源的分布式版本控制系统,在执行 git init 初始化目录时,会在当前目录下自动创建一个 .git目录,用来记录代码变更的记录。发布代码时,如果没有把 .git 目录删除,攻击者就可以通过它查询源代码。
利用工具:GitHack
项目地址:https://github.com/BugScanTeam/GitHack
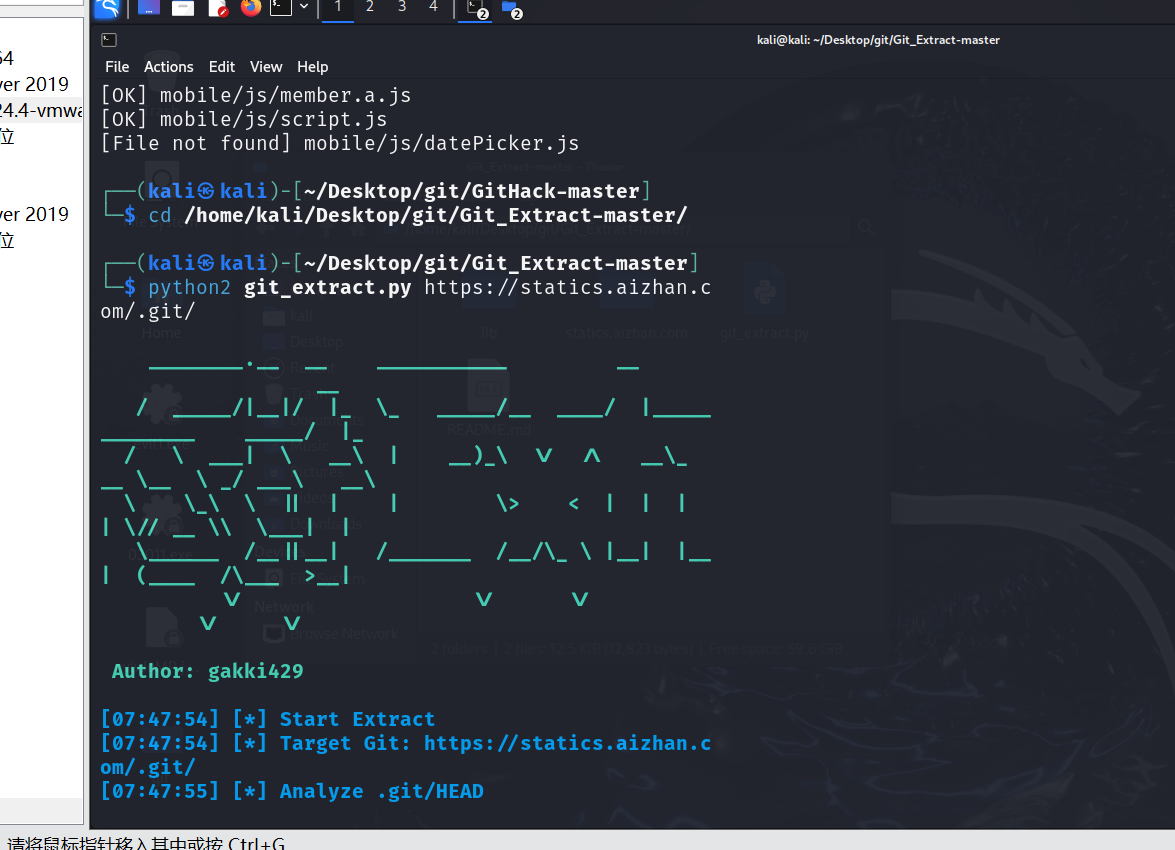
案例:https://statics.aizhan.com/.git/config
使用方法:python2 GitHack.py https://statics.aizhan.com/.git
使用方法2:python2 git_extract.py https://statics.aizhan.com/.git/ 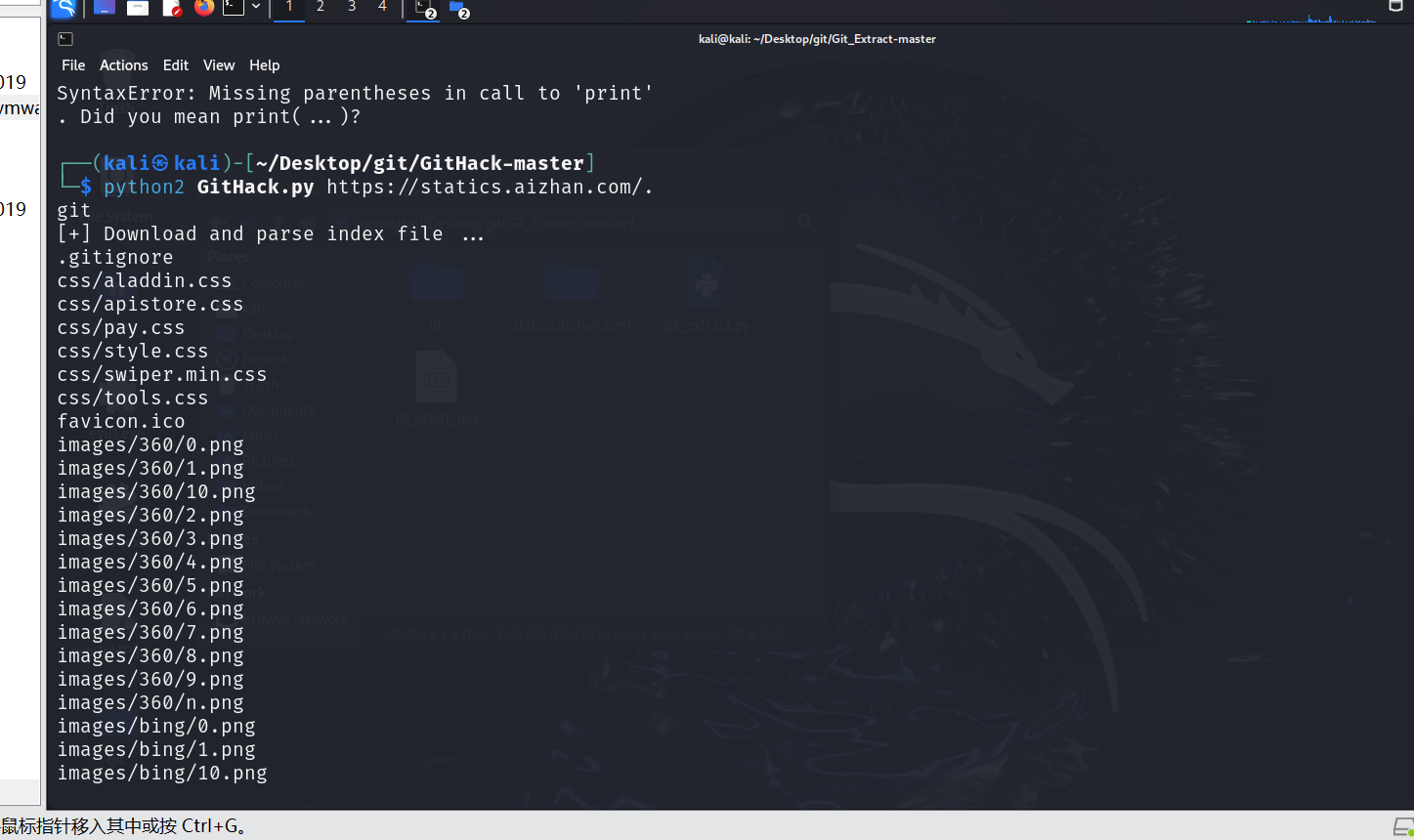
CVS
SVN
SVN是一个开放源代码的版本控制系统。在使用 SVN 管理本地代码过程中,会自动生成一个名为 .svn 的隐藏文件夹,其中包含重要地方源代码信息。网站管理员在发布代码时,没有使用‘导出’功能,而是直接复制代码文件夹到WEB服务器上,这就使 .svn隐藏文件夹 被暴露在外网环境,可以使用 .svn/entries 文件,获取到服务器源码。
利用工具:svnExploit
项目地址:https://github.com/admintony/svnExploit 推荐:svnExploit-master
首次安装依赖库:
python3 -m pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
使用方法:
python3 SvnExploit.py -u http://223.247.153.184:3000/.svn
python3 SvnExploit.py -u http://223.247.153.184:3000/.svn --dump.DS_store文件
.DS_store 是Mac下Finder用来保存如何展示 文件/文件夹 的数据文件,每个文件夹下对应一个。如果将 .DS_store上传部署到服务器 ,能造成文件目录结构泄露,特别是备份文件、源代码文件。
利用工具:ds_store_exp
项目地址:https://github.com/lijiejie/ds_store_exp
案例网站:http://xhsci-hk-gcp-cos.xiaohongshu.net/.DS_Store
安装依赖库:
python3 -m pip install ds-store -i https://pypi.tuna.tsinghua.edu.cn/simple
使用方法:python3 ds_store_exp.py http://xhsci-hk-gcp-cos.xiaohongshu.net/.DS_Store
网站备份文件
WEB-INF/web.xml文件
WEB-INF是Java的WEB应用的安全目录,如果想在页面中直接访问其中的文件,必须通过web.xml文件对要访问的文件进行相应映射才能访问;
WEB-INF 主要包含以下文件或目录:
WEB-INF/web.xml : Web应用程序配置文件, 描述了servlet和其他的应用组件配置及命名规则.
WEB-INF/database.properties : 数据库配置文件
WEB-INF/classes/ : 一般用来存放Java类文件(.class)
WEB-INF/lib/ : 用来存放打包好的库(.jar)WEB-INF/src/ : 用来放源代码(.asp和.php等)
通过找到 web.xml 文件,推断 class 文件的路径,最后直接打开 class 文件,再通过反编译 class 文件,得到网站源码;查找域名对应的IP--CDN(内容分发网络)
简介
缓存服务器数据,就近向用户提供功能。会产生多个IP。
一般来说如果网站开启了CDN服务,会根据用户所在地不同访问不同的CDN的节点服务器,并不直接访问源服务器。这样可以有效防止渗透测试以及DDOS、CC攻击也是一种防护方式。
作用
加速网站访问、减轻服务器压力、抗流量攻击。
CDN验证
例子:
www.7e.hk
0x7e.cn
多地ping
使用全球各个国家位置计算机对其进行ping操作,如果结果出现多个IP地址则存在CDN,如果为单个则不存在。
国内在线:
超级ping:http://ping.chinaz.com/
爱站:https://ping.aizhan.com/
站长工具:http://tool.chinaz.com/speedworld/
ping:http://www.ping.pe/
ipip:https://tools.ipip.net/httphead.php
wepcc:https://www.wepcc.com/nslookup
使用 nslookup 进行检测,原理同ping,如果返回域名解析对应多个 IP 地址多半是使用了 CDN;
nslookup 域名CDN绕过
绕过CND发现其真实IP方式
1.查询DNS历史解析记录
2.查询网站的(SSL证书)证书应用服务器
3.查询子域名的IP地址
4.通过空间搜索引擎搜索相关资产
5.通过空间搜索引擎网站的logo的hash
6.通过网站敏感信息泄露获取其IP
DNS历史记录
查看 IP 与 域名绑定的历史记录,可能会存在使⽤ CDN 前的记录;
查询网站
https://ipchaxun.com/
##综合
https://dnsdb.io/zh-cn/
###DNS查询
https://x.threatbook.cn/
###微步在线
http://toolbar.netcraft.com/site_report?url=
###在线域名信息查询
http://viewdns.info/
###DNS、IP等查询
https://tools.ipip.net/cdn.php
###CDN查询IP网络空间搜索引擎
利用网站返回的内容寻找真实原始IP,如果原始服务器IP也返回了网站的内容,那么可以在网上搜索大量的相关数据;
根据网站特征搜索相关站点:
查询网站:
FOFA:https://fofa.info/
title="网站的title关键字"
body="网站的body特征"
domain="t00ls.net"
钟馗之眼:https://www.zoomeye.org/
Shodan:https://www.shodan.io/
hunter:https://hunter.qianxin.com/ICO图标搜索真实IP
https://www.t00ls.com/favicon.ico 下载图标 放到fofa识别
1. F12网络
2. 查看源码
利用SSL证书寻找真实原始IP
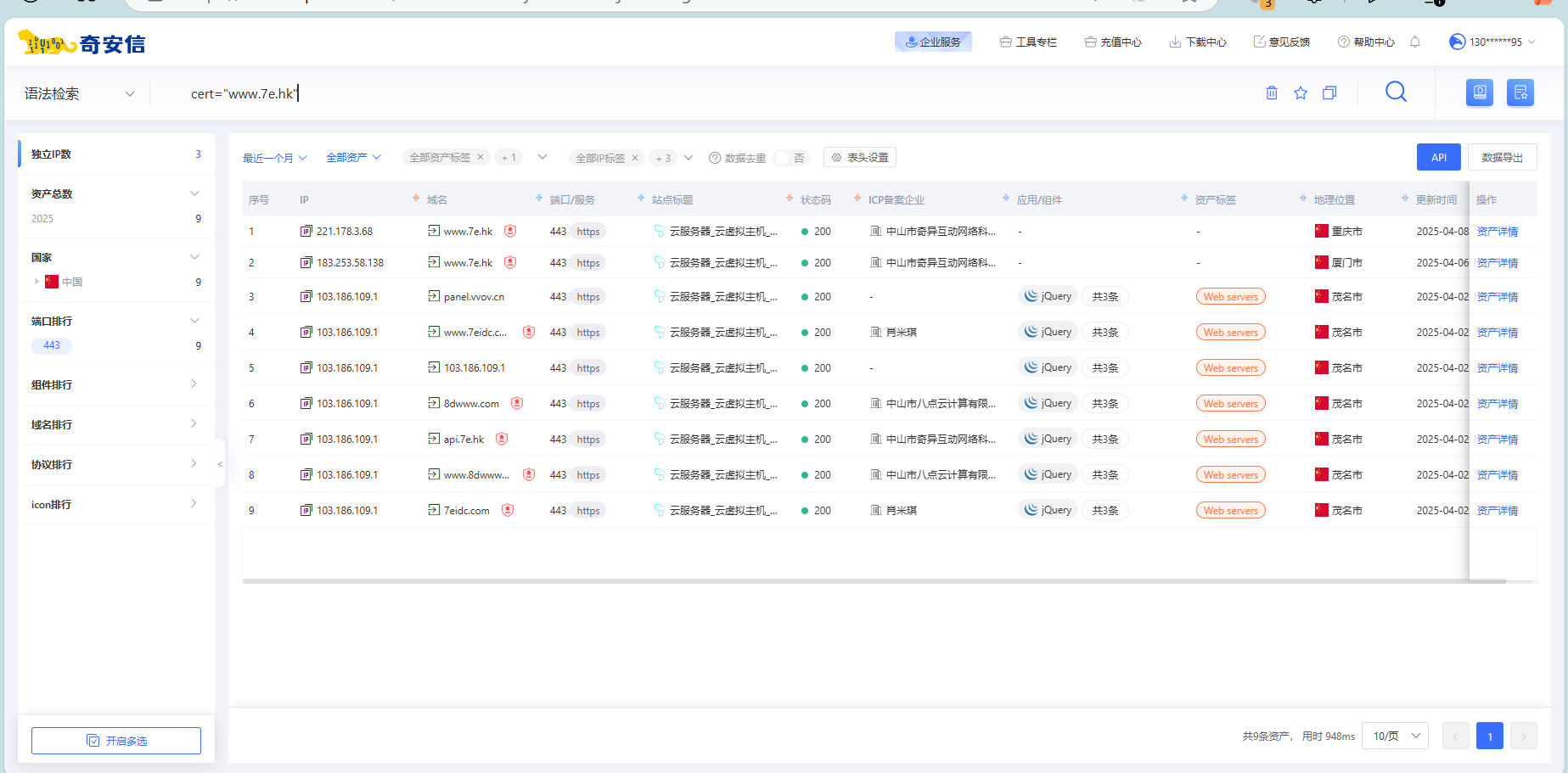
证书颁发机构(CA)必须将他们发布的每个SSL/TLS证书发布到公共⽇志中,SSL/TLS证书通常包含域名、⼦域名和电⼦邮件地址。因此SSL/TLS证书成为了攻击者的切⼊点。
cert="www.7e.hk"、
使用国外主机解析域名
国内很多 CDN 厂商因为各种原因只做了国内的线路,而针对国外的线路可能几乎没有,此时我们使用国外的主机直接访问可能就能获取到真实IP。
#国内在线
超级ping:http://ping.chinaz.com/
爱站:https://ping.aizhan.com/
站长工具:http://tool.chinaz.com/speedworld/
# 国外在线
cdnplanet:https://www.cdnplanet.com/tools/cdnfinder/ping:http://www.ping.pe/
# 全球
ipip:https://tools.ipip.net/httphead.phpwepcc:https://www.wepcc.com/
17ce :https://www.17ce.com/网站漏洞查找
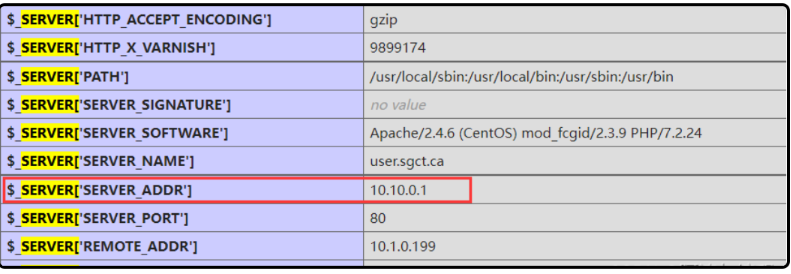
⽬标敏感文件泄露,例如:phpinfo之类的探针、GitHub信息泄露等;XSS盲打,命令执行反弹shell,SSRF等;
无论是⽤社工还是其他手段,拿到了⽬标⽹站管理员在CDN的账号,从⽽在从CDN的配置中找到⽹站的真实IP;
查询子域名
毕竟 CDN 还是不便宜的,所以很多站长可能只会对主站或者流量⼤的⼦站点做了 CDN,⽽很多⼩站⼦站点⼜跟主站在同⼀台服务器或者同⼀个C段内,此时就可以通过查询⼦域名对应的 IP 来辅助查找⽹站的真实IP。
https://x.threatbook.cn/https://dnsdb.io/zh-cn/https://securitytrails.com/list/keywordhttps://tool.chinaz.com/subdomain/
Google 搜索;例如:用语法"site:baidu.com -www"就能查看除www外的子域名。
找到子域名继续确认子域名没有cdn的情况下批量进行域名解析查询,有cdn的情况继续查询历史;域名批量解析:
http://tools.bugscaner.com/domain2ip.html端口扫描
当我们确定了大概的IP后,可以先对IP的开放端口进行探测。因为不同端口上运行着不同的服务;一些特定服务可能开启在默认端口上。探测也是利于快速收集目标资产,找到目标网站的其他功能站点。
# Web应用服务端口
80/443/8080---> 常见web端口
7001/7002--> Weblogic控制台
8080--> Jboss/Resin/Jetty/Jenkins
9090--> WebSphere控制台
4848--> GlassFish控制台
1352--> Lotus domino控制台
10000--> Webmin-Web控制面板
# 文件共享服务端口
21--> Ftp文件传输协议
69--> tftp文件传输协议
389--> Ldap目录访问协议
2049--> Nfs服务
389--> Ldap目录访问协议
# 远程连接服务端口
22--> SSH远程连接
3389--> rdp远程连接
5900--> VNC
5632--> Pyanywhere服务
# 邮件服务端口
25--> SMTP服务
110--> POP3协议
143--> IMAP协议
# 网络常见协议端口
53--> DNS域名系统
161--> SNMP协议
# 特殊服务端口
2181--> Zookeeper服务--分布式应用程序协同服务
8069--> Zabbix服务--基于WEB界面的提供分布式系统监视以及网络监视功能的企业级的开源解决方案
9200/9300--> Elasticsearch服务--分布式多用户能力的全文搜索引擎
11211--> Memcache服务--分布式的高速缓存系统
873--> Rsync服务--linux系统下的数据镜像备份工具
3690--> Svn服务--开放源代码的版本控制系统
# 特殊服务端口(未授权/命令执行)
443 SSL心脏滴血
873 Rsync未授权
5984 CouchDB http://xxx:5984/_utils/
6379 redis未授权
7001,7002 WebLogic默认弱口令,反序列
9200,9300 elasticsearch 参考WooYun: 多玩某服务器ElasticSearch命令执行漏洞
11211 memcache未授权访问
27017,27018 Mongodb未授权访问
50000 SAP命令执行
50070,50030 hadoop默认端口未授权访问masscan
下载地址:https://github.com/robertdavidgraham/masscan
# 使用方式
单端口扫描
masscan 10.11.0.0/16 -p443
扫描一系列端口
masscan 10.11.0.0/16 -p1-1024
快速扫描
默认情况下,masscan扫描的速度为每秒100个数据包,为了增加这一点,只需提供该-rate选项并指定一个值masscan 10.11.0.0/16 --top-ports 100 -rate 100000
排除目标
为了更好的,愉快的玩耍,必要时要对扫描目标进行排除
masscan 10.11.0.0/16 --top-ports 100 --excluedefile exclude.txt
保存扫描结果
可以使用标准的unix重定向器将扫描结果输入到一个文件中masscan 10.11.0.0/16 --top-ports 100 > result.txt
扫描十大端口
masscan 10.11.0.0/16 -top-ten -rate 100000御剑
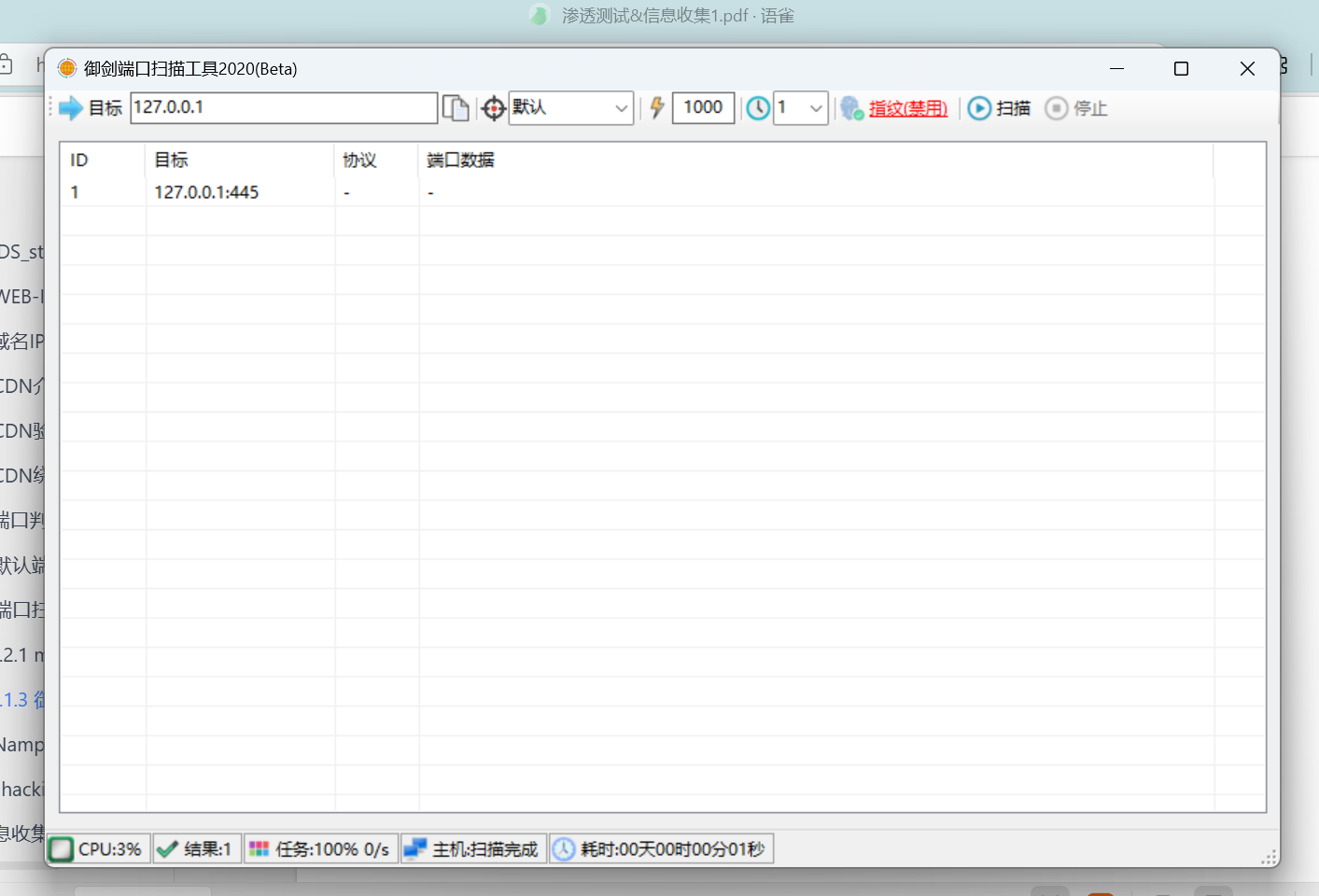
nmap
Nmap是一款开源免费的网络发现( Network Discovery )和安全审计(Security)工具,软件名字Nmap是 NetworkMapper 的简称。
黑客入侵大体可以分为3个过程: 信息收集 、 弱点分析 、 执行入侵 ;其中Nmap既可以用于黑客前期收集主机信息,也可以用于管理员了解网络情况,甚至还可以弱点扫描。
Nmap提供这几种功能:
主机发现,端口扫描,操作系统识别,服务识别,脚本扫描。
主机发现:去发现网段内存活得主机(在线主机)
端口扫描:端口1-65535
操作系统识别:去识别对方使用了什么操作
服务识别:识别端口上得服务版本
脚本扫描:调用nmap自带的脚本去检测漏洞
主机发现原理
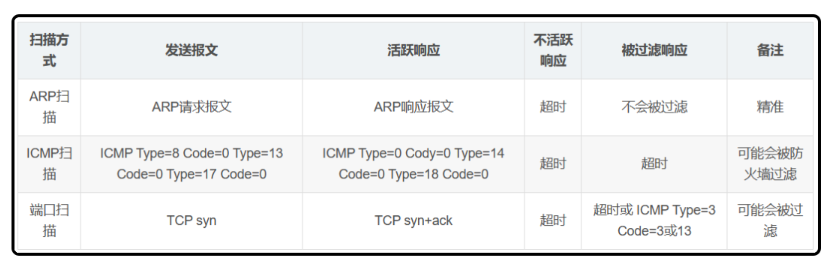
- ARP扫描:是最精准的扫描方式,并不会被过滤,因此会被强制使用。
- ICMP扫描:是最常见的扫描方式,和ping命令原理一致,但现在很多防火墙和IPS设备会禁用ICMP扫描,使得ICMP
主机发现失败 - 端口扫描:是另一种发现主机的方式,准确且不容易被防火墙过滤,这种方式经常被使用
端口扫描技术
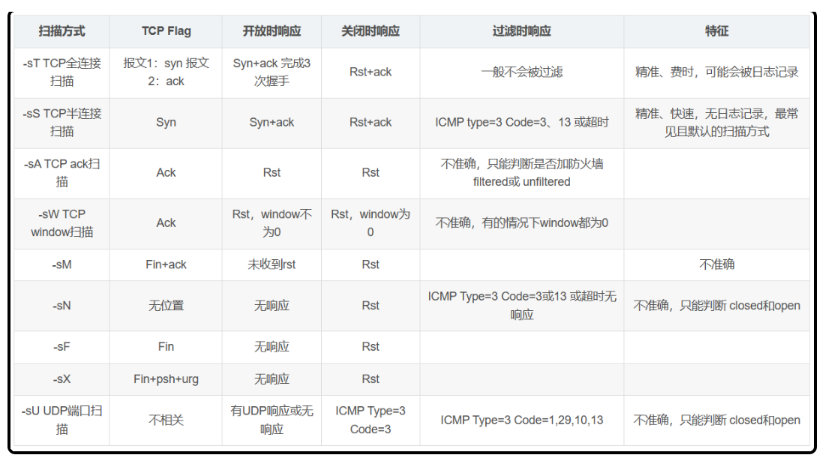
Nmap的端口扫描可以分为 TCP端口扫描和UDP端口扫描 ;
由于TCP能够提供更多的协议字段,因此TCP端口扫描更精准,如今的端口扫描技术主要是指TCP端口扫描,在TCP端口扫描技术中,探测报文组合不同flags位,不同的flags在端口开放、端口关闭、防火墙过滤时的响应是不一样的,通过区分不同的响应来探测端口的状态判断是哪个端口,具体如下所示 (tcp flags有 syn 、 ack 、 rst 、 fin 、psh 、 urg 共6种位置)
扫描端口参数:-p
-p 80
-p 1-1024
-p- 扫描全端口
扫描模式
tcp扫描(扫描TCP端口 扫描速度慢,扫描精准) -sT
udp扫描(扫描UDP端口 扫描速度块) -sU
半开扫描(三次握手,只做第一步) -sS
全面扫描(扫描端口、存活主机) -ANmap命令
扫描目标参数
nmap 192.168.1.1 扫描一个IP *
nmap 192.168.1.1/24 扫描IP段 *
nmap nmap.org 扫描一个域名
nmap -iL target.txt 扫描文件中的目标
nmap --exclude 192.168.1.1 排除列出的主机
nmap 192.168.1.1-254 扫描一个范围
nmap 192.168.1.1 -v 增加详细程度,-vv效果更好
nmap 192.168.1.1 -oN test.txt 标准输出写入到指定文件中扫描方式
nmap 192.168.1.1 -sS TCP SYN端口扫描 *
nmap 192.168.1.1 -sT TCP连接端口扫描 *
nmap 192.168.1.1 -sU UDP端口扫描 *
nmap 192.168.1.1 -sA TCP ACK端口扫描
nmap 192.168.1.1/24 -sn 禁用端口扫描
nmap 192.168.1.1-5 -Pn 跳过主机发现,直接扫描端口,无ping扫描*
nmap 192.168.1.1 -n 不做DNS解析端口扫描范围
nmap 192.168.1.1 -p 21 扫描特定端口 *
nmap 192.168.1.1 -p 21-100 扫描端口范围 *
nmap 192.168.1.1 -p U:53,T:21-25,80 扫描多个TCP和UDP端口
nmap 192.168.1.1 -p- 扫描所有端口 *
nmap 192.168.1.1 -p http,https 基于服务名称的端口扫描扫描线程
nmap 192.168.1.1 -T0 妄想症,非常非常慢,用于IDS逃逸
nmap 192.168.1.1 -T1 猥琐的,相当慢,用于IDS逃逸
nmap 192.168.1.1 -T2 礼貌的,降低速度以消耗更小的带宽,比默认慢十倍
nmap 192.168.1.1 -T3 正常的,默认,根据目标的反应自动调整时间模式
nmap 192.168.1.1 -T4 野蛮的,在一个很好的网络环境,请求可能会淹没目标
nmap 192.168.1.1 -T5 疯狂的,很可能会淹没目标端口或是漏掉一些开放端口漏洞脚本扫描
nmap 192.168.1.1 --script=banner 使用单个脚本扫描,banner示例
nmap 192.168.1.1 --script=http* 使用通配符扫描,http示例
nmap 192.168.1.1 --script=vuln 扫描常见漏洞服务版本探测
nmap 192.168.1.1 -sV 尝试确定端口上运行的服务的版本
nmap 192.168.1.1 -A 启用操作系统检测,版本检测,脚本扫描和跟踪路由
nmap 192.168.1.1 -O 使用TCP/IP进行远程OS指纹识别
nmap 192.168.1.1 -O --osscan-guess 当Nmap无法确定所检测的操作系统时,会尽可能地提供最相近的匹配常用参数
-sV 探测端口服务版本
-O 探测主机操作系统
-p 扫描端口
-sP -sn 主机发现
-sT 进行TCP扫描
-sU 进行UDP扫描
-sS tcp半开扫描
-A 启用操作系统检测,版本检测,脚本扫描和跟踪路由
--script= 指定扫描脚本文件
--proxies=xx 挂代理
-iL 扫描文件中的目标
-T0-5 扫描速率、
-O 识别操作系统得原理
通过 TCP/IP 数据包发到目标主机,由于每个操作系统类型对于处理 TCP/IP 数据包都不相同,所以可以通过之间的差别判定操作系统类型;
Google Hacking
语法参考文章:Google黑客常用搜索语法_黑客搜索语法-CSDN博客
# 搜索引擎
百度:www.baidu.com
bing:www.bing.com
Yahoo:www.search.yahoo.com
aol:www.search.aol.com
google:google.cn
# 搜索语法 Google Hacker语法
intitle: 标题关键字 eg:intitle 后台登陆
inurl: URL关键特征 eg:inurl admin.php
intext: 内容关键词 eg:intext 文件上传
filetype: 指定类型文件 //例如:bak , mdb , asp , php , jsp
site: 指定域名
link: baidu.com //表示返回所有和baidu.com做了链接的网站
info: 查找指定站点的一些基本信息
cache: 搜索google里关于某些内容的缓存
intitle:标题关键字 查询在网站标题中存在该关键字的站点
inurl:URL关键字 查询在URL路径中存在该关键字的站点
intext:内容关键词 查询在网站主体中存在该关键字的站点
filetype:文件类型 查询存在指定文件类型的站点
site: 指定域名 查询在搜索引擎下的所收录的资产
举例:
ntext:管理filetype:mdbinurl:file
site:http://xx.com filetype:txtsite:http://xx.com filetype:asp
site:tw inurl:asp?id= //查找台湾的
intitle:旁注- 网站 filetype:asp
http://lmb.scsio.cas.cn/xzzx/201411/P020141121459287656532.xls
# Google Hacker Database(GHDB)https://www.exploit-db.com/google-hacking-database常用语法
--管理后台地址
site:mi.com intext:管理 | 后台 | 后台管理 | 登录 | 用户名 | 密码 | 系统 | login |system
site:mi.com inurl:login | inurl:admin | inurl:manage | inurl:manager | inurl:admin_login |
inurl:system | inurl:backend
site:mi.com intitle:管理 | 后台 | 后台管理 | 登录
--上传类漏洞
site:target.com inurl:file
site:target.com inurl:upload
--注入漏洞
site:target.com inurl:php?id=
inurl:asp?id=
inurl:?id=1
--编辑器
site:target.com inurl:ewebeditor
--目录遍历漏洞
site:target.com intitle:index.of
--phpinfo()
site:target.com ext:php intitle:phpinfo "published by the PHP Group"
--配置文件泄露
site:target.com ext:.xml | .conf | .cnf | .reg | .inf | .rdp | .cfg | .txt | .ora | .ini
--数据库文件泄露
site:target.com ext:.sql | .dbf | .mdb | .db
--备份|历史文件泄露
site:target.com filetype:.doc | .docx | .xls | .xlsx | .ppt | .pptx | .odt | .pdf | .rtf |
.sxw | .psw | .csv
--邮箱信息
site:target.com intext:@target.com
site:target.com 邮件
site:target.com email
--社工信息
site:target.com intitle:账号 | 密码 | 工号 | 学号 | 身份证其他信息收集
社会工程学
在tg找社工机器人查找密码信息 或本地的社工库查找邮箱或者用户的密码或密文,组合密码在进行猜解登录;
https://t.me/aishegongkubot?start=AISGK_RESM8OIS
https://t.me/AJL01_bot?start=ZiMjRpF9bk
# 社工库
Telegrame
@SGKmainNEWbot非常规操作
1、如果找到了目标的一处资产,但是对目标其他资产的收集无处下手时,可以查看一下该站点的 body
里是否有目标的特征,然后利用网络空间搜索引擎(如 fofa 等)对该特征进行搜索,如:body="XX 公
司" 或 body="baidu" 等;该方式一般适用于特征明显,资产数量较多的目标,并且很多时候效果拔群;
2、当通过上述方式的找到 test.com 的特征后,再进行 body 的搜索,然后再搜索到 test.com 的时候,
此时 fofa 上显示的 ip 大概率为 test.com 的真实 IP;
3.当你对一个目标挖掘不到漏洞的时候(通过指纹识别来判断他是否是一套系统)
通过fofa,去搜索使用这套系统的其他网站,去挖掘其他网站的漏洞。APP信息收集
# 抓包精灵
https://m.cr173.com/mipx/277701.html
# APP软件搜索
https://www.qimai.cn/
# 微信/支付宝小程序
现在很多企业都有小程序,可以关注企业的微信公众号或者支付宝小程序,或关注运营相关人员,查看朋友圈,获取小
程序;微信直接搜索,支付宝直接搜索
公众号搜索网站:
https://weixin.sogou.com/weixin?type=1&ie=utf8&query=%E6%8B%BC%E5%A4%9A%E5%A4%9A
# 公众号小程序收集:小蓝本
# APP收集:https://app.diandian.com/资产管理
--ARL
搭建教程:https://mp.weixin.qq.com/s/mjpeps5H42xVdsLB-tfVqw
默认账户密码:admin/arlpass
# 介绍
旨在快速侦察与目标关联的互联网资产,构建基础资产信息库。
协助甲方安全团队或者渗透测试人员有效侦察和检索资产,发现存在的薄弱点和攻击面
地址:https://github.com/TophantTechnologyARL
--Tide-Mars
# 介绍
主要功能:客户管理、资产发现、子域名枚举、C 段扫描、资产变更监测、端口变更监测、域名解析变
更监测、Awvs 扫描、POC 检测、web 指纹探测、端口指纹探测、CDN 探测、操作系统指纹探测、泛解析
探测、WAF 探测、敏感信息检测等等。目前被动扫描准备对接 xray+wascan,准备二期开源该功能及其
他若干功能;
地址:https://github.com/TideSec/Mars参考文章
子域名收集:史上最全的子域名收集姿势-CSDN博客
信息收集:

















 814
814

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









