







近年来由于抓取数据而引起的纠纷越来越多,有的锒铛入狱,有的被处罚金,本人爬虫笔记学习提醒大家:爬虫有风险,采集需谨慎,写代码不能违法,写代码背后也有法律风险
1.1爬虫注意点
1.1.1遵守Robots协议
Robots协议,也称为爬虫协议、机器人协议等,全称是“网络爬虫排除标准”(Robots Exclusion Protocol),网站通过Robots协议告诉爬虫哪些页面可以抓取,哪些页面不能抓取
如何查看网站的rebots协议?
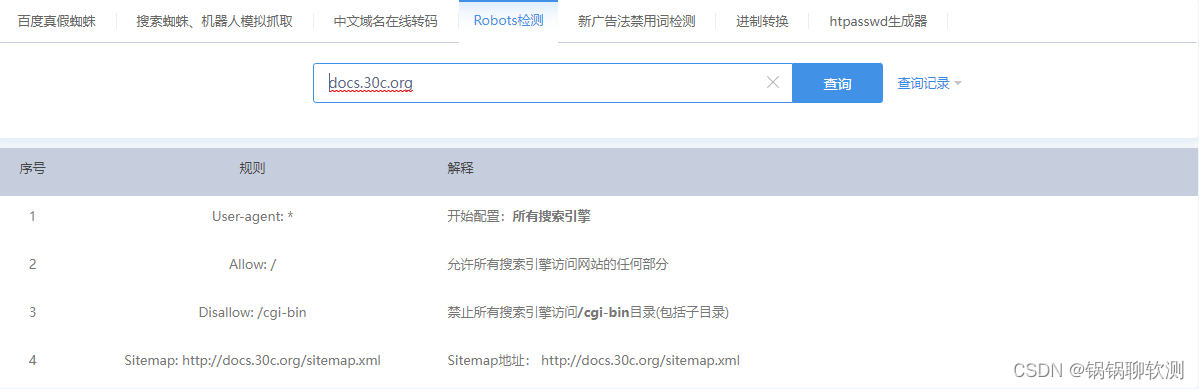
(1)打开浏览器,在地址栏中输入http://网站域名/robots.txt即可,以查询百度的robots协议为例;Disallow后边的目录是禁止所有搜索引擎搜索的

(2)或者借助相关网站进行查看,如站长工具等,浏览器打开
http://s.tool.chinaz.com/robots,输入网站地址,点击查询即可
1.1.2.不过度采集数据
过度数据采集会对目标站点产生非常大的压力,可导致目标站点服务器瘫痪、不能访问等,相当于网
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 2566
2566











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











