







一、sort命令
以行为单位对文件内容进行排序,也可以根据不同的数据类型来排序
比较原则是从首字符向后,依次按ASCII码值进行比较,最后将他们按升序输出。
1.语法格式:
sort [选项] 参数
cat file | sort 选项
2.常用选项
| 选项 | 含义 |
| -n | 按照数字进行排序 |
| -r | 反向排序 |
| -u | 等同于uniq,表示相同的数据仅显示一行 |
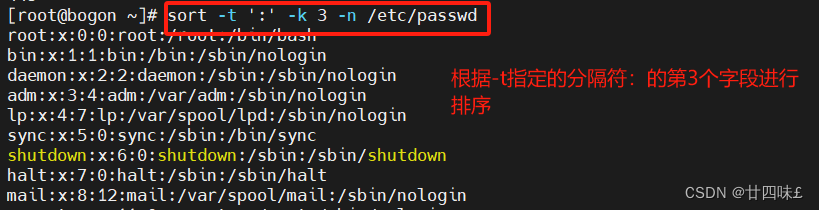
| -t | 指定字段分隔符,默认使用[Tab]键分隔 |
| -k | 指定排序字段 |
| -o | <输出文件>:将排序后的结果转存至指定文件 |
| -f | 忽略大小写,会将小写字母都转换为大写字母来进行比较 |
| -b | 忽略每行前面的空格 |
#排序
[root@bogon ~]# cat 1.txt
16
1
32
56
8
66
65
76
[root@bogon ~]# sort -n 1.txt #正向排序
1
8
16
32
56
65
66
76
[root@bogon ~]# sort -n -r 1.txt #反向排序
76
66
65
56
32
16
8
1
[root@bogon ~]#
#去除重复行
[root@bogon ~]# cat 2.txt
11
445
123
123
123
2222
2222
[root@bogon ~]# sort -u 2.txt
11
123
2222
445
[root@bogon ~]#
二、uniq命令
用于报告或者忽略文件中连续的重复行,常与 sort 命令结合使用
1.语法格式:
uniq [选项] 参数
cat file | uniq 选项
2.常用选项
| 选项 | 含义 |
| -c | 对连续的重复行进行去重,并统计重复次数 |
| -d | 仅输出连续重复的行 |
| -u | 仅输出不连续重复的行 |
#统计重复行并且去重
[root@bogon ~]# sort -n 2.txt | uniq -c #统计重复行并且去重
1 11
3 123
1 445
2 2222
[root@bogon ~]#
#仅输出不连续的重复行
[root@bogon ~]# sort -n 2.txt | uniq -u #仅输出不连续的重复行
11
445
[root@bogon ~]#
#仅输出连续行
[root@bogon ~]# sort -n 2.txt | uniq -d
123
2222
[root@bogon ~]#
三、tr命令
常用来对来自标准输入的字符进行替换、压缩和删除
1.语法格式:
tr [选项] [参数]
2.常用选项
| 选项 | 含义 |
| -t | tr命令的默认选项,使用 参数2 的字符替换成 参数1 的字符 |
| -c | 仅保留 参数1 的字符,其它字符(包括\n)都替换成 参数2 的字符 |
| -s | 根据 参数1 进行去重,如果有 参数2 则再用 参数2 的字符替换 参数1 的字符 |
| -d | 删除所有 参数1 的字符 |
#使用 参数2 的字符替换成 参数1 的字符
[root@bogon ~]# echo abc | tr "ab" "123"
12c
注意:使用-t时默认更换条件为后面的根据前面的更换的字符一致
#将“.” 更换为“ ”
[root@bogon ~]# echo '192.168.10.120' | tr '.' ' '
192 168 10 120
[root@bogon ~]#
#转换大小写
[root@bogon ~]# echo 'ABC' | tr 'A-Z' 'a-c'
abc
[root@bogon ~]#
删除空行 cat 文件 | grep -v "^$"
cat 文件 | tr -s "\n"Windows的另起一行格式(\r\n)转换成 Linux的另起一行格式(\n) cat 文件 | tr -d '\r' > 新文件
对数组排序 echo ${数组名[@]} | tr ' ' '\n' | sort -rn | tr '\n' ' '
#删除指定元素
[root@bogon ~]# echo ABC | tr -d "AB"
C
[root@bogon ~]#
四、cut命令
显示行中的指定部分,删除文件中指定字段
1.语法格式:
cut 参数
cat file | cut 选项
2.常用选项:
| 选项 | 含义 |
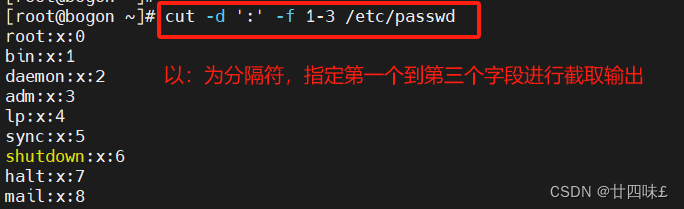
| -f | 通过指定哪一个字段进行提取。cut命令使用“TAB”作为默认的字段分隔符 |
| -d | “TAB”是默认的分隔符,使用此选项可以更改为其他的分隔符 |
| --complement | 此选项用于排除所指定的字段 |
| --output-delimiter | 更改输出内容的分隔符 |
3.字符串分片
echo ${变量:下标:长度} #下标起始从0开始
echo $变量 | cut -b 起始下标-终止下标 #下标起始从1开始
expr substr $变量 起始下标 长度 #下标起始从1开始


五、split命令
linux下将一个大的文件拆分成若干小文件
1.语法格式:
split 选项 参数 原始文件 拆分后文件名前缀
2.常用选项
| 选项 | 含义 |
| -l | 根据行数分割文件 |
| -b | 根据大小分割文件 |
| -d | 输出的目标文件后缀用数字替代 |
如何将一个10G文件分割为10个1G的文件 split -b 1G -d 原文件 目标文件名前缀
如何将一个100行文件分割为10个10行的文件 split -l 10 -d 原文件 目标文件名前缀
#将 a.txt 和 b.txt 按照行合并
cat a.txt b.txt > c.txt
#按照列合并的命令
paste a.txt b.txt > c.txt六、paste命令
用于合并文件的列
paste [-s][-d <间隔字符>] 文件...
-d '分隔符' 指定输出的字段分隔符
-s 将每个列横向输出
合并文件的行 cat 文件1 文件2 ... > 新文件
合并文件的列 paste -d '分隔符' 文件1 文件2 ... > 新文件
[root@localhost tr]#cat a b
1 2 3
2 3 4
2 1 2
4 3 4
2 1 3
12 1 3
12 11 21
11 12 34
a b c
c b a
d e f
f d e
f h j
g k l
1 2 3
[root@localhost tr]#cat b|awk '{print $2}' >c #将ab文件中第二列分别保存到cd文件再用paste进行合并
[root@localhost tr]#cat a|awk '{print $2}' >d #如果要保存该内容可以用重定向输出进行保存
[root@localhost tr]#paste c d
b 2
b 3
e 1
d 3
h 1
k 1
2 11
12七、eval命令
命令字前加上eval时,shell会在执行命令之前扫描它两次。eval命令将首先会先扫描命令行进行所有的置换,然后再执行该命令。该命令适用于那些一次扫描无法实现其功能的变量。该命令对变量进行两次扫描。
eval 在命令行执行前,先将命令行里的变量置换成对应的值后,再执行命令
a=100
b=a
eval echo \$$b 置换成--> echo $a 执行-> 100
eval $b=50 置换成--> a=50 执行
echo $a -> 50
#!/bin/bash
#这是一个验证eval扫描的脚本
a=100
b=a
echo "普通echo输出的变量b的值为:" \$$b
eval echo "经过eval扫描输出变量b的值为:" \$$b八、正则表达式元字符
1.概况
正则表达式是由普通字符与元字符组成
普通字符包括大小写字母、数字、标点符号及一些其他符号
元字符是指在正则表达式中具有特殊意义的专用字符,可以用来规定其前导字符(即位于元字符前面的字符或表达式)在目标对象中的出现模式
2.基础元字符
\ :转义字符,用于取消特殊符号的含义,例:\!、\n、\$等
^ :匹配字符串开始的位置,例:^a、^the、^#、^[a-z]
$ :匹配字符串结束的位置,例:word$、^$匹配空行
. :匹配除\n之外的任意的一个字符,例:go.d、g..d
* :匹配前面子表达式0次或者多次,例:goo*d、go.*d
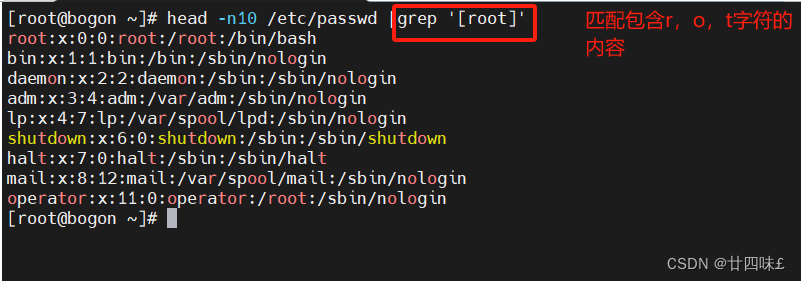
[list] :匹配list列表中的一个字符,例:go[ola]d,[abc]、[a-z]、[a-z0-9]、[0-9]匹配任意一位数字
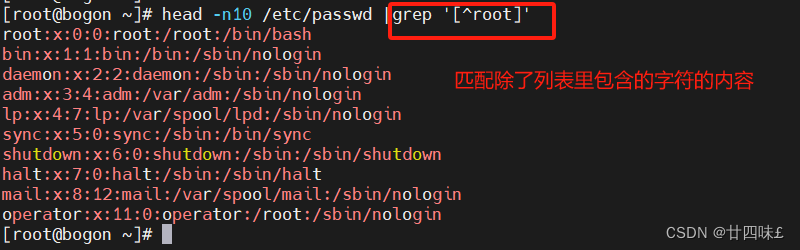
[^list] :匹配任意非list列表中的一个字符,例:[^0-9]、[^A-Z0-9]、[^a-z]匹配任意一位非小写字母
\{n\} :匹配前面的子表达式n次,例:go\{2\}d、'[0-9]\{2\}'匹配两位数字
\{n,\} :匹配前面的子表达式不少于n次,例:go\{2,\}d、'[0-9]\{2,\}'匹配两位及两位以上数字
\{n,m\} :匹配前面的子表达式n到m次,例:go\{2,3\}d、'[0-9]\{2,3\}'匹配两位到三位数字
注:egrep、awk使用{n}、{n,}、{n,m}匹配时“{}”前不用加“\”
\w :匹配包括下划线的任何单词字符。\W :匹配任何非单词字符。等价于“[^A-Za-z0-9_]”。
\d :匹配一个数字字符。\D :匹配一个非数字字符。等价于 [^0-9]。 grep -P
\s :空白符。\S :非空白符
3.扩展元字符
+ 匹配+前面的字符或表达式至少1次(大于等于1次 {1,})
? 匹配?前面的字符或表达式0次或1次({0,1})
() 将()里的表达式作为一个整体 (oo)* (oo)?
| 或 (oo|aa) (oo|aa)?
案例
#查看以xxx为开头和查看以xxx为结尾的文件内容
[root@bogon ~]# cat 1.txt
162546
1357
32246
1623445
163657
66666
662457
734557
[root@bogon ~]# grep '^16' 1.txt #查看以16开头的内容
162546
1623445
163657
[root@bogon ~]# grep '57$' 1.txt #查看以57结尾的内容
1357
163657
662457
734557
[root@bogon ~]#
#匹配单个任意字符或者多个任意字符
[root@bogon ~]# cat 3.txt
good
gooooood
dooooofgoog
goooofogd
good
goodgod
gooooooooooooooooood
gooooooooood
[root@bogon ~]# grep 'g.d' 3.txt #过滤出左边为g,右边为d的,中间为任意字符的内容所在行
goodgod
[root@bogon ~]# grep 'g.*d' 3.txt #过滤出左边字符为9,右边为d。中间为任意长度的任意字符符合这一条件的内容行
good
gooooood
goooofogd
good
goodgod
gooooooooooooooooood
gooooooooood
[root@bogon ~]#
#匹配列表内容和匹配非列表中的内容
[0-9]+ 匹配所有数字字符至少1次(大于等于1次)
(025)? 匹配 025 字符串0次或1次(0到1次)
(abc|123){1,3} 匹配 abc 或 123 字符串1到3次















 746
746

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









