







项目实战 | 使用python分析Excel销售数据
本文目录:
零、00时光宝盒

life is impermanent,cherish the moment
人生无常,珍惜当下
once there was a gathering of three old friends
从前有三个老朋友经常聚会
they were all scholars leading busy lives,but they made it a point to meet once a year to make sure they would always stay in touch with one another。
他们都是学者,过着忙碌的生活,但他们每年都会见面一次,以确保他们始终保持联系。
this time the gathering felt different,they were all getting old and starting to feel their age
这次聚会感觉不太一样了,他们都在变老,开始感觉到自己的年龄
sensing this the first scholar remarked we are all here together this year enjoying each other's company
第一位学者察觉到这一点,说:我们今年都在这里,享受彼此的陪伴
but who can say if we will all be able to come back and be together again next year
但谁能说我们明年是否还能回来再聚一堂
the second scholar laughed
其他两个人听到都笑了
next year I think you may be looking too far ahead and assuming too much
明年?我觉得你可能想得太远了或者假设太多了
today i am alive,but who can say if tomorrow i will open my eyes to greet another day
今天我还活着,但谁能说明天我会睁开眼睛迎接新的一天
they turned to the third scholar who had been quiet
他们转向一直沉默的另一个老人
he looked up at them thoughtfully and said tomorrow
他抬头若有所思地看着他们说,明天?
my friends as i sit here with you,i do not know if each breath i draw will be my last,who can say for certain if one breath will be followed by another
我的朋友们,当我和你们坐在一起时,我不知道我的每一次呼吸是否会是我的最后一次呼吸,谁能确定一次呼吸之后是否会有另一次呼吸
this story is short but deeply meaningful
这个故事很短但意义深远
it points to how uncertain and impermanent life
它指出了生命是多么的不确定和无常
the first scholar thought about life in years
第一位老人是以年为单位去思考人生
like many of us,we usually count the number of years we have been alive,thinking about the time we have left
像我们很多人一样,我们通常会数自己活了多少年,计算着我们剩下多少时间
the truth is
事实是
we might not have many years or even one year left
我们可能没有多少年了,甚至一年的时间也没有了
life is not just about counting years or days
生活不仅仅是按年日来计算
it moves from one moment to the next
而是从某一个时刻移动到下一个时刻
from one breath to the next
从一口气到下一口气
we don't really know how many minutes or seconds we still have
我们真的不知道,我们还剩下多少分钟,或者几秒钟
so the people who are important to you
所以对你很重要的人
be thankful for them now,not tomorrow or next year
现在感谢他们,不要等明天或明年
tell them you appreciate them now for being in your life and be grateful for having a family too
告诉他们你现在感谢他们出现在你的生活中,也感谢有一个家庭
每个人活着都不容易,珍惜每次遇见,不只是口头,而是在你需要帮助时,我愿意伸出手并努力去办到。
逆境清醒
2024.4.7

一、提出问题
用groupby 统计xlsx文件
- 各销售代表的销售量
- 统计各类别商品的平均价并保留2位小数
- 统计各商品的销售额
- 统计各商品各地的销售情况
- 统计8月各代表的销售额
- 统计下半年各月的销售额
首先,导入Pandas库和要操作的Excel文件。
例如,为验证和测试,建立了一个名为"pandas数据分析.xlsx"的Excel文件,它包含了一些数据,结构如下:
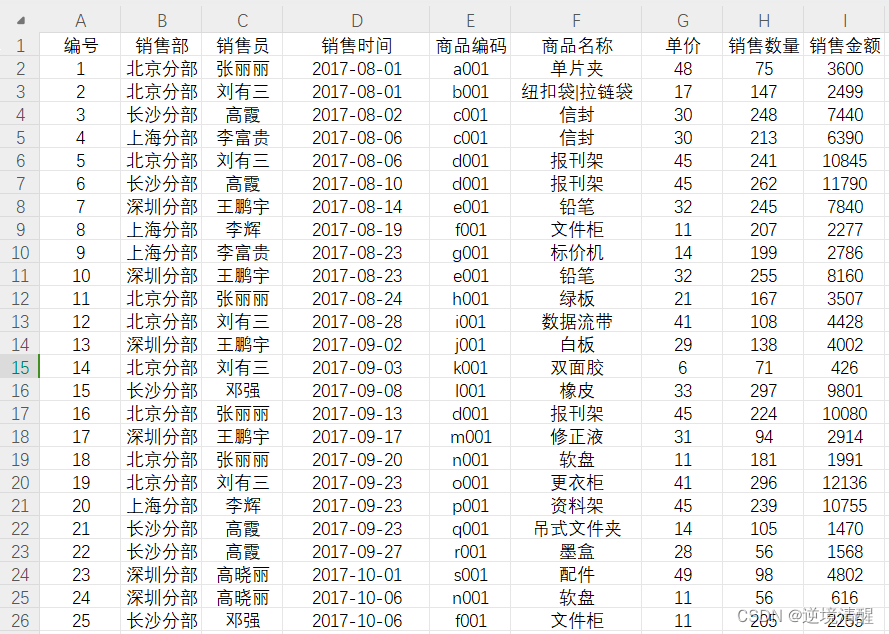
二、理解数据
代码测试环境:python 3、Jupyterlab v3.4.3
2.1、安装python读取excel文件的库
!pip install openpyxl --user

2.2、查看excel表的字段名和前几行记录
导入Pandas库和要操作的Excel文件。
import pandas as pd
FileNameStr='work/202404/pandas数据分析.xlsx'
#使用pandas的read_excel函数读取Ecxcel数据
salesDF=pd.read_excel(FileNameStr,sheet_name='Sheet2',dtype=str)
#打印前几行
salesDF.head()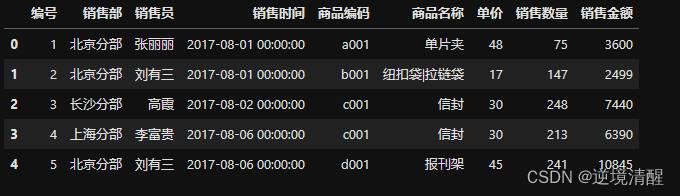
2.3、查看excel表结构
#查看表结构,有多少行和列
salesDF.shape(290, 9)
2.4、查看索引
#查看索引
print(salesDF.index)RangeIndex(start=0, stop=290, step=1)
2.5、查看每一列的列表头内容
#查看每一列的列表头内容
print(salesDF.columns)Index(['编号', '销售部', '销售员', '销售时间', '商品编码', '商品名称', '单价', '销售数量', '销售金额'], dtype='object')
2.6、查看每一列数据统计数目
#查看每一列数据统计数目
print(salesDF.count()) 编号 290
销售部 290
销售员 290
销售时间 290
商品编码 289
商品名称 290
单价 290
销售数量 290
销售金额 290
dtype: int64
2.7、看字段类型
#查看字段类型,每一列的类型
salesDF.dtypes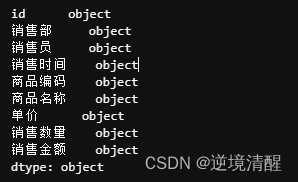
2.8、查看数据信息
#查看数据信息
print(salesDF.info())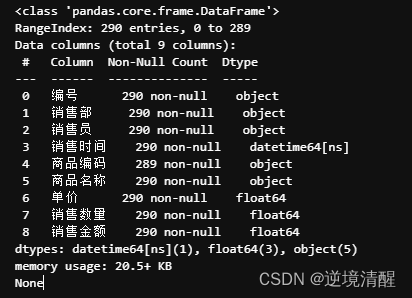
三、数据清洗
数据清洗的步骤为(7步):
选择子集->列名重命名->删除重复值->缺失值处理->一致化处理->数据排序->异常值处理
3.1、选择子集
(本例不需要选择子集)
3.2、列名重命名
(本例不需要列名重命名)
如果需要,可用以下方法:
数据中原来是“销售日期” ,现在需要将 “销售日期” 重命名为"销售时间"
colNameDict={'销售日期':'销售时间'}
salesDF.rename(columns=colNameDict,inplace=True)
salesDF.head()
3.3、删除重复值
(本例不需要删除重复值),
如果需要删除重复值,可用以下方法:
subsalesDF=salesDF.drop_duplicates(subset=['销售时间','商品名称'])
3.4、缺失值处理
(本例不存在缺失值),
获取的数据中很可能存在缺失值,如果遇到错误:例如float错误,那就是有缺失值,所以如果有缺失值需要处理掉。
python缺失值有3种:
1)Python内置的None值;
2)在pandas中,将缺失值表示为NA,表示不可用not available;
3)对于数值数据,pandas使用浮点值NaN(Not a Number)表示缺失数据。
所以,缺失值有3种:None,NA,NaN
可用以下方法:
#删除列(销售时间、商品名称)为空的行
salesDF=salesDF.dropna(subset=['销售时间','商品名称'],how='any')
3.5、一致化处理
1)销售金额由字符串转换为数值(浮点型)
#将销量、单价、销售金额由字符串转换为数值(浮点型)
salesDF['销售数量']=salesDF['销售数量'].astype('float')
salesDF['单价']=salesDF['单价'].astype('float')
salesDF['销售金额']=salesDF['销售金额'].astype('float')
print('转换后的数据类型:\n',salesDF.dtypes)
2)将日期字符串转换为日期数据类型
#将日期字符串转换为日期数据类型
#分割日期格式,获取销售日期
def splitSalestime(salestimeCol):
timeList=[]
for value in salestimeCol:
dataStr=value.split(' ')[0]
timeList.append(dataStr)
salestimeSer=pd.Series(timeList)
return salestimeSer
salestime=salesDF.loc[:,'销售时间']
salestimeSer=splitSalestime(salestime)
salestimeSer[0:5]
#将转换后的日期格式内容赋值原销售时间列
salesDF.loc[:,'销售时间']=salestimeSer
salesDF.head()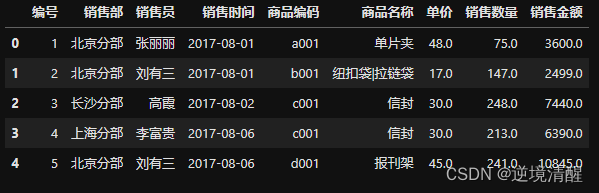
#虽然销售时间是日期形式,但是原表中的数据类型仍然是字符串,需要将其转换为日期格式。
print('销售时间列转换前格式:',salesDF.loc[:,'销售时间'].dtypes)
#errors='coerce' 如果原始数据不符合日期的格式,转换后的值为空值NaT
salesDF.loc[:,'销售时间']=pd.to_datetime(salesDF.loc[:,'销售时间'],format='%Y-%m-%d',errors='coerce')
print('销售时间列转换后格式:',salesDF.loc[:,'销售时间'].dtypes)
print('转换后的数据类型:\n',salesDF.dtypes)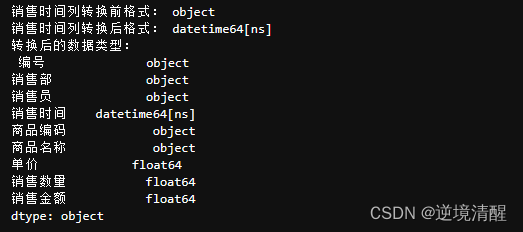
转换日期过程中不符合日期格式的数值会被转换为空值,这里删除列(销售时间,商品名称)中为空的行。
salesDF=salesDF.dropna(subset=['销售时间','商品名称'],how='any')
salesDF.shape
3.6、数据排序
排序时用到的几个参数:
by:按哪几列排序
ascending:True表示升序排列,
false表示降序排列
na_position:
在按指定列进行排序时,
如果此列数据中有空值(NaN),
na_position(参数默认)为 last ,空值默认排在最后面,
na_position='first',表示排序的时候,把空值放到前列
na_position参数只支持按单列排序时使用,在按多重索引或按多列排序时无效。
1)进行升序排列
#进行升序排列
print('进行升序排列排序后的数据集:')
df_index=salesDF.sort_index(ascending=True).head()
df_index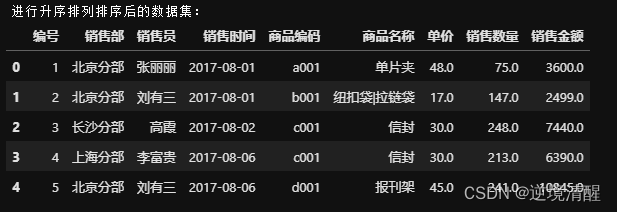
2)进行降序排列
#进行降序排列
print('进行降序排列排序后的数据集:')
df_index=salesDF.sort_index(ascending=False).head()
df_index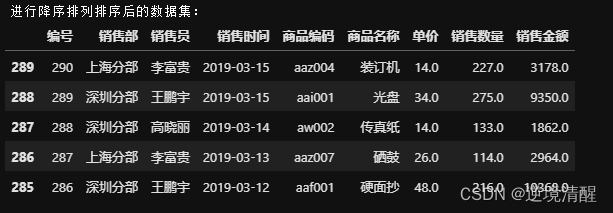
3)按指定列进行排序
#按指定列进行排序
print('按指定列进行排序,排序后的数据集:')
df_value=salesDF.sort_values(by='销售数量',ascending=True).head()
df_value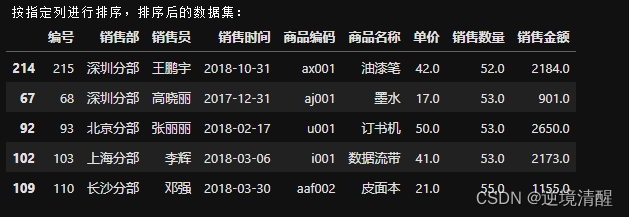
3.7、异常值处理
(本例不存在异常值),
如需要,可按实际情况查询后排除。例如
1)查看是否存在数值异常
#查看异常值,例如“销售数量”值不能小于0,可通过
salesDF.describe()
#查看异常值,例如“销售数量”值不能小于0,可通过
salesDF.describe()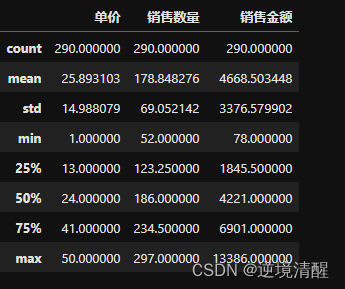
2)设定条件,由系统判定真假
#查看异常值
querySer=salesDF.loc[:,'销售数量']>0
querySer存在异常值:销售数量<0
#删除异常值:通过条件判断筛选出数据
#查询条件
querySer=salesDF.loc[:,'销售数量']>0
#应用查询条件
print('删除异常值前:',salesDF.shape)
salesDF=salesDF.loc[querySer,:]
print('删除异常值后:',salesDF.shape)
四、数据分析统计
4.1、各销售代表的销售量
#各销售代表的销售量
test = salesDF.groupby("销售员")[['销售数量','销售金额']].sum()
display(test)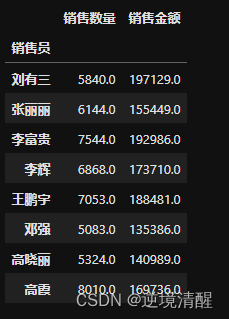
4.2、统计各类别商品的平均价并保留2位小数
test = salesDF.groupby("商品名称")[['销售金额']].agg(["mean"])
test['销售金额'] = test['销售金额'].round(2)
print("统计各类别商品的平均价最终获取到的数据是(保留2位小数):")
display(test)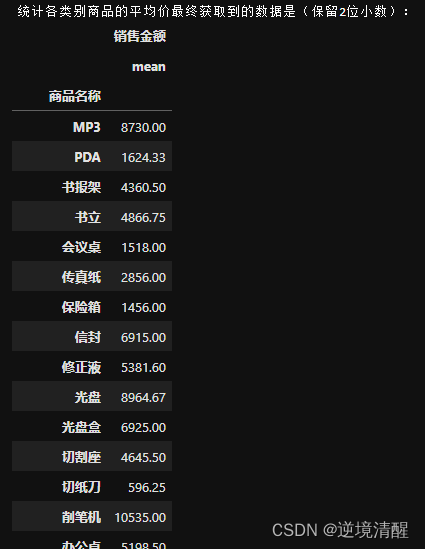
4.3、统计各商品的销售额
#统计各商品的销售额
test = salesDF.groupby(['商品编码','商品名称'])[['销售数量','销售金额']].sum()
display(test)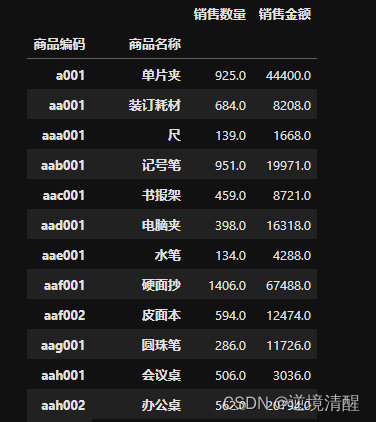
4.4、统计各商品各地的销售情况
#统计各商品各地的销售情况
print("各商品各地的销售情况:")
for g in salesDF.groupby(['商品编码','商品名称'])[['销售数量','销售金额']]:
print();
display(g);
print();
print("===================================================================================")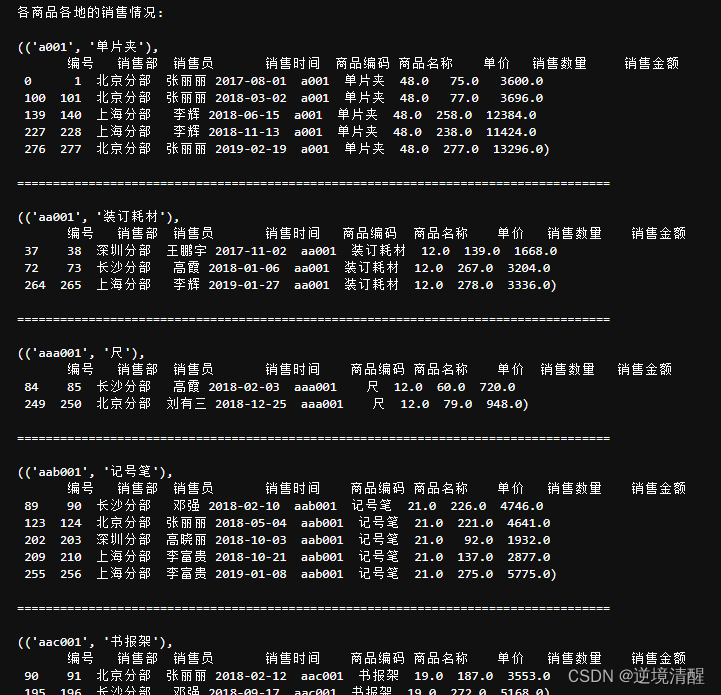
4.5、统计8月各代表的销售额
print("8月各代表的销售额:")
print("=======================")
# 将日期列转换为日期类型
salesDF['销售时间'] = pd.to_datetime(salesDF['销售时间'])
# 提取8月份的数据
august_data = salesDF[salesDF['销售时间'].dt.month == 8]
#display(august_data)
# 使用groupby函数按代表进行分组,并计算销售额总和
test=(salesDF[salesDF['销售时间'].dt.month == 8]).groupby('销售员')['销售金额'].sum()
# 打印结果
print(test)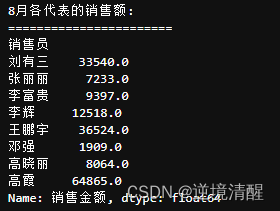
4.6、统计下半年各月的销售额
#统计下半年各月的销售额
print("下半年各月的销售额:")
print("=======================")
# 将日期列转换为日期类型
salesDF['销售时间'] = pd.to_datetime(salesDF['销售时间'])
# 筛选下半年的数据
data_half_year = salesDF[salesDF['销售时间'].dt.month >= 7]
#display(august_data)
# 按月份分组并计算销售额
sales_by_month = data_half_year.groupby(data_half_year['销售时间'].dt.month)['销售金额'].sum()
print(sales_by_month)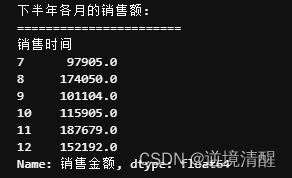
推荐阅读:
| 大数据的关键技术之——大数据采集 |
| [你找到牵手一辈子的人了吗?] 七夕情人节特辑 |
| 深度学习框架TensorFlow |
|
|
|
|
| 给照片换底色(python+opencv) | 猫十二分类 | 基于大模型的虚拟数字人__虚拟主播实例 |
|
|
|
|
| 计算机视觉__基本图像操作(显示、读取、保存) | 直方图(颜色直方图、灰度直方图) | 直方图均衡化(调节图像亮度、对比度) |
|
|
|
|



























|
|
|
|
| 2024年1月多家权威机构____编程语言排行榜__薪酬状况 | ||
|
|
|
|
| 【CSDN云IDE】个人使用体验和建议(含超详细操作教程)(python、webGL方向) | ||













|
|
|
|





















 361
361

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











