







目录
Sed 默认每次只处理一行数据,除非使用 H,G 或者 N 等命令创建多行模式,每行之间用换行
符分开。
本章将解释适用于多行模式的
sed
命令。
提示:在处理多行模式是,请务必牢记
^
只匹配该模式的开头,即最开始一行的开头,且
$
只
匹配该模式的结尾,即最后一行的结尾。
46.读取下一行数据并附加到模式空间(命令 N)
就像大写的命令
H
和
G
一样,只会追加内容而不是替换内容,命令
N
从输入文件中读取下
一行并追加到模式空间,而不是替换模式空间。
前面提到过,小写命令
n
打印当前模式空间的内容,并清空模式空间,从输入文件中读取下
一行到模式空间,然后继续执行后面的命令。
大写命令
N
,不会打印模式空间内容,也不会清除模式空间内容,而是在当前模式空间内容
后加上换行符
\n,
并且从输入文件中读取下一行数据,追加到模式空间中,然后继续执行后
面的命令。
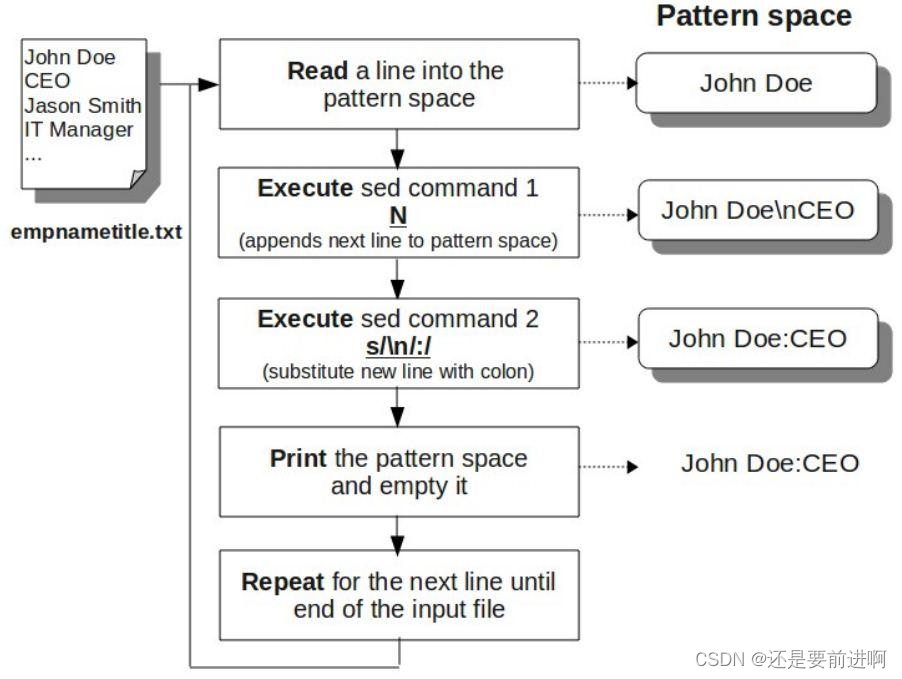
以分号分隔,打印雇员名称和职位
:
$ sed -e '{N;s/\n/:/}' empnametitle.txt
John Doe:CEO
Jason Smith:IT Manager
Raj Reddy:Sysadmin
Anand Ram:Developer
Jane Miller:Sales Manager
这个例子中
:
N
追加换行符
\n
到当前模式空间
(
雇员名称
)
的最后,然后从输入文件读取下一行数
据,追加进来。因此,当前模式空间内容变为
”
雇员名称
\n
雇员职位
”
。
s/\n/:/
把换行符
\n
替换为分号,把分号作为雇员名称和雇员职位的分隔符
流程如下图所示
:
下面的例子将演示在打印 employee.txt 文件内容的同时,以文本方式显示每行的行号:
$ sed -e '=' employee.txt|sed '{N;s/\n/ /}'
1 101,Johnny Doe,CEO
2 102,Jason Smith,IT Manager
3 103,Raj Reddy,Sysadmin
4 104,Anand Ram,Developer
5 105,Jane Miller,Sales Manager
和之前的例子一样,命令
=
先打印行号,然后但印原始的行的内容。
这个例子中,命令
N
在当前模式空间后面加上
\n(
当前模式空间内容为行号
),
然后读取下一行,
并追究到模式空间中。因此,模式空间内容变为
”
行号
\n
原始内容
”
。然后用
s/\n/ /
把换行符
\n
替换成空格。
47.打印多行模式中的第一行(命令 P)
目前为止,我们已经学会了三个大写的命令
(H,N,G)
,每个命令都是追加内容而不是替换内容。
现在我们来看看大写的
D
和
P
,虽然他们的功能和小写的
d
和
p
非常相似,但他们在多行模
式中有特殊的功能。
之前说到,小写的命令
p
打印模式空间的内容。大写的
P
也打印模式空间内容,直到它遇到
换行符
\n
。
下面的例子将打印所有管理者的名称
:
$ sed -n -e 'N' -e '/Manager/P' empnametitle.txt
Jason Smith
Jane Miller
48. 删除多行模式中的第一行(命令 D)
之前提到,小写命令
d
会删除模式空间内容,然后读取下一条记录到模式空间,并忽略后面
的命令,从头开始下一次循环。
大写命令
D
,既不会读取下一条记录,也不会完全清空模式空间
(
除非模式空间内只有一行
)
。
它只会:
z
删除模式空间的部分内容,直到遇到换行符
\n
z
忽略后续命令,在当前模式空间中从头开始执行命令
假设有下面文件,没个雇员的职位都用
@
包含起来作为注释。需要注意的是,有些注释是跨
行的。如
@Information Technology officer@
就跨了两行。请先建立下面示例文件
:
$ vi empnametitle-with-commnet.txt
John Doe
CEO @Chief Executive Officer@
Jason Smith
IT Manager @Infromation Technology
Officer@
Raj Reddy
Sysadmin @System Administrator@
Anand Ram
Developer @Senior
Programmer@
Jane Miller
Sales Manager @Sales
Manager@
现在我们的目标是,去掉文件里的注释
:
$ sed -e '/@/{N;/@.*@/{s/@.*@//;P;D}}' empnametitle-with-commnet.txt
John Doe
CEO
Jason Smith
IT Manager
Raj Reddy
Sysadmin
Anand Ram
Developer
Jane Miller
Sales Manager
也可把上述命令写到
sed
脚本中然后执行
:
$ vi D-upper.sed
#!/bin/sed -f
/@/{
N
/@.*@/{s/@.*@//;P;D}
}
$ chmod u+x D-upper.sed
$ ./D-upper.sed empnametitle-with-commnet.txt
John Doe
CEO
Jason Smith
IT Manager
Raj Reddy
Sysadmin
Anand Ram
Developer
Jane Miller
Sales Manager
这个例子中
:
/@/{
这是外传循环。
Sed
搜索包含
@
符号的任意行,如果找到,就执行后面的命
令;如果没有找到,则读取下一行。为了便于说明,以第
4
行,即
”@Information
Technology”(
这条注释跨了两行
)
为例,它包含一个
@
符合,所以后面的命令会被执
行。
N
从输入文件读取下一行,并追加到模式空间,以上面提到的那行数据为例,这
里
N
会读取第
5
行,即
”Officer@”
并追加到模式空间,因此模式空间内容变
为
”@Informatioin Technology\nOfficer@”
。
/@.*@/
在模式空间中搜索匹配
/@.*@/
的模式
,
即以
@
开头和结尾的任何内容。当
前模式空间的内容匹配这个模式,因此将继续执行后面的命令。
s/@.*@//;P;D
这个替换命令把整个
@Information Technology\nOfficer@”
替换为空
(
相当于删除
)
。
P
打印模式空间中的第一行,然后
D
删除模式空间中的第一行,然
后从头开始执行命令
(
即不读取下一条记录,又返回到
/@/
处执行命令
)
49.循环和分支(命令 b 和 :label 标签)
使用标签和分支命令
b
,可以改变
sed
的执行流程:
:label
定义一个标签
b lable
执行该标签后面的命令。
Sed
会跳转到该标签,然后执行后面的命令。
注意:命令
b
后面可以不跟任何标签,这种情况下,它会直接跳到
sed
脚本的结尾
下面例子将把
empnametitle.txt
文件中的雇员名称和职位合并到一行内,字段之间以分号:
分隔,并且在管理者的名称前面加上一个星号
*
。
$ cat label.sed
#!/bin/sed -nf
h;n;H;x
s/\n/:/
/Manager/!b end
s/^/*/
:end
p
这个脚本中,鉴于之前的例子,你已经知道
h;n;H;x
和
s/\n/:/
的作用了。下面是关于分支的
操作:
z
/Manager/!b end
如果行内不包含关键字
”Manager”,
则 跳转到
’end’
标签,请注意,
你可以任意设置你想要的标签名称。因此,只有匹配
Manager
的雇员名称签名,
才会执行
s/^/*/(
在行首加上星号
*)
。
z
:end
即是标签
给这个脚本加上可执行权限,然后执行:
$ chmod u+x label.sed
$ ./label.sed empnametitle.txt
John Doe:CEO
*Jason Smith:IT Manager
Raj Reddy:Sysadmin
Anand Ram:Developer
*Jane Miller:Sales Manager
个人觉得脚本里面的
h;n;H;x
可以用一个
N
替代,这样就不用使用保持空间了。
如果不使用标签,还可以:
sed 'N;s/\n/:/;/Manager/s/^/\.*/' empnametitle.txt
50.使用命令 t 进行循环
命令
t
的作用是,如果前面的命令执行成功,那么就跳转到
t
指定的标签处,继续往下执行
后续命令。否则,仍然继续正常的执行流程。
下面例子将把
empnametitle.txt
文件中的雇员名称和职位合并到一行内,字段之间以分号:
分隔,并且在管理者的名称前面加上三个星号
*
。
提示:我们只需把前面例子中的替换命令改为 s/^/***/即可带到该目的,下面这个例子仅仅
是为了解释命令 t 是如何运行的。
$ vi lable-t.sed
#!/bin/sed -nf
h;n;H;x
s/\n/:/
: repeat
/Manager/s/^/*/
/\*\*\*/! t repeat
p
$ chmod u+x lable-t.sed
$ ./lable-t.sed empnametitle.txt
John Doe:CEO
***Jason Smith:IT Manager
Raj Reddy:Sysadmin
Anand Ram:Developer
***Jane Miller:Sales Manager
这个例子中
:
下面的代码执行循环
:repeat
/Manager/s/^/*/
/\*\*\*/! t repeat
/Manager/s/^/*/
如果匹配到
Manager,
在行首加上星号
*
/\*\*\*/!t repeat
如果没有匹配到三个连续的星号
*(
用
/\*\*\*/!
来表示
)
,并且前面
一行的替换命令成功执行了,则跳转到名为
repeat
的标签处
(
即
t repeat)
:repeat
标签
资料来源于《SedandAwk101Hacks》,大家有兴趣可以买一本,也可以关注我,我更新完它。
曾经,我花费大半月将它们跑完,现在啥都忘了,还是要常用。
只为学习交流,不为获利,侵权联系立删。















 296
296

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









