






Q1论文试图解决什么问题?
基于深度学习的无监督显著性目标检测方法主要依赖于从传统手工方法或预训练网络中生成的噪声显著性伪标签。为了应该噪声标签问题,一类方法只关注具有可靠标签的简单样本,而忽略了困难样本中的有价值知识。本文从简单样本和困难样本中挖掘丰富而准确的显著性知识。
Q2这是否是一个新的问题?
不是一个新的问题。
大多数基于深度学习的方法基于传统的SOD方法提取的显著线索。这些手工设计的特征相关的线索被用作伪标签,在一定的约束条件下训练深度网络,例如交叉熵损失。然而,传统的显著性线索会偏离目标物体,尤其在复杂场景中。此外,传统的约束条件,在强监督SOD方法上效果较好,但在拟合无监督方法的噪声标签时是次要的。
最近Zhou等人通过无监督预训练网络提取的显著性特征来解决第一个问题(即复杂场景中传统的显著性线索会偏离目标物体)。在训练过程中,其专注于从简单样本中学习可靠的显著性知识,而忽略了难例中的潜在知识。主要原因是难例可能被错误标记,破坏了在早期训练阶段学习到的易损的显著知识。
Q3这篇文章要验证一个什么科学假设?
为了利用硬样本(难学的样本,本文中将显著性得分接近0.5的像素定义为难例),本文作者认为所有样本应该以有意义的顺序(即从高可靠性到低可靠性)使用,这对于从噪声标签中挖掘准确的知识是至关重要的。通过这样的训练策略,网络可以从困难样本中挖掘出有价值的知识,而不会破坏从容易样本中学习到的知识。
神经网络可以从噪声标签中定位显著性区域,但是仍然很难找到目标物体的精确边缘。一般而言,显著性边界周围的外观具有与显著图相似的纹理。因此匹配不同图之间的纹理可以作为产生合理显著性边界的指导。
Q4有哪些相关研究?如何归类?谁是这一课题在领域内值得关注的研究员?
1. 有监督的显著性目标检测--需要大量的人工标注进行训练,收集代价高昂。
Ronneberger等提出了一种U型结构,将较小的特征级联到较大的特征上。(U-net)为了解决标注负担,张等人重新标记了DUTS-TR数据集,并利用边缘检测模型进行边界定位。(Weakly-supervised salient object detection via scribble annotations.)Yu等人提出了一种局部一致性损失来寻找基于自己注释的精确边界。(Structure-consistent weakly supervised salient object detection with local saliency coherence.)
多模态SOD任务旨在使用其他模态的数据提高SOD的性能,例如深度图,热图和光流。这些方法大多采用双流编码器-解码器结构来句和多模态数据中的多层次信息。为了降低标注成本,Zhao等人提出了一个带有乱码标注的视频SOD数据集来表示显著性目标的位置。(Weakly supervised video salient object detection.)
2. 无监督的显著性检测
传统的方法通过对手工特征的相关性建模,从图像中提取显著性线索。受中心先验化的启发,Jiang等人将边界超像素和非边界超像素之间的距离作为显著性分数。Yan等人使用树结构的图模型来计算基于多个过分割图的显著性结果。但由于手工特征中的全局信息代表性不足,无法准确定位显著目标。(Promoting saliency from depth: Deep unsupervised rgb-d saliency detection,Hierarchical saliency detection.)
现存的基于DL的USOD方法可以根据用于从图像中提取显著性线索的方法分为两种。其一专注于细化由几种传统SOD方法提取的粗显著线索。例如,Zhang等通过结合图像内和图像间融合流对这些显著性线索进行加权。Zhang等设计了一个噪声建模模块来处理这些显著性线索。Nguyen等使用显著性线索作为标签去训练多个神经网络。Ji等人细化由传统SOD方法得到的显著图,以产生更为准确的显著性预测。(Supervision by fusion: Towards unsupervised learning of deep salient object detector.,Deep unsupervised saliency detection: A multiple noisy labeling perspective.,Deepusps: Deep robust unsupervised saliency prediction with selfsupervision.,Promoting saliency from depth: Deep unsupervised rgb-d saliency detection.)。其二是为了防止传统方法带来的定位误差。例如Zhou等提出了一个新的框架将预训练网络的激活图转换为高质量的伪标签。(Activation to saliency: Forming high-quality labels for unsupervised salient object detection.)
Q5论文中提到的解决方案之关键是什么?
通过两个新的策略基于一个深层网路生成的噪声激活图来挖掘准确的显著性知识。
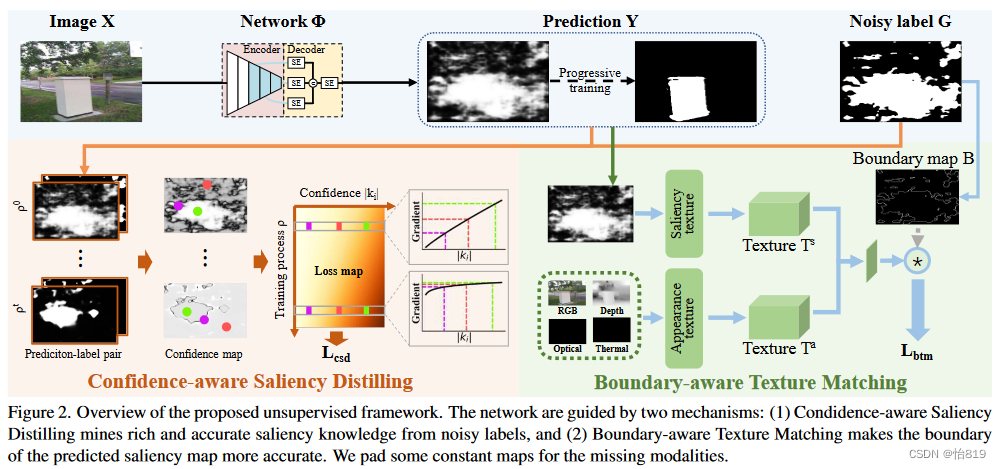
激活图生成(X-->Y):通过预训练好的ResNet-50提取特征,将每层特征经过SE模块后,在通道层面进行拼接后再通过一个SE模块得到融合的多编码器特征H,设置H与其空间均值之差来保证(1)当使用固定阈值时,噪声标签自适应于输入图像;(2)正负样本共存。在通道维度上对该差进行相加,生成单通道激活图后,利用Sigmoid函数产生显著性分数,最后通过inv函数将角点像素较多的区域识别为背景。
将该激活图作为显著性线索的原因:(1)传统方法需要额外的计算量;(2)网络可以专注于挖掘显著性知识而不是拟合传统方法的归纳偏差。
策略一:置信度感知的显著性蒸馏(Confidence-aware Saliency Distilling,CSD)
根据样本的置信度对带有噪声标签的样本进行评分。并使用以训练过程为条件的自适应损失,引导网络从简单样本逐步学习到更复杂的显著性知识。
容易的样本可能包含可靠的知识,因此可以辅助本文方法去学习可靠的显著性知识。相反,难例中的显著性知识隐藏在噪声中,在网络训练的早期阶段可能会破坏脆弱的显著性模式。本文引入了一个从0到的线性递增因子来动态调整样本的梯度。

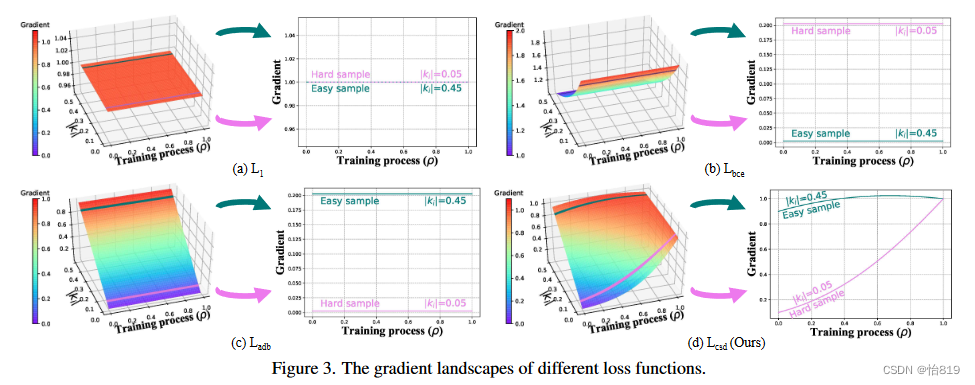
如图3所示,对比了四种梯度函数,除本文提出的方法外,其他方法在训练过程中保持一致,但本文的损失函数从开始为难例分配低梯度,以便从样本中学习可靠的显著性知识,随着训练的进行,难例的梯度越来越大,以挖掘更有价值的显著性知识。
策略二:边界感知的纹理匹配(Boundary-aware Texture Marching,BTM)
通过匹配预测边界周围的纹理来细化噪声标签的显著性边界。在训练过程中,预测的显著性边界在整幅图像的外观空间中向四周边缘移动。
与LBP特征类似,分别从显著性预测和外观中提取纹理向量。对于显著性预测,第i个像素的纹理向量由与其领域kxk个像素的绝对差值计算得到。
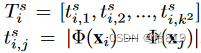
对于外观信息,可能为RGB图像、光流、深度图或热图,为了从多模态数据中提取更具区分性的特征,将纹理向量定义为:
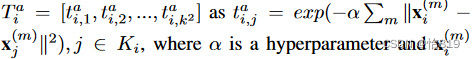
两个像素间的微小差异会产生Ts之间的一个小元素,但会产生Ta之间的一个大元素。因此上述两项的乘积被定义为显著性边界的匹配惩罚,与相似性相反。
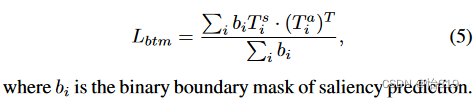
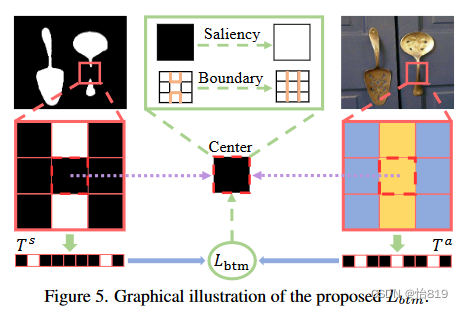
如图5所示,对于预测的边界像素,作者找到了一些在显著性评分上有显著差异的附近像素。一般来说,边界和这些像素之间的外观也是不同的,因为它们分别位于显著目标和背景中。如果不是这种情况,期望这个边界像素的显著性分数接近那些附近的像素,这样边界就会向相反的方向偏移。经过一个迭代训练过程,本文方法方法可以将预测的显著性边界与图像边缘对齐。
Q6论文中的实验是如何设计的?
除了上述两种策略的相关损失,还有一个多尺度一致性损失。由于显著目标在多尺度输入上是一致的,因此作者将输入图像调整到一个参考尺度,使其产生一致的预测。
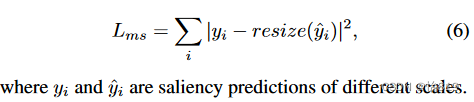
训练通用的检测器:基于显著性预测Y生成的伪标签,在IOU损失的情况下训练额外的显著性检测器。对于RGB,使用与前面方法相同的检测器(A2S即Activation to saliency: Forming high-quality labels for unsupervised salient object detection.)。对于多模态任务,使用MIDD作为检测器。在使用额外检测器训练时仅使用特定任务的数据和相应的伪标签。
数据增强仅使用了水平翻转。使用SGD训练了20个epochs,额外10个epochs用于训练额外的检测器。
探究了不同任务中所提方法(一共有3个,分别为无需额外检测器和后处理的显著性结果、整个方法以及多模态数据训练但只使用MSRS-B和DUTS-TR的伪标签)的定性和定量结果。除此之外,进行了消融实验,探究了标签质量、初始显著线索、损失函数、有监督或无监督预训练的影响。
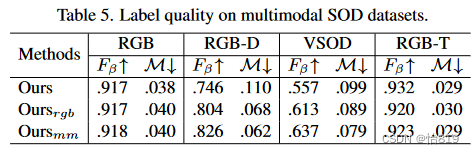
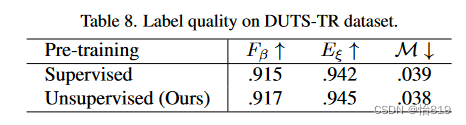
标签质量:(1)收集四个任务的所有RGB图像训练rgb;(2)仅针对特定任务的数据;(3)在所有数据集上的一般化结果mm。由于在无真实数据的情况下训练的,拟合混合数据集可能在某些子集上造成轻微的性能下降。多模态可以显著提高生成的伪标签的质量。
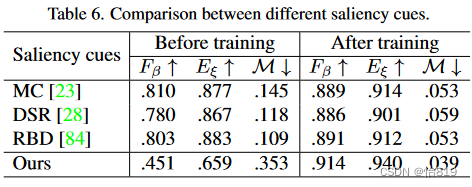
初始显著线索:本文基于的是预训练网络生成的激活图,而其他方法是基于传统显著线索。激活图在训练过程中的动态性,使得网络对学习到的显著性知识进行增量强化。相反,使用传统方法,网络在整个训练过程中从固定标签中学习,从而拟合传统方法中的有偏知识。此外,传统方法会引入额外的计算负载,而预训练网络对于所有基于DL的USOD方法来说都是必不可少的。
损失函数:分别探究三种损失的相互作用(消融实验A)、Lcsd的作用(消融实验B)和Lbtm的作用(消融实验C)。
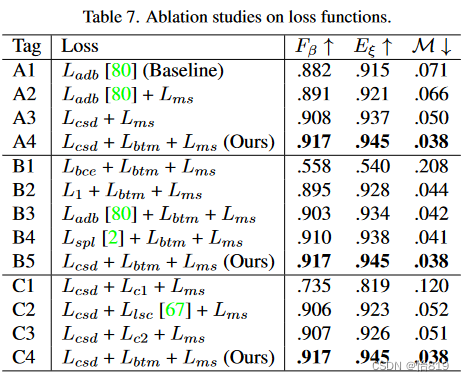
消融实验A:这三种损失可以辅助网络从不同角度挖掘更详细的显著性知识。更重要的是,这些损失是相互补充的,因此它们的组合可以协作为SOD数据集生成高质量的伪标签。
消融实验B:Lcsd损失可以提供精确的显著性定位信息,从而在所有竞争者中获得最好的性能。具体来说,Lbce和L1未能从噪声显著性线索中挖掘详细可靠的显著性知识。Ladb通过关注易样本提高了学习到的显著性知识的鲁棒性,从而超越了L1损失。Lspl也采用了动态调度,但其二进制权重过滤掉了困难样本中潜在的显著性知识。
消融实验C:将Lbtm与Llsc和两个变体进行比较:( 1 )使用L1距离表示外观空间中的纹理特征,记为Lc1;( 2 )去除Lbtm中的边界掩膜,记为Lc2。总体而言,Lbtm优于其他变体。具体来说,Lc1中的L1距离会导致纹理特征不够明显,从而导致显著性边界模糊。Llsc更多地关注相邻像素,使得边界更容易受到有限区域的影响,而不是更大的斑块。此外,利用Lc2,物体或背景中的边缘可能会破坏学习到的显著性知识。
有监督or无监督:对于ImageNet数据集,图像的类别标签通常表示最显著对象的类别。这意味着有监督编码器从这些人工标签中获得额外的显著性知识。因此,对于完全无监督的SOD,本文使用无监督的MoCo - v2来初始化编码器。本文方法在使用监督编码器时的性能是相当的。
Q7用于定量评估的数据集是什么?代码有没有开源?
对于RGB任务:使用MSRA-B和DUTS的训练子集。ECSSD,PASCAL-S,HKU-IS,DUTS-TE,DUT-O和MSRA-B的测试子集用于评估。
对于RGB-D任务:从NLPR和NJUD中选择2185个样本作为训练集,其测试子集和RGBD135、SIP用于评估。
对于RGB-T任务:VT5000中的2500张图像用于训练,剩下的2500张图片以及VT1000、VT821用于测试评估。
对于视频任务:选择DAVIS和DAVSOD的训练划分来训练。在DAVSOD中随机选取每个视频的5帧来避免过拟合。DAVIS、DAVSOD和SegV2的测试划分用于评估。
使用平均Fb( ⬆)、均方误差( ⬆)和E测度( ⬇)来评估。代码开源
Q8论文中的实验及结果有没有很好地支持需要验证的科学假设?
在RGB SOD上结果较好,在多模态数据上与全监督方法结果相当。在一定程度上验证了科学假设,对于难例(例如某目标的遮挡或者较弱区域)能够较好地预测。
Q9这篇论文到底有什么贡献?
提出了CSD和BTM两种策略来从噪声标签中得到丰富准确的显著图,并可以在RGB,RGB-D,RGB-T和视频SOD基准上进行USOD。
Q10下一步呢?有什么工作可以继续深入?
暂未提及,但是从结果来看,和GT图像在某些不可见目标细节方面还有待加强。可以借鉴该思路在将显著性引入其他任务时进行参考。















 2452
2452











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









