






一. 生成数组
1. 快速生成数组
import numpy as np
a = np.array([1,2,3,4,5])
# [1 2 3 4 5]
b = np.array(range(6,11,1))
# [ 6 7 8 9 10]
c = np.arange(11,16,1)
# [11 12 13 14 15]
d = np.linspace(16,20,5)
#[16. 17. 18. 19. 20.]其中:
np.array(range(......)) ←→ np.arange(......)
2. 类型
(一). 数组的类型
import numpy as np
a = np.array([1,2,3,4,5])
# [1 2 3 4 5]
print(type(a))
# <class 'numpy.ndarray'>数组的类型为:numpy.ndarray
(二). 数据的类型
import numpy as np
a = np.array([1,2,3,4,5])
# [1 2 3 4 5]
print(a.dtype)
# int32(1). 强制转换数据类型
b = np.array([1,0,1],dtype = float)
# [1. 0. 1.]
b = np.array([1,0,1],dtype = bool)
# [True False True](2). 强制修改数据类型
c = b.astype("float")
# [1. 0. 1.]
c = b.astype("bool")
# [True False True]3. 生成小数: random.random()
import numpy as np
import random
a = np.array([random.random() for i in range(5)])
# [0.30625875 0.41934503 0.36532562 0.45451505 0.90432966]4. 保留小数: round()
round(数组, 保留位数)
import numpy as np
import random
a = np.round(np.array([0.30625875, 0.41934503, 0.36532562, 0.45451505, 0.90432966]),2)
# [0.31 0.42 0.37 0.45 0.9 ]5. 多维数组
import numpy as np
a = np.array([[1,2,3],[4,5,6]])
# [[1 2 3]
# [4 5 6]]二. 数组的形状
1. 查看形状
数组名.shape
数组名.ndim
import numpy as np
a = np.array([1,2,3])
# (3,)
b = np.array([[1,2,3],[4,5,6]])
# (2, 3)
c = np.array([[[1,2,3],[4,5,6]],[[7,8,9],[10,11,12]]])
# (2, 2, 3)
# c是一个三维数组,该数组有2块,每块有2层,每层有3个2. 修改形状
数组名.reshape((行数, 列数))
其中:
①行数×列数 = 原数组的元素数
②-1代表自动分行(或自动分列)
import numpy as np
a = np.arange(1,13,1)
# [ 1 2 3 4 5 6 7 8 9 10 11 12]
b = a.reshape((3,4))
#[[ 1 2 3 4]
# [ 5 6 7 8]
# [ 9 10 11 12]]import numpy as np
a = np.arange(24).reshape((2,3,4))
# [[[ 0, 1, 2, 3],
# [ 4, 5, 6, 7],
# [ 8, 9, 10, 11]],
# [[12, 13, 14, 15],
# [16, 17, 18, 19],
# [20, 21, 22, 23]]]
# a是一个三维数组,该数组有2块,每块有3层,每层有4个import numpy as np
b = np.arange(5).reshape((5,))
# [0, 1, 2, 3, 4]
c = np.arange(5).reshape((5,1))
# [[0],
# [1],
# [2],
# [3],
# [4]]
d = np.arange(5).reshape((1,5))
# [[0, 1, 2, 3, 4]]将任何二维数组转化为一维:
① 数组名.flatten()
② 数组名.ravel()
三. 数组的计算
1. 加法
(一). 数组与常数
数组中的每个元素都与常数相加
import numpy as np
a = np.array([[1,2,3],
[4,5,6],
[7,8,9]])
a+2
# [[ 3, 4, 5],
# [ 6, 7, 8],
# [ 9, 10, 11]](二). 数组与数组
两个数组的对应元素分别相加(维度相同)
import numpy as np
a = np.array([[1,2,3],
[4,5,6],
[7,8,9]])
b = np.array([[9,8,7],[6,5,4],[3,2,1]])
a+b
# [[10, 10, 10],
# [10, 10, 10],
# [10, 10, 10]]2. 减法
(一). 数组与常数
数组中的每个元素都与常数相减
(二). 数组与数组
两个数组的对应元素分别相减(维度相同)
3. 乘法
(一). 数组与常数
数组中的每个元素都与常数相乘
(二). 数组与数组
两个数组的对应元素分别相乘(维度相同)
4. 除法
(一). 数组与常数
数组中的每个元素都与常数相除
(二). 数组与数组
两个数组的对应元素分别相除(维度相同)
5. 补充
(一). 行数不同,列数相同的两个数组
若行数不同,那么这个行只能是一行。
两数组之间可进行:
①相加:每行元素依次与这一行元素对应相加
②相减:每行元素依次与这一行元素对应相减
③相乘:每行元素依次与这一行元素对应相乘
④相除:每行元素依次与这一行元素对应相除
(二). 列数不同,行数相同的两个数组
若列数不同,那么这个列数只能是一列。
(三). 其他
①形状为(3,3,3)的数组,不可与形状为(3,2)的数组计算
②形状为(3,3,2)的数组,可以与形状为(3,2)的数组计算
四. 数组的轴
在numpy中,轴可以理解为方向,用数字0、1、2、3、......表示
对于一维数组,只有0轴;
对于二维数组,有0轴与1轴;
对于三维数组,有0轴、1轴、2轴;
1. 一维数组的轴
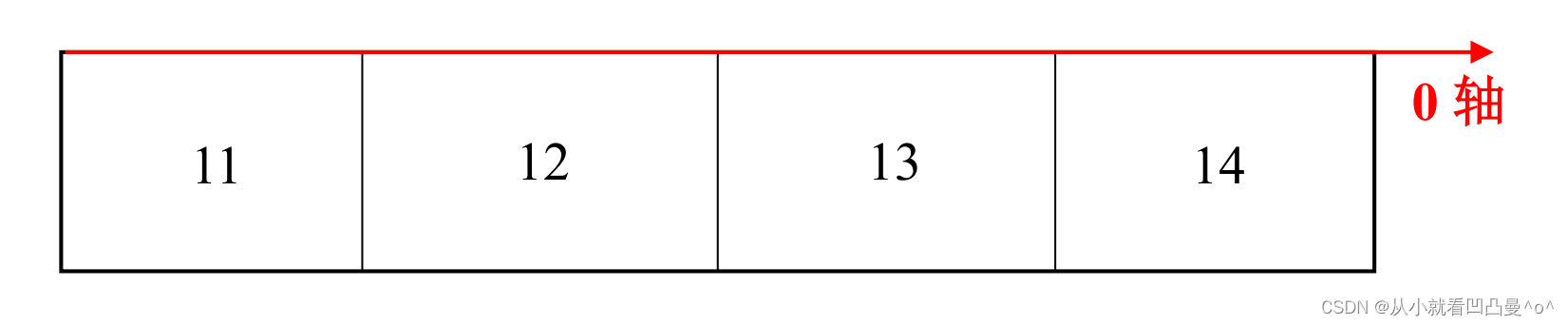
2. 二维数组的轴
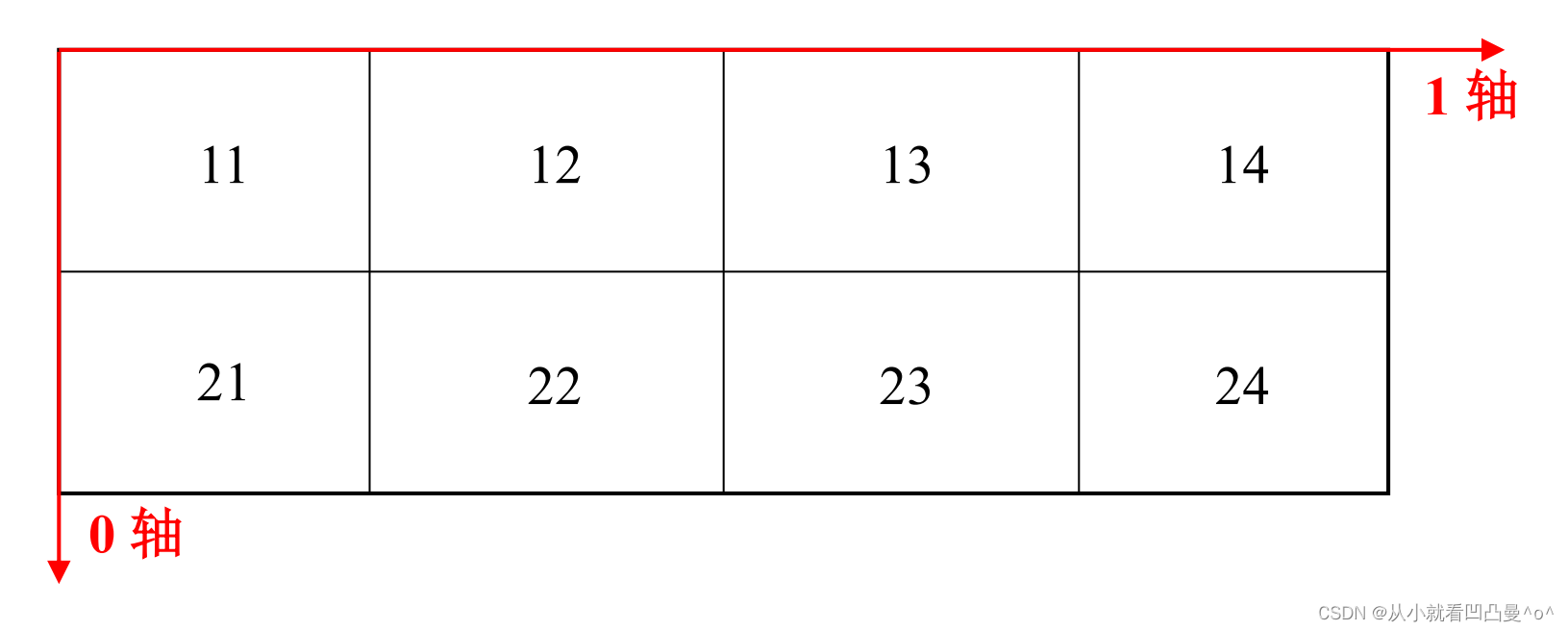
3. 三维数组的轴
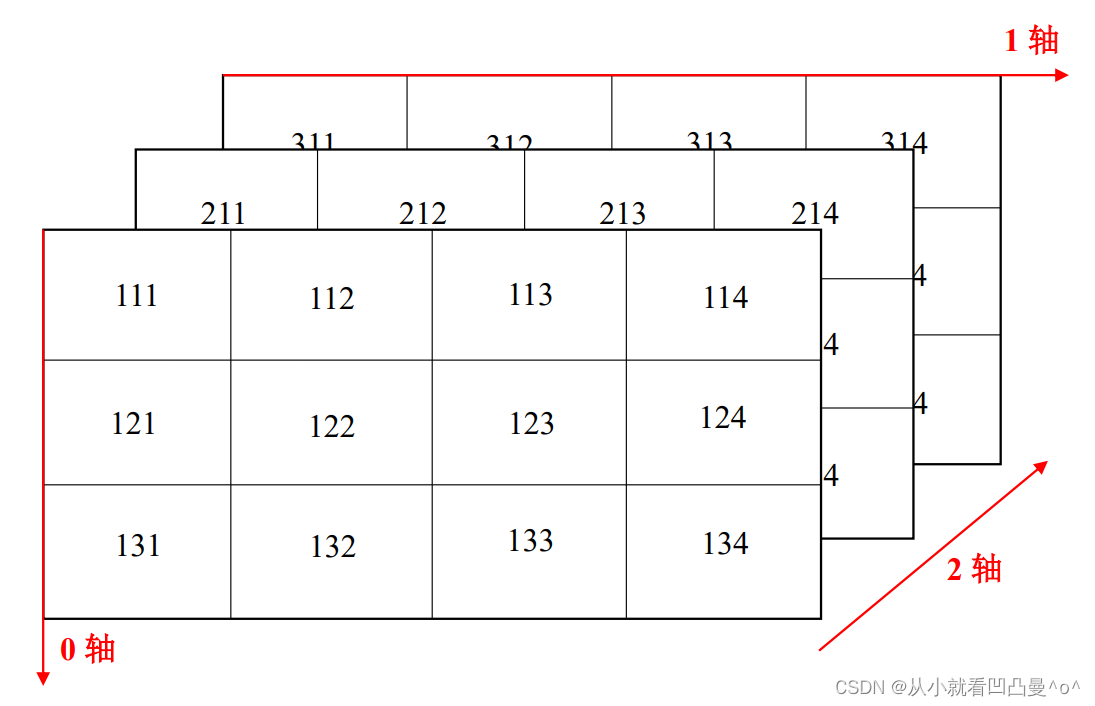
五. 读取数据
csv文件时逗号分隔值文件(所有的值都是通过逗号分隔的)
np.loadtxt(文件路径/文件名,
dtype="float", →→转化数据类型为float
"int" →→转化数据类型为float
None
delimiter=None, →→用什么字符串进行分隔,默认时空格
skiprows=0, →→跳过前0行
usecols=None, →→读取指定索引值的列
unpack=False) →→转置
True) →→不转置
np.loadtxt(./video_data.csv, dtype="int")六. 转置
转置时一种变换,就是在对角线方向将行数据转化为列数据,将列数据转化为行数据
① 数组名.transpose()
② 数组名.T
③ 数组名.swapaxes(1,0) →→将0轴与1轴进行交换
七. 索引与切片
1. 切片
数组名[ 起始索引 : 终止索 : 引步长 ]
其中:
起始索引:开始位置(包含),默认为0
终止索引:结束位置(不包含),默认为0
步长:默认为1
2. 一维数组
(一). 切取某一值
数组名[ 索引值 ]
import numpy as np
a = np.array([1,2,3,4,5])
a[3]
# 4(二). 切取某值以后的全部
数组名[ 索引值 : 全部 :1 ]
↕
数组名[ 索引值 : 全部 ]
↕
数组名[ 索引值 : ]
import numpy as np
a = np.array([1,2,3,4,5])
a[1:len(a):1] # [2, 3, 4, 5]
a[1:len(a)] # [2, 3, 4, 5]
a[1:] # [2, 3, 4, 5](三). 切取某值到某值之间的全部
数组名[ 索引值1 : 索引值2 :1 ]
↕
数组名[ 索引值1 : 索引值2 ]
import numpy as np
a = np.array([1,2,3,4,5])
a[1:3:1] # [2, 3, 4]
a[1:3] # [2, 3, 4](四). 每间隔n进行切取
数组名[ 0 : 全部 :n ]
↕
数组名[ : : n ]
3. 二维数组
(一). 行
,: 代表行,写在后面
(1). 切取一行
数组名[ 索引值 ]
↕
数组名[ 索引值 ,: ]
(2). 切取某行以后的全部行
数组名[ 索引值 : ]
↕
数组名[ 索引值 : ,: ]
(3). 间隔n行进行切取
数组名[ : : n ]
↕
数组名[ : : n ,: ]
(4). 任意切取几行
数组名[ [ 索引值1, 索引值2, 索引值3, ...... , 索引值n ] ]
↕
数组名[ [ 索引值1, 索引值2, 索引值3, ...... , 索引值n ] ,: ]
(二). 列
:, 代表列,写在前面
(1). 切取一列
数组名[ :, 索引值 ]
(2). 切取某列以后的全部列
数组名[ :, 索引值 : ]
(3). 间隔n列进行切取
数组名[ :, : : n ]
(4). 任意切取几列
数组名 [ :, [ 索引值1, 索引值2, 索引值3, ...... , 索引值n ] ]
(三). 交叉位置
取第 a 行到第 b 行,并且第 i 列到第 j 列的内容
数组名[ 索引a : 索引b , 索引x : 索引y ]
(四). 连续取不相邻的点
数组名[[ 行索引1 , 行索引2 , ...... , 行索引n ] , [ 列索引1 , 列索引2 , ...... , 列索引m ]]
(五). 条件取值
数组名[条件表达式]
d[d>5]
# 将d中元素值>5的值取出八. 数值的修改
1. 直接赋值
数组名[行索引, 列索引] = 值
① 数组名[行索引1 : 行索引2] = 值 → 将两行之间的所有行都赋值为“值”
② 数组名[行a : 行b : 步长] = 值 → 将间隔步长的行赋值为“值”
③ 数组名[行索引 ,: ] = 值 → 将某行赋值为“值”
① 数组名[列索引1 : 列索引2] = 值
② 数组名[列a : 列b : 步长] = 值
③ 数组名[ :, 列索引 ] = 值
2. 条件赋值
数组名[ 条件表达式 ] = 值
np.where( 条件表达式, 值1, 值2 ) → 三元运算符 ( ≈ if ... else)
np.where(a<5,0,10)
# 在数组a中,若元素值<5,则赋值为0;否则赋值为10数组名.clip( 值1, 值2 )
↕ → 将数组中≤值1的元素赋值为值1;将数组中≥值2的元素赋值为值2
np.clip( 数组名, 值1, 值2 )
九. Nan和Inf
Nan表示不是一个数字
以下情况Numpy会出现Nan:
- 读取本地文件为float,但数据有缺失时,会出现nan
- 不合适的计算如:inf-inf(inf 为正无穷,-inf 为负无穷)
1. 指定Nan或Inf
a = np.array([1,2,3], dtype = int)
a[1] = np.nan
#或
#a[1] = np.inf
# 报错a = np.array([1,2,3], dtype = float)
a[1] = np.nan
#[ 1., nan, 3.]2. Nan的特点
①. 任意两个Nan都不相同
np.nan == np.nan
# False(可以用来判断nan的个数)
① np.count_nonzero( 数组名 != 数组名 )
② np.count_nonzero( np.isnan(数组名))
其中:
np.count_nonzero( 数组名 ):作用是统计非0元素个数
np.isnan( 数组名 ):作用是是否为nan
import numpy as np
a = np.array([1,np.nan,3])
print(np.count_nonzero(np.isnan(a)))
# 1②. nan与任何值计算,都为nan。在计算行和(或列和)中,值会变成nan,因此需要用0来代替。
③. nan不能一概用0来替换:
在计算行(或列)平均值时,nan用0替代会带来很大误差
应将nan替换为均值或中值(或直接删除nan所在行)
十. 数组的拼接
1. 上下拼接
① np.vstack((数组1, 数组2, ...... , 数组n))
② np.concatenate((数组1, 数组2), axis=0)
2. 左右拼接
①np.hstack((数组1, 数组2, ...... , 数组n))
② np.concatenate((数组1, 数组2), axis=1)
十一. 行(列)互换
1. 两行互换
数组名[[行索引1, 行索引2] ,: ] = 数组名[[行索引1, 行索引2] ,: ]
2. 两列互换
数组名[ :, [列索引1, 列索引2]] = 数组名[ :, [列索引1, 列索引2]]
十二. 常用函数
1. 求和
np.sum(数组名,axis = None)
0
1
2
数组名.sum(axis = None)
0
1
2
2. 均值
数组名.mean(axis = None)
0
1
2
3. 中值
np.median(数组名,axis = None)
0
1
2
4. 最大值
数组名.max(axis = None)
0
1
2
5. 最小值
数组名.min(axis = None)
0
1
2
6. 极值
最大值与最小值之差
np.ptp(数组名,axis = None)
0
1
2
7. 标准差
标准差反应一组数据平均值的分散程度。标准差越大,数据与平均值差异越,数据越不稳定。
数组名.std(axis = None)
0
1
2
8. 幂函数
np.power(数组名, 幂次) → 将数组的每个元素都幂运算
9. 开根号
np.sqrt(数组名) → 将数组的每个元素都开根号
↕
np.power(数组名, 0.5)
10. 对数
① np.log(数组名) → 将数组的每个元素都取对数(默认以e为底)
② np.log常数(数组名) → 以“常数”为底,将数组的每个元素都取对数
11. 点乘
① 数组1 @ 数组2
② 数组1.dot(数组2)
③ np.dot(数组1, 数组2)
12. 排序(按某列)
np.argsort(数组名, axis=0) → 将数组按第一列进行排序
↕
数组名[np.argsort(数组名[:, 0])]
十三. 其他
1. 全0矩阵
np.zeros((行数, 列数), dtype = float)
int
2. 全1矩阵
np.ones((行数, 列数), dtype = float)
int
3. 单位矩阵
np.eye(行数, 列数, 对角线索引值, dtype = float)
int
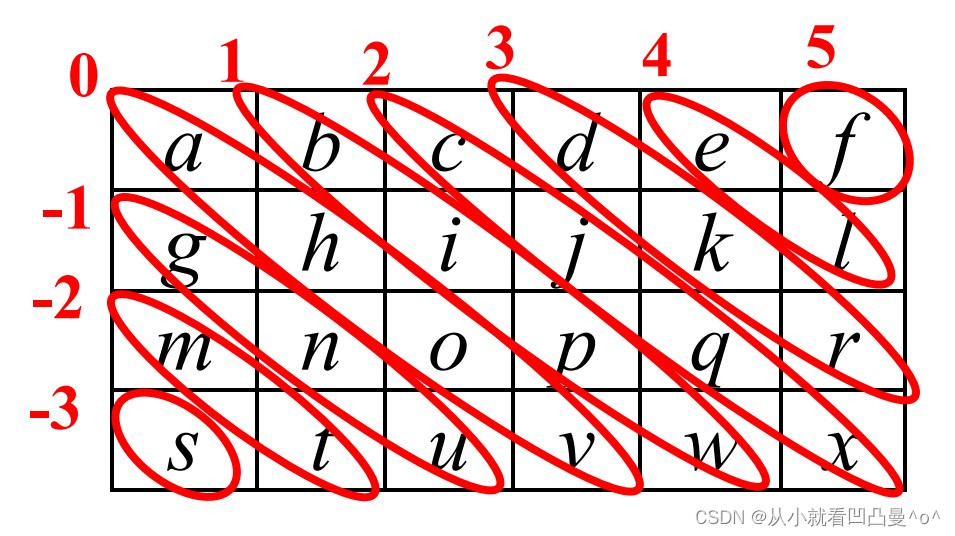
对角线索引值示意图
① np.eye(行列数, dtype = float)
int
② np.eye(行列数)
③ np.identity(行列数, dtype = float)
int
4. 随机矩阵
np.random.randint(最大值, 最小值, (行数,列数), dtype = float)
int
















 806
806











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











